Reliability Studies
advertisement

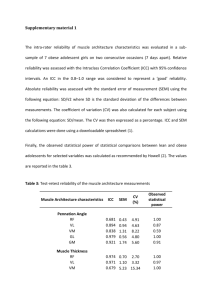
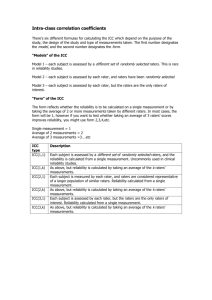
A Few Points to Consider When Reporting Reliability Studies LANGUAGE Throughout the manuscript avoid characterizing reliability as (1) a property of the measure, and (2) an all-or-none property. Poorly worded: Our results showed that the 6-minute walk test was reliability. Better worded: Our results showed that the reliability of the 6-minute walk test exceeded 0.80 when applied to patients with OA of knee awaiting total joint arthroplasty. COHESION Ensure there is cohesion among the study purpose, description of analysis and sample size calculation, and reporting of results. PURPOSE STATEMENT Ensure the purpose / research question statement clearly identifies the study context and prepares readers for whether the goal is parameter estimation or hypothesis testing. Vaguely worded: Our purpose was to examine (or explore) the test-retest reliability of the 6minute walk test. Better statement parameter estimation: Our purpose was to estimate the test-retest reliability of the 6-minute walk test in patients with OA of the knee awaiting total joint arthroplasty. Better statement hypothesis testing: Our purpose was to determine whether the test-retest reliability of the 6-minute walk test in patients with OA of the knee awaiting total joint arthroplasty exceeded 0.80. Null hypothesis: ICC2,1 ≤ 0.80 Alternate hypothesis: ICC2,1 > 0.80 CONTEXT Because properties such as reliability, validity, and sensitivity to change are not properties of a measure, but rather of a measure applied in a specific context, it is essential that the context is clearly reported. Patients: Provide a clear description of the eligibility criteria and sampling method. Raters (if applicable): Provide a clear description of the rater eligibility and whether your interest is in just these raters or whether you wish to generalize beyond the raters taking part in the study to all raters who share similar characteristics and training. Study setting: Provide a clear description of the study setting. STUDY DESIGN Language: If the study involves different raters assessing patients on multiple occasions, avoid “pigeon holing” the study label description into either inter-rater or test-retest terminology. Considering including both descriptors when referring to the design: think potential sources of variation. Balancing raters’ assessments: If raters assessed patients on different occasions, report whether the order testing patients was balanced across raters. Analyses Subsection of Methods Specify the descriptive and summary statistics to be reported. Specify the requisite statistical and design assumptions tested. Report both relative (intraclass correlation coefficient: ICC) and absolute reliability (standard error of measurement: SEM) coefficients. If the goal was parameter estimation, report point and interval estimates of both the ICC and SEM. If the goal was hypothesis testing, report point and interval estimates of both the ICC and SEM.and the p-value associated when the specified null hypothesis (usually framed in terms of the ICC). Caution: Often the default null hypothesis for many statistical software packages is ICC=0. Choose the appropriate ICC: The following table provides a guide when the Shrout and Fleiss classification scheme is applied to designs that do not allow the partitioning of interaction and error variances. Table. Considerations When Choosing Shrout and Fleiss ICC Coding k=1 k=number of measurements averaged Type 1, k ICC 1-way ANOVA: patients need not have the same number of measured values, nor do the measurements need to be performed by the same rater or set of raters Type 2, k ICC 2-way ANOVA: all patients are rated by the same assumption same set of raters which are considered to represent a larger group of raters. Rater factor is random. Or, a systematic difference among raters or time-points matters. Absolute agreement is of interest. Type 3, k ICC 2-way ANOVA: all patients are rated by the same set of raters which are the only raters of interest. Rater factor is fixed. Consistency (rank ordering) rather than absolute agreement is of interest. same assumption same assumption SAMPLE SIZE Sample size estimates for reliability studies are typically based on the ICC. Parameter estimation: Specify whether the sample size estimate was based on: (1) the lower 1sided confidence interval width, or (2) the overall (2-sided) width. In addition to this clarification specific the confidence interval of interest. Lower 1-sided 97.5% CI example: Our test-retest sample size was based on two assessments (1 at each occasion) an expected ICC of .90 with a lower 1-sided 97.5% CI wide of 0.10 (i.e., the lower limit would be 0.80). 2-sided 95% CI example: Our test-retest sample size was based on two assessments (1 at each occasion) an expected ICC of 0.90 with a confidence interval width 0.20. Hypothesis testing: When framing hypotheses for reliability studies, an investigator is typically interested in whether the reliability exceeds some lower limit deemed to be acceptable. For this reason the alternate hypothesis is directional (ICC>0.80). Accordingly, the following information is required when calculating the sample size for a hypothesis testing study: (1) null hypothesis (ICC ≤ 0.80), (2) alternate hypothesis (ICC > 0.80), (3) the expected point estimate of the ICC from the study (e.g., 0.90), (4) the number of measurements per subject (e.g., 2 for a test-retest reliability study), (5) the 1-tailed probability of a Type I error (0.05), (6) the probability of a Type II error (e.g., 1-power = 0.20). RESULTS Report summary statistics (mean and standard deviation) for each rater, occasion, and order when applicable. Report the extent to which requisite statistical and design assumptions were met. Report point and interval estimates for the ICC and SEM for both parameter estimation and hypothesis testing studies. Also, for hypothesis testing studies include the p-value associated with the specified null hypothesis. DISCUSSION / KNOWLEDGE TRANSLATION Although it may seem obvious to authors, human beings do not transfer information well. For this reason make it obvious to readers how your results can be applied to clinical decisionmaking by embedding a brief clinical vignette. For example, the standard error of measurement, or a multiple of it, could be used to illustrate the confidence in a measured value and the change required to be reasonably certain a patient has change.