Class 24 Assignment answers
advertisement

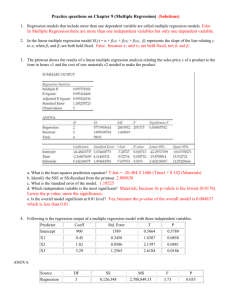
ASSIGNMENT 24 Assumptions, R-square adjusted, and Testing Hypotheses. 1. In class 22 we saw four clouds of points (A, B, C, D) that produced identical regression lines and regression statistics. Match the data set with the regression assumption most clearly violated . (This is a matching question, draw lines connecting each of the data sets with one (and only one) entry from the second column.) One of the data sets did not clearly violate any of the three listed assumptions. [20 points] Data Set A B C D Assumption Violated Linearity Homoskedasticity Normality none A definitely violates Linearity. B will have two large positive residuals and 9 small negative residuals. Thus the distribution of residuals will not be symmetric. B violates the normality assumption. C looks fine. D will have scattered residuals for the high X value and a single residual of zero at the low X value. This might indicate heteroskedasticiy. Thus D violates homoscedasticity. Using n (X,Y) pairs, Al regressed Y on X. Bo appended a copy of the data set to the original data set and also regressed Y on X. This meant that each X,Y pair in Al’s data set appeared twice in Bo’s. Bo’s sample size was 2n. Assume X and Y are positively correlated. 2. This question asks how Bo’s regression line will compare to Al’s. (Circle one answer.) [10 points] A. Bo’s line will be steeper than Al’s. B. Bo’s line will be the same slope as Al’s. C. Bo’s line will be less steep than Al’s. D. How Bo’s line compares to Al’s will depend on the data. The correct answer is B. Al and Bo’s lines will be identical. 3. Both Al and Bo test H0: b=0 versus Ha: b≠0. How will their p-values compare? (Circle one answer.) [10 points] A. Bo’s p-value will be lower than Al’s. B. Bo’s p-value will be equal to Al’s C. Bo’s p-value will be greater than Al’s. D. It depends on the data. The correct answer is A. The coefficients will be identical and the standard error of the model will be about equal (Bo has the same ten residuals as Al…twice….the scatter of Bo’s 20 residuals will be the same as Al’s.) But with n=20, the standard error of Bo’s coefficient will be lower. Given the coefficient is positive (as mentioned in the question), Bo’s t will be higher and p-value lower. Once again, Bo has CHEATED by doubling his data….his cheating is rewarded with a lower pvalue. 4. (EMBS problem 22) PC World provided ratings for the top five small-office laser printers and five corporate laser printers (PC World, Feb 2003). The following data show the speed for plain text printing in pages per minute (ppm) and the price of the printer. Name Minolta-QMS PagePro 1250W Brother HL-1850 Lexmark E320 Minolta-QMS PagePro 1250E HP Laserjet 1200 Xerox Phaser 4400/N Brother HL-2460N IBM Infoprint 1120n Lexmark W812 Oki Data B8300n Type Small Office Small Office Small Office Small Office Small Office Corporate Corporate Corporate Corporate Corporate Speed 12 10 12.2 10.3 11.7 17.8 16.1 11.8 19.8 28.2 Price 199 499 299 299 399 1850 1000 1387 2089 2200 a. Regress Price on Speed and report the resulting regression equation. (One can simply cut and paste the data above into excel….or key in the data.) [15 points] Intercept Speed Coefficients -745.4806 117.91732 The predicted price is -745.5 + 117.9 * Speed (in ppm). As expected, the predicted price increases with speed. The best guess for the rate of increase is $117.9 per ppm. b. What is the adjusted R-square? [5 points] Regression Statistics Multiple R 0.840892 R Square 0.7070994 Adjusted R Square 0.6704869 Standard Error 458.02486 Observations 10 The adjusted R square is 67%. 67% of the variation of price (in our ten data points) is explained using regression and ppm. c. One might expect that faster printers are higher priced. Do the data support that notion? (As always, state relevant hypotheses, present a test statistic and p-value, and state your conclusion.) [20 points] Let the null hypothesis be that b (the coefficient of the true regression line of price on speed) is zero. The alternative is Ha: b>0. This is a one-tailed test. Intercept Speed Coefficients -745.480629 117.9173201 Standard Error 427.4955998 26.83196475 t Stat -1.743832286 4.394658432 P-value 0.119347079 0.002303147 The p-value reported in the output if for the 2-tailed alternative, so our p-value is half that. Our p-value is 0.00115. We reject H0 in favor of our Ha. (We guessed the correct tail. B-hat was positive….and consistent with our Ha.) The relationship between price and speed is statistically significant. d. One might also expect that printers positioned for corporate use are higher priced (on average) than those marketed for small office use. Use two different methods (t-test two sample and regression with a dummy variable) to test the relevant hypothesis. Be sure to state the hypotheses, give the test statistics, p-values and conclusions. The two methods should produce identical results. [20 points] First we do a t-test Two-Sample. The two samples are the four price for the small office printers and the four prices for the corporate printers. I did not even bother to put the data into two columns. In the “t-test two-sample” window I simply highlighted the first four, then the second four prices. t-Test: Two-Sample Assuming Equal Variances Mean Variance Observations Pooled Variance Hypothesized Mean Difference df t Stat P(T<=t) one-tail t Critical one-tail P(T<=t) two-tail t Critical two-tail Variable 1 339 13000 5 132956.85 Variable 2 1705.2 252913.7 5 0 8 -5.92418929 0.000176015 1.859548038 0.00035203 2.306004135 The t-stat is -5.9 and the one-tailed p-value is 0.00017. We reject H0 in favor of Ha. The difference in sample mean prices for the two kinds of printers is statistically significant. Next we use regression with a dummy variable. The conclusion will be identical. This makes this an academic exercise. I will comply…..I need the points. Name Minolta-QMS PagePro 1250W Brother HL-1850 Lexmark E320 Minolta-QMS PagePro 1250E HP Laserjet 1200 Xerox Phaser 4400/N Brother HL-2460N IBM Infoprint 1120n Lexmark W812 Oki Data B8300n Type Speed Price Dsmalloffice Small Office Small Office Small Office 12 10 12.2 199 499 299 1 1 1 Small Office Small Office Corporate Corporate Corporate Corporate Corporate 10.3 11.7 17.8 16.1 11.8 19.8 28.2 299 399 1850 1000 1387 2089 2200 1 1 0 0 0 0 0 ANOVA df Regression Residual Total Intercept Dsmalloffice 1 8 9 Coefficients 1705.2 -1366.2 SS 4666256.1 1063654.8 5729910.9 MS F 4666256.1 35.09601875 132956.85 Standard Error t Stat P-value 163.0686052 10.45694846 6.07462E-06 230.6138331 -5.92418929 0.00035203 Significance F 0.00035203 Lower 95% 1329.163122 -1897.996453 The p-value for our one-tail alternative is ½ of the p-value of 0.00035reported (in two places) in the regression output.