PPT - Cophylogeny.net
advertisement

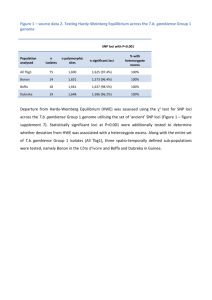
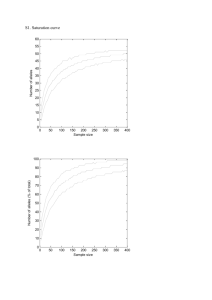
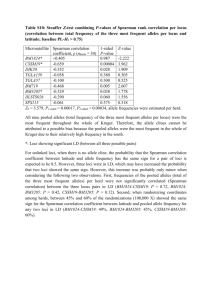
Targeted next generation sequencing for population genomics and phylogenomics in Ambystomatid salamanders Eric M. O’Neill David W. Weisrock Photograph by Stephen Dalton/Animals Animals - Earth Scenes Ambystoma tigrinum complex Coalescent Processes • Stochastic • Incomplete lineage sorting • Gene tree incongruence • Capture variance • Many loci Degnan and Rosenberg, 2006 PLOS Genetics Goals • Sequence >100 independent loci from 100s of samples – both alleles • • • • Population genetics Species delimitation Gene phylogenies Species phylogeny Jeremiah Smith Past Option • Sanger Sequencing – expensive – cloning or computational phasing alleles – low throughput 454 (Roche) Next Generation Sequencing 1 million reads × 400 bp each = 400 Million bp Barcoding Meyer et al. 2008 Nature Protocols Methods • Screened ~250 EST loci across 16 representative samples • Found >100 variable loci that amplify well at the same temperature • Amplified 95 loci for one individual in one plate • 94 individuals – 8930 amplicons • Pooled across 95 loci for each individual • Barcoded 94 individuals and pooled • UKY-AGTC: 454 Libraries, emPCR, 454 sequencing Preliminary Results • Two test runs: 1/8th picotiter plate – 65K + 20K sequences • One final run: 1/4th picotiter plate – 225K sequences • Total ~ 300K sequences • Coverage of about 34X per sample per locus • Sorted >95% 1664 seqs / 95 loci = 18X coverage 96% loci have sequence 45 loci had >10X coverage Genotyping • Clonal amplification through emPCR • Each sequence is derived from a single DNA strand • Identify both alleles without bacterial cloning Errors • Homopolymer regions • Single nucleotide mismatches Automated Statistical Genotyping Hohenlohe et al., 2010 PLOS Genetics Genotyping • Let n be the total number of reads per site • Let n = n1 + n2 + n3, where ni is the read count for each possible nucleotide at the site • For diploid, there are 10 possible genotypes – 4 homozygous (AA, TT, GG, CC) – 6 heterozygous (AT, AG, AC, TG, TC, GC) • Calculate the likelihood of each possible genotype using a multinomial sampling distribution, which gives the probability of observing a set of read counts (n1,n2,n3,n4) Likelihood of a Homozygote Likelihood of a Heterozygote Assigning Genotypes • The 2 equations give the likelihoods of the two most likely hypotheses out of 10 • Use a LRT to compare the Homo vs. Het hypotheses (df=1) • If the test is significant, we assign the most likely genotype at that site for that individual • If the test is not significant, we do not assign a genotype • This process tests for each SNP independently, but we want to genotype the entire sequence 8 ways to be Het at 3 SNPs: C—T—C C—C—C C—T—T C—C—T We need to maintain the correct info. G—T—C G—C—C G—T—T G—C—T Desired Workflow • 454 data received as FASTA files • Sort by barcode – Tommy has some code for this • Assemble by locus (alignments) – Currently in Geneious, what other options? • Genotype (phase the alleles) – Need to implement automated method – Quality scores • Export data as sequences for phylogenetic analysis • Export data as alleles for population genetic analysis