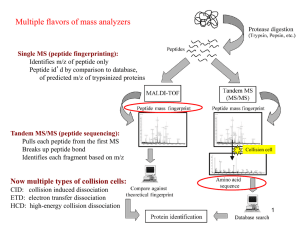
Supplementary Legends - Word file
advertisement

Supplementary figure 1. Isolated HeLa nucleoli are structurally intact and transcriptionally active. a, Detail of a transmission electron micrograph (TEM) of a HeLa cell, showing a nucleolus in situ, in which the three subnucleolar compartments, Fibrillar Center (FC), Dense Fibrillar Component (DFC) and Granular Component (GC) are visible. b, TEM and c, Field-emission scanning electron micrograph (FESEM) of the isolated HeLa nucleoli. d, In vitro transcription assay showing the isolated HeLa nucleoli (counterstained by Pyronin Y (Red)) incorporated Br-UTP (Green). e, Transcription sites (Green) in HeLa cells were labeled in vivo by 5-fluorouridine (5-FU) incorporation. f, Treatment of HeLa cells with actinomycin D (1 g/ml, 1 hr) completely abolished RNA synthesis, as shown by the absence of 5-FU incorporation. Bars: (a and b) 1m, (c to f) 5 m. Supplementary figure 2. Hierarchical clustering of 302 nucleolar proteins arranged by similarity in their response to Actinomycin D treatment. Clustering was based on the data from Suppl. Table 2 (5 and 9 time point experiment) showing fold change values for each protein after drug treatment. Red indicates proteins recruited to and green indicates proteins depleted from the nucleolus. Selected proteins illustrating the observed clustering of factors associated in stable complexes are marked in the rightmost column, i.e., the snRNP (SNRPA, SNRPD2, SNRPD3), Pol I subunits (POLR1A, POLR1D, POLR1B, POLR1C) and subunits of the exosome. Supplementary Table 1 The nucleolar proteome. Proteins from two separate nucleolar preparations from HeLa cells were separated by 1D gel electrophoresis. Each gel was divided into 16 gel slices and subjected to in-gel digested with trypsin or endoproteinase Lys-C. The resulting peptide mixtures (64 samples) were analysed by nano-scale liquid chromatography coupled to an LTQ-FT ICR mass spectrometer. The data was searched in the International Protein Index (IPI) database using stringent search criteria (see Methods). Sheet 1. “Proteome and Dynamics” Columns A & B give the protein accession numbers from the IPI database (‘Acc # IPI’) and the SwissProt accession number (‘Acc # SwissProt’), respectively. The IPI numbers are hyperlinked to corresponding 1 entries in an online nucleolar proteome database we have established while the Swiss Prot numbers are hyperlinked to the respective protein entries in the Swiss Prot database. Columns C-F) indicate which gel slice the peptide was identified in (C ‘Gel slice’), the calculated molecular mass of the protein (D-‘Protein mass’), the total number of unique peptide sequences identifying that protein (E- total number of unique peptides identified), Peptide link (F), and the protein name (G-‘protein name’), with the name colored in blue either if the protein is known from the literature to be nucleolar or if the protein is homologous to a known yeast nucleolar protein. Columns H-J give a functional classification of the protein as displayed in Fig. 1a, i.e., (G‘classification’), the homologues to yeast nucleolar proteins used in Fig. 1b (H-‘Yeast nucleolar homologues’) with hyperlinks to the Saccharomyces cerevisiae genome database (SGD), and finally names of yeast homologues (I-‘yeast gene name’). Note that all proteins were identified with at least two peptides. In cases of single peptides (indicated by an asterisk in column E), the same protein is identified with a different peptide in the quantitative experiments using the QSTAR instrument. To facilitate comparison of proteins identified with the corresponding lists of peptide data (see Sheet 2 below) we have provided a link tool on a floating palette. To use this tool first select an accession number in column F then click on the link tool on the palette. To return to the Proteome and Dynamics sheet click on the Tab at the bottom of the page. Supplementary Table 1 Sheet 2. Peptides. List of all peptides identified by MS for the characterization of the nucleolar proteome. Blue rows indicate each identified protein and its name. Uncolored rows are the corresponding peptides identifying that protein that were detected by MS analysis. Columns: A-IPI number, BTREMBL/SWISSPROT number C - C-protein name/peptide sequence, D- database hit score determined by the Mascot search engine (‘Peptide score’), E -the difference in score to the second best matching peptide sequence (‘delta score’), F- the charge state of the precursor that was fragmented (‘Charge’), G- the calculated, and H- measured peptide masses and I - their absolute difference in parts per million. The last four columns indicate which gel slice the peptide was identified in (J -‘Gel slice’), which enzyme was used in digestion (K‘Enzyme’) the total number of unique peptides for each protein (L- ‘# peptides’) and the added protein score (M- ‘Protein score’). Note that a peptide sequence is listed 2 once although several fragmentation spectra acquired may identify the same sequence. Typical cases include identical precursor ions generated by the two enzymes used, different charge states of the precursor ion, or different oxidation states of methionine containing peptides. Supplementary Table 2 Nucleolar proteome dynamics Three cell populations were labeled with Arg0, Arg6 and Arg10. The two latter populations where drug treated for various length of time before the cell populations where mixed in a 1:1:1 ratio and used for isolation of nucleolar proteins and quantitative analysis of tryptic peptides using a QSTAR mass spectrometer. The table represents data obtained from two independent experiments, a five time-point experiment using YFP-p68 HeLa cells (based on two nucleolar preparations), and a nine-time point experiment using HeLa cells (based on 4 nucleolar preparations). Sheet 1. Proteome and dynamics The three first columns show A- the accession number to the IPI database (Acc # IPI’), B- the protein name (‘Protein name’), and C- selected groups of proteins presented in Fig. 4a-j, where ‘Helic’ indicates helicases, ‘snRNP’ indicates small nuclear ribonucleoproteins, ‘SSU’ indicates homologues to the yeast small subunit processsome, ‘POL’ indicates polymerase I subunits, ‘RNaseP’ indicates ribonuclease P subunits, and ‘Exo’ indicates subunits of the exosome. Column D Peptide link. E-H, - the normalized fold change for the five time-point experiment, and I-P, normalized fold changes for the 9 time-point experiment. The fold change values for each protein are calculated from the corresponding peptide ratios in sheet 2 and sheet 3, for the 5 and 9 time-point experiments, respectively. To facilitate comparison of proteins with the corresponding lists of peptide ratio data (see Sheets 2&3 below) we have provided a link tool on a floating palette. To use this tool first select an accession number in column D then click on the link tool on the palette. To return to the Proteome and Dynamics sheet click on the Tab at the bottom of the page. (Note that Excel Macros need to be enabled for this feature to work.) The color scheme designates recruited proteins (red corresponds to proteins with positive normalized fold change values) and depleted proteins (green indicates proteins with negative normalized fold change values). The last 12 columns (Q-AB) provide standard deviation values for each protein, quantified by at least two peptides in the five time-point and the 9 time-point experiments. 3 Supplementary Table 2 Sheet 2. Peptides 5 time point Lists peptides quantified for the 5 time point experiments of actinomycin D treatment. Blue rows indicate each quantified protein and its name. Uncolored rows are the peptides quantifying that protein. Columns A & B give the IPI accession number (‘Acc # IPI’) and the amino acid sequences of the arginine containing peptide that were quantitated respectively. Column C gives the database hit score determined by the Mascot search engine (‘Peptide score’) where ‘insert’ refers to peptides for which a peptide ion signal was expected at that mass, charge state, and elution time from cross correlation of peptides between experiment 1 and 2. Additional columns: D indicates the difference in score to the second best matching peptide sequence (‘delta score’), E- the charge state of the precursor that was fragmented (‘Charge’), F -the calculated (‘Calc. mass’) and G- measured peptide masses (‘Meas. mass’) and H their absolute difference in parts per million, I - which gel slice the peptide was identified in (‘Gel slice’), and J- which experiments the peptide was analysed in (‘Exp #’), where experiment 1 represents 20 and 80 minutes of drug treatment, and experiment 2 represents 40 and 160 minutes of drug treatment. Columns K-N give the isotope ratios for peptides labeled with Arg 0, Arg 6 and Arg10 (see Methods). Note that non-arginine containing peptides supporting the identification of the proteins are not displayed. Supplementary Table 2 Sheet 3. Peptides 9 time point Lists peptides quantified for the 9 time point experiments of actinomycin D treatment. Blue rows indicate each quantified protein and its name. Uncolored rows are the peptides quantifying that protein. Columns A & B give the IPI accession number (‘Acc # IPI’) and the amino acid sequences of the arginine containing peptide that were quantitated respectively. Column C gives the database hit score determined by the Mascot search engine (‘Peptide score’) where ‘insert’ refers to peptides for which a peptide ion signal was expected at that mass, charge state, and elution time from cross correlation of peptides between experiment 1 and 2. Additional columns: D indicates the difference in score to the second best matching peptide sequence (‘delta score’), E- the charge state of the precursor that was fragmented (‘Charge’), F -the calculated (‘Calc. mass’) and G- measured peptide masses (‘Meas. mass’) and H their absolute difference in parts per million, I - which gel slice the peptide was 4 identified in (‘Gel slice’), and J- which experiments the peptide was analysed in (‘Exp #’), where experiment I represents 15 and 90 minutes of drug treatment, experiment 2 represents 30 and 120 minutes of drug treatment, experiment 3 represents 45 and 150 minutes of drug treatment, and experiment 4 represents 60 and 180 minutes of drug treatment. Columns K-R give the isotope ratios for peptides labeled with Arg 0, Arg 6 and Arg10. Note that non-arginine containing peptides supporting the identification of the proteins are not displayed. 5