Worksheet 4
advertisement

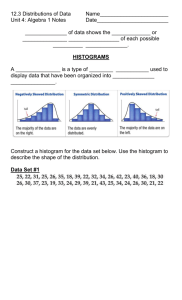
Worksheet 4: Histograms, Box plot, and Scatter plot Learning Objectives: open and close a project load a shape file select functions from the menu or toolbar. create a histogram for a variable change the number of categories depicted in the histogram create a regional histogram create a box plot for a variable Activities: This exercise will introduce a tool for exploratory Data Analysis, called GeoDA. The open source version of this tool is available from VLABS, under \\UP.IST.LOCAL\VA\data\GeoDa\OpenGeoDa.exe Step 1 Getting to know menus and toolbars. Start OpenGeoDa from the folder: \\UP.IST.LOCAL\VA\data\GeoDa\OpenGeoDa.exe Go to File menu and choose “Open Shape File.” Navigate to the directory: \\UP.IST.LOCAL\VA\data\GeoDa\Data\ and choose to open the St. Louis homicide sample data set for 78 counties surrounding the St. Louis metropolitan area (stl hom.shp). Explore the menus and toolbars for a moment. Step 2. Creating quantile maps and view tables. Close all windows of OpenGeoDa, and then open the shape file SIDs2.shp. The SIDS data set Contains variables for the count of SIDS deaths for 100 North Carolina counties in two time periods, here labeled SID74 and SID79. In addition, there are the count of births in each county (BIR74, BIR79) and a subset of this, the count of non-white births (NWBIR74, NWBIR79). Construct two quantile maps to compare the spatial distribution of non-white births and SIDS deaths in 74 (NWBIR74 and SID74). Click on the base map to make it active (in GeoDa, the last clicked window is active). In the Map Menu, select Quantile. A dialog will appear, allowing the selection of the variable to be mapped. In the Variables Settings dialog, select NWBIR74 and keep the number classes to be the default of 4. [Question] What does the number on the right of the legend (in parentheses) mean? Why they are all 25? Use the cursor to drag a box to select a few counties. Then try to view the attribute table by clicking menu: Table Move Selected to Top. Try different selection from either the table view or the map view. Observe how selections on the two views are linked. Next, apply a range selection (from table menu), so that BIR74 is in the range of <0, 500>. Show your result of the table and map. Step 3. Histogram With the map view open, invoke the histogram as Explore > Histogram from the menu. In the variable settings dialogue, choose “NWBIR74”. The result is a histogram with the variables classified into 7 categories. You may change the number of categories by going to the “Options” menu and “Intervals”. Show a histogram when the interval is set to 9. Step 4. Boxplot Clear all windows and start a new project using the stl hom.shp homicide sample data set. Invoke the box plot by selecting Explore > Box Plot from the menu, or by clicking on the Box Plot toolbar icon. Next, choose the variable HR8893 (homicide rate over the period 1988–93) in the dialog. Click on OK to create the box plot. Specific observations in the box plot can be selected in the usual fashion, by clicking on them, or by click-dragging a selection rectangle. The selection is immediately reflected in all other open windows through the linking mechanism. While you have the table and base map open for the St. Louis data, select the outlier observations in the box plot by dragging a selection rectangle around them. Show where are the outliers on the map view. Step 5. Scatter plot Invoke the scatter plot functionality from the menu, as Explore > Scatter Plot. In the Dialogue, select HR7984 (the county homicide rate in the period 1979–84) in the left column as the y variable and RDAC80 (a resource deprivation index constructed from census variables) in the right column as the x variable. Click on OK to bring up the basic scatter plot. The scatter plot in GeoDa has two useful options. They are invoked by selection from the Options menu or by right clicking in the graph. While having the scatter plot open, bring up the options menu and choose Scatter plot > Standardized data. This converts the scatter plot to a correlation plot, in which the regression slope corresponds to the correlation between the two variables (as opposed to a bivariate regression slope in the default case). The variables on both axes are rescaled to standard deviational units, so any observations beyond the value of 2 can be informally designated as outliers.