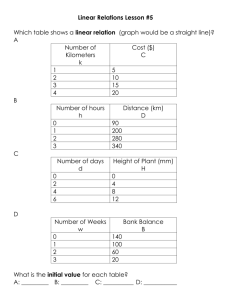
The regression line
advertisement

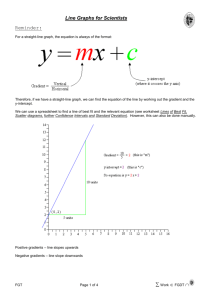
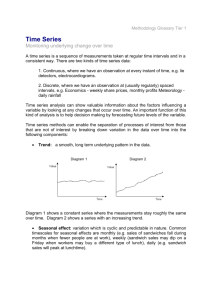
Simple regression We remember (or have forgotten) that the equation y = mx + c represents a straight line as shown in the diagrams below. If we have a number of data points and we plot them on a graph, then maybe we can fit such a straight line to the data. That is to say, we can calculate (from the data points) values of the slope m and the y-axis intercept c, such that the resulting straight line passes reasonably well through the data points. Such a process is called regression. If we can achieve this, then perhaps we can use the resulting equation of the straight line to predict what value of y we would get for a value of x which was not in the original data set. This is forecasting! The problems which arise when doing this include: 1) How do we know whether a straight line really does represent the data, and not a curve of some kind? 2) How reliable a guide is such a straight line to forecasting values which were not in the original data set? 3) If several people draw a straight line through a set of data points, they will draw different lines - is there a ‘best’ way of doing it, so that different people will get the same answer? y y y1 - y2 slope = m = x1 - x2 y1 c y1 y = mx + c y2 y1 - y2 slope = m = x1 - x2 y2 y = mx + c c x x2 x1 Positive slope (m > 0) x1 x x2 Negative slope (m < 0) An example to answer the queries Suppose that a company is considering increasing the selling price of one of its products by 5 per cent, so as to pass on the effects of inflation to its customers. The company expects this to have some effect on sales, and wants to know what the effect might be. Here are the data describing this product’s sales versus selling price over several years. Price Sales (*10000) Price Sales (*10000) 3.79 8.7 6.09 7.6 4.29 8.6 6.29 7.7 4.79 8.3 6.39 8.0 4.89 8.4 6.49 7.4 5.19 8.2 6.59 7.8 5.39 8.3 6.89 7.4 5.49 8.2 7.19 7.0 5.69 7.7 7.29 7.5 5.99 7.7 7.39 6.6 Even though the table has been arranged strictly in order of increasing price, the only thing we can say is that there seems to be a general decrease in sales volume as the price increases. The largest sales volume happens to coincide with the c:\ken\lects\ietm6_7.doc 1 3/6/2016 lowest price, and vice versa. However, there are clearly many other variations here, which mean that any pattern is not obvious. Scatter diagrams The first step to take in viewing such data is to plot a scatter diagram. This is simply the data points, plotted on a graph, but without any line joining the points together. This appears as the left-hand diagram below. Looking at the scatter diagram, there is obviously some connection between the two variables (selling price and sales volume), because the points are clustered around a definite path across the plot, not just scattered randomly. The question is, what might this relationship be? The simplest function which might relate the two variables is a straight line, and we could just draw one ‘by eye’, which we thought was the best fit between the points. Such a line is shown in the right-hand figure. Maybe this line could be used to predict the effect of the proposed selling price increase – but there is a couple of other things we need to cover first. Sales (* 10000) Sales (* 10000) 9 9 8.5 8.5 8 8 7.5 7.5 7 7 6.5 6.5 6 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5 8 6 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5 8 Price (£) Price (£) The regression line If two different people drew a ‘best-fit’ line onto the scatter diagram (above left) ‘by eye’, they would generate two different results. There has to be a better way, which would lead to a consistent, repeatable result. The ‘better way’ is to fit a straight line equation to the data, mathematically, of the form y = mx + c. We can’t do this straight from the plot, because it would be just as subjective as drawing the line ‘by eye’. Also, the y-axis does not pass through x = 0, so we cannot locate the c value. Rather, we obtain m and c for the straight line equation, by analysis of the actual data values. The formulae for these are fairly horrific but, as in the case of some other formulae we have seen, they are easily worked out if we work in a tabular form, step-by-step (especially if it is done using a spreadsheet). The formulae are derived from an analysis which fits the best straight line, in the sense that it minimises the sum of the squares of the errors between the line and the actual data points. Any other straight line would make this sum of the squares of the errors larger. Here are the formulae, using n for the number of data pairs (one x value and the corresponding y value per pair), x to represent the data values along the x-axis (the selling price in this case) and y to represent the data values up the y-axis (the c:\ken\lects\ietm6_7.doc 2 3/6/2016 sales volume in units of 10000 in this case). Note the difference between sum of the squares of the x-values) and x 2 x 2 (the (the square of the sum of all the x- values). Following the formulae is a table, which will allow the required factors to be easily worked out. m n xy x y c n x 2 x 2 y m x n n Over to you: Complete the table below and draw the regression line onto the scatter diagram above. Since the y-axis does not pass through x = 0, the easiest way to plot the line is just to pick a couple of x-axis values that seem convenient (or three, to be safe), plug them into the regression line equation to find the corresponding y values, and join up the two points. Now, if we increase the selling price by five per cent, and then apply the formula of the regression line we have calculated, we shall get a prediction of what will happen to the sales as a result. Price (£) x 3.79 4.29 4.79 4.89 5.19 5.39 5.49 5.69 5.99 6.09 6.29 6.39 6.49 6.59 6.89 7.19 7.29 7.39 Sums x= Sales (10000) y 8.7 8.6 8.3 8.4 8.2 8.3 8.2 7.7 7.7 7.6 7.7 8.0 7.4 7.8 7.4 7.0 7.5 6.6 y= x2 (x2)= xy xy= Over to you: Increase the present sales price (£7.39) by five per cent, and use your regression line (either on the graph, or using the formula of the line) to predict the effect on sales. How reliable do you think your prediction will be? c:\ken\lects\ietm6_7.doc 3 3/6/2016 The correlation coefficient The method used above has fitted the best straight line between the data points on our graph. However, it looks as if the best-fitting line of all might be a curve, rather than a straight line (if this isn’t obvious, try looking along the straight line from the edge of the paper, and see how the data points fall). There are methods for fitting curves to sets of data points, but fortunately (!) they are too complex for this session. In fact, it is really only one or two (literally) of the data points which give the impression of a curve, so we are again back on rather subjective ground. However, there is a measure of how well the straight line fits the data points, called the correlation coefficient. This measure will tell us how confident we can be that our straight line is a reasonable representation between selling price and sales volume, or whether we ought really to use a curve. There is more than one correlation coefficient, but the one suggested in Wisniewski’s ‘Foundation’ text (known as Pearson’s product moment, and given the symbol r) is given by the wonderful formula: n xy x y r 2 2 n x 2 x n y 2 y Mathematically, r cannot be greater than one. A value of r = 1 means that the straight line passes through every data point, so we can be absolutely sure that it fits the given data. A value of r near to zero, means that the straight line is a very poor representation of the given data, and we should not trust it at all (for example, the data points may just be randomly scattered all over the place, or they may lie on a well-defined curved line). The sign of r should agree with the sign of m. Over to you: Add a y2 column to the table above, and then calculate r. Given that r should be at least 0.7 in magnitude before we trust the line as a good representation, what do you make of your previous conclusions? Trends and cyclic variations In the previous example, about the effect of price increases on sales volume, we assumed throughout that there was no other effect operating to affect the sales. In fact, the demand for a particular product of a company might be changing due to increased competition, or many other reasons, and not just because of the price increases. Also, there may well be seasonal variations in the performance of a business, as noted before. To take all these things into account, it is necessary to regard the data as being made up of three components. Bill Barraclough says these were once described to him as, ‘trend plus cyclic plus hash’ (Wisniewski’s ‘Foundation’ text has the rather more prosaic description, trend plus seasonal variation plus residual). The trend is self-explanatory. It is the underlying movement in the data after ‘filtering out’ the effects of any seasonal or other relatively rapid variations. This is very useful information as it shows the general progress of some variable, on a long timescale. If the trend in sales is always downwards, then a company knows it has a problem, and can react accordingly. c:\ken\lects\ietm6_7.doc 4 3/6/2016 The cyclic or seasonal component is any oscillatory behaviour which has been observed over a long period of time, and is known to be more-or-less repetitive. For example, the electricity and gas supply industries understand very well how demand for their products varies, not only from season to season, but even from hour to hour during any given day; as the population wakes up, goes to work, comes home, puts on the kettle after popular TV programmes, etc. This is clearly very useful information, as it allows demand to be predicted, and catered for. In the case of a department store, there may be a large downturn in sales of umbrellas and winter clothing as the spring arrives. However, this will generally not cause any alarm, as it happens every year, and the company knows that sales will automatically increase again as the next winter approaches without any special action on their part. The ‘hash’, or residual is the remaining fluctuation in the data caused by random variations in activity as time passes. These are generally unpredictable and are, hopefully, relatively small, compared with the other two effects. Any business whose sales depend to any great extent on random fluctuations in demand, is certainly a ‘hostage to fortune’, and would not be popular with its accountant or bank manager. An analysis of the sales volume of a product over a period of five years, appears in the table below. If we plot this data simply as a line graph, we obtain the plot marked by the crosses in the left-hand figure on page 11. c:\ken\lects\ietm6_7.doc 5 3/6/2016 Quarter Sales (* 1000) 1993 (1) 6.2 1993 (2) 6.1 Fourperiod total 8period total Trend (T) Seasonal (sales T) 51.8 6.475 -0.075 53.5 6.688 0.012 54.5 6.812 0.388 Seasonal ly adjusted 25.4 1993 (3) 6.4 26.4 1993 (4) 6.7 27.1 1994 (1) 7.2 27.4 1994 (2) 6.8 1994 (3) 6.7 1994 (4) 7.1 1995 (1) 7.5 1995 (2) 7.4 1995 (3) 7.3 1995 (4) 7.7 1996 (1) 8.2 1996 (2) 8.0 1996 7.8 c:\ken\lects\ietm6_7.doc 6 3/6/2016 (3) 1996 (4) 8.3 1997 (1) 8.6 1997 (2) 8.4 1997 (3) 8.4 1997 (4) 8.7 9 9 8.5 8.5 8 8 7.5 7.5 7 7 6.5 6.5 6 6 1993 1993.5 1994 1994.5 1995 1995.5 1996 1996.5 1997 1997.5 1998 Sales (in thousands) and trend plot 5.5 1993 1993.5 1994 1994.5 1995 1995.5 1996 1996.5 1997 1997.5 1998 Sales (* 1000) and seasonally-adjusted plot It is fairly clear just from that plot, that there is an underlying ‘upwards’ trend to the sales as the years go by (it is actually superimposed on the plot), but also a repetitive cyclic variation with the seasons in each year. This variation is not identical from one year to the next (because of random fluctuations), but there is a definite pattern. The question is, how do we extract these separate parts of the information from the raw data? The trend As we mentioned earlier, the trend is simply a filtered version of the data, to reduce greatly the cyclic variation. How do we achieve this filtering? The simplest filter we can apply is known as a moving average filter. In principle, we decide upon a number of successive data points to average (say four), plot the average value of the first four points, move along one data point and plot the average of points (2, 3, 4 and 5), move along again and plot the average of points (3, c:\ken\lects\ietm6_7.doc 7 3/6/2016 4, 5 and 6) and so on. There is an obvious problem with this. Namely, if we average the sales for the first four points (all four quarters of the year 1993, which is why we chose four as the number), where do we plot the average on the time axis? If we plot it half way through 1993, it will not coincide with the time-value of any of our data points. If we just want to see the plot, that doesn’t really matter, and we could go ahead. However, it is more likely that we shall want to do some comparisons between the trend and the original data, so we do really need the data points for the trend to coincide with the same times as the original data points. One way to achieve this would simply be to pick an odd number of data points to average at each step (e.g. five). This is not normally done though, because in financial analysis we always work in months, quarters, four-week periods, years and so on; making four a much more convenient number for a time axis like ours, divided into quarter-years. So, the following procedure is used. With reference to the table above, the sales for the first four quarters are totalled, and written in the ‘four-period total’ column, at the mid-point of the four values to which they refer. Notice again that this value (25.4 thousand sales) does not therefore coincide with any of our period sales data. The same procedure is repeated for the sales in the next set of four quarters (1993 quarters 2, 3 and 4, plus 1994 quarter 1), and the value of 26.4 thousand total sales written as shown. The entire ‘four-period total’ column is completed in this way. Next, each adjacent pair of ‘four period total’ values is added together to give the data in the ‘eight-period total’ column. For example, the first two four-period totals sum to give 25.4 + 26.4 = 51.8 thousand sales. The value used to show the trend is then the average value of this, taken over the eight periods it covers (1993 (1), 1993 (2) twice, 1993 (3) twice, 1993 (4) twice and 1994 (1)). So the value is 51.8 / 8 = 6.475 thousand sales. The time 1993, 3 rd quarter, is exactly in the middle of this data, so that is where the point is plotted on the trend plot. Note that the first few points of the trend plot are effectively absent, because it takes a certain number of data points to build up the moving average, in order to generate the first result. Over to you: Complete the table for the trend data, and check it against the left-hand plot on page 11. Seasonal (or cyclic) variation The data set is made up of the trend, plus the seasonal variation, plus some random residual fluctuations. Assuming the random fluctuations to be negligibly small, this means that subtracting the trend data from the original data, will leave the cyclic variation. This can be plotted if required, but often it is used to ‘seasonally adjust’ the sales data, so that the sales figures can be viewed effectively taking into account the fact that the above average sales in some quarters will be cancelled out by the below average sales in others. Over to you: a) Fill in the seasonal variation column of the data table above (‘sales – T’). Notice that positive values show where the sales figure is higher than the trend, and negative values show where it is lower. c:\ken\lects\ietm6_7.doc 8 3/6/2016 b) Now find the mean seasonal variation in each quarter of the year. For example, to find the mean third quarter variation, add up the variations for 1993 (quarter 3), 1994 (quarter 3), 1995 (quarter 3) and 1996 (quarter 3) and divide the total by four. You can only include the periods for which a variation exists in the table, so you can’t include 1993 (quarter 1), for example. c) These four means should theoretically sum to zero, but they may not, due to accumulated rounding errors. If they don’t, they can be made to, by subtracting ¼ of the sum of the four mean values from each of them. d) Finally, subtract the appropriate corrected mean quarterly variation, from each of the original sales figures, to give the seasonally-adjusted sales. Check your result against the smoother line in the right hand graph on page 11. Summary In these notes, we have seen how the probabilities of certain events happening can be evaluated, and how such probabilities can be combined to predict the likelihood of more complex situations occurring. We have also seen how straight line graphs can be fitted to suitable data to assist in forecasting, and how the confidence we can have in such forecasts can be evaluated. Finally, we saw how to calculate trends and seasonal variations from data plotted against time. All these things are of assistance in trying to plan for the future. Ken Dutton October 1998 c:\ken\lects\ietm6_7.doc 9 3/6/2016