Two Groups and One Continuous Variable
advertisement

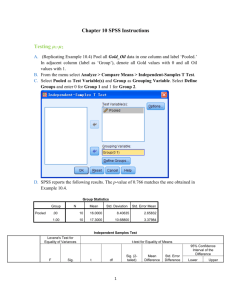
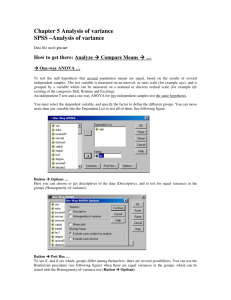
Two Groups and One Continuous Variable Psychologists and others are frequently interested in the relationship between a dichotomous variable and a continuous variable – that is they have two groups of scores. There are many ways such a relationship can be investigated. I shall discuss several of them here, using the data on sex, height, and weight of graduate students, in the file SexHeightWeight.sav. For each of 49 graduate students, we have sex (female, male), height (in inches), and weight (in pounds). After screening the data to be sure there are no errors, I recommend preparing a schematic plot – side by side box-and-whiskers plots. In SPSS, Analyze, Descriptive Statistics, Explore. Scoot ‘height’ into the Dependent List and ‘sex’ into the Factor List. In addition to numerous descriptive statistics, you get this schematic plot: 76 74 72 70 68 66 HEIGHT 64 62 60 58 N= 28 21 Female Male SEX The height scores for male graduate students are clearly higher than for female graduate students, with relatively little overlap between the two distributions. The descriptive statistics show that the two groups have similar variances and that the within-group distributions are not badly skewed, but somewhat playtkurtic. I would not be uncomfortable using techniques that assume normality. Student’s T Test. This is probably the most often used procedure for testing the null hypothesis that two population means are equal. In SPSS, Analyze, Compare Means, Independent Samples T Test, height as test variable, sex as grouping variable, define groups with values 1 and 2. The output shows that the mean height for the sample of men was 5.7 inches greater than for the women and that this difference is significant by a separate variances t test, t(46.0) = 8.005, p < .001. A 95% confidence interval for the difference between means runs from 4.28 inches to 7.08 inches. When dealing with a variable for which the unit of measure is not intrinsically meaningful, it is a good idea to present the difference in means and the confidence interval for the difference in means in standardized units. While I don’t think that is necessary here (you probably have a pretty good idea regarding how large a difference of 5.7 inches is), I shall for pedagogical purposes compute Cohen’s d (the sample statistic) and a confidence interval for Cohen’s (the parameter). In doing so, I shall use a special SPSS script and the separate variances values for t and df. See the document Confidence Intervals, Pooled and Separate Variances T. For these data, d = 2.36 (quite a large difference) and the 95% confidence interval for runs from 1.61 (large) to 3.09 (even larger). We can be quite confident that the difference in height between men and women is large. Dichot-Contin.docx Group Statistics height sex Female Male N Mean 64.893 70.571 28 21 Std. Deviation 2.6011 2.2488 Std. Error Mean .4916 .4907 Independent Sam ple s Te st t-t est for Equality of Means t height Equal variances as sumed Equal variances not as sumed df Sig. (2-tailed) Mean Difference St d. Error Difference 95% Confidenc e Int erval of t he Difference Lower Upper -8. 005 47 .000 -5. 6786 .7094 -7. 1057 -4. 2515 -8. 175 45.981 .000 -5. 6786 .6946 -7. 0767 -4. 2804 Point Biserial Correlation. Here we simple compute the Pearson r between sex and height. The value of that r is .76, and it is statistically significant, t(47) = 8.005, p < .001. This analysis is absolutely identical to an independent samples t test with a pooled error term (see the t test output above) or an Analysis of Variance with pooled error. The value of r here can be used as a strength of effect estimate. Square it and you have an estimate of the percentage of variance in height that is “explained” by sex. One-Way Independent Samples Parametric ANOVA. This too is absolutely equivalent to the t test. The value of F obtained will equal the square of the value of t, the numerator df will be one, the denominator df will be N – 2 (just like with t), and the (appropriately one-tailed for nondirectional hypothesis) p value will be identical to the two-tailed p value from t. Our t of 8.005 when squared will yield an F of 64.08. ANOVA height Sum of Squares Between Groups Within Groups Total df Mean Square 386.954 1 386.954 283.821 670.776 47 48 6.039 F 64.078 Sig. .000 Discriminant Function Analysis. This also is equivalent to the independent samples t test, but looks different. In SPSS, Analyze, Classify, Discriminant, sex as grouping variable, height as independent variable. Under Statistics, ask for unstandarized discriminant function coefficients. Under Classify, ask that prior probabilities be computed from group sizes and that a summary table be displayed. In discriminant function analysis a weighted combination of the predictor variables is used to predict group membership. For our data, that function is DF = -27.398 + .407*height. The correlation between this discriminant function and sex is .76 (notice that this identical to the pointbiserial r computed earlier) and is statistically significant, 2(1, N = 49) = 39.994, p < .001. Using this model we are able correctly to predict a person’s sex 83.7% of the time. Canonical Discriminant Function Coefficients Function 1 .407 -27.398 height (Constant) Unstandardized coefficients Eigenvalues Function 1 Eigenvalue % of Variance 1.363a 100.0 Canonical Correlation .760 Cumulative % 100.0 a. First 1 canonical dis criminant functions were us ed in the analysis. Wilks' Lambda Test of Function(s) 1 Wilks' Lambda .423 Chi-square 39.994 df Sig. .000 1 Classification Resultsa Original Count % sex Female Male Female Male Predicted Group Membership Female Male 26 2 6 15 92.9 7.1 28.6 71.4 Total 28 21 100.0 100.0 a. 83.7% of original grouped cases correctly clas sified. Logistic Regression . This technique is most often used to predict group membership from two or more predictor variables. The predictors may be dichotomous or continuous variables. Sex is a dichotomous variable in the data here, so let us test a model predicting height from sex. In SPSS, Analyze, Regression, Binary Logistic. Identify sex as the dependent variable and height as a covariate. The 2 statistic shows us that we can predict sex significantly (p < .001) better if we know the person’s height than if all we know is the marginal distribution of the sexes (28 women and 21 men). The odds ratio for height is 2.536. That is, the odds that a person is male are multiplied by 2.536 for each one inch increase in height. That is certainly a large effect. The classification table show us that using the logistic model we could, use heights, correctly predict the sex of a person 83.7% of the time. If we did not know the person’s height, our best strategy would be to predict ‘woman’ every time, and we would be correct 28/49 = 57% of the time. Omnibus Tests of Model Coefficients Chi-square Step 1 df Sig. Step 38.467 1 .000 Block 38.467 1 .000 Model 38.467 1 .000 Variables in the Equation Step a 1 height Constant B .931 -63.488 S.E. .287 19.548 Wald 10.534 10.548 df Sig. .001 .001 1 1 Exp(B) 2.536 .000 a. Variable(s) entered on s tep 1: height. Classification Table a Predicted sex Step 1 Observed sex Female Male Female 26 6 Overall Percentage Male 2 15 Percentage Correct 92.9 71.4 83.7 a. The cut value is .500 Wilcoxon Rank Sums Test . If we had reason not to trust the assumption that the population data are normally distributed, we could use a procedure which makes no such assumption, such as the Wilcoxon Rank Sums Test (which is equivalent to a Mann-Whitney U Test). In SPSS, Analyze, Nonparametric Tests, Two Independent Samples, height as test variable, sex as grouping variable with values 1 and 2, Exact Test selected. The output shows that the difference between men and women is statistically significant. SPSS gives mean ranks. Most psychologists would prefer to report medians. From Explore, used earlier, the medians are 64 (women) and 71 (men). Ranks height sex Female Male Total N 28 21 49 Mean Rank 15.73 37.36 Test Statisticsa Mann-Whitney U Wilcoxon W Z As ymp. Sig. (2-tailed) Exact Sig. (2-tailed) Exact Sig. (1-tailed) Point Probability height 34.500 440.500 -5.278 .000 .000 .000 .000 a. Grouping Variable: sex Sum of Ranks 440.50 784.50 Kruskal-Wallis Nonparametric ANOVA on Ranks As with the parametric ANOVA, this ANOVA can be used with 2 or more independent samples. While the results of the analysis will not be absolutely equivalent to those of a Wilcoxon rank sum test, it does test the same null hypothesis. Test Statisticsa,b height Chi-Square df Asymp. Sig. 27.854 1 .000 a. Kruskal Wallis Test b. Grouping Variable: sex Resampling Statistics. Using the bootstrapping procedure in David Howell’s resampling program and the SexHeight.dat file, a 95% confidence interval for the difference in medians runs from 4 to 8. Since the null value (0) is not included in this confidence interval, the difference between group medians is statistically significant. Using the randomization test for differences between two medians, the nonrejection region runs from -2.5 to 3. Since our observed difference in medians is -7, we reject the null hypothesis of no difference. Return to Wuensch’s Stats Lessons Karl L. Wuensch East Carolina University March, 2015