Chapter 5 Biological Molecules (Macromolecules)
advertisement
")
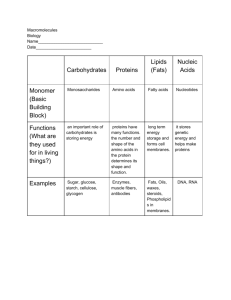
Biology 120, Sec. 10 J. Greg Doheny Chapter 5 Biological Molecules (Macromolecules) Notes: Chemical molecules important to biology (biological molecules) are sometimes called macromolecules because they are large (‘macro’ means large). The four important classes of macromolecules we’ll study for this course are carbohydrates (sugars or ‘saccharides’), lipids, proteins and nucleic acids. Monomer vs. Polymer: Most of the larger macromolecules are assembled by linking together smaller units that are all identical. The individual smaller units are called monomers, and when you link them together they are called a polymer. For example, proteins are polymers that are made up of individual amino acids, linked together into a chain. Cellulose is a polymer made of individual beta-Glucose monomers linked together into a chain. Enzymes: Enzymes are proteins that catalyze chemical reactions, including putting together and/or taking apart polymers. Because enzymes are proteins, they are encoded by genes. Hydrophobic vs. Hydrophilic: Water is very important to biology. Macromolecules that do not mix well with water are said to be hydrophobic (‘phobe’ means to dislike). Water is a polar molecule, and hydrophobic macromolecules tend to be non-polar, and therefore do not mix well with water. Fats and oils are examples of hydrophobic macromolecules. (What happens when you try to mix oil with water? They refuse to mix!) Macromolecules that mix well with water are said to be hydrophilic (‘phile’ means to like), and are usually polar. Important Biological Molecules CARBOHYDRATES CARBOHYDRATES: The term ‘carbohydrates’ usually refers to sugars, either individually or polymerized into chains. Another term for sugars is ‘saccharides.’ Monosaccharides are individual sugars (ie-glucose), disaccharides are two sugars bonded together (ie-sucrose, which is one molecule of glucose and one molecule of fructose), and polysaccharides are long chains of individual sugar molecules linked together (ie-cellulose is a long chain of glucose monomers). Most of the sugars we’ll deal with in biology are either pentoses (5 carbons in the ring, like ribose), or hexoses (six carbons in the ring, like glucose). The bonds that link monosaccharides together into either disaccharides or polysaccharides are called glycosidic bonds. Two important monosaccharides are glucose (a hexose) and ribose (a pentose). Polymers of glucose can form either starch or cellulose. Polymers of ribose form either DNA or RNA. (In the case of DNA, one of the oxygens is removed, hence the name ‘Deoxyribonucleic Acid.”) Important disaccharides include sucrose (glucose and fructose), maltose (two molecules of glucose), and lactose (glucose and galactose). Lactose is also known as ‘milk sugar’ and is the 1 main carbohydrate present in milk. Note that all of these biologically important saccharides contain glucose. (Note that glucose is also sometimes referred to by other names, such as ‘dextrose’ and ‘berry sugar’ on food product labels.) Numbering the Carbons in a Monosaccharide Ring: (See Figure 5.8) Take the first carbon to the right of the oxygen, and number the carbons (starting from 1) in clockwise order. Then put the ‘prime’ symbol next to the number (1’, 2’, 3’ etc. Pronounced ‘one prime,’ ‘two prime’ etc.). Note that when glucose forms a ring, it can have one of two forms (Figure 5.8a). If the hydroxyl group attached to carbon 1 is below the plane of the carbon it is called alpha-glucose, if it is above the plane it is beta-glucose. This difference is critical, as some organisms can digest or break down only one of these two forms. It is also critical to the difference between the polysaccharides starch and cellulose, both of which are polymers of glucose (see below). Storage Carbohydrates: Glucose is the main energy source for both plants and animals, and is often stored, as a reserve supply, as a polymer. Animals store a glucose polymer called glycogen, and plants store a glucose polymer called starch. Plants typically store large amounts of starch as an energy reserve, but animals do not store large amounts of glycogen. Instead, they store other materials (fats) that can be converted into glucose. Plants also use a polymer of glucose called cellulose as a structural support. Animals (like humans) have the enzymes needed to break starch down into its individual glucose monomers, which is why we can eat plants that store large amounts of starch (ie-corn, potatoes). Animals do not have the enzymes needed to break cellulose down into its individual glucose monomers, which is why we cannot digest wood, cotton, or straw. Some bacteria and fungi possess the enzymes needed to break down cellulose. Some rare animals and insects are able to digest cellulose, but only because they have cellulose-digesting bacteria and fungi living synergistically in their guts. The only difference between starch and cellulose is that starch is made up of only alpha-glucose, while cellulose is made up of beta-glucose. CHITIN: Chitin is an important structural polysaccharide made from a substitution variant of glucose (another chemical group has been substituted at the 2’ carbon; see Figure 5.9). Chitin makes up the exoskeleton of arthropods (insects, crustaceans etc.), and is also present in many fungi. LIPIDS Lipids are long, hydrophobic chains of carbohydrates. phospholipids and steroids. There are three main types: fats, FATS: Glycerol is a three carbon alcohol (see Figure 5.10). When the three hydroxyl groups are attached to three ‘fatty acid’ chains (ie-palmitic acid) by ester linkages, it is called a fat molecule, or a triacylglycerol (Figure 5.10). Such fats are used as both an energy storage material (ieadipose tissue, or fat tissue in animals), and a structural material. If every carbon atom in the chain is ‘saturated’ with hydrogens, it is called a ‘saturated fat.’ In ‘unsaturated fats’ some of the carbon atoms are double bonded to each other, rather than to hydrogens. Because the double bonds introduce bends into the chains, they do not stack together as easily, and form oils rather 2 than semi-solids (Figure 5.11). Thus, butter is a saturated fat, but vegetable oil (ie-canola oil) is an unsaturated fat. Margarine is made by bubbling hydrogen gas through vegetable oil, thus converting an unsaturated fat (an oil) into a saturated fat (a butter-like substance called margarine). Note that unsaturated fats can have the hydrogens on the same side of the carbons (called ‘cis fats’) or on opposite sides (called ‘trans fats’). For unknown reasons, trans fats contribute more to atherosclerosis (hardening of the arteries) than cis fats and saturated fats. Because of this, food manufacturers are attempting to reduce the amount of trans fats in foods. PHOSPHOLIPIDS: Phospholipids are the main constituents of the cell membrane, also known as the ‘lipid bilayer’ or ‘phospholipid bilayer.’ Phospholipids are a variation of triacylglycerol motif, where a phosphate group has been substituted for one of the fat chains. Thus, they have a hydrophilic phosphate group at one end, which mixes well with water, and two hydrophobic fatty tails at the other. Because one end is hydrophilic and the other hydrophobic, they tend to form a bilayer (two layers), a type of ‘sandwich’ which has the two hydrophilic phosphate parts facing the water, and the two hydrophilic parts facing each other (see Figures 5.12 and 5.13). Because the fatty chains are not fully saturated, the bilayer is more like an oil than a solid, and it allows various things that are embedded in the bilayer to move laterally. STERIODS: Steroids are another variation of the carbon chains that form the hydrophobic tails of fats. Instead of being saturated, the carbon chains form into ring structures (Figure 5.14). These ring structures are rigid, and are often inserted into the phospholipid bilayer of the cell membrane to add strength to it (ie-cholesterol). Steroids are also used as intracellular signals (iesteroid hormones). PROTIENS Proteins are made up of polymers of amino acids (Figure 5.16). There are 20 different amino acids, all of which have the same basic structure, consisting of a central carbon attached to a hydrogen, an amino group (NH3+), a carboxyl group (COO-), and a variable ‘side chain’ abbreviated by the letter R (see Figure 5.16). Proteins are made by linking long chains of amino acids together. The linking process takes place on microscopic structures inside the cell called ribosomes. The linkages are called peptide bonds. The individual amino acids that make up a protein are sometimes referred to as amino acid ‘residues.’ When several amino acid residues are linked together they are referred to as a polypeptide chain. Polypeptide chains (and proteins in general) have what is called an amino terminus (the NH3+ end) and a carboxyl terminus (the COO- end), which correspond to the 5’ end and the 3’ end codons of the mRNA which encoded it. When polypeptide chains become very long, we stop calling them polypeptide chains and start referring to them as proteins. The physical properties of a protein are determined by the composition and order of amino acids that make it up. Each amino acid has physical properties that are determined by the side chain. Some amino acids have acidic side chains (ie-glutamic acid, abbreviated Glu, or E), others have basic side chains (ie-lysine, abbreviated Lys, or K). Some amino acids have hydrophobic side chains (ie-alanine, abbreviated Ala, or A) while others have hydrophilic side chains (ie-serin, abbreviated Ser, or S). Some amino acid side chains contain aromatic groups (ring structures; ie3 tyrosine, abbreviated Tyr, or Y). The amino acid proline (Pro, or P) is important because it will introduce a rigid bend into any protein it is incorporated into. The amino acid cysteine (Cys or C) is also important because when two cysteins are incorporated into a protein they can react with each other, forming a covalent bond between them called a disulfide bridge. Thus, the composition and order of the amino acids that make up a protein will determine the physical and chemical properties of that protein. Proteins that contain many basic amino acids will be basic, and have a net positive charge (ie-the histone proteins, around which negatively charged DNA is wrapped). Many proteins serve as enzymes (proteins that carry out chemical reactions), and have a set of negatively and positively charged amino acids in what is called their ‘active site.’ The active site of an enzyme is the most critical part of the protein. Most enzymes can tolerate mutations (changes to the DNA that result in amino acid substitutions) to any other part of the protein, but not to the active site. The shape and folding pattern of a protein is also important to its function. Most proteins are folded in such a way that their hydrophobic amino acids are buried on the inside (facing each other) and their hydrophilic amino acids are on the outside (facing the water). If you heat up a solution containing proteins, or immerse the proteins in an organic solvent, the protein will ‘unfold,’ and ‘denature,’ and no longer function as it was intended to. Levels of Protein Structure (see Figure 5.20): The sequence of amino acids that make up a protein is called the protein’s primary structure. In some cases, the order of amino acids will allow the polypeptide chain to form a helix (called an alpha-helix) when hydrogen bonds are formed between different side chains within the same polypeptide. In other cases, hydrogen bonding between side chains will cause the polypeptide chain to form a kinked ribbon that folds back on itself to form a sheet structure (called a beta pleated sheet). If the primary amino acid sequence causes a protein to form alpha-helices or beta-pleated sheets, or both, this is referred to as the protein’s secondary structure. If a protein forms several helices and sheets, and these are arranged into an elaborate three dimensional structure it is referred to as the protein’s tertiary structure. When two or more protein chains come together, and are held together by various types of bonds, it is referred to as a protein’s quaternary structure. Finally, proteins will sometimes incorporate a different type of molecule, such as a metal ion, or a steroid carbohydrate structure, within itself. The additional, non-protein part is referred to as a prosthetic group. For example, hemoglobin (the protein that carries oxygen in the blood) is composed of four individual peptide chains (its quaternary structure), each of which has a heme prosthetic group containing an iron ion. NUCLEIC ACIDS The term Nucleic Acids refers to DNA and RNA. Proteins are encoded by genes that are located in the nucleus of the cell. Genes are made of DNA. An RNA copy of the gene (called a messenger RNA or mRNA) is made in the nucleus, transported out to the cytoplasm, and converted into a protein by a ribosome. Making an RNA copy of a DNA template is called ‘transcription,’ and converting the mRNA sequence into a sequence of amino acids (a protein) is called ‘translation.’ The ‘code’ used to translate the nucleic acid sequence into a sequence of amino acids is called the Genetic Code. (See the Genetic Code table at the end of this handout.) 4 The ‘backbone’ of both DNA and RNA is the pentose sugar Ribose (see Figure 5.26c). In the case of DNA, the 2’ carbon is missing an oxygen (hence the name ‘Deoxyribonucleic Acid). In DNA, each ribose has a nitrogenous base attached to its 1’ carbon. There are four nitrogenous bases to choose from (Cytosine, Thymine, Adenine, and Guanine; see Figure 5.26b). The nitrogenous bases are often referred to simply as ‘bases,’ and can be abbreviated C, T, A and G. A and G are members of a class of bases called Purines, and C and T are members of a class called Pyrimidines. One or more phosphate groups are also attached to the 5’ carbon of the ribose backbone. A deoxyribose sugar with a base and a phosphate group is called a Nucleotide. Nucleotides are the monomers that make up DNA. Initially, each nucleotide will have three phosphate groups attached to the 5’ carbon, and be called a ‘nucleotide triphosphate.’ The name for each nucleotide is derived from the name of the base combined with the name of the sugar. For example, if the base is Adenine (A), the nucleotide will be called deoxyadenosine. If it has three phosphate groups, it will be called Deoxyadenosine Triphosphate (abbreviated (d)ATP). If the ribose sugar is not missing its 2’ oxygen (as in RNA) it will be called Adenosine Triphosphate (abbreviated ATP). Initially, each nucleotide will have three phosphate groups at the 5’ end. When they are linked together into a chain, two of the phosphates will be removed. Thus, only the nucleotide at the 5’ end of the chain will have all three phosphates. DNA nucleotides are linked together by an enzyme (a protein) called DNA Polymerase, and RNA nucleotides are linked together by an enzyme called RNA Polymerase. Single DNA strands are not stable, so a DNA chain is normally paired with another DNA chain, and the two DNA chains are bound together by hydrogen bonding between the bases. The hydrogen bonding occurs in a very specific order! C always binds with G, and A always binds with T. Thus, the DNA ‘Double Helix’ is composed of two chains of DNA running in opposite directions, with the ribose backbones on the outside, and the bases on the inside, holding the helix together by hydrogen bonding (Figure 5.27). In addition to RNA having the extra oxygen at the 2’ position, the other main difference between DNA and RNA is that RNA uses a base called Uracil instead of Thymine (Figure 5.26). PRACTICE QUESTIONS: Short Answer Questions: 1. What monomers make up proteins? 2. What monomers make up nucleic acids? 3. What is the difference between cellulose and starch? (2 points) 4. What is the difference between a hexose and a pentose? 5. List the name of one biologically important hexose. 6. List the name of one biologically important pentose. 7. What is the difference between a monosaccharide and a disaccharide? (2 points) 8. Is glucose a monosaccharide or a disaccharide. If it is a disaccharide, what are the two monomers? 9. Is maltose a monosaccharide or a disaccharide? If it is a disaccharide, what are the two monomers? 10. Is sucrose a monosaccharide or a disaccharide? If it is a disaccharide, what are the two monomers? 5 11. What is a polysaccharide? 12. What do you call the bond that joins to monosaccharides together? 13. What is the name of the carbohydrate that makes up the backbone of RNA? 14. What is the name of the carbohydrate that makes up the backbone of DNA? 15. Is the phosphate group at the 5’ end or the 3’ end of a nucleotide? 16. Which carbon of the ribose backbone is missing an oxygen in DNA as opposed to RNA? 17. What biomolecules are used to form the cell membrane? 18. What do you call two different sugars that are linked together? 19. What sugar monomer is starch made of? 20. What sugar monomer is cellulose made of? 21. What do you call a biomolecule that ‘dislikes’ water, and is usually not soluble in water? 22. What do you call a biomolecule that ‘likes’ water, and is usually soluble in water? 23. What do you call a protein that catalyzes chemical reactions? 24. The glucose monomer is the main energy source for both plants and animals. What form (polymer form) do animals store glucose in? 25. The glucose monomer is the main energy source for both plants and animals. What form (polymer form) do plants store glucose in? 26. The glucose monomer is both an energy source and a structural support for plants. What is the name of the glucose polymer that plants use to store energy, and what is the name of the glucose polymer that plants use as a structural support? (2 points) 27. List the name and one letter abbreviation for an acidic amino acid. 28. List the name and one letter abbreviation for a basic amino acid. 29. List the name and one letter abbreviation for the amino acid that can form disulfide bridges. 30. List the name and one letter abbreviation for the amino acid that introduces a bend into a peptide chain. 31. List the name and one letter abbreviation for an amino acid that contains an aromatic group. 32. Draw out the general chemical form of an amino acid, indicating the side chain with the letter R. 33. List the four nitrogenous bases that are incorporated into nucleotides to make DNA. (4 points) 34. List the nitrogenous base that is incorporated into RNA in place of thymine. 35. The four nitrogenous bases can be abbreviated A, C, G and T. Which two are purines and which two are pyrimidines? (2 points) 36. The four nitrogenous bases can be abbreviated A, C, G and T. Which form hydrogen bonds with which? 6 Extended Matching Inventory Question: Match The Term To The Definition: A. Adenine and Guanine N. Lysine B. Alanine O. Maltose C. Alpha-helix P. Nucleotide D. Amino acid Q. Phospholipid E. Beta pleated sheet R. Proline F. Cellulose S. Prosthetic group G. Cysteine T. Ribosome H. Cytosine and Thymine U. Serine I. Denaturation V. Starch J. Glucose W. Sucrose K. Glutamic acid X. Triacylglycerol L. Glycogen Y. Tyrosine M. Lactose Z. Uracil 1. A hydrophobic amino acid. 2. The often irreversible unfolding of a protein, leading to loss of its biological activity. 3. A variation of a triacylglycerol where one of the fatty acid chains has been replaced by a phosphate group. (The main constituent of the cell membrane.) 4. An amino acid that will put a rigid bend into a protein. 5. A basic amino acid. 6. Name for the monomer of DNA (or RNA), consisting of a ribose molecule and a nitrogenous base. 7. Purines 8. Pyrimidines 9. A variant of Thymine that is used in RNA. 10. A disaccharide made of glucose and fructose 11. A disaccharide made of glucose and galactose. 12. A disaccharide made of two molecules of glucose. 13. A polymer of glucose used for energy storage by animals. 14. A polymer of alpha-glucose used for energy storage by plants. 15. A glycerol backbone linked to three hydrophobic hydrocarbon chains. 16. A kinked ribbon structure that a protein can assume (secondary structure). 17. The microscopic anvil-shaped organelle where proteins are put together. 18. A pentose sugar. 19. An acidic amino acid. 20. Name for a non-protein accessory to a protein. 21. An amino acid that can form a disulfide bridge 22. A hexose sugar. 23. The monomer that proteins are made of. 24. A coiled structure that proteins sometimes assume (secondary structure). 25. Plant structural material made of polymerized beta-glucose 7 PHYSICAL PROPERTIES OF PROTEINS QUESTION: Using the Genetic Code chart above, translate the following mRNAs into protein, and comment about the physical properties of the protein based on their primary amino acid sequence. Also, indicate which amino acid is at the amino terminus and which is at the carboxyl terminus of the protein. 1. 2. 3. 4. 5. 6. 5’- AUG AGG AAA AGA UAA AAG AAA UAA-3’ 5’- AUG GAU GAA GAC GAG UAA-3’ 5’-AUG GCU GCC GCG AUU UAA-3’ 5’-AUG AGU ACU AGC ACC ACA UAA-3’ 5’-AUG UGU AGC ACA UGC UAA-3’ 5’-AUG AGU ACU CCU ACC ACA UAA-3’ © J. Greg Doheny 2014 8