Chapter 16
advertisement

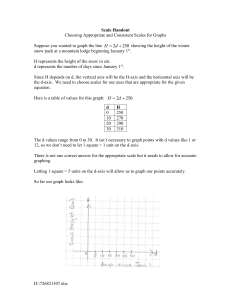
CHAPTER 16 Nonmetric Multidimensional Scaling Tables, Figures, and Equations From: McCune, B. & J. B. Grace. 2002. Analysis of Ecological Communities. MjM Software Design, Gleneden Beach, Oregon http://www.pcord.com Basic procedure 1. Calculate dissimilarity matrix D. Basic procedure 1. Calculate dissimilarity matrix D. 2. Assign sample units to a starting configuration in the kspace (define an initial X). Usually the starting locations (scores on axes) are assigned with a random number generator. Alternatively, the starting configuration can be scores from another ordination. Basic procedure 1. Calculate dissimilarity matrix D. 2. Assign sample units to a starting configuration in the kspace (define an initial X). Usually the starting locations (scores on axes) are assigned with a random number generator. Alternatively, the starting configuration can be scores from another ordination. 3. Normalize X by subtracting the axis means for each axis l and dividing by the overall standard deviation of scores: normalized x il = x il xl k n x l 1 i 1 xl 2 il / (n k ) 4. Calculate D, containing Euclidean distances between sample units in k-space. 5. Rank elements of D in ascending order. 6. Put the elements of D in the same order as D. (containing elements d , these being the 7. Calculate D ij result of replacing elements of D which do not satisfy the monotonicity constraint). Figure 16.1. Moving a point to achieve monotonicity in a plot of distance in the original p-dimensional space against distances in the k-dimensional ordination space. 8. Calculate raw stress, S* n-1 * S = n 2 ( d ij - d ij ) i=1 j=i 1 Note that S* measures the departure from monotonicity. If S* = 0, the relationship is perfectly monotonic. Figure 16.2. Plot of distance in ordination space (dij, horizontal axis) vs. dissimilarity in original p-dimensional space (dij, vertical axis), analogous to Fig. 16.1. Points are labeled with the ranked distance (dissimilarity) in the original space. Figure 16.2. Plot of distance in ordination space (dij, horizontal axis) vs. dissimilarity in original p-dimensional space (dij, vertical axis), analogous to Fig. 16.1. Points are labeled with the ranked distance (dissimilarity) in the original space. 9. Because raw stress would be altered if the configuration of points were magnified or reduced, it is desirable to standardize ("normalize") stress. Kruskal’s “stress formula one:” n-1 S = S / * n d i=1 j=i 1 2 ij 9. Because raw stress would be altered if the configuration of points were magnified or reduced, it is desirable to standardize ("normalize") stress. Kruskal’s “stress formula one:” n-1 S = S / * n d 2 ij i=1 j=i 1 PC-ORD reports stress as SR, the square root of the scaled stress, analogous to a standard deviation, then multiplied by 100 to rescale the result from zero to 100: SR = 100 S “stress formula two” is: n-1 n S = S / ( d ij d ) * i=1 j=i 1 The two formulas yield very similar configurations. 2 10. Now we try to minimize S by changing the configuration of the sample units in the k-space. For the method of steepest descent, we first calculate the "negative gradient of stress" for each point i. The gradient vector (a vector of length k containing the movement of each point h in each dimension l) is calculated by: g hl S D - D n n hi i=1 j=1 hj d ij x il - x jl d ij - d ij S* 2 d ij d ij i, j i indexes one of the n points, j indexes another of the n points, l indexes a particular dimension, and h indexes a third point, the point of interest which is being moved on dimension l. So ghl indicates a shift for point h along dimension l. The Dhi and Dhj are Kronecker deltas which have the value 1 if i and h or h and j indices are equal, otherwise they have the value 0. If the strict lower triangles of the distance matrices have been used then the Kronecker deltas can be omitted. 11. The amount of movement in the direction of the negative gradient is set by the step length, a, which is normally about 0.2 initially. The step size is recalculated after each step such that the step size gets smaller as reductions in stress become smaller. 12. Iterate (go to step 3) until either (a) a set maximum number of iterations is reached or (b) a criterion of stability is met. At the stopping point, the stress should be acceptably small. One way to assess this is by calculating the relative magnitude of the gradient vector g: magnitude of g = 2 g hl /n h,l Mather suggested that mag(g) should reach a value of 2-5% of its initial value for an arbitrary configuration. This is often not achievable. Randomization (Monte Carlo) test p = (1+n)/(1+N) n = number of randomized runs with final stress less than or equal to the observed minimum stress N = number of randomized runs Table 16.1. Stress in relation to dimensionality (number of axes), comparing 20 runs on the real data with 50 runs on randomized data. The p-value is the proportion of randomized runs with stress less than or equal to the observed stress (see text). This table is the basis of the scree plot shown in Figure 16.3. Axes 1 2 3 4 5 6 Stress in real data Minimum Mean Maximum 37.52 15.30 10.96 7.62 5.73 6.96 49.00 18.10 12.33 10.09 6.06 8.65 Stress in randomized data Minimum Mean Maximum 54.76 27.27 19.88 15.34 6.39 10.56 36.49 19.93 13.90 10.23 7.27 5.42 48.70 27.12 19.01 15.00 13.28 12.17 55.54 43.35 32.06 28.87 30.44 33.82 p 0.0199 0.0050 0.0050 0.0050 0.0050 0.0796 60 Real Data Randomized Data Maximum 50 Mean Minimum Figure 16.3. A scree plot shows stress as a function of dimensionality of the gradient model. "Stress" is an inverse measure of fit to the data. The "randomized" data are analyzed as a null model for comparison. See also Table 16.1. Stress 40 30 20 10 0 1 2 3 4 Dimensions 5 6 Table 16.2. A second example of stress in relation to dimensionality (number of axes), comparing 15 runs on the real data with 30 runs on randomized data, for up to 4 axes. Stress in real data Axes 1 2 3 4 Minimum 42.80 27.39 20.30 15.76 Mean Maximum 49.47 56.57 29.01 30.69 20.48 21.27 16.02 16.97 Stress in randomized data Minimum 43.18 27.75 19.87 14.89 Mean Maximum 50.39 56.52 29.68 31.99 20.81 22.30 16.03 16.96 p 0.0323 0.0323 0.3548 0.3548 Table 16.3. Thoroughness settings for autopilot mode in NMS in PC-ORD version 4. Thoroughness setting Parameter Maximum number of iterations Instability criterion Starting number of axes Number of real runs Number of randomized runs Quick and dirty 75 0.001 3 5 20 Medium 200 0.0001 4 15 30 Slow and thorough 400 0.00001 6 40 50 Choosing the best solution 1. Select an appropriate number of dimensions. 60 Real Data Randomized Data Mean Minimum 40 Stress Figure 16.3. A scree plot shows stress as a function of dimensionality of the gradient model. "Stress" is an inverse measure of fit to the data. The "randomized" data are analyzed as a null model for comparison. See also Table 16.1. Maximum 50 30 20 10 0 1 2 3 4 Dimensions 5 6 2. Seek low stress. Stress 2.5 5 10 20 <5 5-10 10-20 > 20 Kruskal’s rules of thumb Excellent Good Fair Poor Clarke’s rules of thumb An excellent representation with no prospect of misinterpretation. This is, however, rarely achieved. A good ordination with no real risk of drawing false inferences Can still correspond to a usable picture, although values at the upper end suggest a potential to mislead. Too much reliance should not be placed on the details of the plot. Likely to yield a plot that is relatively dangerous to interpret. By the time stress is 35-40 the samples are placed essentially at random, with little relation to the original ranked distances. 16 Final Stress (%) 14 12 10 8 6 4 2 0 0 10 20 30 40 50 Number of Sample Units Figure 16.4. Dependence of stress on sample size, illustrated by subsampling rows of a matrix of 50 sample units by 29 species. Stress (%) or Spp count 30 25 Species remaining, count Final Stress 20 15 10 5 0 0 20 40 60 80 100 Criterion for species retention (% of SU's) Figure 16.5. Dependence of final stress on progressive removal of rare species from a data set of 50 sample units and 29 species. For example, when only species occurring in 19% or more of the sample units were retained, 16 species remained in the data set and the final stress was about 15%. 3. Use a Randomization (Monte Carlo) test. Helpful but not foolproof. The most common problems are: A. Strong outliers caused by one or two extremely high values can result in randomizations with final stress values similar to the real data. B. The same can be true for data dominated by a single superabundant species. C. With very small data sets (e.g., less than 10 SUs), the randomization test can be too conservative. D. If a data set contains very many zeros, then most randomizations will produce multiple empty sample units, making applications of many distance measures impossible. 4. Avoid unstable solutions. 35 Stress 20 15 10 5 0 0 50 100 150 200 Step Instability Step Length Mag(G) 0 -1 -2 log(Value) Figure 16.7. NMS seeks a stable solution. Instability is the standard deviation in stress over the preceding 10 steps (iterations); step length is the rate at which NMS moves down the path of steepest descent; it is based on mag(g), the magnitude of the gradient vector (see text). 30 25 -3 -4 -5 -6 -7 -8 0 50 100 Step 150 200 30 25 Stress 20 Figure 16.8. NMS finds an unstable solution; normally this would be unacceptable instability. In this case it was induced by overfitting the model (fitting it to more dimensions than required). The plotted variables are described in Figure 16.7. 15 10 5 0 0 50 100 Step 200 Instability Step Length Mag(G) 0 log(Value) 150 -1 -2 -3 0 50 100 Step 150 200 50 30 20 10 0 0 50 100 150 200 Step Instability Step Length Mag(G) 0 -1 log(Value) Figure 16.9. NMS finds a fairly stable solution, ending with a periodic but low level of instability. The instability is so slight that the stress curve appears nearly flat after about 45 steps. The plotted variables are described in Figure 16.7. Stress 40 -2 -3 -4 0 50 100 Step 150 200 Example Table 16.5. Abundance of six species in each of five sample units. Species SU sp1 sp2 sp3 sp4 sp5 sp6 1 2 3 4 5 1 1 0 1 5 2 3 3 2 2 3 2 0 2 1 4 4 1 2 3 5 6 0 3 5 5 6 1 4 6 Table 16.6. Sørensen distances among the five sample units from Table 16.5. SU SU 1 2 3 4 1 2 3 4 5 0 0.0952 0.6800 0.1765 0.1905 0 0.6296 0.2222 0.1818 0 0.5789 0.7037 0 0.2778 5 0 Point 1 Axis 2 Axis 2 Axis 1 Axis 1 Point 4 Axis 2 Axis 2 Point 3 Axis 1 Axis 1 50 Point 5 Stress Stress 40 Axis 2 Figure 16.10. Migration of points from the starting configuration through 20 steps to the final configuration using NMS. Each point in the ordination represents one of five sample units. The first five graphs show the migration of individual points (arrows indicate starting points), followed by the graph of the decline in stress as the migration proceeds. Point 2 30 20 10 0 0 Axis 1 5 10 Step 15 20 Figure 16.10. (cont.) Migration of points from the starting configuration through 20 steps to the final configuration using NMS. Each point in the ordination represents one of five sample units. Table 16.7. Focusing parameters for fitting new points to an existing NMS ordination. The units for interval width and range are always in the original axis units. Focus level 1 2 3 Range examined Intervals Points 80 + 2 (0.2 80) = 112 20 + 4 + 4 = 28 29 Interval Width 112/28 = 4 2 5 4/5 = 8 2 5 (0.8/5) = 1.6 2 5 = 10 2 5 = 10 11 11 4/5 = 0.8 0.8/5 = 0.16 51.5 50.5 50.0 49.5 -20 0 20 40 60 80 100 120 Trial Score 49.90 Stress 49.85 49.80 49.75 49.70 10 11 12 13 14 15 16 17 18 19 20 Trial Score 49.737 Stress Figure 16.11. Successive approximation of the score providing the best fit in predictive-mode NMS. The method illustrated is for one axis at a time. Multiple axes can be fit similarly by simultaneously varying two or more sets of coordinates. Stress 51.0 49.736 49.735 13.5 14.0 14.5 Trial Score 15.0 15.5 Table 16.8. Flags for poor fit of new points added to an existing NMS ordination. Flag Meaning 0 Criteria for acceptability were met 1 Final stress is too high 2 Score is too far off low end of gradient 3 Score is too far off high end of gradient The following options were selected: Distance measure = Sørensen Method for fitting = one axis at a time Flag for poor fit = autoselect (2 stand.dev. > mean stress) Extrapolation limit, % of axis length: 5.000 Calibration data set: D:\FHM\DATA\94\SEModel.wk1 Figure 16.12. Example output (PC-ORD) from “one axis at a time” method of fitting new points in an NMS ordination. Contents of data matrices: 85 Plots and 87 Species in calibration data set 34 plots and 140 species in test data set 85 scores from calibration data set Title from file with calibration scores: SEModel.wk1, rotated 155 degrees clockwise 63 species in test data set are not present in calibration data AXIS SUMMARY STATISTICS -------------------------------------------------------------------Axis: 1 2 Mean stress 49.833 50.251 Standard deviation of stress 0.351 0.391 Stress used to screen poor fit (flag = 1) 50.536 51.033 Cutoff score, low end-of-axis warning flag (2) -6.473 -12.895 Cutoff score, high end-of-axis warning flag (3) 106.473 112.895 Minimum score from calibration data 6.559 1.619 Maximum score from calibration data 93.441 98.381 Range in scores from calibration data 86.881 96.761 -------------------------------------------------------------------- BEST-FIT SCORES ON EACH AXIS -------------------------------------------------Axis: 1 2 Item (SU) Score Fit Flag Score Fit Flag -------------------------------------------------3008281 25.673 49.713 0 90.253 50.085 0 3008367 44.440 50.058 0 74.190 50.582 0 3008372 36.099 50.141 0 80.964 50.437 0 etc. 3108526 3108564 2.563 50.000 49.505 49.953 0 0 8.199 87.543 50.007 50.491 0 0