Day1-Intro-to
advertisement

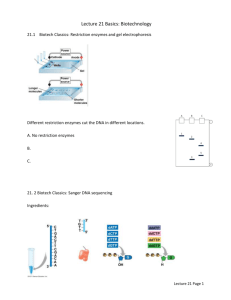
Introduction to Next Generation Sequencing Overview • Day 1: AM - Basic biology recap and Intro to NGS • Day 1: PM - Intro to Data Analysis – Format(s), Quality checking, Trimming • Day 2: AM - General procedures and strategies in NGS • Day 2: PM - Exome sequence analysis practical (Galaxy) • Day 3: AM - Introduction to RNA-Seq (and a touch of miRNA-Seq) • Day 3: PM - RNA-Seq practical (Tophat + Cuffdiff pipeline on Galaxy) Note: practical write-ups = assessment assignment Overview • Day 4: AM – NGS in the wild (case studies) – Clinical genomics – Human microbiome • Day 4: PM - Candidate filtering and prioritization – Mostly SNP based – Little bit of functional and pathway enrichment analysis • Day 5: AM - Knowledge-driven methods for finding ‘causative’ genes & wrap-up • Day 5: PM – Free or wrap up practical Next Generation Sequencing Day 1: Introduction Full genome sequencing Day 1 - Overview • Central Dogma Review • History of DNA Sequencing • First Generation (Sanger) Sequencing • Next Generation Sequencing Introduction • NGS Opportunities and Challenges • NGS Applications • NGS Study Design and Technology Choice History 1866 Gregor Mendel published the results of his investigations of the inheritance of "factors" in pea plants. DNA was first isolated by the Swiss physician Friedrich Miescher in 1869. 1950's • Maurice Wilkins (19162004), Rosalind Franklin (1920-1957), Francis Crick (1916-2004) and James Watson (1928- ) discover chemical structure of DNA • Starts a new branch of science - molecular biology. The Central Dogma of Molecular Biology Reverse Transcription 10 Structure of the DNA molecule • DNA is shaped like a double helix • It is like a spiral staircase • Another way to think of it is a twisted ladder 11 Connecting the DNA molecule • Rails of the DNA ladder are alternating sugar & phosphates • Rungs are composed of pairs of bases – A bonds with T – G bonds with C 12 Connecting the DNA molecule • The two strands of DNA are different • One is called the sense strand and it is the plan to make a protein • The other strand is the antisense strand 13 Connecting the DNA molecule • The two strands of DNA are said to be antiparallel antisense • The other strand is oriented in the opposite 3’ to 5’ direction sense • One strand is oriented in a 5’ to 3’ direction 5’ 3’ 3’ 5’ 14 Replication of DNA 15 DNA sequencing exploits the physicochemical properties of DNA and the enzymes involved in its replication (more later…) Introns and Exons • Introns – non-coding sequences in the DNA that are NOT used to make to make a protein • Exons – coding sequences in the DNA that are expressed or used to make mRNA and ultimately are used to make a protein 17 Introns and Exons 18 Transcription 19 Transcription 20 Translation 21 Sanger Method Fred Sanger, 1958 Was originally a protein chemist Made his first mark in sequencing proteins Made his second mark in sequencing RNA 1980 dideoxy sequencing Sanger Method: Dideoxy Chain Termination 300-500 bases Capillary Method - Fluorescent Dyes 800-1000 bases Automated Sequencing – Leroy Hood developed fluorescent color labels for the 4 terminator nucleotide bases (late 80s). – This allowed all 4 bases to be sequenced in a single reaction and sorted in a single gel lane. – Hood also pioneered direct data collection by computer – Improvements in this technology now enabled sequencing of billion base genomes in < 1 year. • Automated sequencing machines use 4 colors, so they can read all 4 bases at once. Genome Sequencing TG..GT TC..CC AC..GC CG..CA TT..TC TG..AC AC..GC GA..GC CT..TG AC..GC GT..GC AC..GC AA..GC AT..AT TT..CC Genome Short fragments of DNA ACGTGGTAA CGTATACAC TAGGCCATA GTAATGGCG CACCCTTAG TGGCGTATA CATA… ACGTGGTAATGGCGTATACACCCTTAGGCCATA Short DNA sequences ACGTGACCGGTACTGGTAACGTACA CCTACGTGACCGGTACTGGTAACGT ACGCCTACGTGACCGGTACTGGTAA CGTATACACGTGACCGGTACTGGTA ACGTACACCTACGTGACCGGTACTG GTAACGTACGCCTACGTGACCGGTA CTGGTAACGTATACCTCT... Sequenced genome 28 28 -2001 The HGP consortium publishes its working draft in Nature (15 February), and Celera publishes its draft in Science (16 February). Sequencing the Human Genome 2001: Human Genome Project 2.7G$, 11 years Log10(price) 10 8 6 2007: 454 1M$, 3 months 2008: ABI SOLiD 60K$, 2 weeks 2001: Celera 100M$, 3 years 4 2009: Illumina, Helicos 40-50K$ 2 2000 2010: 5K$, a few days? 2012: 100$, <24 hrs? 2005 Year 2010 30 Sequence Database Size Exponential Data Increase Year NAR. 2007 September; 35(18): 6227–6237. Adapted from Eric Green, NIH; Adapted from Messing & Llaca, PNAS (1998) History of DNA Sequencing 1870 Miescher: Discovers DNA 1940 Avery: Proposes DNA as ‘Genetic Material’ Efficiency (bp/person/year) 1953 Watson & Crick: Double Helix Structure of DNA 1 1965 Holley: Sequences Yeast tRNAAla 1970 Wu: Sequences Cohesive End DNA 1977 Sanger: Dideoxy Chain Termination Gilbert: Chemical Degradation 1980 Messing: M13 Cloning 1986 Hood et al.: Partial Automation 15 150 1,500 15,000 25,000 50,000 1990 • Cycle Sequencing • Improved Sequencing Enzymes • Improved Fluorescent Detection Schemes 200,000 50,000,000 100,000,000,000 2002 2008 • Next Generation Sequencing •Improved enzymes and chemistry •Improved image processing Sanger vs NGS • ‘Sanger sequencing’ has been the only DNA sequencing method for 30 years but… • …hunger for even greater sequencing throughput, at lower cost • NGS has the ability to process millions of sequence reads in parallel rather than 96 at a time (at a small fraction of the cost) Next Generation Sequencing: Why Now? • Motivation: HGP and its derivatives, personalized medicine • Short reads applications: (re-)sequencing, other methods (e.g. gene expression) • Advancements in technology 34 “Paradigm Shift” • Standard ABI “Sanger” sequencing – 96 samples/day – Read length ~650 bp = 450,000 bases • 454 was the game changer! – ~400,000 different templates (reads)/day – Read length ~250 bp – Total = 100,000,000 bases of sequence data!!! Solexa ups the Game • Solexa (Illumina GA) – 60,000,000 different sequence templates (yes that is an insane 60 million reads) – 36 bp read length (much longer now) – 4 billion bases of DNA per run (3 days) Next Generation Sequencing • 454 Life Sciences/Roche – Genome Sequencer FLX: currently produces 400-600 million bases per day per machine – Published 1 million bases of Neanderthal DNA in 2006 – May 2007 published complete genome of James Watson (3.2 billion bases ~20x coverage) • Solexa/Illumina – 10 GB per machine/week – May 2008 published complete genomes for 3 hapmap subjects (14x coverage) • ABI SOLID – 20 GB per machine/week Nanotechnology • Each system works differently, but they are all based on a similar principals: 1. 2. 3. 4. Shear target DNA into small pieces bind individual DNA molecules to a solid surface, amplify each molecule into a cluster copy one base at a time and detect different signals for A, C, T, & G bases 5. requires very precise high-resolution imaging of tiny features • (Solexa has 800 images @ 4 megapixels each) Sequencing by Synthesis (SBS) Problem: Huge Amount of Image Data • Raw image data huge: 1-2 TB for the Solexa, more for ABI-SOLID, less for 454 • The images are immediately processed into intensity data (spots w/ location and brightness) • Intensity data is then processed into basecalls (A, C, T, or G plus a quality score for each) • Basecall data is on the order of 5-10 GB per run (or a week of runs for 454) From John McPherson, OICR Next-gen sequencers 100 Gb AB/SOLiDv3, Illumina/GAII short-read sequencers (10+Gb in 50-100 bp reads, >100M reads, 4-8 days) bases per machine run 10 Gb 454 GS FLX pyrosequencer 1 Gb (100-500 Mb in 100-400 bp reads, 0.5-1M reads, 5-10 hours) 100 Mb ABI capillary sequencer (0.04-0.08 Mb in 450-800 bp reads, 96 reads, 1-3 hours) 10 Mb 1 Mb 10 bp 100 bp read length 1,000 bp Adapted from John McPherson, OICR 2009/10 AB SOLiDv3 120Gb, 100 bp reads 100 Gb Illumina HiSeq 100Gb, 150bp reads bases per machine run 10 Gb 1 Gb 454 GS FLX Titanium 0.4-0.6 Gb, 100-400 bp reads 100 Mb 10 Mb ABI capillary sequencer (0.04-0.08 Mb, 450-800 bp reads 1 Mb 10 bp 100 bp read length 1,000 bp Stein Genome Biology 2010 11:207 Storage is becoming a real problem Kahn, 2011, Science Lower Cost = More Innovation • As sequencing becomes cheaper, more investigators can use it for routine assays • Leads to variations and absolutely novel applications Lower Cost = More samples • More patients in GWAS studies • More replicates (or the use of some replicates and statistical approaches) in all other assays Bioinformatics is the Bottleneck • Sequencing is a commodity – can easily be outsourced • Bioinformatics is the essential point of the science – Data analysis and discovery of meaning in results • As the data throughput increases, the cost and time spent on analysis increase more than linearly More Investigators = Less Informatics skill • Sequencing is a readout for many different types of laboratory experiments • Clinical and basic science investigators from all areas of biology can make use of this technology • Many are completely naïve about bioinformatics • Informatics tools for NGS are very challenging Challenging Bioinformatics Environment • Very rapid change in technology platform – New file formats, new data types – Different “standards” from different vendors • Very rapid evolution of new methods • Very rapid ‘release’ of methods as ‘software’ via unsupported open source distribution • Large data sizes (both experimental and reference) The key Automation, automation, automation… 454 Sequencing Overview • Prepare library of single stranded DNA, 200-500 bp long and ligate adapters • Perform emulsion PCR, amplifying a single DNA template molecule in each microreactor (bead). • Sequence all clonally amplified sample fragments in parallel using pyrosequencing technology • Analyze sequence results – CLEAN data – Align overlapping sequence of individual reads to define contigs (Shotgun) – Order and orient contigs, create scaffolds (Paired End) – Identify variants (Amplicon) – Determine gene expression patterns (Transcriptome) Emulsion Based Clonal Amplification A + PCR Reagents + Emulsion Oil B Micro-reactors Adapter carrying library DNA Mix DNA Library & capture beads (limited dilution) “Break micro-reactors” Isolate DNA containing beads Create “Water-in-oil” emulsion Perform emulsion PCR • Generation of millions of clonally amplified sequencing templates on each bead From: Roche 454 James Grabeau 2007 (www.lsbi.mafes.msstate.edu/Roche%20454%20James%20Grabau%202007.ppt ) Depositing DNA Beads into the PicoTiter™Plate Load beads into PicoTiter™Plate Load Enzyme Beads 44 μm Adapted from: Roche 454 James Grabeau 2007 (www.lsbi.mafes.msstate.edu/Roche%20454%20James%20Grabau%202007.ppt ) Reagent flow and image capture PicoTiterPlate Wells Reagent Flow Sequencing By Synthesis Photons Generated are Captured by Camera Sequencing Image Created Adapted from: Roche 454 James Grabeau 2007 (www.lsbi.mafes.msstate.edu/Roche%20454%20James%20Grabau%202007.ppt ) FLX Sequencing Reaction www.roche-applied-science.com Different Library Preparation Methods for Different Project Aims • Shotgun Library Preparation for de novo or resequencing of genomic DNA or long PCR product. Align overlapping reads to define contigs • Paired End Library Preparation provides regions of sequence a known distance apart, allowing for ordering of contigs and analysis of genetic rearrangement. • Amplicon Library Preparation for detection of rare variants. Shotgun Library Preparation Create random DNA fragments, 300-800 bp, by nebulization with compressed N2 Ligate universal adpaters “A” and “B”. Select for “A” – “B” fragments. Remove second strand Attach to library beads via “B” adapter at calculated concentration to yield a single template molecule per library bead Proceed to emPCR Images from: https://www.roche-applied-science.com/ Amplicon Library Preparation • Target amplicon of 200-500 bp – 200 bp for uni-direction reads – 500 bp requires bi-directional reads • Amplify using fusion primers that include template specific primer and primers A and B •Purify and quantify •Proceed to emPCR From Michael Metzker, http://view.ncbi.nlm.nih.gov/pubmed/19997069 Solexa/Illumina Sequencing: Fluorescently labeled Nucleotides (Solexa) Complementary strand elongation: DNA Polymerase 60 From Debbie Nickerson, Department of Genome Sciences, University of Washington, http://tinyurl.com/6zbzh4 From Michael Metzker, http://view.ncbi.nlm.nih.gov/pubmed/19997069 From Michael Metzker, http://view.ncbi.nlm.nih.gov/pubmed/19997069 Sequencing by Synthesis (SBS) From Debbie Nickerson, Department of Genome Sciences, University of Washington, http://tinyurl.com/6zbzh4 Illumina (Solexa) Applications Resequencing • Characterise different related species or strains Transcriptome analysis • • No chip/array required! random priming of RNA DNA methylation analysis • sequencing bisulfite-converted DNA methylation-sensitive restriction digest enriched fragments Examine chromatin modifications • Quantify in vivo protein-DNA interactions using the combination of chromatin immunoprecipitation and sequencing (ChIP-Seq) Computational Biology Research Group 454 vs Solexa • • • • • Homopolymers (AAAAA..) Read length: 400 bp Number of reads: 400.000 Per-base cost greater De novo assembly, metagenomics • • • • Read length: 40 bp Number of reads: millions Per-base cost cheaper Ideal for application requiring short reads: ncRNA General ways of using the sequences: • Assemble them and look at what you have • You map them (align against a known genome) and then look at what you have. • Or a mixture of both! • Sometimes you select the DNA you are sequencing or you try to sequence everything • Depends on biological question, sequencing machine you have, and how much time and money you have Bioinformatics Tools • Alignment of reads to reference genome • Assembly of de novo sequence • Quality Control & Base Calling • Polymorphism detection • Differential expression and splicing detection • Genome browsing and annotation Alignment of reads • Reads generated from sequencing is mapped to a reference genome • Conventional tools like BLAST or BLAT do not work well with short sequence reads. • Modification of existing alignment algorithms to handle short reads. Alignment Tools • • • • • • • • ELAND MAQ Mosaik SHRiMP SOAP BWA Bowtie NOVOALIGN (commercial) Assembly • De novo sequencing involves assembling overlapping reads to form contiguous sequence of DNA • Done in cases where there’s no genomic information available NGS Applications • DNA mixtures from diverse ecosystems = metagenomics • Identification of all mutations in an organism • Deciphering cell’s transcripts at sequence level without prior knowledge of the genome sequence • Chip-seq: interactions protein-DNA • Epigenomics • Detecting noncoding RNA (miRNA-Seq is BIG now) • Genetic human variation : SNP, CNV (diseases) • Ancient DNA • Pooled sequencing Take home message Before you choose the analysis tools, choose your NGS technology wisely AND Decide whether NGS is absolutely necessary Where to get help/tips/clues