HILL, D.R. (1975b) Computer models for synthesising British English
advertisement
 Computer models for synthesising British English")
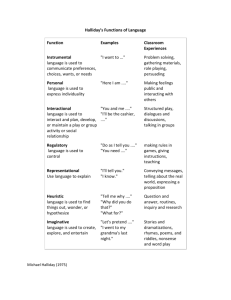
8th International Congress of Phonetic Sciences Leeds, UK, Aug 17-23, 1975 paper 129 p 1 Computer Models of British English Rhythm and Intonation David R. Hill Assoc. Professor, Dept. of Computer Science, The University, Calgary, Alberta, Canada. There are very few computer models of British English rhythm and intonation. Part of the reason lies in the relative absence of relevant models in the literature, and part in the fact that such descriptive models as do exist are lacking the kind of essential detail required for computer implementation. This paper is not intended as a survey of past or present efforts, but as a short statement of some practical experience we have had on the joint speech analysis and speech synthesis project that currently exists de facto between the universities of Calgary and Essex, currently comprising Ian Witten, Peter Madams, Rick Jenkins, Walter Lawrence and myself. In 1973 Ian and I set out to attempt speech synthesis by rule at both segmental and suprasegmental levels, based partly upon some rather simple segmental rules I had developed at Edinburgh University in 1964 using the published Haskins Laboratory work and the Phonetics Dept. experience with speech synthesis. Figure 1 illustrates the basic framework at the segmental level, the durations and steady-state values being looked up from a table. Such a model at the segmental level clearly indicates an early tendency towards a postural view of speech, albeit oversimplified, and no doubt reflects the influence of my tutors. At the suprasegmental level we faced two problems: patterns of segment timing had to be specified and pattern of voicing frequency variation determined. My research and experience (especially that of hearing infinitely compressed speech, in which there is no amplitude variation) strongly indicated that we need not worry about any special provision for patterns of intensity variation. The initial timing algorithm decided upon was simple. Like Mattingley, we used segment durations intrinsically determined from a table with lengthening (50% of the steady-state duration) of stressed vowels. However, under the influence of the isochronicity theory, especially as expounded by Abercrombie, we elected to view speech as having a foot structure based upon the stressed syllables and to modify the intrinsically determined element durations in each foot to provide a pronounced tendency for the stressed syllables to fall at equal intervals. The procedure involved “squashing” or “stretching” complete feet, towards a norm of 600 milliseconds duration, by scaling the steady state durations of its elements, after applying the stressing. Under favourable (?) circumstances the procedure produced precise isochrony, but there were limits on the amount of squashing or stretching allowed. The election was an important factor in the further decision to use Halliday’s (1970) prescription for voicing frequency variation, diagrammatically summarised in figure 2. Other factors were the notation, well suited to computer input; the comprehensiveness (it covered, at an adequate level of delicacy, enough patterns to deal with all sentences in an appropriate way); the explicit inclusion of the whole of each contour, giving continuity of specification; its relative simplicity, giving hope of viable implementation; and its link with grammatical usage, giving hope for future research on automatic assignation of appropriate contours. This list goes a long way to specifying the requirements such a model must satisfy in order to be suited to computer implementation, and the possession of these qualities by Halliday’s model probably reflects its successful design as a vehicle for communicating with students of English-as-a-foreign-language. paper 129 p 2 The first implementation (summer 1973) produced much amusement and was soon modified, for a subjective effect of plain-song chanting of speech was inescapable. Some passages could have been taken straight from the spoken part of a church service conducted by a vicar of the old school, insofar as they were credible at all. The basic trouble seemed to lie in lack of voicing frequency movement during pretonic feet, in voicing frequency movements that were too smooth and too predictable, in having too long a foot length and in having too regular a rhythm. Especially, we had ignored what Halliday calls the “sandhi” features of intonation patterns, but doesn’t specify. These amount to voicing frequency variations which necessarily occur with speakers, being an overlay on the basic intonation contour, and thus do not need to be specified in teaching people to speak correctly. Ian modified the timing algorithm, incorporating some of Walter’s ideas on syllable structure and its relation to segment duration which in turn derived from Abercrombie (Lawrence 1974) and introduced some pretonic foot voicing frequency shift, especially for tone-group 1, though retained the principle of tending to isochronicity. The result is the computer voice you hear on the tape, during the log in procedure to the speaking computer. Walter has continued his introspective approach to rhythm and intonation, using the same Essex computer system (developed as a component of the joint Essex-Calgary project) and the second tape you hear alternates between the same computer voice as before, and speech using the same segmental synthesis algorithm, but with timing and voicing frequency data supplied by hand on the basis of Walter’s ideas as to what is necessary. This also illustrates how the computer system may be used for comparison of different rule sets, and what improvement is possible, even on our present knowledge, given a computer formalisation of the knowledge that goes into Walter’s synthesis. In writing and modifying such program suites, many arbitrary decisions must be made, and much taken on trust. It behoves the aspiring computer speech-output programmer to gain as much linguistic knowledge as possible, and to talk to the right people. Despite the acceptability of the speech we can now generate, for people hearing it in the context of practical applications such as stores enquiries (components, delivery dates, etc.), it is clear that much improvement is needed. We have reacted in two ways. First, we have jointly written a new segmental-suprasegmental program suite which is just now working, and forms a basis for planned elaboration in the future. Brief mention is made of the segmental part in another paper in this proceedings (Hill 1975) and the suprasegmental module is outlined in Witten (1975). Detailed reports will become available, but the emphasis is on flexibility to permit information-gathering experiments with computer generated synthetic speech, and on a better defined interface between segmental and suprasegmental levels. Both these areas have caused problems with the present system. In parallel with this work, I have begun an analytic-spectrographic study of intonation and rhythm, observing that our knowledge of the basic cues and patterns is incomplete and may be wrongly structured, as well as observing that experiments in synthesis alone, based on invalid assumptions about real speech, may be very misleading. In view of the strange character of perception, it is not even certain that such cues and patterns are as people perceive them, for perception follows its own unstated assumptions and prejudices. Figures 3 and 4 show two voicing frequency analyses as specific but typical examples of the small set I have so far examined. The intonation contour is superimposed upon an approximation to a segmental. analysis, of the conventional type. Times are given in milliseconds. The original speech was generated and recorded to illustrate Halliday’s book (1970, study unit 30, sentences 1 and 2) and may be taken paper 129 p 3 as realisations of the contours specified by a trained speaker. It is interesting to compare these real speech intonation contours to Halliday’s paradigms, and to try to interpret the rhythm in terms of a theory of isochronicity. This very limited view is suggestive of some of the difficulties we face in implementing computer models of rhythm and intonation. Acknowledgements I would like to thank Ian Witten and Peter Madams of the EES Dept. at Essex University, as well as Walter Lawrence, for their collaboration in this research, and for many lively discussions on relevant topics. I would also like to thank my own University (of Calgary) for generously granting sabbatical leave, and Essex University for granting me facilities during this period. Finally, I should like to thank the National Research Council of Canada for the generous financial support over a number of years that has made the research possible. References HALLIDAY. M.A.K. (1970) A course in spoken English: Intonation. Oxford University Press. HILL, D.R. (1964) Unpublished experiments at Dept. of Phonetics, Edinburgh University. HILL, D.R. (1975) Avoiding segmentation in speech analysis: problems and benefits. Proc. 8th Int. Cong. of Phonetic Sciences, Leeds, 17th-23rd August 1975, paper no.l28. LAWRENCE, W. (l974) The phoneme, the syllable and the parameter track. Proc. of Speech Communication Seminar, K.T.H., Stockholm, August 1-3. WITTEN, I.H. (1975) A flexible scheme for assigning timing and pitch to synthetic speech. Technical Report EES-MMS-SYN 1-75 University of Essex: Colchester, U.K. [Later published under the same title in Language and Speech, 20(3), pp. 240-260, July-September.] paper 129 p 4 1. Basic segmental synthesis framework (Hill 1964). paper 129 p 5 The dashed lines indicate the start of each tonic. For cases where the contour is linear for the tonic, note that if more than one syllable occurs, more change occurs on the first syllable than the remainder. The above summary is a condensed basic statement of the main features. 2. Summary of the main features of different intonation contours required as a basic framework for British English intonation following Halliday (1970). • 3. Two typical voicing frequency tracings taken from recordings accompanying Halliday (1970), study unit 30. paper 129 p 6 Eighth International Congress of Phonetic Sciences Paper 129 17-23 August 1975 DISCUSSION SHEET paper presented by HILL on Friday 22nd at 16.20 YOUR NAME: STEVE MARCUS PLEASE RECORD ON THIS SHEET, writing very clearly, a brief summary, in English, French or German, of what you have just said. Then hand in the sheet, at the Secretariat, so that your contribution may reach the presenter of the paper as soon as possible, for him to record his reply (on the back if necessary). PRESENTERS are requested to return the completed sheet to the Secretariat before the end of the Congress. AUTHOR’S REPLY A strict interpretation of isochrony in spoken English must be concerned with the interval between successive word stresses. However, one problem is that we lack, at present, a reliable objective set of criteria for deciding that a syllable carries such stress; nor have I seen a published discussion of such problems as words bearing double stress, in the context of isochronicity (how does “isochronicity” fit into the foot structure, for example). Walter Lawrence suggests that simple cases (“blackbird” for example) are accommodated by foot reduction -- two successive feet for the two syllables, but having a total duration of only one and a half feet, with a foot boundary in the middle of the word, our simple squashing/stretching algorithm would produce much the same effect. But even assigning stress (which is what assigning foot boundaries amounts to) is a subject of debate. Jonathan Allan, at MIT Research Lab of Electronics used the ChomskyHalle approach in assigning word stress for speech synthesis. The problem of looking for isochrony quickly assumes the character of looking for a real (?) invisible man, if we are not careful. However, from the point of view of natural rhythm -- even intelligibility -- in synthetic speech by rules, isochronicity, or any other theory dealing only with the spacing of stressed syllables is not enough. Indeed we do need a theory dealing with the finer time structure of syllables. Our current computer program for synthesis has some rules for this, but I am currently including the syllable structure problem in my general research effort. I would not be surprised if the syllable turned out to be the important fundamental speech unit for many purposes , although I am not working on that assumption yet. Eighth International Congress of Phonetic Sciences Paper 129 17-23 August 1975 DISCUSSION SHEET Paper presented by HILL on Friday 22nd. at 16.20 YOUR NAME: J.D. O’Connor PLEASE RECORD ON THIS SHEET, writing very clearly, a brief summary, in English, French or German, of what you have just said. Then hand in the sheet, at the Secretariat, so that your contribution may reach the presenter of the paper as soon as possible, for him to record his reply (on the back if necessary). PRESENTERS are requested to return the completed sheet to the Secretariat before the end of the Congress. AUTHOR’S REPLY This is an excellent point and I thank you for your question. I think the main relevant difference between the two theories is that Jassem allows the equivalent of “anacrusis” in his metrical calculations, i.e. unstressed syllables that are not counted in determining the time interval between successive beats. If observed departures from Abercrombie’s simpler statement of isochronicity always took the form of unexpectedly lengthened feet which also contained syllables that would not be counted under Jassem’s formulation, then your suggestion could be valid. In practice I find discrepancies between foot lengths of the order of 2-300%, while George Allen tells me he has found interval variations on a five to one ratio. Such variation is outside any reasonable interpretation of anacrusis. However, I do take the point that one should not entirely dismiss isochronicity just because measurements on real speech disagree with a simple interpretation.