protein
advertisement

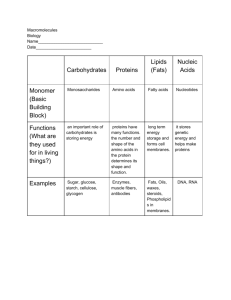
Chapter 4: Protein Structure and Folding Life … is a relationship between molecules. Linus Pauling, as quoted in T. Hager, Force of Nature: The Life of Linus Pauling (1997), p. 542 4.1 Introduction • Proteins are found in all living systems, ranging from bacteria and archaea through the unicellular eukaryotes, to plants, fungi, and animals. • In all life forms, proteins are made up of the same building blocks―amino acids. • Each cell contains thousands of different genes and makes thousands of different proteins. What is a gene? • In the late 1930s… “A molecule of living stuff made up of many atoms held together.” What is a gene? • A specific stretch of nucleotides in DNA (or in some viruses, RNA) that contains information for making a particular RNA molecule that in most cases is used to make a particular protein. 4.2 Primary structure: amino acids and the genetic code The 22 amino acids found in proteins • Proteins are chain-like polymers of amino acids specified by the genetic code. • Each amino acid has an amino group (NH3+) and a carboxyl group (COO) attached to a central carbon called the -carbon. • The only difference between two amino acids is in their different side chain or “R group.” • At pH 7 the amino and carboxyl groups of amino acids are charged. • Over a pH range from 1 to 14 these groups exhibit binding and dissociation of a proton. • The weak acid-base behavior of amino acids provides the basis for many techniques for amino acid identification and protein separations. Protein primary structure • Amino acids joined together by peptide bonds form the primary structure of a protein. • The amino group of one molecule reacts with the carboxyl group of the other in a condensation reaction. • When joined in a series of peptide bonds, amino acids are called residues. • A short sequence of amino acids is called a peptide; the term polypeptide applies to longer chains of amino acids. • The arrangement of amino acids, with their distinct side chains, gives each protein its characteristic structure and function. • The peptide bond has a partial double bond character as a result of resonance. • Free rotation occurs only between the -carbon and the peptide unit. • Trans and cis-configurations are possible about the rigid peptide bond. • The peptide chain is flexible, but it is more rigid than it would be if there were free rotation about all of the bonds. Translating the genetic code • How is the genetic code translated into a specific sequence of amino acids? • The mechanism of translation is described in detail in Chapter 14. • A DNA sequence is read in triplets using the antisense (non-coding) strand as a template that directs synthesis of RNA via complementary base pairing. • An open reading frame (ORF) in the mRNA indicates the presence of a start codon followed by codons for a series of amino acids and ending with a termination codon. The genetic code • Each “codon box” is composed of four threeletter codes, 64 in all. • 61 codons are recognized by tRNAs for the incorporation of the 20 common amino acids. • 3 codons signal termination, or code for selenocysteine and pyrrolysine. The genetic code is degenerate • tRNAs specific to a particular amino acid recognize multiple codon triplets that differ only in the third letter. e.g. leucine is coded for by 6 different codons, while methionine has only one codon The “wobble hypothesis” • Pairing between codon and anticodon at the first two codon positions always follows the usual rule of complementary base pairing. • Exceptional “wobbles” (non-Watson-Crick base pairing) can occur at the third position. The genetic code is not universal • In certain organisms and organelles the meaning of select codons has been changed. e.g. Tetrahymena reads UAA and UAG as glutamine (Gln) The 21st and 22nd genetically encoded amino acids The UGA code for selenocysteine is found in: • >15 genes in prokaryotes that are involved in redox reactions. • >40 genes in eukaryotes that code for various antioxidants and the type I iodothyronine deiodinase. The UAG code for pyrrolysine has been found in: • a few archaebacteria and eubacteria. Modified nucleotides and codon bias • “Wobbles” can occur at the third position. • When bases in the anticodon are modified, further pairing patterns are possible. • Examples: Inosine can pair with U, C, and A. 2-thiouracil restricts pairing to A alone. Implications of codon bias for molecular biologists • The frequencies with which different codons are used vary significantly between different organisms and between proteins expressed at high or low levels within the same organism. • Expression of functional proteins in heterologous hosts is a cornerstone of molecular biology research. • Codon bias can have a major impact on the efficiency of expression of proteins if they contain codons that are rarely used in the desired host. • What might happen if you tried to express a Tetrahymena gene that encodes a glutamine-rich protein in E. coli? D- and L-amino acids in nature • D- and L-amino acids are enantiomers (sterioisomers that are mirror images of each other). • Living organisms are composed predominantly of L-amino acids. • Ribosomes only use L-amino acids to make proteins. Exceptions: • D-amino acids are found in some peptides in microorganisms, but are synthesized by pathways that do not involve the ribosome. • D-amino acids are present in some peptides in other organisms, but are made from the genetically encoded L-amino acids by a post-translational process. Examples: • D-amino acids are present in the venom of some bivalves, snails, spiders, amphibians, and the duck-bill platypus. • The presence of D-amino acids is linked to more potent venom. 4.3 The three-dimensional structure of proteins • There is tremendous variation in the size and complexity of proteins. • Dalton (Da) units are typically used to describe the molecular weight of proteins. • Typical polypeptide chains have molecular weights of 20 to 70 kDa (20,000 to 70,000 Da). • The average molecular weight of an amino acid is 110. • A typical polypeptide chain thus contains 181 to 636 amino acids. Secondary structure • Interactions of amino acids with their neighbors gives a protein its secondary structure. • Primarily stabilized by hydrogen bonds. • Also depends on disulfide bridges, van der Waals interactions, hydrophobic contacts, and electrostatic interactions. The three basic elements of protein secondary structure • -helix • -pleated sheet • Unstructured turns -helix • Most common structural motif in proteins. • Tight helical structure stabilized by hydrogen bonding among near-neighbor amino acids. • Proline, the “helix-breaking residue”, cannot participate as a donor in hydrogen bonding. -pleated sheet • Extended amino acids chains packed side by side to create a pleated, accordian-like appearance. • Stabilized by hydrogen bonding. Parallel structure • Two segments of a polypeptide chain (or two individual polypeptides) are aligned in the Nterminal to C-terminal direction or vice versa. Antiparallel structure • One segment is N-terminal to C-terminal and the other is C-terminal to N-terminal. Unstructured turns • “Turns” connect the -helices and pleated sheets in proteins. • Relatively short loops that do not exhibit a defined secondary structure. Tertiary structure • The folded three-dimensional shape of a polypeptide. • Most interactions are stabilized by noncovalent bonds: Hydrophobic interactions Hydrogen bonds • The principle covalent bonds within and between polypeptides are disulfide (S-S) bonds or “bridges” between cysteines. Three main categories of tertiary structure • Globular proteins • Fibrous proteins • Membrane proteins Globular proteins • The overall shape of most proteins is roughly spherical. e.g. the enzyme lysozyme folds up into a globular tertiary structure forming the active site. Fibrous proteins • Long filamentous or “rod-like” structures. • Structural components of cells and tissues. • A number of major designs: - triple helical arrangement - “coiled coils” - antiparallel -pleated sheets Membrane proteins • Differ from soluble proteins in the relative distribution of hydrophobic amino acid residues. • The seven transmembrane helix structure is a common motif in membrane proteins. Prediction of protein structure • By comparing the sequences of proteins of unknown structure with those that have been determined, it is often possible to make structural predictions based on identified similarity. Quaternary structure • A functional protein can be composed of one or more polypeptide subunits. • Can be identical or nonidentical subunits. • Stabilizing bonds are the same as those for tertiary structure. • Quaternary structure allows greater versatility of function. • Catalytic or binding sites are often formed at the interface between subunits. e.g. the two and two subunits in hemoglobin form a binding site for a heme group 4.4 Protein function and regulation of activity • Proteins larger than about 20 kDa are often formed from two or more domains with specific functions. • A single domain is usually formed from a continuous amino acid sequence. e.g. DNA-binding domain • Domains can contain common structuralfunctional motifs. • Proteins have a diversity of functions in cells. • One vital role of proteins is to serve as enzymes that catalyze the hundreds of chemical reactions necessary for life. Enzymes are biological catalysts • Enzymes lower the activation energies of the chemical groups that participate in a reaction and thereby speed up the reaction. • The substrate forms a tight complex with the enzyme by binding to a region called the active site. • Most enzymes act through an induced-fit mechanism. Example: • Lysozyme catalyzes the breakdown of polysaccharides from the E. coli peptidoglycan layer. • The active site is a long, deep cleft that can bind six N-acetylglucosamine (NAG) and Nacetylmuramic acid (NAM) units. • Lysozyme brings the reacting species together in a geometry that favors reaction. • For the fourth NAG-NAM unit to fit in the active site, it must be distorted, and forms a less stable conformation. • Asp 52 and Glu35 residues of lysozyme interact with the fourth and fifth NAG-NAM units, breaking the C-O bond between them by hydrolysis. Regulation of protein activity by post-translational modifications The functional activity of proteins can be regulated at several different levels: •Transcription •RNA processing •Translation •Post-translational modifications, such as phosphorylation and allosteric effectors • After translation, proteins are joined covalently and noncovalently to other molecules. e.g. lipoproteins, glycoproteins, metalloproteins • The most common regulatory mechanism is the reversible phosphorylation of amino acid side chains. Protein phosphorylation • May cause a protein to change shape and unmask or mask a catalytic or functional domain. • Phosphorylated side chain may be part of a binding motif to facilitate formation of a multiprotein complex. • Phosphorylated side chain may promote dissociation of a multiprotein complex. Kinases • Catalyze the addition of phosphate groups. • Tend to be very specific, acting on very few substrates. • Two protein kinase groups have been widely studied in eukaryotes: 1. Those that phosphorylate serine or threonine side chains. 2. Those that phosphorylate tyrosine side chains. Phosphatases • Remove phosphates. • Tend to be less specific, acting on many substrates. Allosteric regulation of protein activity • Ligand-induced conformational change. • An active site or another binding site is altered in a way that increases or decreases its activity. Example: • Cyclin-dependent kinase (CDK) activity is regulated by both allosteric modification and phosphorylation. Inactive conformation of CDK • The T loop is located at the entrance to the active site. • Polypeptide substrates are blocked from gaining access to the ATP molecule in the active site. • A critical glutamate residue in the PSTAIRE helix is held at a distance from the active site. Partial activation of CDK • Binding of cyclin to CDK induces a conformational change. • T loop moves away from the entrance of the active site. • Critical glutamate in PSTAIRE helix moves into active site. Full activation of CDK • Phosphorylation of Thr160 in T loop by CDK-activating kinase (CAK). • Stabilizes active site “catalytic cleft.” Macromolecular assemblages • Expression of the genetic information relies on the sequential action of large and dynamic macromolecular assemblages or “molecular machines.” 4.5 Protein folding and misfolding • In some cases, protein folding is initiated before the completion of protein synthesis. • Other proteins undergo major folding after release into the cytoplasm or a specific organelle. • Most proteins require “molecular chaperones” to fold properly in vivo. Molecular chaperones • Increase the efficiency of protein folding. • Reduce the probability of competing reactions such as aggregation. • Aid in the destruction of misfolded proteins. • Typically ATP-dependent. • Heat-shock proteins promote protein folding and aid in the destruction of misfolded protein. e.g. Hsp40, Hsp70, Hsp90 • Hsp90 mediates protein folding by undergoing major shape changes upon binding and hydrolysis of ATP and interaction with p23. Endoplasmic reticulum “quality control” • Secreted proteins are translocated into the endoplasmic reticulum (ER). • Folding takes place before secretion through the Golgi apparatus. • Folding catalysts accelerate potentially slow steps in the folding process e.g. peptidylprolyl and protein disulfide isomerases • Incorrectly folded proteins are detected by the “unfolded protein response” and targeted for degradation. Ubiquitin-mediated protein degradation • Ubiquitin (a 76 amino acid polypeptide) is attached to a protein by a series of enzymemediated reactions. • The ubiquitin-conjugated protein is then targeted to the 26S proteasome. • Ubiquitin is released and the target protein is degraded by proteases. Protein misfolding diseases • Formation of protein aggregates is linked to at least 20 different human diseases. • Normally soluble proteins accumulate as insoluble deposits known as amyloid or amyloid-like fibrils. • Proteins in amyloid-like fibrils fold into a cross -spine. Prions The primary cause of transmissible spongiform encephalopathies (TSEs). •Progressive neurodegeneration. •Dementia. •Loss of muscle control of voluntary movements. •Once symptoms appear, death results in 6 months to 1 year. •There is no cure. Human forms of prion disease • • • • Kuru Creutzfeldt-Jakob disease Gerstmann-Straussler syndrome Fatal familial insomnia Animal forms • Scrapie (sheep) • Bovine spongiform encephalopathy (BSE: “mad cow disease”) • Chronic wasting disease (elk and deer) The “prion only” hypothesis of infection • Stanley Prusiner: Nobel Prize in 1997. • Lack of immune response characteristic of infectious diseases. • Long incubation time (up to 40 years for kuru). • Resistance of the infectious agent to radiation that destroys living microorganisms (e.g. viruses, bacteria). • The infectious agent is not a living organism but a protein called PrPSc with the unusual ability to replicate itself within the body. • The prion PrPSc has the same amino acid sequence as the normal host protein PrPC. • But, the prion is misfolded into a different 3-D structure. After misfolding the prion protein becomes… • Aggregated (brain plaques). • Protease resistant. • Infectious. • Able to survive standard sterilization techniques. Normal cell • The normal cellular protein PrPC is a cell surface protein expressed in neurons. Infected cell • Host protein PrPC is misfolded to form new prions called PrPSc. • Formation of fibrils, aggregates, and amyloid plaques. Human sporadic transmissible spongiform encephalopathies • PrPC misfolds spontaneously and generates more prions by “autoinfection” Creutzfeldt-Jakob disease (CJD) • Preventative action? None – frequency of one in a million. Human inherited transmissible spongiform encephalopathies • Mutated PrPC gene with greater tendency to spontaneously misfold to prion form. Gerstmann-Straussler syndrome Fatal familial insomnia • Preventative action? None – 100% likelihood of disease progression. Human infectious transmissible spongiform encephalopathies • Eating brains or infected meat products Kuru: former ritualistic cannibalism in Papua New Guinea New variant CJD: consumption of tainted beef • Preventative action? Don’t eat contaminated meat products. Pathway from infection to disease • Penetration • Translocation • Multiplication • Pathogenesis