Elizabeth Dirkse Skittles

MA 1040 Skittles Term Project
Elizabeth Dirkse
Introduction
The purpose of this report is to analyze data from Skittles candy. The sample size is 22 bags which is used for the majority of the report but is also compared to data from just one bag of Skittles. The report will show and describe the organization of qualitative and quantitative data, confidence interval estimates, and hypothesis tests.
Categorical Color Display
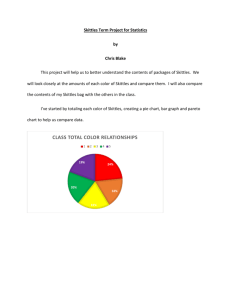
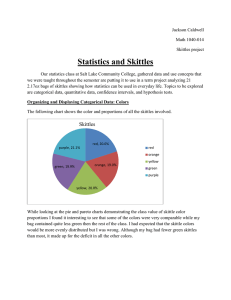
Categorical Color Display Observations
The data shows that each or the five colors represent approximately 1/5 th of the total number of candies. When looking at only the data from my one bag of candy, it seemed that there would be a higher number of yellow candies and lower number of orange. Before starting to organize the data, I wondered if it is more or less costly for Skittles to produce certain colors.
If that were the case I thought for sure that we would see uneven proportions of colors.
My Bag
Total Sample
Color Comparison: My Personal Skittles Bag vs. Total Sample
Red
.197
.181
Orange
.115
.19
Yellow
.279
.207
Green
.197
.202
Purple
.213
.22
Quantitative Data: Number of Candies
Mean= 59.6 Standard Deviation= 2.24
Five Number Summary=55, 58, 60, 62, 64
Number of Candies in My Bag: 61 Total Number of Bags in Sample: 22
Quantitative Data Observations
The frequency histogram has what we call a bell-shape curve (representing a normal distribution) while the boxplot is not skewed in either direction. Therefore, both the boxplot and frequency histogram that the shape of the data is approximately normal. In dealing with a bag of candy that is measured by weight and with each candy at approximately the same size, I figured that the number of candies in each bag would be controlled enough for the data to
have a normal distribution. As I had 61 candies in my bag of Skittles, this data does agree with my findings.
Reflection
In this first part of the Skittles project we have analyzed categorical and quantitative data. Categorical Data is qualitative and uses non-numerical categories like names and/or labels. Quantitative Data is numerical and involves numbers of totals, sums or amounts.
Histograms, scatterplots, and dotplots are used for quantitative data because they require numerical values. A histogram uses quantitative data and their frequencies, a scatterplot requires a pair of data (x,y), and dotplots require a list of numbers. Pie and pareto charts work best for qualitative data because they show proportions of a whole and decreasing frequencies for categorical data, respectively. Bar graphs are fairly similar to histograms but are specifically used for qualitative/categorical data. For categorical data, calculating sums and proportions of the whole make sense but measures of center and variation do not work as these need a list of numbers to calculate from.
Confidence Interval Estimates
A confidence interval is a range of values that is estimated to contain a population parameter. A confidence interval is expressed as a percentage and would read similar to, “we are 95% confident that the true population statistic lies between values X and Y.” The purpose of a confidence interval is to give an idea of how accurate an estimate may or may not be.
True Proportion of Yellow Candies x = 271 n = 1312 C-level = .99 Z “critical value”= 2.576
2.576*√ ((.2*.8)/1312 = .028 which is the E value p̂ = .207 is the best point estimate
.207-.028 = .179 .207+.028 = .253
Confidence Interval (.179, .253) or .179 < p < .253 x,ˉ = 59.636
True Mean Number of Candies per Bag
Sx = 2.237 n = 22 C-level .95%
95% Confidence Interval (58.645, 60.628) however, since we are dealing with whole candies the confidence interval would be (59, 60).
Standard Deviation of the Number of Candies per Bag
Variance/ s 2 = 5.004 DF = 21 σ = 2.237 98% Confidence
Chi-squared tail values: 8.897 & 38.932
√ ((21*5.004)/8.897 = 3.437 √ ((21*5.004)/38.932 = 1.643
Confidence interval (1.643, 3.437) or 1.643 < σ < 3.437
In calculating the true proportion of yellow candies, I used the total number of yellow candies and the total number of candies to find the point estimate of the sample proportion of yellow candies. The confidence interval calculated has a 5.7% range and contains .2. As yellow is one of five colors in the bag, if all the colors had an equal proportion of each bag that would be
.2 and fall within this 99% confidence Interval. The confidence interval is interpreted to be, “we are 99% confident that the population proportion of yellow candies per bag of skittles falls between .178 and .235.”
For the true mean number of candies per bag the confidence interval only contained two possible mean counts: 59 and 60. This shows that the mean number of candies per bag is fairly consistent in sample data. This is interpreted to be, “we are 95% confident that the mean number of candies per skittles bag will be between 58.645 (59) candies and 60.628 (60).” I have rounded the second value down instead of up because if I were to round up to 61, that value would no longer fall within the true confidence interval.
The standard deviation was a little tricky for me. In order to calculate this, I copied the data from the total number of candies per bag into StatCrunch. From there I used the raw data in calculating a variance 98% confidence interval. As the results were for the variance or σ², I simply took the square root of the values to obtain the standard deviation interval. This confidence interval is interpreted as, “we are 98% confident that the population standard deviation for the number of candies per bag is between 1.643 and 3.437 standard deviations from the mean.”
Hypothesis Tests
A hypothesis test is used to test a claim about some aspect of a population. In hypothesis testing, we use a null hypothesis (a parameter that is equal to some claimed value) and an alternative hypothesis (states that the parameter somehow differs from the null).
20% of all Skittles are Red
α = .05 p = .092 p̂ = .181 n = 1312
We are testing the null hypothesis of p = .2. The p-value (probability of getting a result at least as extreme) is .092. As the p-value is greater than the significance level we will fail to reject the null hypothesis and say that there is significant evidence to support the claim that the proportion of red candies of all Skittles is .2 or 20%.
Mean Number of Candies in a Bag of Skittles is 55
α = .01 HO μ = 55 p = 0 x,ˉ = 59.636 n = 1312
We are testing a null hypothesis of mean = 55 candies per bag. The p-value (probability of getting a result at least as extreme) is 0. As this is less than the significance level of .01, we reject the null hypothesis. There is sufficient evidence to support the alternative hypothesis that the mean number of candies per bag of Skittles is not 55.
Reflection: Testing Requirements
In using confidence intervals for estimating a population proportion, the sample must be a simple random sample, conditions for a binomial distribution must be satisfied, and there must be at least 5 successes and 5 failures. It does not seem that we have met the first requirement for a simple random sample as we have taken this sample via the convenience method; we are all in a statistics class at SLCC. This sample may not accurately represent the population. The other two conditions have been met; success = yellow and failure = not yellow and there are more than five of each of those two categories.
In using confidence intervals for estimating a population mean, the sample must be a simple random sample and the population must be normally distributed and/or n must be greater than 30. Again, we have not met the simple random sample requirement but the data is normally distributed so we met the second requirement.
In using confidence intervals for estimating a population standard deviation, the sample must be a simple random sample and the population must be normally distributed. Again, we have not met the first requirement but we have met the second.
For proportion hypothesis tests, the distribution must be normal and n*p must be greater than or equal to 5 and n*q must be greater than or equal to 5. In the first part of this project, we determined via the histogram that the distribution is approximately normal so we met that requirement. With n=22, p=.2, and q=.8, we failed the requirement of n*p as it is 4.4.
For mean hypothesis tests, the distribution must be normal and as we do not know the population standard deviation n must be greater than 30. As stated the distribution is normal but we failed the second requirement as n=22 with our data.