Chapter 1-99. Homework Problem Solutions
advertisement

Chapter 1-99. Homework Problem Solutions
Chapter 1-1. Installing Stata and recovering Stata windows
No problems.
Chapter 1-2. Getting data into Stata and some other basics
Problem 1) Creating a csv file
Open Microsoft Excel. Highlight the white cells (not the first row or first column) of the
following table, copy them, and paste them into Excel.
1
2
3
4
5
A
Controls
B
C
id
age
sbp
1
2
40
48
120
125
Save the file as a csv file, paying attention to which directory it goes into. Here are the
steps:
Inside Excel, click on top left icon (the Office Button),
Double Click Save As
File name: ch1-14-problem1.csv
Save as type: CSV (Comma delimited) (*.csv)
Save
Excel will then ask some questions:
“The selected file type does not support….” Answer OK (this is just Excel letting you
know only the worksheet you have open will be saved as a csv file)
“ch1-14-problem1.csv may contain features….” Answer Yes (this is just Excel letting
you know features like colored text and colored shading will not show up in
the csv file.
The file ch1-14-problem1.csv should now be in some directory, say My Documents.
Click on the X in the upper right corner to exit Excel
_____________________
Source: Stoddard GJ. Biostatistics and Epidemiology Using Stata: A Course Manual. Salt Lake City, UT: University of Utah
School of Medicine. Chapter 1-99. (Accessed January 8, 2012, at http://www.ccts.utah.edu/biostats/
?pageId=5385).
Chapter 1-99 (revision 8 Jan 2012)
p. 1
Excel will then ask, “Do you want to save the changes..” Answer No, since you have
already saved the file. (Excel does not know if you made any additional changes
in between the save you just did and when you are now exiting Excel.)
The file ch1-14-problem1.csv should now be in some directory, perhaps My Documents.
Problem 2) Reading in a csv file from the Stata menu
Stata cannot open a csv file directly, but it can import it. From inside Stata, on the main
menu bar, click on
File
Import
ASCII data created by a spreadsheet
ASCII dataset filename: click on Browse
The Open box comes up. In the window Files of type,
while you are looking in the correct directory where you saved
the file in Problem 1),
Ask for “Comma Separated Values (*.csv)”
Click on “ch1-14-problem1.csv
Open
OK
You will see that Stata brought in the data and named the variables v1, v2, and v3.
This is all Stata could do, since it has no way to know that the variable names are in row
3.
Listing the data,
list
1.
2.
3.
4.
5.
+----------------------+
|
v1
v2
v3 |
|----------------------|
| Controls
|
|
|
|
id
age
sbp |
|
1
40
120 |
|
2
48
125 |
+----------------------+
we see the variable names on row 3 and notice that rows 1 and 2 have no value as data.
Problem 3) Having Stata delete first two rows and bring back in starting on row 3
Now do the trick found in Chapter 1-2, under the heading
Importing an Excel File Into Stata When the Variable Names are Not on the First Row
Chapter 1-99 (revision 8 Jan 2012)
p. 2
Cut-and-paste the following lines into the Stata do file editor.
* bring data back in using 3rd row as variable names
drop in 1/2
outsheet using temp1.csv, comma nonames replace
insheet using temp1.csv, clear names
erase temp1.csv
Highlight this block of Stata commands and hit the execute botton (last icon on the dofile menu bar).
Listing the data again,
list
+----------------+
| id
age
sbp |
|----------------|
1. | 1
40
120 |
2. | 2
48
125 |
+----------------+
We now have the data read in with the desired variable names.
Chapter 1-3. Cleaning data
Problem 1) Convert Excel file to an ASCII file (explained in Chapter 1-2)
Open the file homework1.xls inside Excel. Save it back out as an ASCII file with a csv
file extension, calling it homework1.csv. The contents of this file are:
id
1
2
3
4
5
6
sex
M
m
F
F
m
f
age
unknown
20
21
30
40
Problem 2) Reading ASCII file into Stata (explained in Chapter 1-2)
Part 1) Change your working directory to wherever the course manual data files are.
You can use the menu to help with this.
File
Change working directory…
Browse until you find the datasets & do-files directory
OK
Chapter 1-99 (revision 8 Jan 2012)
p. 3
. cd "C:\Documents and Settings\u0032770.SRVR\Desktop\Biostats & Epi With
Stata\datasets & do
> -files"
C:\Documents and Settings\u0032770.SRVR\Desktop\Biostats & Epi With
Stata\datasets & do-files
Part 2) Read the file homework1.csv into Stata using the “insheet” command (in
Command window, or do-file editor, rather than the menu Import option. The command
you need is:
insheet using homework1.csv, clear
Here the “clear” option was added. Actually, this option is only needed if data are already
in Stata memory.
Problem 3) Convert messy string variable to a numeric variable
In the do-file editor, create a numeric “female” variable from the string “sex” variable
using the inlist function. Use 1 = female and 0 = male.
capture drop female // optional
gen female = 1 if inlist(sex, "F", "f")
replace female = 0 if inlist(sex, "M", "m")
tab sex female, missing // check that it worked
|
female
sex |
0
1 |
Total
-----------+----------------------+---------F |
0
2 |
2
M |
1
0 |
1
f |
0
1 |
1
m |
2
0 |
2
-----------+----------------------+---------Total |
3
3 |
6
Problem 4) Clean up messy numeric variable that contains strings
Convert the age variable to numeric, after setting “unknown” to missing. (Something
similar was done for matage in Chapter 1-3.)
replace age="" if age=="unknown"
destring age, replace
sum age
list age
Chapter 1-99 (revision 8 Jan 2012)
p. 4
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------age |
4
27.75
9.322911
20
40
1.
2.
3.
4.
5.
6.
+-----+
| age |
|-----|
|
. |
| 20 |
| 21 |
| 30 |
|
. |
|-----|
| 40 |
+-----+
Problem 5) Save this cleaned up dataset as a Stata formatted file.
save homework1, replace
(note: file homework1.dta not found)
file homework1.dta saved
Chapter 1-4. Merging files
Problem 1) Match Merge
The Excel spreadsheet, called chapter1-4exercise.xls has two sheets of data. The first
sheet is called demographics, and the second is called qol.
Sheet 1: demographics
id
age
1
2
3
4
5
female
15
29
18
20
22
1
1
0
0
0
Sheet 2: qol
id
quality of life
1
2
3
5
2
2
3
4
Save each sheet into an ASCII file, such as a csv file, perform a match-merge on id, and
then list the data. (If needed, look at Chapter 1-2 Problem 1, above, to see how to save a
worksheet in Excel to a csv file.)
Your solution should look like:
Chapter 1-99 (revision 8 Jan 2012)
p. 5
. list
1.
2.
3.
4.
5.
+------------------------------------------------+
| id
age
female
qualit~e
_merge |
|------------------------------------------------|
| 1
15
1
2
matched (3) |
| 2
29
1
2
matched (3) |
| 3
18
0
3
matched (3) |
| 4
20
0
.
master only (1) |
| 5
22
0
4
matched (3) |
+------------------------------------------------+
To avoid abbreviating the variable names to 8 characters, you can use the “abbrev( 15)
option on the list to allow up to 15 characters per column
. list , abbrev(15)
1.
2.
3.
4.
5.
+-----------------------------------------------------+
| id
age
female
qualityoflife
_merge |
|-----------------------------------------------------|
| 1
15
1
2
matched (3) |
| 2
29
1
2
matched (3) |
| 3
18
0
3
matched (3) |
| 4
20
0
.
master only (1) |
| 5
22
0
4
matched (3) |
+-----------------------------------------------------+
Finally, save the merged file into a new file name (Stata formattted file).
A good way to keep track of where the csv files came from is to append the sheet name
onto the Excel file name. If you did it this way, you would have saved the demographics
sheet into the file:
chapter1-4exercise_demographics.csv
and the qol sheet into the file:
chapter1-4exercise_qol.csv
Any file names you chose would have been fine, as well.
After changing to the directory where these files are located, perhaps using the change
directory (cd) command or the “change working directory” menu option (as was done in
Chapter 1-3 problem 2 above), you could use the following,
insheet using chapter1-4exercise_qol.csv, clear
sort id
save chapter1-4exercise_qol, replace
insheet using chapter1-4exercise_demographics.csv, clear
sort id
merge 1:1 id using chapter1-4exercise_qol
list , abbrev(15)
save chapter1-4final, replace
1.
2.
3.
4.
5.
+-----------------------------------------------------+
| id
age
female
qualityoflife
_merge |
|-----------------------------------------------------|
| 1
15
1
2
matched (3) |
| 2
29
1
2
matched (3) |
| 3
18
0
3
matched (3) |
| 4
20
0
.
master only (1) |
| 5
22
0
4
matched (3) |
+-----------------------------------------------------+
Chapter 1-99 (revision 8 Jan 2012)
p. 6
Chapter 1-5. Labeling variables and values
Problem 1) Assigning Labels
Cut-and-paste the following lines into the Stata do file editor. Highlight this block of
Stata commands and hit the execute botton (last icon on the do-file menu bar) to load the
dataset into Stata.
clear
input id dose
1 1
2 1
3 1
4 2
5 2
6 3
7 3
8 3
9 3
end
list
Chapter 1-99 (revision 8 Jan 2012)
p. 7
1.
2.
3.
4.
5.
6.
7.
8.
9.
+-----------+
| id
dose |
|-----------|
| 1
1 |
| 2
1 |
| 3
1 |
| 4
2 |
| 5
2 |
|-----------|
| 6
3 |
| 7
3 |
| 8
3 |
| 9
3 |
+-----------+
Assign the following labels to the dose variable (variable label and value labels):
dose: ibuprofen dose category
1:
1) low dose
2:
2) mod dose
3:
3) high dose
and generate a frequency table. Your solution show look like:
ibuprofen |
dose |
category |
Freq.
Percent
Cum.
-------------+----------------------------------1) low dose |
3
33.33
33.33
2) mod dose |
2
22.22
55.56
3) high dose |
4
44.44
100.00
-------------+----------------------------------Total |
9
100.00
label variable dose "ibuprofen dose category"
label define doselab 1 "1) low dose" 2 "2) mod dose" ///
3 "3) high dose"
label values dose doselab
tab dose
ibuprofen |
dose |
category |
Freq.
Percent
Cum.
-------------+----------------------------------1) low dose |
3
33.33
33.33
2) mod dose |
2
22.22
55.56
3) high dose |
4
44.44
100.00
-------------+----------------------------------Total |
9
100.00
Chapter 1-99 (revision 8 Jan 2012)
p. 8
Chapter 1-6. Basic graphics
Problem 1) Publication quality graph
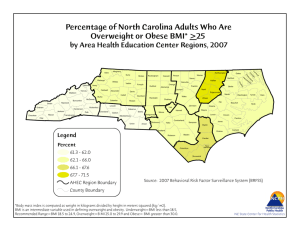
Anker et al (2009), in their Figure 2, Panel C, present a mean change from baseline graph
with error bars that represent standard errors. The results are a 6-minute-walk test, with a
separate line for the ferric carboxymaltose (FCM) group and the placebo group.
Measures occurred at baseline, week 4, 12, and 24. By visual examination of the graph,
the data are approximately,
Mean changes from baseline with standard errors
Group
Baseline Week 4 Week 12 Week 24
FCM
0
21±3
39±4
38.5±5
Placebo 0
2±5
3±6
10±6
The assignment is to create a graph in the do-file editor. First, input the mean change and
the lower and upper bounds of the error bars, something like what was done in Chapter 16, p.27. Then, using other commands, or graph options found in that chapter, create the
following black-and-white graph:
50
P<0.001
P<0.001
P<0.001
40
FCM
30
20
Placebo
10
0
-10
0
4
Chapter 1-99 (revision 8 Jan 2012)
8
12
16
Weeks since Randomization
20
24
p. 9
Hint: add one feature at a time. That way, it is easier to discover what the error message
goes with (it goes with the last thing you added).
Hint: The following table shows where Stata positions titles, subtitles, etc. To add some
white space on the right side of graph, just use
r1title(" ")
to put a blank title on that side.
l2title
l1title
r1title
r2title
title
subtitle
t2title
t1title
b1title
b2title
legend
note
caption
Work on it long enough to get most of the features. Stop and look at the solution when it
gets to the point of being more frustrating than it is fun.
Chapter 1-99 (revision 8 Jan 2012)
p. 10
The graph was drawn using the following Stata comands:
clear
input week fcm change lower upper
0 1 0 . .
4 1 21 18 24
12 1 39 35 43
24 1 38.5 33.5 43.5
0 0 0 . .
4 0 2 -3 7
12 0 3 -3 9
24 0 10 4 16
end
list
*
sort week
#delimit ;
twoway
(scatter change week if fcm==1, msymbol(diamond) mlcolor(black)
mfcolor(black))
(rcap lower upper week if fcm==1, color(black))
(line change week if fcm==1, lcolor(black))
(scatter change week if fcm==0, msymbol(circle) mlcolor(black)
mfcolor(white) msize(*1.5))
(rcap lower upper week if fcm==0, color(black))
(line change week if fcm==0, lcolor(black))
, scheme(s1mono) legend(off)
plotregion(style(none))
ytitle("Change in Distance (m)")
xtitle("Weeks since Randomization" , height(5))
ylabels(-10(10)50, angle(horizontal))
xlabels(0(4)24)
text(35 17 "FCM", placement(e))
text(11 19 "Placebo", placement(e))
text(50 4 "P<0.001", placement(c))
text(50 12 "P<0.001", placement(c))
text(50 24 "P<0.001", placement(c))
r1title(" ") /* blank y-title on right side to add white space */
;
#delimit cr
Chapter 1-99 (revision 8 Jan 2012)
p. 11
Chapter 1-7. Looping, collapsing, and reshaping
Problem 1) reshaping
In Hand et al (1994, p.7), a dataset which was taken from Snedecor and Cochran (1967,
p.347), contains the weight gain in rats. Hand et al give this description,
“The data come from an experiment to study the gain in weight of rats fed on four
different diets, distinguished by amount of protein (low and high) and by source of
protein (beef and cereal). The design of the experiment is completely randomized
with ten rates on each of the four treatments (which have a complete factorial
structure).”
Cut-and-paste the following into the do-file editor, highlight, and execute it to set up the
dataset.
clear
input
90
76
90
64
86
51
72
90
95
78
end
gain1
73
102
118
104
81
107
100
87
117
111
gain2 gain3 gain4
107
98
95
74
97
56
80
111
98
95
74
88
74
82
67
77
89
86
58
92
These data represent the weight gain in rats for four groups:
gain1 = beef low
gain 2 = beef high
gain 3 = cereal low
gain 4 = cereal high
To analyze these data with independent group t-tests, we need a variable for group which
contains the numbers 1 to 4, and then a variable for weight gain. That is, we need a long
format structure.
Convert these data from the present width structure to long structure, creating a variable
called group and gain. To make this work, you will need an identification number that
uniquely defines the rows. You could use:
gen tempid = _n
The following would work,
Chapter 1-99 (revision 8 Jan 2012)
p. 12
gen tempid = _n
reshape long gain , i(tempid) j(group)
drop tempid
Problem 2) Value labels
Assign the following value labels to the variable group:
1 = beef low
2 = beef high
3 = cereal low
4 = cereal high
You can refer to Chapter 1-5 to recall how to do this.
The following would work,
label define grouplab 1 "1) beef low" 2 "2) beef high" ///
3 "3) cereal low" 4 "4) cereal high"
label values group grouplab
tab group
Problem 3) All possible t-tests
Now, we want to compute all the possible t-tests (1 vs 2)(1 vs 3)(1 vs 4)(2 vs 3)(2 vs 4)
(3 vs 4). (Note: In an actual data analysis, you would then most likely apply a multiple
comparison procedure to the p values, as described in Chapter 2-8, but that is not part of
this problem.) For the groups 1 and 2 comparison, we will need,
ttest gain if group==1 | group==2, by(group)
Rather than putting six t-test lines in the do-file, see if you can do it with two for loops.
We did something quite close to this in Chapter 1-7, page 7, to create an upper triangular
matrix
* -- multiplication table (upper triangular matrix): attempt 2
* r = row , c = col
forvalues r = 1/3 {
local m=(`r'-1)*2
display _skip(`m') _continue
forvalues c = `r'/3 {
display `r'*`c' " " _continue
}
display // display nothing goes to next line
}
1 2 3
4 6
9
Chapter 1-99 (revision 8 Jan 2012)
p. 13
Hint: If you get the following error:
1 group found, 2 required
r(420);
it means you are trying to use the same group twice in the t-test—the two groups must be
different.
If you tried the following, which is a good first attempt,
forvalues i = 1/3 {
forvalues j = `i'/4 {
ttest gain if group==`i' | group==`j' , by(group)
}
}
*
you would get the following error:
1 group found, 2 required
r(420);
This error would come from trying to do a t-test between groups 1 and 1. The j counter
needs to always be at least one larger than the i counter.
If you tried the following, which is also a good attempt,
forvalues i = 1/3 {
forvalues j = 2/4 {
ttest gain if group==`i' | group==`j' , by(group)
}
}
*
you would get three t-tests and then that same error:
1 group found, 2 required
r(420);
which could come from trying to do a t-test between groups 2 and 2.
Here is a solution that works,
forvalues i = 1/3 {
local jstart = `i'+1
forvalues j = `jstart'/4 {
ttest gain if group==`i' | group==`j' , by(group)
}
}
*
It is true, just putting the six t-test lines in would have been faster. This solution ended
up taking six lines, anyway. But if you are geeky enough, this was a fun challenge.
Chapter 1-99 (revision 8 Jan 2012)
p. 14
Chapter 1-8. Operators, ifs, dates, and times
Problem 1) numeric operators
A frequent research problem is computing BMI using the following formula:
body mass index (BMI) = weight/height2 (units: kg/m2)
If the data are height in inches and weight in pounds, then a conversation is first needed.
Cut-and-paste the following into the do-file editor, highlight and execute it to set up the
dataset.
clear
input heightin weightlbs
56 200
63 240
50 125
60 127
48 150
57 180
58 210
56 185
60 220
61 310
60 180
59 175
60 100
61 98
59 90
58 80
58 145
65 150
end
lab var heightin "height (inches)"
lab var weightlbs "weight (pounds)"
To use the BMI formula, we need height in meters. The conversion formula is:
1 inch = 0.0254 meter
We also need weight in kilograms. The conversion formula is:
1 pound = 0.4536 kilogram
Generate a BMI variable.
We could do it three steps, creating the intermediate variables and then BMI:
Chapter 1-99 (revision 8 Jan 2012)
p. 15
gen heightm = heightin*0.0254 // convert from inches to meters
gen weightkg = weightlbs*0.4536 // convert from pounds to kg
gen bmi = weightkg/heightm^2
Or, it could be done on one line,
gen bmi = (weightlbs*0.4536)/(heightin*0.0254)^2
Problem 2) BMI categories
Cut-and-paste the following into the do-file editor, highlight and execute it to set up the
dataset.
clear
input id bmi
1 17.44444
2 18.49999
3 18.50000
4 18.50001
5 18.99999
6 24.00000
7 25.00000
8 25.00001
9 .
10 27.33333
11 29.99999
12 30.00000
13 32.44444
end
list
BMI categories recommended by the National Heart, Lung, and Blood Institute
(1998)(Onyike et al., 2003) are:
underweight (BMI <18.5)
normal weight (BMI 18.5–24.9)
overweight
(BMI 25.0–29.9)
obese
(BMI 30)
Create a variable, bmicat, that has scores 1 to 4, representing the four BMI categories. A
recode command is the easiest way, which we will do in Problem 3, but first try it with a
generate command, to create the first category, followed by some replace commands for
the other three categories.
Hint: one of the replace commands might be,
replace bmicat = 2 if 18.5<= bmi & bmi<25.0
End with the following comands to check your work,
list bmi bmicat
bysort bmicat: sum bmi
Chapter 1-99 (revision 8 Jan 2012)
p. 16
A first attempt might have been,
capture drop bmicat
gen bmicat = 1 if bmi<18.5
replace bmicat = 2 if 18.5<= bmi & bmi<25.0
replace bmicat = 3 if 25.0<= bmi & bmi<30.0
replace bmicat = 4 if bmi>=30
list bmi bmicat
bysort bmicat: sum bmi
but it would not have dealt with the missing value correctly. Missing data are stored as a
very large number (plus infinity if you want to think of it like that). Therefore,
(bmi>=30) evaluates to true, so a 4 is assigned.
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
+-------------------+
|
bmi
bmicat |
|-------------------|
| 17.44444
1 |
| 18.49999
1 |
|
18.5
2 |
| 18.50001
2 |
| 18.99999
2 |
|-------------------|
|
24
2 |
|
25
3 |
| 25.00001
3 |
|
.
4 | <- wrong answer
| 27.33333
3 |
|-------------------|
| 29.99999
3 |
|
30
4 |
| 32.44444
4 |
+-------------------+
The following will work,
capture drop bmicat
gen bmicat = 1 if bmi<18.5
replace bmicat = 2 if 18.5<= bmi & bmi<25.0
replace bmicat = 3 if 25.0<= bmi & bmi<30.0
replace bmicat = 4 if bmi>=30 & bmi~=.
list bmi bmicat
bysort bmicat: sum bmi
+-------------------+
|
bmi
bmicat |
|-------------------|
1. | 17.44444
1 |
2. | 18.49999
1 |
3. |
18.5
2 |
4. | 18.50001
2 |
5. | 18.99999
2 |
|-------------------|
6. |
24
2 |
7. |
25
3 |
8. | 25.00001
3 |
9. |
.
. |
10. | 27.33333
3 |
|-------------------|
11. | 29.99999
3 |
Chapter 1-99 (revision 8 Jan 2012)
<- right answer
p. 17
12. |
30
4 |
13. | 32.44444
4 |
+-------------------+
-> bmicat = 1
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------bmi |
2
17.97222
.7463863
17.44444
18.49999
-> bmicat = 2
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------bmi |
4
20
2.677062
18.5
24
-> bmicat = 3
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------bmi |
4
26.83333
2.380469
25
29.99999
-> bmicat = 4
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------bmi |
2
31.22222
1.728479
30
32.44444
-> bmicat = .
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------bmi |
0
Notice that the minimums and maximuns agree with the category endpoints.
Problem 3) BMI categories
Use the Problem 2) dataset, again. This time, create the BMI categories using a recode
statement.
Here are the categories, again.
underweight (BMI <18.5)
normal weight (BMI 18.5–24.9)
overweight
(BMI 25.0–29.9)
obese
(BMI 30)
Hint: a recode for categorizing age might be,
capture drop agecat
recode age 90/max=5 80/90=4 70/80=3 60/70=2 , min/60=1 , gen(agecat)
list age agecat // check our work
bysort agecat: sum age // check our work
Chapter 1-99 (revision 8 Jan 2012)
p. 18
Forming the categories in reverse order solves the problem of decimal places. For
example, using “90/max=5” assigns 90 to 5, so when “80/90=4” comes up next, it
translates into 80/89.999999=4”. That is, once a number in a range is assigned, it stays
assigned. Also, since we did not assign missing, using “.=99”, for example, it remains
missing (remains unassigned).
The following would work,
capture drop bmicat
recode bmi 30/max=4 25/30=3
list bmi bmicat
bysort bmicat: sum bmi
18.5/25=2
min/18.5=1 ,gen(bmicat)
Problem 4) Concatenating (combining) strings
In a study were upper respiratory disease symptoms were abstracted from the patient
medical record, the investigator wanted to create a string that showed the combination of
symptoms.
Cut-and-paste the following into the do-file editor, highlight and execute it to set up the
dataset and create the symptoms string variable.
clear
input runnynose cough congestion throatpain earpain fever
1 1 1 1 1 1
1 0 1 1 0 0
0 1 0 0 1 1
0 0 1 0 1 0
0 0 0 1 0 0
1 0 0 0 0 0
0 0 0 0 0 1
0 0 0 0 0 0
0 0 0 0 1 0
end
*
* -- create a variable showing all symptoms found in medical record
* run = runnynose
* cou = cough
* con = congestion
* thr = throat pain
* ear = ear pain
* fev = fever
capture drop symptoms
gen str20 symptoms = ""
replace symptoms = "run," if runnynose==1
replace symptoms = "...," if runnynose==0
replace symptoms=symptoms+"cou," if cough==1
replace symptoms=symptoms+"...," if cough==0
replace symptoms=symptoms+"con," if congestion==1
replace symptoms=symptoms+"...," if congestion==0
replace symptoms=symptoms+"thr," if throatpain==1
replace symptoms=symptoms+"...," if throatpain==0
replace symptoms=symptoms+"ear," if earpain==1
replace symptoms=symptoms+"...," if earpain==0
replace symptoms=symptoms+"fev" if fever==1
replace symptoms=symptoms+"..." if fever==0
tab symptoms
Chapter 1-99 (revision 8 Jan 2012)
p. 19
symptoms |
Freq.
Percent
Cum.
------------------------+----------------------------------...,...,...,...,...,... |
1
11.11
11.11
...,...,...,...,...,fev |
1
11.11
22.22
...,...,...,...,ear,... |
1
11.11
33.33
...,...,...,thr,...,... |
1
11.11
44.44
...,...,con,...,ear,... |
1
11.11
55.56
...,cou,...,...,ear,fev |
1
11.11
66.67
run,...,...,...,...,... |
1
11.11
77.78
run,...,con,thr,...,... |
1
11.11
88.89
run,cou,con,thr,ear,fev |
1
11.11
100.00
------------------------+----------------------------------Total |
9
100.00
In knee surgery, when an artificial vein is implanted to replace a damaged vein, three
popular drugs to prevent clotting are coumadin, plavix, and aspirin (ASA), either
separately or in combination.
The researcher wants to see a frequency table of these combinations in an easy to read
format. Cut-and-paste the following into the do-file editor, highlight and execute it to set
up the dataset. Then, create a drug combination string variable similar to the symptoms
variable just demonstrated.
input coumadin plavix aspirin
1 0 0
1 1 0
0 1 0
0 0 0
. . .
0 0 1
0 1 1
1 1 1
end
list
The following would work,
* -- create a variable showing all symptoms found in chart review
* cou = coumadin
* plv = plavix
* asa = aspirin
capture drop drugs
gen str11 drugs = ""
replace drugs = "cou," if coumadin==1
replace drugs = "...," if coumadin==0
replace drugs=drugs+"plv," if plavix==1
replace drugs=drugs+"...," if plavix==0
replace drugs=drugs+"asa," if aspirin==1
replace drugs=drugs+"...," if aspirin==0
list
tab drugs, missing
Chapter 1-99 (revision 8 Jan 2012)
p. 20
Problem 5) Hierarchical combinations
Returning to the knee surgery study in Problem 4), the investigator wants to create a drug
group variable. A decision was made that a combination is a more correct category than a
single drug. So, the patient would be assigned to the combination group, rather than the
single drug. In this way, a patient can only belong to one group. Set up the Problem 4
dataset again, and then create a drug group variable with the following categories:
1 = ASA + coumadin + plavix
2 = coumadin + plavix
3 = ASA + coumadin
4 = ASA + plavix
5 = coumdin
6 = plavix
7 = ASA
8 = no drug
Be sure to check your work.
On a first attempt, you might try something like,
capture drop group
gen group=1 if aspirin==1 & coumadin==1 & plavix==1
replace group=2 if coumadin==1 & plavix==1
replace group=3 if aspirin==1 & coumadin==1
replace group=4 if aspirin==1 & plavix==1
replace group=5 if coumadin==1
replace group=6 if plavix==1
replace group=7 if aspirin==1
replace group=8 if aspirin==0 & coumadin==0 & plavix==0
list
1.
2.
3.
4.
5.
6.
7.
8.
+-------------------------------------+
| coumadin
plavix
aspirin
group |
|-------------------------------------|
|
1
0
0
5 |
|
1
1
0
6 | <- wrong answer
|
0
1
0
6 |
|
0
0
0
8 |
|
.
.
.
. |
|-------------------------------------|
|
0
0
1
7 |
|
0
1
1
7 | <- wrong answer
|
1
1
1
7 | <- wrong answer
+-------------------------------------+
The reason that does not work is that the group can be reassigned as you go along.
In a really large dataset, where it is unfeasible to check the classification by listing the
data, you can use a frequency table after each line to make sure that nothing gets
reclassified. With each replace command, assign a category only if a category has not
already been assigned. The following would work,
capture drop group
Chapter 1-99 (revision 8 Jan 2012)
p. 21
gen group=1 if aspirin==1 &
tab group
replace group=2 if group==.
tab group
replace group=3 if group==.
tab group
replace group=4 if group==.
tab group
replace group=5 if group==.
tab group
replace group=6 if group==.
tab group
replace group=7 if group==.
tab group
replace group=8 if group==.
tab group
list
1.
2.
3.
4.
5.
6.
7.
8.
coumadin==1 & plavix==1
& coumadin==1 & plavix==1
& aspirin==1 & coumadin==1
& aspirin==1 & plavix==1
& coumadin==1
& plavix==1
&aspirin==1
& aspirin==0 & coumadin==0 & plavix==0
+-------------------------------------+
| coumadin
plavix
aspirin
group |
|-------------------------------------|
|
1
0
0
5 |
|
1
1
0
2 |
|
0
1
0
6 |
|
0
0
0
8 |
|
.
.
.
. |
|-------------------------------------|
|
0
0
1
7 |
|
0
1
1
4 |
|
1
1
1
1 |
+-------------------------------------+
This time, all classifications are correct.
1 = ASA + coumadin + plavix
2 = coumadin + plavix
3 = ASA + coumadin
4 = ASA + plavix
5 = coumdin
6 = plavix
7 = ASA
8 = no drug
Problem 6) Dates
Cut-and-paste the following into the do-file editor, highlight and execute it to set up the
dataset.
clear
input str10 visit1date str10 visit2date
"03/04/2000" "03/10/2000"
"05/06/2001" "05/15/2001"
end
list
Create a variable that represents the number of days between the two visits.
Chapter 1-99 (revision 8 Jan 2012)
p. 22
The following would work,
gen date1 = date(visit1date,"MDY")
gen date2 = date(visit2date,"MDY")
gen followupdays = date2 - date1
list
+----------------------------------------------------+
| visit1date
visit2date
date1
date2
follow~s |
|----------------------------------------------------|
1. | 03/04/2000
03/10/2000
14673
14679
6 |
2. | 05/06/2001
05/15/2001
15101
15110
9 |
+----------------------------------------------------+
Chapter 1-9. More graphics: popular scientific graphs
Chapter 1-10. Programming Stata
Chapter 1-11. Compilation of frequently used variable generation and modifying
commands
Chapter 1-12. Stata results into Excel & Word
References
Anker SD, Colet JC, Filippatos G, et al. (2009). Ferric carboxymaltose in patients with heart
failure and iron deficiency. N Engl J Med 361(25):2436-48.
Hand DJ, Daly F, Lunn AD, McConway KJ, Osterowski E, editors. (1994). A Handbook of
Small Data Sets. New York, Chapman & Hall.
Onyike CU, Crum RM, Lee HB, Lyketsos CG, Eaton WW. (2003). Is obesity associated with
major depression? Results from the third national health and nutrition examination
survey. Am J Epidemiol 158(12):1139-1153.
Snedecor GW, Cochran GC. (1967). Statistical Methods, 6th ed, Ames, Iowa, Iowa State
University Press.
Chapter 1-99 (revision 8 Jan 2012)
p. 23