tugas peramalan
advertisement

TUGAS PERAMALAN
Anggota
1. Abid hasbiya
(M0108024)
2. Sofiin
(M0109062)
3. Livvia Paradisea S
(M0110050)
4. Moch. Arif hidayatullah
(M0110056)
5. Retno jati sahari
(M0110079)
12.
Paul Raymond, president of Washington Water Power, is worried about the possibility of a
takeover
attempt and the fact that the number of common shareholders has been
decreasing since 1983. He instruct you to study the number of common shareholders since
1968 and forecast for 1996. You decide to investigate three potential predictor variables:
earnings per share (common), dividends per share (common), and payout ratio. You collect
the data from 1968 to 1995 as shown in Table P-12.
a. Run these data on the computer and find the best prediction model.
b. Is serial correlation a problem in this model?
c. If serial correlation is a problem, write a memo to Paul that discusses various solutions
to the autocorrelation problem and includes your final recommendation.
Solution
Table P-12
Common
Earning Dividend Payou
Sharehold
s per
s per
t
ers
Share
Share
Ratio
Y
X1
X2
X3
1968
26472
1.68
1.21
1969
28770
1.7
1970
29681
1971
Year
Differenc Differenc
Difference
Differe
eY
e X1
X2
nce X3
72
*
*
*
*
1.28
73
2298
0.02
0.07
1
1.8
1.32
73
911
0.10
0.04
0
30481
1.86
1.36
72
800
0.06
0.04
-1
1972
30111
1.96
1.39
71
-370
0.10
0.03
-1
1973
31052
2.02
1.44
71
941
0.06
0.05
0
1974
30845
2.11
1.49
71
-207
0.09
0.05
0
1975
32012
2.42
1.53
63
1167
0.31
0.04
-8
1976
32846
2.79
1.65
55
834
0.37
0.12
-8
1977
32909
2.38
1.76
74
63
-0.41
0.11
19
1978
34593
2.95
1.94
61
1684
0.57
0.18
-13
1979
34359
2.78
2.08
75
-234
-0.17
0.14
14
1980
36161
2.33
2.16
93
1802
-0.45
0.08
18
1981
38892
3.29
2.28
69
2731
0.96
0.12
-24
1982
46278
3.17
2.4
76
7386
-0.12
0.12
7
1983
47672
3.02
2.48
82
1394
-0.15
0.08
6
1984
45462
2.46
2.48
101
-2210
-0.56
0.00
19
1985
45599
3.03
2.48
82
137
0.57
0.00
-19
1986
41368
2.06
2.48
120
-4231
-0.97
0.00
38
1987
38686
2.31
2.48
107
-2682
0.25
0.00
-13
1988
37072
2.54
2.48
98
-1614
0.23
0.00
-9
1989
36968
2.7
2.48
92
-104
0.16
0.00
-6
1990
34348
3.46
2.48
72
-2620
0.76
0.00
-20
1991
34058
2.68
2.48
93
-290
-0.78
0.00
21
1992
34375
2.74
2.48
91
317
0.06
0.00
-2
1993
33968
2.88
2.48
86
-407
0.14
0.00
-5
1994
34120
2.56
2.48
97
152
-0.32
0.00
11
1995
33138
2.82
2.48
88
-982
0.26
0
-9
a. With least square method using Minitab 16 software we get the model
Regression Analysis: Y versus X1, X2, X3
The regression equation is
Y = - 14502 + 15124 X1 - 11272 X2 + 430 X3
Predictor
Coef
SE Coef
T
P
-14502
33684
-0.43
0.671
X1
15124
14678
1.03
0.313
X2
-11272
19416
-0.58
0.567
X3
430.5
449.2
0.96
0.347
Constant
S = 3975.23
R-Sq = 54.1%
R-Sq(adj) = 48.3%
Analysis of Variance
Source
DF
SS
MS
F
P
Regression
3
446239155
148746385
Residual Error
24
379258158
15802423
Total
27
825497313
Source
DF
Seq SS
X1
1
263649350
X2
1
168075347
X3
1
14514459
9.41
0.000
Durbin-Watson statistic = 0.413926
\
From the result of Minitab we see the Durbin Watson Statistics 𝐷𝑊 = 0.413926
With an alpha 0.01, 𝑑𝐿 = 0.969 and 𝑑𝑈 = 1.414
Because the Durbin Watson statistics 𝐷𝑊 < 𝑑𝐿 , so the conclusion is there is a possitive
autocorrelation in model. We know that autocorrelation makes the model bad, so we
must solve the problem.
b. Yes, the problem is serial correlation.
c. We will try to difference the data and make autoregressive model to vanished the
autocorrelation.
1. Best Subset by Minitab
Best Subsets Regression: Y versus X1, X2, X3
Response is Y
Vars
1
1
1
2
2
2
3
R-Sq
51.7
31.9
18.9
53.4
52.3
52.0
54.1
R-Sq(adj)
49.9
29.3
15.8
49.7
48.5
48.2
48.3
Mallows
Cp
1.2
11.6
18.3
2.3
2.9
3.1
4.0
S
3915.0
4648.6
5073.4
3922.2
3968.7
3980.1
3975.2
X X X
1 2 3
X
X
X
X
X
X X
X X
X X X
The best model if variable independent just X2, dividens per share
2. Model Difference
Regression Analysis: C11 versus C12, C13, C14
The regression equation is
C11 = - 864 - 8484 C12 + 34640 C13 - 271 C14
27 cases used, 1 cases contain missing values
Predictor
Constant
C12
C13
C14
Coef
-863.7
-8484
34640
-270.9
S = 1661.68
SE Coef
427.9
4605
8332
138.6
T
-2.02
-1.84
4.16
-1.95
R-Sq = 46.7%
P
0.055
0.078
0.000
0.063
R-Sq(adj) = 39.7%
Analysis of Variance
Source
Regression
Residual Error
Total
Source
C12
C13
C14
DF
1
1
1
DF
3
23
26
SS
55632421
63506828
119139249
MS
18544140
2761166
F
6.72
P
0.002
Seq SS
4080932
41004363
10547126
Unusual Observations
Obs
15
19
20
C12
-0.120
-0.970
0.250
C11
7386
-4231
-2682
Fit
2415
-2927
536
SE Fit
636
1190
825
Residual
4971
-1304
-3218
St Resid
3.24R
-1.13 X
-2.23R
R denotes an observation with a large standardized residual.
X denotes an observation whose X value gives it large leverage.
Durbin-Watson statistic = 1.38324
Note: The Durbin Watson Statistics 𝐷𝑊 = 1.38324
With alpha 0.01 𝑑𝐿 = 1.20, 𝑑𝑈 = 1.41. The value 𝑫𝑾 < 𝒅𝑳 , so there is still possitive
correlation in the difference model. Now, we check the residual autocorrelations for the
first few lags.
From the plot ACF indicates that they are well within their two standard error limits(the dashed
lines in the figure) for the first few lags.
Conclusion : The serial Correlation has been eliminated and Raymond will use the fitted
equation for forecasting.
The final model:
y = - 864 - 8484 X1 + 34640 X2 - 271 X3
3. Transform the model into Ln
Regression Analysis: C22 versus C23, C24, C25
The regression equation is
C22 = - 0.0205 - 0.118 C23 + 1.21 C24 - 0.137 C25
27 cases used, 1 cases contain missing values
Predictor
Constant
C23
C24
C25
Coef
-0.02051
-0.1178
1.2081
-0.1371
S = 0.0457880
SE Coef
0.01214
0.3354
0.4220
0.3121
R-Sq = 36.7%
T
-1.69
-0.35
2.86
-0.44
P
0.105
0.729
0.009
0.665
R-Sq(adj) = 28.4%
Analysis of Variance
Source
Regression
Residual Error
Total
Source
C23
C24
C25
DF
1
1
1
DF
3
23
26
SS
0.027908
0.048221
0.076128
MS
0.009303
0.002097
F
4.44
P
0.013
Seq SS
0.002755
0.024748
0.000405
Unusual Observations
Obs
15
C23
-0.037
C22
0.17388
Fit
0.03258
SE Fit
0.01278
Residual
0.14129
St Resid
3.21R
R denotes an observation with a large standardized residual.
Durbin-Watson statistic = 1.53713
DW>Du, No Autocorrelation.
4. Model Autoregressive
Using software E-views we get the model autoregressive
Explanation:
Because we use lagged data so, we can’t using Durbin watson statistics to test the
autocorrelation. So, we must use Durbin Watson h.
h 1
d
2
N
1 - N Var 3
ℎ = (1 −
1.379333
27
)√
= −0.00412
2
1 − 27(−8466)
Conclusion for h statistics :
1. if h > 1,96 so there is possitive autocorrelation.
2. If h < -1,96 so there is possitive autocorrelation
3. If h-statistic between -1,96 dan +1,96 { -1,96 ≤ h ≤ 1,96 } , there is no autocorrelation
Because h-statistics between -1,96 and 1,96, so there is no autocorrelation.
Memo To Paul
1. For the best prediction you must using model difference, ln difference or model
autoregressive, because the model out of autocorrelation. It’s good to forecast.
2. The best model is Autoregressive model because the R-square adjusted up to 91 %, it
mean, 91 % variability can explained by the model.
3. The best model
𝒚 = −𝟏𝟖𝟓𝟓𝟏𝟔. 𝟐 − 𝟖𝟒𝟔𝟔𝑿𝟏 + 𝟑𝟒𝟕𝟗𝟕𝑿𝟐 − 𝟐𝟔𝟗. 𝟕𝑿𝟑 + 𝟎. 𝟗𝟗𝟓𝑨𝑹(𝟏)
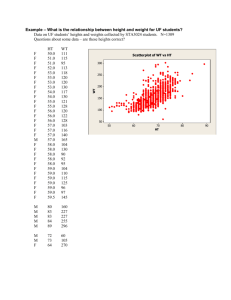
13. Thompson Airlines has determined that 5% of the total number of U.S. domestic airline
passengers fly on Thompson planes. You are given the task of forecasting the number of
passengers who will fly on Thompson Airlines in 2004. The data are presented in Table P13.
a.
Develop a time series regression model, using time as the independent variable and the
number of passengers as the dependent variable.
b.
Are the error terms for this model dipersed in a random manner?
c.
Transform the number-of-passengers variable so that the error terms will be randomly
dispersed.
d.
Run a computer program for the transformed model developed in part c.
e.
Are the error terms independent for the model run in part d.
f.
If the error terms are dependent, what problems are involved with using this model?
g.
Forecast the number of Thompson Airlines passengers for 2004.
Solutions:
Table P-13
Number of
Year
Passengers
Ln Year
Ln Passengers
(thousands)
Difference Ln
Difference Ln
Year
Passengers
1979
22.8
7.59035
3.12676
-
-
1980
26.1
7.59085
3.26194
0.0005052
0.135175
1981
29.4
7.59136
3.38099
0.0005049
0.119059
1982
34.5
7.59186
3.54096
0.0005047
0.159965
1983
37.6
7.59237
3.62700
0.0005044
0.086045
1984
40.3
7.59287
3.69635
0.0005042
0.069347
1985
39.5
7.59337
3.67630
0.0005039
-0.020051
1986
45.4
7.59388
3.81551
0.0005037
0.139211
1987
46.3
7.59438
3.83514
0.0005034
0.019630
1988
45.8
7.59488
3.82428
0.0005031
-0.010858
1989
48.0
7.59539
3.87120
0.0005029
0.046917
1990
54.6
7.59589
4.00003
0.0005026
0.128833
1991
61.9
7.59639
4.12552
0.0005024
0.125486
1992
69.9
7.59689
4.24707
0.0005021
0.121545
1993
79.9
7.59740
4.38078
0.0005019
0.133710
1994
96.3
7.59790
4.56747
0.0005016
0.186692
1995
109.0
7.59840
4.69135
0.0005014
0.123880
1996
116.0
7.59890
4.75359
0.0005011
0.062242
1997
117.2
7.59940
4.76388
0.0005009
0.010292
1998
124.9
7.59990
4.82751
0.0005006
0.063632
1999
136.6
7.60040
4.91706
0.0005004
0.089544
2000
144.8
7.60090
4.97535
0.0005001
0.058297
2001
147.9
7.60140
4.99654
0.0004999
0.021183
2002
150.1
7.60190
5.01130
0.0004996
0.014765
2003
151.9
7.60240
5.02322
0.0004994
0.011921
Regression Analysis: passengers versus Year
The regression equation is
passengers = - 11830 + 5.98 Year
Predictor
Constant
Year
Coef
-11829.7
5.9813
S = 11.0171
SE Coef
608.4
0.3056
R-Sq = 94.3%
T
-19.44
19.58
P
0.000
0.000
R-Sq(adj) = 94.1%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
1
23
24
SS
46509
2792
49300
MS
46509
121
F
383.18
Durbin-Watson statistic = 0.158667
a. Model:
passengers = - 11830 + 5.98 Year
P
0.000
b. Probability normal Plot
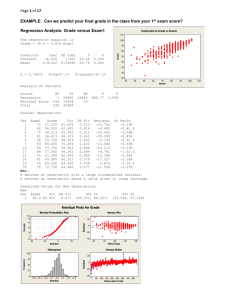
It looks that the residuals normal
The residual have the pattern, it looks have some trend. It is not random, so there is
autocorrelation. Error dependent.
So the error terms not dispersed in random manner.
c. We try to transform model to Ln.
Regression Analysis: C8 versus C7
The regression equation is
Ln y = - 5.21 + 10539 ln x
24 cases used, 1 cases contain missing values
Predictor
Constant
C7
Coef
-5.215
10539
S = 0.0564879
SE Coef
3.316
6603
T
-1.57
1.60
R-Sq = 10.4%
P
0.130
0.125
R-Sq(adj) = 6.3%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
1
22
23
Unusual Observations
SS
0.008130
0.070200
0.078329
MS
0.008130
0.003191
F
2.55
P
0.125
Obs
7
16
C7
0.000504
0.000502
C8
-0.0201
0.1867
Fit
0.0963
0.0723
SE Fit
0.0158
0.0123
Residual
-0.1163
0.1144
St Resid
-2.15R
2.07R
R denotes an observation with a large standardized residual.
Durbin-Watson statistic = 1.21315
With n=25, k=1, alpha=0.01, we get 𝑑𝐿 = 1.037, 𝑑𝑈 = 1.119. Because 𝐷𝑊 =
1.21315 > 1.119 the model effective to eliminate autocorrelation.
Versus Fits
(response is C8)
0.10
Residual
0.05
0.00
-0.05
-0.10
-0.15
0.05
0.06
0.07
0.08
Fitted Value
0.09
0.10
After we do regression difference ln y and difference ln x we get the random model.
Model Regression :
Difference ln y = - 5.21 + 10539 difference ln x
d. Have been done in part c
e. Yes the error independent, because there is no indicates autocorrelation
f. Because the error have been independent, so the question can’t be answered.
g. Forecast for 2004
0.11
ln 𝑦 = −5.21 + 10539 (𝑙𝑛2004 − 𝑙𝑛2003) + 𝑙𝑛151.9
= −5.21 + 10539(7.6029 − 7.6024) + 5.023
𝑦 = 𝑒 5.0825 = 𝟏𝟔𝟏. 𝟏𝟕𝟔
So, the forecast for 2004 is 161.176 thousands passengers