Least-Squares Regression Line
advertisement

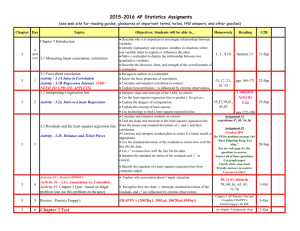
Section 3.2 Least – Squares Regression » summarize the relationship between two variables, but only in settings where one of the variables helps explain or predict the other (We must have an explanatory variable and a response variable.) » describe how a response variable y changes as an explanatory variable x changes » We often use a regression line to predict the value of y for a given value of x. Don’t you hate it when you open a can of soda and some of the contents spray out of the can? Two AP®Statistics students, Kerry and Danielle, wanted to investigate if tapping on a can of soda would reduce the amount of soda expelled after the can has been shaken. For their experiment, they vigorously shook 40 cans of soda and randomly assigned each can to be tapped for 0 seconds, 4 seconds, 8 seconds, or 12 seconds. Then, after opening the can and cleaning up the mess, the students measured the amount of soda left in each can (in ml). Here are the data and a scatterplot. The scatterplot shows a fairly strong, positive linear association between the amount of tapping time and the amount remaining in the can. The line on the plot is a regression line for predicting the amount remaining from the amount of tapping time. A regression lines is a model for the data and provides a compact mathematical description between the variables. For the soda example, the equation of the regression line is 𝑠𝑜𝑑𝑎 = 248.6 + 2.63(𝑡𝑎𝑝𝑝𝑖𝑛𝑔 𝑡𝑖𝑚𝑒). Identify the slope and y-intercept of the regression line. Interpret each value in context. We can use a regression line to predict the response 𝑦 for a specific value of the exploratory variable x. The accuracy of the prediction depends on how much the data scatter about the line. For the soda example, use the equation of the regression line to predict the amount of soda remaining after tapping on the can for 10 seconds. Extrapolation is the use of a regression line for prediction far outside the interval of values of the explanatory variable x used to obtain the line. Such predictions are often not accurate. Should we predict how much soda will be left over after 60 seconds of tapping? Try it! What do you find? Some data were collected on the weight of a male white laboratory rate for the first 25 weeks after its birth. A scatterplot of the weight (in grams) and time since birth (in weeks) shows a fairly strong, positive linear relationship. The linear regression equation 𝑤𝑒𝑖𝑔ℎ𝑡 = 100 + 40(𝑡𝑖𝑚𝑒) models the data fairly well. 1. What is the slope of the regression line? 2. What is the y-intercept? Explain its meaning in context. 3. Predict the rat’s weight after 16 weeks. 4. Should you use this line to predict the rat’s weight at age 2 years? (There are 454 grams in a pound.) In most cases, no line will pass exactly through all the points in a scatterplot. A good regression line makes the vertical distances of the points from the line as small as possible. Recall, the regression equation for “Tapping on Cans” is 𝑠𝑜𝑑𝑎 = 248.6 + 2.63(𝑡𝑎𝑝𝑝𝑖𝑛𝑔 𝑡𝑖𝑚𝑒). Find and interpret the residual for the can that was tapped for 4 seconds and had 260 ml of soda remaining. Different regression lines produce different residuals. The regression line we want is the one that minimizes the sum of the squared residuals. The least-squares regression line of y on x is the line that makes the sum of the squared residuals as small as possible. Find the value of each residual. What do you notice if you add them together? Where else have we seen this? We want the sum of squared of our residuals to be as small as possible!! 1. Enter your data into two lists. 2. Create a scatterplot. Describe what you see. (DOFS) 3. Find the equation of your leastsquares regression line. STAT -> CALC -> LinReg(a+bx) 4. To store your equation as a line: VARS -> Y-VARS -> Function: Y1 » Page 163 #27 – 32 (More review from 3-1) » Page 193 #35, 37, 39, 41, 43, 45, 47 Here is a scatterplot showing the tapping time and amount of soda remaining for the 40 cans. The least-squares regression line, 𝑠𝑜𝑑𝑎 = 248.6 + 2.63(𝑡𝑎𝑝𝑝𝑖𝑛𝑔 𝑡𝑖𝑚𝑒), is shown on the scatterplot. The point in red is for the can that was tapped for 8 seconds and had 255 ml remaining after it was opened. What is the residual for this point? Explain what the value means. A regression line describes the overall pattern of a linear relationship between two variables. We see departures from this pattern by looking at the residuals. The residuals for a least-squares regression line have a special property: the mean of the least squares residuals is always zero A residual plot is a scatterplot of the residuals against the explanatory variable. Residual plots help us assess how well a regression line fits the data. Here are the scatterplot and residual plot for the can tapping data. **Notice the horizontal axis is the same. **The “residual = 0” corresponds to the regression line. » The residual plot in effect turns the regression line horizontal and magnifies deviations so they are easier to see. » The scatterplot and residual plot show a nonlinear relationship. » When an obvious curved pattern exists in a residual plot, the model we are using is not appropriate. » When we use a line to model a linear association, there should only be a random scatter of points. (Consider the scatterplot and residual plot for price versus miles driven.) » Residuals look for what is left over when comparing the actual observation with the predicted value. 𝑦 − 𝑦 = 𝑜𝑏𝑠𝑒𝑟𝑣𝑒𝑑 − 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 » A residual plot looks at the form that is left when comparing the form of the association to the form of the regression model ˃ If there is a pattern, then the form of the two plots are not the same. The data below represents the years since 1995 and student enrollment. Based on the residual plot, is a linear model appropriate for these data? *Type your data into two lists. *Enter your residuals. [2ndStat] *Create a scatter plot with Explanatory variables and residuals The plots below are the scatterplot and residual plot for years since 1995 and student enrollment. What do you notice? An association can be clearly nonlinear and still have a correlation close to ±1. » Residuals show the amount of error for each observation. » To estimate the approximate size of a “typical” prediction error (residual), calculate the standard deviation of the residuals. 𝑠= 𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 2 = 𝑛−2 𝑦𝑖 − 𝑦 𝑛−2 2 For the can tapping data, the standard deviation of the residuals is 𝑠 = 951.536 40−2 = 5.00 𝑚𝐿. When we use the least-squares regression line to predict the amount of soda remaining using the amount of tapping time, our predictions will typically be off by about 5 ml. If all of the points fall directly on the least squares line, the sum of squared residuals is 0, which means 𝑟 2 = 1. This means all the variation in y is accounted for by the linear relationship with x. Suppose that we wandered in during the can tapping experiment and found a partially-full can. Without measuring the contents, how could we predict how much soda is left in the can? We don’t know how long it was tapped, so our best guess would be the mean amount remaining in all the cans: 𝑦 = 264.45 mL. When using 𝑦 as our predicted value, the sum of the squared prediction errors is 6506. The sum of the squared residuals when using the leastsquares regression line is 951.3. “ ______ % of the variation in (y variable) is accounted for by the linear relationship to the (x variable).” » They both help to answer the question, “How well does the line fit the data?” » S is measured in the same units as the response variable (y). » 𝑟 2 does not have units but is usually expressed as a percentage. » Report BOTH when you are assessing the fit of a line. In Section 3.1, we looked at the relationship between the 40-yard sprint time (in seconds) and the long-jump distance (in inches) for a small statistics class with 12 students. 1. Use your graphing calculators to create a scatterplot and find the least-squares regression line. 2. Find the value of 𝑟 2 . 3. Using your residuals, create a residual plot. 4. Find the value of s. A scatterplot with the least-squares regression line ( 𝑦 = 414.79 – 45.74x) and a residual plot are shown below. Also, s = 22.38 and 𝑟 2 = 0.702. (a) Calculate and interpret the residual for Christian, who had a sprint time of 7.25 seconds and a long jump of 110 inches. (b) Is a linear model appropriate for these data? Explain. (c) Interpret the value of s. (d) Interpret the value of 𝑟 2 . Section 3-2: Page 193 #48, 49, 50, 51, 55, 58 Many people believe that students learn better if they sit closer to the front of the classroom. Does sitting closer cause higher achievement, or do better students simply choose to sit in the front? To investigate, an AP®Statistics teacher randomly assigned students to seat locations in his classroom for a particular chapter. At the end of the chapter, he recorded the row number (row 1 is closest to the front) and test score for each student. Least-squares regression was performed on the data. A scatterplot with the regression line added, a residual plot, and some computer output from the regression are shown. (a) What is the equation of the leastsquares regression line that describes the relationship between row number and test score? Define any variables that you use. (b) Interpret the slope of the regression line in context. (c) Find the correlation. (d) Is a line an appropriate model to use for these data? Explain how you know. It is also possible to calculate the equation of the leastsquares regression line using only the means and standard deviations of the two variables and their correlation. Both formulas are on the AP Test formula sheet!! In the previous example, we investigated the relationship between test scores and seat location. The mean and standard deviation of the row numbers are 𝑥 = 4.033 and 𝑠𝑥 = 1.974. The mean and standard deviation of the test scores are 𝑦 = 81.2 and s𝑦 = 10.135. The correlation between row number and test score is r = –0.218. (Note that this value is slightly different than the previous example because of rounding in the computer output.) Find the equation of the least-squares regression line for predicting test score from row number. Show your work. Netbooks are a hybrid of a laptop computer and a tablet. They are smaller and have better battery life than a traditional laptop. They also have a separate keyboard, unlike most tablets. Consumer Reports did a study of 22 netbooks in their February 2010 issue. Among the variables measured were battery life (hours), weight (pounds), and cost. The data appear in the table. Should we use a linear model to predict battery life of a new netbook based on its weight? If so, how accurate will our predictions be? 1. The distinction between explanatory and response variables is important in regression. 2. Correlation and regression lines describe only linear relationships. 3. Correlation and least-squares regression lines are not resistant. An outlier is an observation that lies outside the overall pattern of the other observations. Points that are outliers in the y direction but not the x direction of a scatterplot have large residuals. Other outliers may not have large residuals. An observation is influential for a statistical calculation if removing it would markedly change the result of the calculation. Points that are outliers in the x direction of a scatterplot are often influential for the least-squares regression line. 4. Association does not imply causation. (Use common sense when drawing conclusions.) Example – Does committing more turnovers lead to more points? In the NBA, there is a strong positive association between the number of turnovers a player has and the number of points that he scores. A turnover is when a player loses the ball to the other team. Could a player increase his point totals by turning the ball over more frequently? No! Turning the ball over to the other team doesn’t cause a player to score more points. Instead, there is another variable that influences both turnovers and points: playing time. Players who are on the court more often tend to score more points and have more turnovers than players who don’t get much playing time. In the chapter-opening Case Study (page 141), the Starnes family had just missed seeing Old Faithful erupt. They wondered how long it would be until the next eruption. The scatterplot below shows data on the duration (in minutes) and the interval of time until the next eruption (also in minutes) for each Old Faithful eruption in the month before the eruption. Answer all of the questions on page 191 and turn them in. Section 3-2: Page 193 #59, 61, 63, 65, 69, 71 – 78