Assumptions of R
advertisement

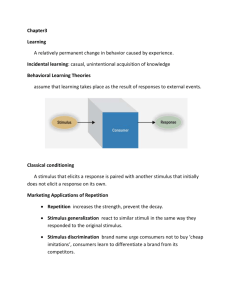
The basic design: CS ---------> US-------> UR bell food salivation \ | \ | ----> CR: salivation • important variables: – CS = conditioned stimulus: arbitrary stimulus that does not automatically evoke the response – UCS or US = unconditioned stimulus: – nonarbitrary stimulus that does automatically evoke the response – UCR or UR = unconditioned response: the response that is evoked by the US – CR = conditioned response: response that the CR evokes (what learned): May or may not be identical to UR • automatically Crucial aspect for learning: Pairing of CS and US predicts an event Important (critical) things to note about classical conditioning: • the CS MUST precede the US • the CS MUST predict the US • • if the CS does not predict the US, no conditioning occurs the CR does not have to be identical to the UR – E.g., subtle differences even Pavlov noticed) – may even be opposite: Morphine studies • Any response is a classically conditioned response if it occurs to a CS after that CS has been paired with a US but does NOT occur to a randomly presented CS-US pairing Rescorla: 6 types of control groups • CS-alone – present CS alone with no US pairing – problem: not have same number of US trials as experimental animals do, may actually be extinction effect • Novel CS group: – looks at whether stimulus is truly "neutral" – may produce habituation- animal doesn't respond because it "gets used to it" • US-alone – present US aloine with no CS pairing – problem: not have same number of CS trials • explicitly unpaired control – CS NEVER predicts US – that is- presence of CS is really CS-, predicts NO US – animal learns new rule: if CS, then no US • Backward conditioning: – US precedes CS – assumes temporal order is important (but not able to explain why) – again, animal learns that CS predicts no US • Discrimination conditioning (CS+ vs CS-) – use one CS as a plus; one CS as a minus – same problem as explicitly unpaired and backward- works, but What is it that's important about CC? Rescorla's ideas • CS-US correlation vs contiguity: – Typically in conditioning arrangements- CS always followed by the US in a perfect correlation – p(US|CS) = 1.0 – p(US|no CS) = 0.0 • but: life not always a perfect correlation • Problem: how to prove this beyond a reasonable doubt- MUST use truly random control – Must be absolutely no prediction – CS does not either predict or not predict US Probabilities interact to determine size of CS • CS = 2 min tone; presented at random intervals (X = 8 minutes) – E.g., for: Group 1: • p(shock|CS) = 0.4 during 2 min presentation • p(shock|no CS) = 0.2 • only information that CS provided = whether probability of shock was high or low – used 10 groups of rats, all with different values of p(US|CS) and p(US|no US) • whenever p(US|CS) > p(US|NO CS): – TONE = EXCITATORY CS – that is, response suppression occurred (CER) • amount of suppression depended on size difference between p(US|CS) and p(US|no CS) and vice versa • Most predictive stimulus was what attended to Relation of CS to US • appears to be the CORRELATION between the CS and US, not the contiguity (closeness in time) that is important • that is: – correlation (r) carries more information – if r = + then excitatory CS – if r = - then inhibitory CS – if r = 0 then neutral CS (not really even a CS) Blocking and overshadowing • Overshadowing: – use one "weak" and one "strong" CS – reaction to weaker stimulus is blotted out by stronger CS • Blocking: – One stimulus “blocks” learning to second CS Kamin’s investigations • Wanted to study role of attention in classical conditioning • Usual set up: neutral stimulus becomes CS predictive of a US • Note: used CER • Wanted to know about “nonneutral” stimuli – Compound stimuli – Stimuli with a history How measure in classical conditioning? • look at change in an operant behavior as a result of a CS-US pairing – teach the rat to bar press for food – shock rat- rat naturally freezes – incompatible response- can't bar press and freeze at same time – • suppression ratio: – baseline of A – intro CS condition B • suppression ratio = B/A+B – no effect = 0.5 – complete suppression = 0.0 – (disinhibition = 1.0 or oops!) Kamin’s blocking experiment • used multiple CS's and 4 groups of rats • the blocking group receives – series of L+ trials which produce strong CR – series of LT+ trials – then tested to just the T • control group receives – SAME TOTAL NUMBER OF TRIALS AS BLOCKING GROUP – no first phase – LT+ in phase 2 (totaling phase 1 and 2 above) Data are “surprising”! • .prediction: – since both received same # of trials to the tone– should get equal conditioning to the tone • results quite different: – Blocking group shows no CR to the tone– the prior conditioning to the light "blocked" any more conditioning to the tone • directly contradicts frequency principle • Group Phase I Phase II Test Phase • • • • Group A Group B Group C Group B2 LN N -N N LN LN ---- Test L Test L Test L Test L Result L elicits small CR L elicits no CR L elicits CR L elicits no CR .25 .45 .05 .45 Second experiment: • Group Y: • Group Z: 1st training 2nd N (16x w/Sr) LN (no sr) (8) N (16x w/Sr) N (no sr) (12) 3rd N (non sr) • Result: – – – – For first 16 trials: identical treatment: 0.02 on average Group Y: presented with compound, ratio increased to 0.41 Group Z: presented with noise only, ratio = 0.33 (EXT) Goup Y: noise only slight decrease to about 0.35 • Conclusion: superimposed element provided NEW information – not only notice cue – respond to cue because it carries info! Things we know about blocking • the animal does "detect" the stimulus: – EXT of CER with either N alone or with NL is slower than EXT for compound NL • appears to be independent of: – – • length of CS number of trials of conditioning to compound CS influenced by: – – – – use of CER measure (not the best) nature of CS may be important- e.g. modality intensity of stimuli important depends on amount of conditioning to blocking stimulus which already occurred • constancy of US from phase 1 to 2 important. • change in either US or CS can prevent/overcome blocking – – change the intensity of the CS from one situation to another this is why spent so much time on overshadowing• • • strong vs weak stimulus is change intensity of the stimulus- presents a different learning situation and no blocking same is true if change the intensity of US – – – – (although generally must be stronger, not weaker) e.g. experiments when changed from 1 ma to 4 ma shock quickly condition to compound stimulus little or no overshadowing or blocking Theoretical Explanations? • Perceptual gating theory: – tone never gets processed – tone not informative – data not really support this • Kamin's Surprise theory: – to condition requires some mental work on part of animal – animal only does mental work when surprised – bio genetic: prevents having to carry around excess mental baggage • • • thus only learn with "surprise" situation must be different from original learning situation Alternative explanation: Rescorla Wagner model: – particular US only supports a certain amount of conditioning – if one CS hogs all that conditioning- none is left over for another CS to be added – question- how do we show this? Assumptions of R-W model • helpful for the animal to know 2 things about conditioning: – – • Thus, classical conditioning is really learning about: – – • the CS might become more INHIBITORY the CS might become more EXCITATORY there is no change in the CS how do these 3 rules work? – – – • signals (CS's) which are PREDICTORS for important events (US's) model assumes that with each CS-US pairing 1 of 3 things can happen: – – – • what TYPE of event is coming the SIZE of the upcoming event if US is larger than expected: CS = excitatory if US is smaller than expected: CS= inhibitory if US = expectations: No change in CS The effect of reinforcers or nonreinforcers on the change of associative strength depends upon: – – the existing associative strength of THAT CS AND on the associative strength of other stimuli concurrently present More assumptions • Explanation of how an animal anticipates what type of CS is coming: – direct link is assumed between "CS center" and "US center": e.g. between a tone center and food center – assumes that STRENGTH of an event is given and that the conditioning situation is predicted by the strength of this connection – THUS: when learning is complete: the strength of the association relates directly to the size or intensity of the CS • The change in associative strength of a CS as the result of any given trial can be predicted from the composite strength resulting from all stimuli presented on that trial: – if composite strength is low, the ability of reinforcer to produce increments in the strength of component stimuli is HIGH – if the composite strength is low; reinforcement is relatively less effective (LOW) More assumptions: • Can expand to extinction, or nonreinforced trials: – if composite associative strength of a stimulus compound is high, then the degree to which a nonreinforced presentation will produce a decrease in associative strength of the components is LARGE – if composite associative strength is low- nonreinforcement effects reduced • Yields an equation: Vi =αißj(Λj-VAX) • Here is an easier way to write it: VT =αißj(Λj-Vsum) First example: • rat is subjected to conditioned suppression procedure: – CS (light) ---> US (1 mA shock) – what is associative strength? – 1 = associative strength that a 1mA shock can support at asymptote ( Λj ) – VL = associative strength of the light (strength of the CS-US association) • thus: Λ1 = size of the observed event (actual shock) • VL = measure of the Subjects current "expectation" about the size of the shock • VL will approach Λ1 over course of conditioning Second example: Same rat, same procedure but 2CS's: • CS (light+tone) --> 1 mA shock – – – – Determine associative strength when Λ1 is constant Vsum = VL + VT = assoc. strength of the 2 CS's Vsum = αißj(Λ) if VL and VT equally salient: • VL = 0.5αißj; • VT = 0.5αißj – VT = if not equally salient: VL > VT or VL < VT • now can restate the 3 rules of conditioning: – Λj > Vsum = excitatory conditioning – Λj < Vsum = inhibitory conditioning – Λj = Vsum = no change Now have the Rescorla-Wagner Model: • Model makes predictions on a trial by trial basis • For each trial: predicts increase or decrement in associative strength for every CS present • The equation: Vi =αißj(Λj -Vsum) – – – – – – – – – Vi = change in associative strength that occurs for any CS, i, on a single trial Λj= associative strength that some US, j, can support at asymptote Vsum = associative strength of the sum of the CS's (strength of CS-US pairing) αi = measure of salience of the CS (must have value between 0 and 1) ßj = learning rate parameters associated with the US (assumes that different beta values may depend upon the particular US employed) Assumptions of the formal model: • General Principle: as Va increases with repeated reinforcement of j, the difference between Λa and Va decreases – increments of Va then decrease – produce negatively accelerated learning curve with asymptote of Λj • Reinforcement of compound stimuli: lots of Va trials, then give trials of compound Vax – Va increases toward Λa as a result of a-alone presentations – Vax then exceeds Λa – result: reinforced aX trial results in DECREMENT to the associative strength of a and X components • as a and aX are reinforced: – increments to A occur on the reinforced A trials – increments to A and X occur on reinforced AX trials – result: transfer to A of whatever associative strength X may have The equation: Vi =αißj(j-Vsum) • Vi = change in associative strength that occurs for any CS, i, on a single trial • αi = stimulus salience (assumes that different stimuli may acquire associative strength at different rates, despite equal reinforcement) • ßj = learning rate parameters associated with the US (assumes that different beta values may depend upon the particular US employed) • Vsum = associative strength of the sum of the CS's (strength of CS-US pairing) • Λj= associative strength that some CS, i, can support at asymptote • In English: How much you learn on a given trial is a function of the value of the stimulus x value of the reinforcer x (the absolute amount you can learn minus the amount you have already learned). Acquisition • first conditioning trial: CS = light; US= 1 ma Shock – – – Vsum = Vl; no trials so Vl = 0 thus: Λj-Vsum = 100-0 = 100 -first trial must be EXCITATORY • BUT: must consider the salience of the light: αi = 1.0 and learning rate: ßj = 0.5 • Plug into the equatio: for TRIAL 1 – – • TRIAL 2: – – • V1 = (1.0)(0.5)(100-50) = 0.5(50) = 25 Vsum = (50+25) = 75 TRIAL 3: – – • Vl = (1.0)(0.)(100-0) = 0.5(100) = 50 thus: V only equals 50% of the discrepancy between Aj an Vsum for the first trial V1 = (1.0)(0.5)(100-75) = 0.5(25) = 12.5 Vsum = (50+25+12.5) = 87.5 TRIAL 4: – – V1 = (1.0)(0.5)(100-87.5) = 0.5(12.5) = 6.25 Vsum = (50+25+12.5+6.25) = 93.75 • TRIAL 10: Vsum = 99.81, etc., until reach 100 on approx. trial 14 • When will you reach asymptote? Overshadowing • Pavlov: compound CS with 1 intense CS, 1 weak – after a number of trials found: strong CS elicits strong CR – weak CS elicits weak or no CR • Rescorla-Wagner model helps to explain why: assume – αL = light = 0.2; αT = tone = 0.5 – ßL = light = 1.0 ; ßt = tone = 1.0 • Plug into equation: – Vsum = Vl + Vt = 0 on trial 1 – Vl = 0.2(1)(100-0) = 20 – Vt = 0.5(1)(100-0) = 50 – after trial 1: Vsum = 70 • TRIAL 2: – Vl = 0.2(1)(100-(50+20)) = 6 – Vt = 0.5(1)(100-(50+20)) = 15 – Vsum = (70+(6+15)) = 91 • TRIAL 3: – Vl = 0.2(1)(100-(91)) = 1.8 – Vt = 0.5(1)(100-(91)) = 4.5 – Vsum = (91+(1.8+4.5)) = 97.3 and so on – thus: reaches asymptote (by trial 6) MUCH faster w/2 CS's • NOTE: CSt takes up over 70 units of assoc. strength CSl takes up only 30 units of assoc. strength Blocking • similar explanation to overshadowing: – no matter whether VL more or less salient than Vt, because CS has basically absorbed all the assoc. strength that the CS can support • give trials of A-alone to asymptote: – reach asymptote: VL = Λj =100 =Vsum – αL =1.0 – ß =0.2 – First Vt Trial: Vt= αß(Λj-Vsum) • Vt=0.2*1.0*(100-100)=? • No learning! How could one eliminate blocking effect? • increase the intensity of the US to 2 mA with Λj now equals = 160 – then: Vsum still equals 100 (learned to 1 mA shock) • plug into the equation: (assume Vl and Vt equally salient) – Vt = 0.2(1)(160-100) = 0.2(60) = 12 – Vl = 0.2(1)(160-100) = 0.2(60) = 12 • on trial 2: – – – – Vsum = 124 Vt = 0.2(1)(160-124) = 0.2(36) = 7.2 Vl = 0.2(1)(160-124) = 0.2(36) = 7.2 Vsum now = (124+14.4) = 138. • could also play around with ß Critique of the Rescorla-Wagner Model: • R-W model really a theory about the US effectiveness: – says nothing about CS effectiveness – states that an unpredicted US is effective in promoting learning, whereas a well-predicted US is ineffective • Fails to predict the CS-pre-exposure effect: – two groups of subjects (probably rats) – Grp I CS-US pairings Control – Grp II CS alone CS-US pairings PRE-Expos • pre-exposure group shows much less rapid conditioning than the control group • R-W model doesn't predict any difference, because no conditioning trials occur when CS is predicted alone: Vsum = 0 – BUT: may be that salience for the CS is changing: – habituation to CS • Original R-W model implies that salience is fixed for any given CS – R-W assume CS salience doesn't change w/experience – these data strongly suggest CS salience DOES change w/experience • Newer data supports changes salience – data suggest that Si DECREASES when CS is repeatedly presented without consequence – NOW: appears that CS and US effectiveness are both highly important • Model has stood test of time, now widely used in neuroscience Can deal with variety of other issues • Compound CSs: – When two CSs are conditioned together – How much conditioning occurs to one or other depends on previous exposure and salience of each stimulus. • Time alone as CS – Time can serve as a CS; as long as it is predictive! • Difference between CS and no CS Can also explain why probability of reward given CS vs no CS makes a difference: • π = probability of US given the CS or No US given No CS • can make up three rules: – if πax > πa then Vx should be POSITIVE – if πax < πa then Vx should be NEGATIVE – if πax = πa then Vx should be ZERO • modified formula: (assume Λ1 =1.0; Λ2 =0; ß1 =.10; ß2=.05; α1=.10; α2=.5) Va = πaß1 ---------------------πaß1 - (1-πa)ß2 Vax = πaxß1 ---------------------πaxß1 - (1-πax)ß2 Vx = Vax - Va PLUG IN: Probability of CSa then US = 0.2; Probability of CSax then US = 0.8 Va = (0.2)(1.0) --------------------------((.2)(.10)) - (1-.2)(.05) = -10 Vax = (0.8)(1.0) --------------------------- = +11.43 ((.8)(.10)) - (1-.8)(.05) Vx = Vax - Va or 11.43-(-10) = 21.43 probability of US given AX greater than probability of US given X) PLUG IN: Probability of CSa then US = 0.8; Probability of CSax then US =0.2 Va = Vax = (0.8)(1.0) --------------------------- = ((.8)(.10)) - (1-.8)(.05) 11.43 (0.2)(1.0) --------------------------- = ((.2)(.10)) - (1-.2)(.05) -10 Vx = Vax - Va or -10 - 11.43 = -21.43 probability of US given AX is less than probability of US given A PLUG IN: Probability of CSa then US = 0.5 Probability of CSax then US = 0.5 Va = Vax = (0.5)(1.0) --------------------------((.5)(.10)) - (1-.5)(.05) = 20 (0.5)(1.0) --------------------------= ((.5)(.10)) - (1-.5)(.05) 20 Vx = Vax - Va or 20-20 = 0 (probability of AX = A)