Statistics and Skittles
advertisement

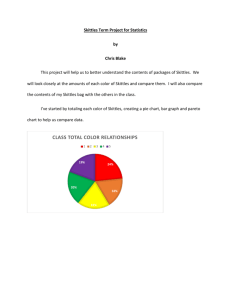
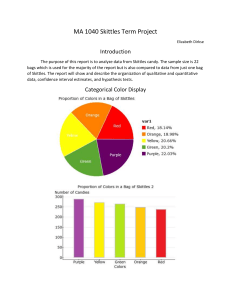
Jackson Caldwell Math 1040-014 Skittles project Statistics and Skittles Our statistics class at Salt Lake Community College, gathered data and use concepts that we were taught throughout the semester are putting it to use in a term project analyzing 21 2.17oz bags of skittles showing how statistics can be used in everyday life. Topics to be explored are categorical data, quantitative data, confidence intervals, and hypothesis tests. Organizing and Displaying Categorical Data: Colors The following chart shows the color and proportions of all the skittles involved. Skittles purple, 21.1% red, 20.0% red orange green, 19.9% orange, 19.0% yellow green purple yellow, 20.0% While looking at the pie and pareto charts demonstrating the class value of skittle color proportions I found it interesting to see that some of the colors were very comparable while my bag contained quite less green then the rest of the class. I had expected that the skittle colors would be more evenly distributed but I was wrong. Although my bag had fewer green skittles than most, it made up for the deficit in all the other colors. Pareto Chart Total 270 265 260 255 250 245 240 235 230 225 Sum of purple Sum of red Sum of yellow Sum of green Sum of orange My bag of Skittles: Total number of candies in sample = 61 Number of red candies Number of orange candies Number of yellow candies Number of green candies Number of purple candies 14 12 13 7 15 The total number of candies in the sample = 1252 The entire sample: Number of red candies Number of orange candies Number of yellow candies Number of green candies Number of purple candies 251 238 250 249 264 Proportion .200 .190 .200 .199 .211 Organizing and Displaying Quantitative Data: the number of candies per bag The total number of candies in your own single 2.17-ounce bag of Skittles = 61 The total number of bags in the sample collected by the entire class = 21 The total number of candies in the sample collected by the entire class =1252 For the entire sample: 𝑥̅ = 59.6 (the mean number of candies per bag rounded to 1 decimal place) s = 2.75 (the std. deviation of the number of candies per bag rounded to two decimal places) Candies Per Bag Frequency Histogram 10 9 Frequency 8 9 6 4 2 1 0 51-53 54-56 2 0 57-59 60-62 63-65 Skittles Per Bag 5- number summary: (round to one decimal place where necessary) Min: 51 51 Q1: 58 Median: 60 58 Q3: 61.5 60 61.5 Max: 64 64 While organizing and displaying quantitative data I noticed that the shape of the histogram was almost in a normal distribution. What causes the graph to not be a normal distribution is the gap created between 54-56 where no one in our class had a pack of skittles containing this number. The graphs did reflect what I expected to see and the data of the whole class does agree with mine. Also, the box plot shows the mean which was very similar to the number of candies in my bag of skittles. Reflection: Categorical Versus Quantitative Data To this point I have presented two types of data, categorical and quantitative. Categorical, also known as qualitative data, consists of names or labels not numbers or measurements. One example in our skittles data is the colors of the skittles. Charts used to represent categorical data include pie charts and pareto charts as seen before. Charts that wouldn’t make sense representing categorical data include box plots, frequency histograms, histograms, dotplots, and scatterplots because these all involve numbers not names or categories. Categorical data does not involve calculations. This data is used when shedding light upon certain data, like the average proportion of color in skittles. Quantitative, or numerical data, consist of numbers that represent numbers or measurements. Examples from the skittle data shown above are frequency histograms and boxplots. Other examples used for numerical data include stem and leaf plot, line graphs, scatterplots, and time series graphs. Graphs that wouldn’t make sense as numerical graphs are any graphs that talk about specific categories not involving numbers. Numerical data has numerous calculations. The main ones used in the skittles project, up to this point, include the mean, standard deviation, and the five number summary. As we continue to analyze the skittle data other numerical calculations will be shown. The importance of these calculations let us look deeper into statistics to make better inferences and conclusions. Confidence Interval Estimates A confidence interval is a range of values used to estimate the true value of a population parameter. A population parameter includes the proportion of a population, the mean of a population, and the standard deviation of a population. With a confidence interval also comes a confidence level, the probability that 1- alpha (such as .95) that the confidence interval does contain the population parameter, population mean, or the standard deviation of a population. Below are confidence intervals, one for the proportion, one for the mean, and one for the standard deviation. The following given decimals are the probability of the accuracy of the given interval. After constructing a 95% confidence interval estimate for the true proportion of purple candies I discovered that: .188 < p < .233. This statistic is 95 percent confident that this is the true proportion of purple candies per bag of 2.17-ounce skittles. After solving a 99% confidence interval for the true mean of the number of candies per bag of skittles I found that mean is: 57.893 < u < 61.307 This confidence inteval is 99% confident that all 2.17-ounce bags of skittles ever packaged contain a mean listed in the above interval. After formulating another confidence interval of 98% for the standard deviation in a 2.17-ounce bag of skittles I concluded that: 2.007 < o < 4.279 This confidence interval is 98% confident to hold the value of standard deviation of the number of skittles in every 2.17-ounce bag. See notes at end of paper to see calcultations. Hypothesis Tests In general a hypothesis is an educated guess about the explaination to a scientific question. In statistics a hypothesis has a little bit of a different meaning. Statistically a hypothesis is a claim or statement about a property of a population. A hypothesis test is a procedure for proven, a test never tries to prove the hypothesis it only fails to disprove it. Several components make up a hypothesis test, including the null and alternative hypothesis, the test stastic, the finding of the p-value or critical value, and the conclusion regarding a claim. Below are two claims to be tested, one about the amount of green skittles in a 2.17-ounce bag and another about the mean number of candies in a bag of skittles. Claim: 20% of skittle candies are green. See notes at the end of paper for calculations Conclusion: Fail to reject the null. There wasn’t sufficient enough evidence to warrant a rejection of the claim that 20% of skittles are green. The p-value is greater than the alpha value there for it fails to reject the null. Claim: The mean number of candies in a bag or skittles is 56. See notes at end of paper for calculations. Conclusion: Fail to reject the null hypothesis. There wasn’t sufficient enough evidence to warrant a rejection of the claim that the mean of skittles per bag is 56. The p-value is substantually bigger than the alpha value leading to a failure of rejection. Confidence Interval and Hypothesis Testing Conclusion Several conditions need to be met for these different calculations to be sucessful. For confidence intervals for the mean the sample must be a simple random sample and be normally distributed. The same goes for the population proportion and the standard deviation. One exception for the proportion is that if the sample isn’t normally distrubuted or that information is not given one can continue with their calculations if n>30. For hypothesis testing of a population proportion the requirements are similar to the confidence interval requirements listed above. The only difference is that the binomial distribution must also be satisfied, as well as meau equals np and sigma equals npq. The conditions for the hypothesis testing of a claim about the mean are the same as the confidence interval but if n> 30 this also satisfies the requirement of normal distribution. While working with skittles and performing certain calcultations I noticed that all of these requirements were met. If they failed to do so calculations could not be taken futher. This statistical project could be improved by having each student bring in their 2.17ounce bags of skittles to class to ensure that proper counting and proper reporting is done. Errors could have been made by counting a candy twice or not writing the correct number down when reporting colors. The conslusions that I have drawn are that 20% of skittles are green and that the mean of a bag of skittles can be claimed 56 according to the hypothesis test done above.