Modeling Consumer Decision Making and Discrete Choice Behavior
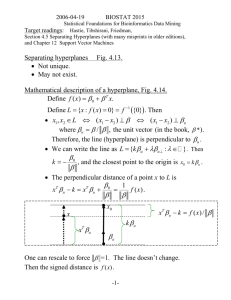
advertisement

[Part 3: Common Effects ] 1/62
Econometric Analysis of Panel Data
William Greene
Department of Economics
Stern School of Business
[Part 3: Common Effects ] 2/62
Short Term Agenda for Simple Effects Models
Models with individual effects
Extensions
Interpretation of models
Computation (practice) and estimation (theory)
Nonstandard panels: Rotating, Pseudo-, Nested
Generalizing the regression model
Alternative estimators
Methods
Least squares: OLS, GLS, FGLS
MLE and Maximum Simulated Likelihood
[Part 3: Common Effects ] 3/62
Fixed and Random Effects
Unobserved individual effects in regression: E[yit | xit, ci]
Notation:
y it =xit + ci + it
x i1
x
i2
X i Ti rows, K columns
Linear specification: x iTi
Fixed Effects: E[ci | Xi ] = g(Xi). Cov[xit,ci] ≠0
effects are correlated with included variables.
Random Effects: E[ci | Xi ] = μ; effects are uncorrelated with
included variables. If Xi contains a constant term, μ=0 WLOG.
Common: Cov[xit,ci] =0, but E[ci | Xi ] = μ is needed for the
full model
[Part 3: Common Effects ] 4/62
Convenient Notation
Fixed Effects – the ‘dummy variable model’
yit = i + xit + it
Individual specific constant terms.
Random Effects – the ‘error components model’
yit = xit + it + ui
Compound (“composed”) disturbance
[Part 3: Common Effects ] 5/62
Balanced and Unbalanced Panels
Distinction: Balanced vs. Unbalanced Panels
A notation to help with mechanics
zi,t, i = 1,…,N; t = 1,…,Ti
The role of the assumption
Mathematical and notational convenience:
Balanced,
n=NT
N
Unbalanced: n i=1 Ti
Is the fixed Ti assumption ever necessary? Almost
never. (Baltagi chapter 9 is about algebra, not
different models!)
Is unbalancedness due to nonrandom attrition
from an otherwise balanced panel? This will
require special considerations.
[Part 3: Common Effects ] 6/62
Unbalanced Panels and Attrition ‘Bias’
Test for ‘attrition bias.’ (Verbeek and Nijman, Testing for Selectivity
Bias in Panel Data Models, International Economic Review, 1992,
33, 681-703.
Variable addition test using covariates of presence in the panel
Nonconstructive – what to do next?
Do something about attrition bias. (Wooldridge, Inverse Probability
Weighted M-Estimators for Sample Stratification and Attrition,
Portuguese Economic Journal, 2002, 1: 117-139)
Stringent assumptions about the process
Model based on probability of being present in each wave of the panel
[Part 3: Common Effects ] 7/62
[Part 3: Common Effects ] 8/62
Inverse Probability Weighting
Panel is based on those present at WAVE 1, N1 individuals
Attrition is an absorbing state. No reentry, so N1 N 2 ... N T .
Sample is restricted at each wave to individuals who were present at
the previous wave.
d it = 1[Individual is present at wave t].
d i1 = 1 i, d it 0 d i ,t 1 0.
xi1 covariates observed for all i at entry that relate to likelihood of
being present at subsequent waves.
(health problems, disability, psychological well being, self employment,
unemployment, maternity leave, student, caring for family member, ...)
Probit model for dit 1[xi1 wit ], t = 2,...,T. ˆ it fitted probability.
t
Assuming attrition decisions are independent, Pˆit s 1 ˆ is
ˆ d it
Inverse probability weight W
it
P̂it
Weighted log likelihood
logLW i 1 t 1 log Lit (No common effects.)
N
T
[Part 3: Common Effects ] 9/62
An Unbalanced Panel: RWM’s
GSOEP Data on Health Care
N = 7,293 Households
Some households exited then returned
[Part 3: Common Effects ] 10/62
Unbalanced Panel Data – Not Attrition
(First 10 households in healthcare data)
z.t Nit1zit
[Part 3: Common Effects ] 11/62
Exogeneity
Contemporaneous exogeneity
Strict exogeneity – the most common assumption
E[εit|xi1, xi2,…,xiT,ci]=0
Can use first difference or fixed effects
Cannot hold if xit contains lagged values of yit
Sequential exogeneity?
E[εit|xit,ci]=0 Not sufficient for regression
Doesn’t imply how to estimate β
E[εit|xi1, xi2,…,xit,ci] = 0
These assumptions are not testable. They are part of the
model.
[Part 3: Common Effects ] 12/62
Assumptions for Asymptotics
Convergence of moments involving cross section Xi.
N increasing, T or Ti assumed fixed.
“Fixed T asymptotics” (see text, p. 175)
Time series characteristics are not relevant (may be
nonstationary)
If T is also growing, need to treat as multivariate time series.
Ranks of matrices. X must have full column rank. (Xi
may not, if Ti < K.)
Strict exogeneity and dynamics. If xit contains yi,t-1 then
xit cannot be strictly exogenous. Xit will be correlated
with the unobservables in period t-1. (To be revisited
later.)
Empirical characteristics of microeconomic data
[Part 3: Common Effects ] 13/62
Estimating β
β is the partial effect of interest
Can it be estimated (consistently) in the presence
of (unmeasured) ci?
Does pooled least squares “work?”
Strategies for “controlling for ci” using the sample data
Using a proxy variable.
[Part 3: Common Effects ] 14/62
The Pooled Regression
Presence of omitted effects
y it =x itβ+c i +εit , observation for person i at time t
y i =X iβ+c ii+ε i , Ti observations in group i
=X iβ+c i +ε i , note c i (c i , c i ,...,c i )
y =Xβ+c +ε , Ni=1 Ti observations in the sample
Potential bias/inconsistency of OLS – depends
on ‘fixed’ or ‘random’
[Part 3: Common Effects ] 15/62
A Popular Misconception
If only one variable in X is correlated with , the other coefficients are
consistently estimated. False.
Suppose only the first variable is correlated with ε
1
0
Under the assumptions, plim(X'ε /n) = . Then
...
.
q11
1
21
0
q
plim b - β = plim(X'X /n)-1 1
...
...
K 1
.
q
1 times the first column of Q-1
The problem is “smeared” over the other coefficients.
[Part 3: Common Effects ] 16/62
OLS with Individual Effects
Bias turns on the group means
b=(X X )-1 X'y = (X X )-1 X'(Xβ+c+ε)
-1
=β + (1/N)Σ X iX i (1/N)Σ Ni=1 X ic i (part due to the omitted c i )
N
i=1
-1
+ (1/N)Σ X iX i (1/N)Σ Ni=1 X iε i (covariance of X and ε will = 0)
The third term vanishes asymptotically by assumption
N
i=1
-1
T
1
plim b = β + plim ΣNi=1 X iX i ΣNi=1 i x i c i (left out variable formula)
N
N
So, what becomes of ΣNi=1 wi x i c i ?
plim b = β if the covariance of x i and c i converges to zero.
[Part 3: Common Effects ] 17/62
Mundlak’s Estimator
Mundlak, Y., “On the Pooling of Time Series and Cross Section
Data, Econometrica, 46, 1978, pp. 69-85.
Write c i = x iδ ui , E[c i | x i1 , x i1 ,...x iTi ] = x iδ
Assume c i contains all time invariant information
y i =X iβ+c ii+ε i , Ti observations in group i
=X iβ+ix iδ+ε i + uii
Looks like random effects.
Var[ε i + uii]=Ωi +σ 2uii
May be estimable by 2 step FGLS.
[Part 3: Common Effects ] 18/62
Chamberlain’s (1982) Approach
Use a linear projection, not necessarily the conditional
mean.
P[ci | x i1 , x i1 ,...x iTi ] = xi11 + xi22 ... xiT T
ci P[ci | x i1 , x i1 ,...x iTi ] ui , cov[ui ,x it ]=0
y it =xitβ+xi11 + xi22 ... xiT T + εit ui
This “regression” can be computed T times, using one year at a time.
How would we reconcile the multiple estimators of each parameter?.
[Part 3: Common Effects ] 19/62
Chamberlain’s (1982) Approach
P[c i | x i1 , x i1 ,...x iTi ] = x i11 + x i22 ... x iT T
c i P[c i | x i1 , x i1 ,...x iTi ] ui , cov[ui ,x it ]=0
y it =xitβ+xi11 + xi22 ... xiT T + εit ui
Period 1
y i1=xi1 (β+1 ) + xi22 ... xiT T + εi1 ui
Period 2
y i2=xi11 + xi2 (β+2 ) ... xiT T + εi2 ui
and so on...
[Part 3: Common Effects ] 20/62
Proxy Variables
Proxies for unobserved effects: e.g., Test score for unobserved ability
Interest is in δ(xit,ci)=E[yit|xit,ci]/xit
Since ci is unobserved, we seek APE = Ec[δ(xit,ci)]
Proxy has two characteristics
Ignorable in the model: E[yit|xit,zi,ci] = E[yit|xit,ci]
‘Explains’ ci in that E[ci|zi,xit] = E[ci|zi]. In the presence of zi, xit does not
further ‘explain ci.’
Then, Ec[δ(xit,ci)] = Ez{E[yit|xit,zi]/xit}
Proof: See Wooldridge, pp. 23-24.
Loose ends:
Where do you get the proxy?
What is E[yit|xit,zi]? Use the linear projection and hope for the best.
[Part 3: Common Effects ] 21/62
Estimating the Sampling Variance of bOLS
s2(X ́X)-1?
Correlation across observations => No
Possible heteroscedasticity
Find a “robust” covariance matrix
Robust estimation (in general)
The White estimator
A Robust estimator for OLS.
[Part 3: Common Effects ] 22/62
A ‘Cluster’ Estimator
y it =xitβ+(c i+εit )
=xitβ+v it , Cov[v it , v is ] 0 (same individual),
Cov[v it , v js ] 0 (different individuals)
There are N groups and Ti observations in group i.
OLS: X X = Ni1 X i X i (sum over N groups)
X y = Ni1 X i y i = Ni1 X i X i v i
b
=
XX Xy = + Ni1XiX i
1
True Variance(b | X ) = Ni1 X i X i
Looks like
1
N
i 1
X i v i
Var N X v N X X
i1 i i i 1 i i
XX Ni1Xi i X i XX
1
1
1
1
[Part 3: Common Effects ] 23/62
Cluster Estimator (cont.)
[Part 3: Common Effects ] 24/62
Cornwell and Rupert Data
Cornwell and Rupert Returns to Schooling Data, 595 Individuals, 7 Years
Variables in the file are
EXP
WKS
OCC
IND
SOUTH
SMSA
MS
FEM
UNION
ED
LWAGE
=
=
=
=
=
=
=
=
=
=
=
work experience
weeks worked
occupation, 1 if blue collar,
1 if manufacturing industry
1 if resides in south
1 if resides in a city (SMSA)
1 if married
1 if female
1 if wage set by union contract
years of education
log of wage = dependent variable in regressions
These data were analyzed in Cornwell, C. and Rupert, P., "Efficient Estimation with Panel
Data: An Empirical Comparison of Instrumental Variable Estimators," Journal of Applied
Econometrics, 3, 1988, pp. 149-155. See Baltagi, page 122 for further analysis. The data
were downloaded from the website for Baltagi's text.
[Part 3: Common Effects ] 25/62
Application: Cornell and Rupert
[Part 3: Common Effects ] 26/62
Bootstrapping
Some assumptions that underlie it - the sampling mechanism
Method:
1. Estimate using full sample: --> b
2. Repeat R times:
Draw n observations from the n, with replacement
Estimate with b(r).
3. Estimate variance with
W = (1/R)r [b(r) - b][b(r) - b]’
[Part 3: Common Effects ] 27/62
Bootstrap Application
matr;bboot=init(7,21,0.)$
Store results here
name;x=one,occ,…,exp$
Define X
regr;lhs=lwage;rhs=x$
Compute b
calc;i=0$
Counter
Proc
Define procedure
regr;lhs=lwage;rhs=x;quietly$
… Regression
matr;{i=i+1};bboot(*,i)=b$...
Store b(r)
Endproc
Ends procedure
exec;n=20;bootstrap=b$
20 bootstrap reps
matr;list;bboot' $
Display results
[Part 3: Common Effects ] 28/62
Results of Bootstrap Procedure
[Part 3: Common Effects ] 29/62
Bootstrap Replications
Full sample result
Bootstrapped
sample results
[Part 3: Common Effects ] 30/62
Bootstrap variance for a
panel data estimator
Panel Bootstrap =
Block Bootstrap
Data set is N groups
of size Ti
Bootstrap sample is N
groups of size Ti
drawn with
replacement.
[Part 3: Common Effects ] 31/62
[Part 3: Common Effects ] 32/62
Bootstrapping
Naïve bootstrap: Why is it naïve?
Cases when it fails
Time series
“Clustered data”
Order statistics
Parameters on the edge of the parameter space
Alternatives
Block bootstrap
“Wild” bootstrap (injects extra randomness)
[Part 3: Common Effects ] 33/62
Using First Differences
yit =xitβ+ci +εit , observation for person i at time t
Eliminating the heterogeneity
y it = y it - y i,t-1 = (xit )β+c i + εit
= (xit )β + uit
Note: Time invariant variables become zero
Time trend becomes a constant term
[Part 3: Common Effects ] 34/62
OLS with First Differences
With strict exogeneity of (Xi,ci), OLS regression of Δyit
on Δxit is unbiased and consistent but inefficient.
i,2 i,1
i,3 i,2
Var
i,T i,T 1
i
i
22
2
0
0
2
22
2
0
2
2
0
(Toeplitz form)
2
22
GLS is unpleasantly complicated. In order to
compute a first step estimator of σε2 we would use
fixed effects. We should just stop there. Or, use OLS
in first differences and use Newey-West with one lag.
[Part 3: Common Effects ] 35/62
Two Periods
With two periods and strict exogeneity,
y it = y i2 - y i,1 = 0 + (xi2 - xi1 )β + ui
Consider a "treatment, Di ," that takes place between
time 1 and time 2 for some of the individuals
y i= 0 + (x i )β + 1Di + ui
Di = the "treatment dummy"
This is a classical regression model. If there are no regressors,
ˆ
1 y | treatment - y | control
= "difference in differences" estimator.
ˆ
0 Average change in y i for the "treated"
[Part 3: Common Effects ] 36/62
Difference-in-Differences Model
With two periods and strict exogeneity of D and T,
y it = 0 1Dit 2 Tt 3 TtDit it
Dit = dummy variable for a treatment that takes place
between time 1 and time 2 for some of the individuals,
assumed exogenous so E[it | D 1] E[it | D 0]
Tt = a time period dummy variable, 0 in period 1,
1 in period 2.
This is a linear regression model. If there are no regressors,
Using least squares,
b3 (y 2 y1 )D1 (y 2 y1 )D0
[Part 3: Common Effects ] 37/62
Difference in Differences
y it = 0 1Dit 2 Tt 3Dit Tt βx it it , t 1, 2
y it = 2 3Di 2 (βx it ) it
= 2 3Di 2 β(x it ) ui
y it | D 1 y it | D 0
3 β (x it | D 1) (x it | D 0)
If the same individual is observed in both states,
the second term is zero. If the effect is estimated by
averaging individuals with D = 1 and different individuals
with D=0, then part of the 'effect' is explained by change
in the covariates, not the treatment.
[Part 3: Common Effects ] 38/62
http://dera.ioe.ac.uk/14610/1/oft1416.pdf
[Part 3: Common Effects ] 39/62
Outcome is the fees charged.
Activity is collusion on fees.
[Part 3: Common Effects ] 40/62
Treatment Schools:
Treatment is an
intervention by the
Office of Fair Trading
Control Schools were
not involved in the
conspiracy
Treatment is not
voluntary
[Part 3: Common Effects ] 41/62
[Part 3: Common Effects ] 42/62
[Part 3: Common Effects ] 43/62
Treatment (Intervention)
Effect = δ
[Part 3: Common Effects ] 44/62
In order to test robustness two versions of the fixed effects model were run. The first is
Ordinary Least Squares, and the second is heteroscedasticity and auto-correlation robust
(HAC) standard errors in order to check for heteroscedasticity and autocorrelation.
[Part 3: Common Effects ] 45/62
[Part 3: Common Effects ] 46/62
[Part 3: Common Effects ] 47/62
[Part 3: Common Effects ] 48/62
Natural Experiment: Do Motorcycle Helmets Save Lives?
In the three years after Michigan repealed a mandatory motorcycle helmet law, deaths and
head injuries among bikers rose sharply, according to a recent study.
Deaths at the scene of the crash more than quadrupled, while deaths in the hospital tripled
for motorcyclists. Head injuries have increased overall, and more of them are severe, the
researchers report in the American Journal of Surgery.
[Part 3: Common Effects ] 49/62
D-in-D Model: Natural Experiment
With two periods and strict exogeneity,
y it = 0 1Di 2 2 Tt 3 Tt Dit it
Di2 = dummy variable for a treatment that takes place
between time 1 and time 2 for some of the individuals,
Tt = a time period dummy variable, 0 in period 1,
1 in period 2.
This is a classical regression model. If there are no regressors,
Using least squares,
b3 (y 2 y1 )D1 (y 2 y1 )D0
[Part 3: Common Effects ] 50/62
D-i-D – Natural Experiment
Card and Krueger: “Minimum Wages and Employment: A Case
Study of the Fast Food Industry in New Jersey and Pennsylvania,”
AER, 84(4), 1994, 772-793.
Pennsylvania vs. New Jersey
1991, NJ raises minimum wage
Compare change in employment PA after the change to change in
employment in NJ after the change.
Differences cancel out other things specific to the state that would
explain change in employment.
[Part 3: Common Effects ] 51/62
A Tale of Two Cities
A sharp change in policy can constitute a natural
experiment
The Mariel boatlift from Cuba to Miami (MaySeptember, 1980) increased the Miami labor force by
7%. Did it reduce wages or employment of nonimmigrants?
Compare Miami to Los Angeles, a comparable
(assumed) city.
Card, David, “The Impact of the Mariel Boatlift on the
Miami Labor Market,” Industrial and Labor Relations
Review, 43, 1990, pp. 245-257.
[Part 3: Common Effects ] 52/62
Difference in Differences
i individual, T = 0 for no immigration, T=1 for immigration
(Yi | T) Yi,T 1 if unemployed, 0 if employed.
c = city, t = period.
Unemployment rate in city c at time t is E[Yi,0 | c,t] with no migration
Unemployment rate in city c at time t is E[Yi,1 | c,t] with migration
Assume E[Yi,0 | c,t] t c
E[Yi,1 | c,t] t c
E[Yi,0 | c,t]
the effect of the immigration on the unemployment rate.
[Part 3: Common Effects ] 53/62
Applying the Model
c = M for Miami, L for Los Angeles
Immigration occurs in Miami, not Los Angeles
T = 1979, 1981 (pre- and post-)
Sample moment equations: E[Yi|c,t,T]
E[Yi|M,79] = β79 + γM
E[Yi|M,81] = β81 + γM + δ
E[Yi|L,79] = β79 + γL
E[Yi|L,79] = β81 + γL
It is assumed that unemployment growth in the two
cities would be the same if there were no immigration.
[Part 3: Common Effects ] 54/62
Implications for Differences
Neither city exposed to migration
Both cities exposed to migration
E[Yi,0|M,81] - E[Yi,0|M,79] = [β81 + γM ] – [β79 + γM] ( Miami)
E[Yi,0|L,81] - E[Yi,0|L,79] = [β81 + γL ] – [β79 + γL] (LA)
E[Yi,1|M,81] - E[Yi,1|M,79] = [β81 + γM ] – [β79 + γM] + δ(Miami)
E[Yi,1|L,81] - E[Yi,1|L,79] = [β81 + γL ] – [β79 + γL] + δ(LA)
One city (Miami) exposed to migration: The difference
in differences is.
Miami change - Los Angeles change
{E[Yi,1|M,81] - E[Yi,1|M,79]} – {E[Yi,0|L,81] - E[Yi,0|L,79]}
= δ (Miami)
[Part 3: Common Effects ] 55/62
The Tale
1979
1980
1981
1982
1983
1984
1985
In 79, Miami unemployment is 2.0% lower
In 80, Miami unemployment is 7.1% lower
From 79 to 80, Miami gets
5.1% better
In 81, Miami unemployment is 3.0% lower
In 82, Miami unemployment is 3.3% higher
From 81 to 82, Miami gets
6.3% worse
[Part 3: Common Effects ] 56/62
Application of a Two Period Model
“Hemoglobin and Quality of Life in Cancer
Patients with Anemia,”
Finkelstein (MIT), Berndt (MIT), Greene (NYU),
Cremieux (Univ. of Quebec)
1998
With Ortho Biotech – seeking to change labeling
of already approved drug ‘erythropoetin.’
r-HuEPO
[Part 3: Common Effects ] 57/62
[Part 3: Common Effects ] 58/62
QOL Study
Quality of life study
yit = self administered quality of life survey, scale = 0,…,100
xit = hemoglobin level, other covariates
Treatment effects model (hemoglobin level)
Background – r-HuEPO treatment to affect Hg level
Important statistical issues
i = 1,… 1200+ clinically anemic cancer patients undergoing
chemotherapy, treated with transfusions and/or r-HuEPO
t = 0 at baseline, 1 at exit. (interperiod survey by some patients was
not used)
Unobservable individual effects
The placebo effect
Attrition – sample selection
FDA mistrust of “community based” – not clinical trial based statistical
evidence
Objective – when to administer treatment for maximum marginal
benefit
[Part 3: Common Effects ] 59/62
Regression-Treatment Effects Model
QOL it t + "other covariates"
+ 7Hbit7 + 8Hbit8 + 9Hbit9 + ... 15Hb15
it
+ c i + εit
Hbit hemoglobin level, grams/deciliter, range 3+ to 15
Hbit7 1(3 Hbit < 7.5) (Base case; 7 = 0)
Hbit8 1(7.5 Hbit < 8.5)
Hb15
it 1(14.5 Hbit 15)
[Part 3: Common Effects ] 60/62
Effects and Covariates
Individual effects that would impact a self reported
QOL: Depression, comorbidity factors (smoking), recent
financial setback, recent loss of spouse, etc.
Covariates
Change in tumor status
Measured progressivity of disease
Change in number of transfusions
Presence of pain and nausea
Change in number of chemotherapy cycles
Change in radiotherapy types
Elapsed days since chemotherapy treatment
Amount of time between baseline and exit
[Part 3: Common Effects ] 61/62
First Differences Model
QOL i QOL i1 QOL i0
j
j
K
= (1 0 ) 15
(Hb
Hb
)
j 8 j
i1
i0
k 1k (x ik ,1 x ik ,0 ) i1 i0
Regression to the mean (the "tendency to mediocrity")
i0 i1 ui (QOL i0 QOL 0 ) Expect 0 < 1
implies
= 1 0 QOL 0
QOL i QOL i1 QOL i0
j
j
K
= 15
(Hb
Hb
)
j 8 j
i1
i0
k 1k (x ik ,1 x ik ,0 ) QOL i0 + ui
[Part 3: Common Effects ] 62/62
Optimal treatment.
Conventional wisdom
and assumption of
policy.
Study finding
Note the implication of
the study for the
location of the optimal
point for the treatment.
Largest marginal benefit
moves from the left tail
to the center.
Finding
[Part 3: Common Effects ] 63/62
[Part 3: Common Effects ] 64/62
Most Helpful Customer Reviews
31 of 39 people found the following review helpful Too theoretical and poorly written
By Doktor Faustus on May 7, 2013
Format: Hardcover Econometric Analysis" by William Greene is one of the more widely use graduate-level
textbooks in econometrics. I used it in my first year PhD econometrics course. This is unfortunate for several
reasons. The book states that its first objective is to introduce students to applied econometrics, especially the basic
techniques of linear regression. When reading the book, however, what the reader notices first is that the applications
are essentially just footnotes; the meat of each chapter is dense econometric theory. An applied textbook would focus
on working with data, but Greene's book has exercises that focus on proving obscure statistical properties (i.e. prove
that the asymptotic variance of various estimators goes to zero). Useful for theorists, but not for applied work, which
is what the book advertises itself as.
Another problem with the book is its impenetrable text. Reading this book is drudgery even when not trying to make
sense of the absurdly huge matrix equations. Greene uses academic, elevated language that does not belong in a
technical textbook. Where the student needs clear explanation, he instead reads sentences like the following found in
a chapter introduction: "We first consider the consequences for the least squares estimator of the more general form
of the regression model. This will include assessing the effect of ignoring the complication of the generalized model
and of devising an appropriate estimation strategy, still based on least squares". After reading that second sentence
several times I still don't understand what Greene is trying to convey.
Finally the book is much too large and expensive for a class textbook. The book is 1200 pages long and includes
numerous asides in every chapter. If the objective of the book is to teach econometrics to graduate students (as it
says in the book), then it would be better off focusing on important topics and applications, not on topics that are
never used by the vast majority of economists. I do not recommend this book for anyone; there are better
econometrics textbooks available for undergraduates, graduate students, and professionals.
[Part 3: Common Effects ] 65/62
October 13, 2014
By Daniel Pulido
This review is from: Econometric Analysis (7th Edition) (Hardcover)
The delivery was fine. But the book itself is the worst Econometric Analysis book
I have ever come across. No examples. Only a continuous list of theorems.
I would not recommend anyone this book.
[Part 3: Common Effects ] 66/62