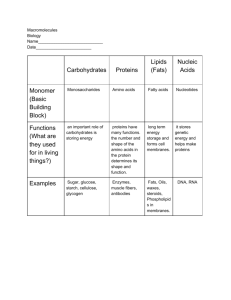
Chapter 1 The foundations of biochemistry Living organisms have
advertisement

Chapter 1 The foundations of biochemistry Living organisms have distinguishing features: (1) A high degree of chemical complexity and microscopic organization. (2) Systems for extracting(吸收), transforming, and using energy from the environment. (3) A capacity for precise(精密的) self-replication and self-assembly. (4) Mechanisms for sensing and responding to alterations in their surroundings by adapting internal(内部的) chemistry. (5) Defined functions for each of their components and regulated interactions among them. (6) A history of evolutionary change. 1.1 Cellular foundations 1. Cells are the structural and functional units of all living organisms(except viruses) Hydrophobic(疏水的) plasma membrane(细胞膜) is composed of lipid and protein, giving it flexibility. Ions and most polar compounds can pass it freely. There are transport proteins helping passage, receptor proteins and enzymes. Cytoplasm(细胞质) has cytosol(细胞液) containing enzymes, RNA, amino acids, nucleotides, metabolites(代谢产物), intermediates(中间体), coenzymes, ions and ribosomes(核糖体). Genome is in nucleus( 细 胞 核 ) or nucleoid( 核 状 体 ). Eukaryotes( 真 核 生 物 ) have nuclear envelope( 核 膜 ) and prokaryotes(原核生物) not. 2. Cellular dimensions are limited by oxygen diffusion Typical animal and plant cells are 5 to 100 μm in diameter and bacteria 1 to 2 μm long. The smallest cells are mycoplasmas(支原体). The lower limit is set by the biomolecule type, and the upper limit the rate of diffusion(扩散) of molecules. The ratio of surface area to volume is important to be large. 3. There are three distinct domains of life Archaebacteria( 古 / 原 细 菌 )/Archaea inhabiting extreme environments, eubacteria( 真 细 菌 )/Bacteria and eukaryotes evolving from the same branch for archaebacteria. In Archaea and Bacteria, there are aerobic(需氧) and anaerobic(厌氧) getting energy by transferring electrons to nitrate(N), sulfate(S) or CO2. Obligate anaerobes(专性厌氧生物) die when exposed to oxygen. Another way to classify organisms: phototrophs( 光 养 型 ) and chemotrophs( 化 养 型 ). In phototrophs, there are autotrophs(自养) and heterotrophs(异养). All chemotrophs are heterotrophs. In chemotrophs, there are lithotrophs(无机营养) and organotrophs(有机营养). 4. Escherichia coli is the most-studied prokaryotic cell E. coli has peptidoglycans(肽聚糖) to keep shape and rigidity(刚性). In Archaea is kept by pseudopeptidoglycan(假肽聚 糖). Plasma membrane and outer layers constitute cell envelope. Gram-negative bacteria have outer membrane and thinner peptidoglycan layer, while Gram-positive bacteria have no outer membrane and thicker peptidoglycan layer. There are plasmids(质粒) conferring resistance to toxins(毒素) and antibiotics(抗生素). 5. Eukaryotic cells have a variety of membranous organelles, which can be isolated for study Mitochondria(线粒体), endoplasmic reticulum(内质网), Golgi complexes(高尔基体) and lysosomes(溶酶体). Plant cells have vacuoles(液泡) and chloroplasts(叶绿体). There are also granules(颗粒) or droplets(小滴) containing nutrients such as starch(淀粉) and fat. First homogenization(均化作用), then centrifuged(离心) can make levels of different organelles sedimentation position(沉积位点). 6. The cytoplasm is organized by the cytoskeleton and is highly dynamic Cytoskeleton(细胞骨架) has actin(肌动蛋白) filaments, microtubules(微管) and intermediate filaments(中间纤维). First two help producing motion of organelles or the cell. Filaments are not permanent(永久) and change between disassembling and reassembling, also change their positions. Endomembrane system segregates(分离) different processes and provides surfaces for reactions. Exocytosis(胞吐) and endocytosis(胞吞) come from that. 7. Cells build supramolecular(超分子) structures Macromolecules are held together by noncovalent interactions weaker than covalent bonds. There are hydrogen bonds(H 键), ionic interactions, hydrophobic interactions(疏水作用) and van der Waals interactions. 8. In vitro(生物体外) studies may overlook important interactions among molecules Centrifugations(离心), chromatography, electrophoresis are used. We must consider the situation in vivo(生物体内). 1.2 Chemical foundations Most elements in living matter have relatively low atomic numbers. H, O, N, C make up over 99%. 1. Biomolecules are compounds of carbon with a variety of functional groups Half of the dry weight of cells is C. Carbon-carbon single bonds(0.154nm) are important. Double bond is 0.134nm and allows litter rotation. Functional groups are added to carbon skeletons. There are methyl(甲基), amino(氨基), ethyl(乙基), amido(酰氨基), phenyl(苯基), guanidino(胍基), aldehyde/carbonyl (醛), imidazole(咪唑), ketone/carbonyl (酮), sulfhydryl(巯 基 SH), carboxyl(羧基), disulfide(二硫化物), hydroxyl(羟基), thioester(硫代酸酯), ether(醚), phosphoryl(磷酰基), ester(酯), phosphoanhydride(两个磷酸形成酯键), anhydride(酸酐), mixed anhydride/acyl phosphate(混合酐/酰基的磷酸酯). Other biomolecules are derivatives(衍生物) of hydrocarbons(CH). 2. Cells contain a universal set of small molecules Cells share some same biomolecules. Some have secondary metabolites(次级代谢产物) including some drugs. The whole of biomolecules is called metabolome compared with genome. 3. Macromolecules are the major constituents of cells Proteins and nucleic acids are informational macromolecules. Polysaccharides( 多 聚 糖 ) store energy and make extracellular(胞外) structural elements. Oligosaccharides(低聚糖) can be signals. Lipids can be structural components of membranes, fuel, pigments(色素) and intracellular signals. 4. Three-dimensional structure is described by configuration(构型) and conformation(构象) Stereochemistry(立体化学) research stereoisomers(立体异构体) i.e. configurations. Biomolecules have stereospecific(立 体特异性). Three ways to illustrate configuration: perspective(透视) diagram, ball-and-stick model and space-filling model. Configuration comes from double bonds and chiral centers(手性中心). The first gives geometric isomers(几何异构) or cis-trans isomers (顺反异构). The second gives enantiomers(对映异构体) and diastereomer(非对映异构体). Enantiomers have nearly identical chemical properties but not in physical property. Racemic mixture(外消旋体) shows no optical rotation. RS system: The smallest group pointing away from the viewer, if the other three groups from big to small is in clockwise order then is R else is S. Conformation comes from rotation of single bonds. Staggered(错开) is more stable, and the eclipsed(重叠) is least stable. 5. Interactions between biomolecules are stereospecific Chiral molecules are usually present in one of chiral forms, amino acids in proteins are L, glucose only D. 1.3 Physical foundations 1. Living organisms exist in a dynamic steady state, never at equilibrium with their surroundings The constancy of concentration is because of a dynamic steady state, which needs energy. 2. Organisms transform energy and matter from their surroundings System and surroundings constitute the universe. Isolated system exchanges nothing, closed system exchanges energy and open system exchanges both energy and matter with surroundings. Living organisms derive energy from chemical fuels or directly sunlight. 3. The flow of electrons provides energy for organisms Oxidation-reduction(氧化还原) reactions: 6CO2+6H2O=C6H12O6+6O2 by light, C6H12O6+O2=6CO2+6H2O+energy. 4. Creating and maintaining order requires work and energy Free-energy content(G)=enthalpy(H)-T*entropy(S). Endergonic(吸能) reactions need other exergonic(放能) reactions, usually the energy released by hydrolysis(水解) of phosphoanhydride(二磷酸键) bonds such as adenosine triphosphate(三磷酸 腺苷 ATP). They share intermediate, so to make ΔG negative. 5. Energy coupling links reactions in biology Equilibrium is a steady state. Some energy is used by friction(摩擦) to increase entropy. 6. Keq and ΔG° are measures of a reaction’s tendency to proceed spontaneously Keq=生成物比反应物平衡活度/有效浓度的系数次方乘积, ΔG=ΔG°+RTlnQ, Q 为任意情况比值. ΔG°=-RTlnKeq. 7. Enzymes promote sequences of chemical reactions The sequences of reactions are pathways. Catabolism(氧化作用) degrade organic nutrients. Anabolism(合成代谢) can synthesize new things. Their major connecting link is ATP. The overall network of enzyme-catalyzed pathways is metabolism(新陈代谢). 8. Metabolism is regulated to achieve balance and economy Feedback inhibition(反馈抑制) is one important way. Metabolism is a meshwork(网) of interconnected(相互连接) and interdependent(相互作用) pathways, so discrete(离散) pathways concept is simplification. 1.4 Genetic foundations 1. Genetic continuity is vested(归属) in single DNA molecules DNA is deoxyribonucleic acid. 2. The structure of DNA allows for its replication and repair with near-perfect fidelity Deoxyribonucleotides(脱氧核糖核苷酸) are in a linear sequence, two polymeric strands are twisted to form double helix. 3. The linear sequence in DNA encodes proteins with three-dimensional structures Proteins fold according the sequence of amino acids, during which molecular chaperones(分子伴侣) help discourage incorrect folding. Native conformation of a protein is crucial to function. The environment can affect that. 1.5 Evolutionary foundations 1. Changes in the hereditary instructions allow evolution Mutations in reproductive cells occasionally better equip organism or cell to survive so to have advantages to wild-type. Two copies make it possible to keep the original gene while producing a new gene. 2. Biomolecules first arose by chemical evolution Aleksandr I. Oparin’s theory: At first the atmosphere was rich in methane(甲烷), ammonia(氨气) and water and devoid(缺 乏) of oxygen. Electrical energy from lightning and heat energy from volcanoes make them react to form organic compounds dissolving in the ancient seas to be primordial(原始的) soup. There they become complexes. 3. Chemical evolution can be simulated(模拟) in the laboratory Stanley Miller’s experiment give evidence to the theory. 4. RNA or related precursors may have been the first genes and catalysts RNA can act as catalysts. 5. Biological evolution began more than three and a half billion years ago 6. The first cell was probably a chemoheterotroph Then pigments came out. The original photosynthetic(光合作用) processes electron donor(供体) was probably H2S. Cyanobacteria(蓝藻) are descendants(后裔) of early photosynthetic oxygen-producers. Early anaerobic oxidization electron acceptors ay be SO42- to produce H2S. 7. Eukaryotic cells evolved from prokaryotes in several stages Three major changes: chromosomes, intracellular membranes and endosymbiotic( 内 共 生 ) of aerobic bacteria or photosynthetic bacteria. Later cells got together, then differentiation came out. 8. Molecular anatomy reveals evolutionary relationships Genomes of many species are sequenced. Homologous genes encode homologs(同源蛋白). If that happens in the same species, it’s paralogous genes encode paralog. They are similar in sequence, structure but not in functions. If that happens in different species, it’s orthologous encode orthologs. Usually they have similar functions. Annotated(注释) genome gives the likely functions of genes derived by comparison. The sequence differences can show the diverge of evolution. 9. Functional genomics shows the allocations(分配) of genes to specific cellular processes The more complex the organism, the more genes for regulation in proportion(比例). 10. Genomic comparisons will have increasing importance in human biology and medicine Chapter 2 Water Making up 70% or more of the weight of most organisms, water gave birth to first living organisms. 2.1 Weak interactions in aqueous systems There are hydrogen bonds, ionic, hydrophobic and van der Waals interactions. Hydrogen bonds provide cohesive forces making water liquid at room temperature and can explain the solution of polar molecules. Nonpolar molecules tend to cluster(聚集) together in aqueous(水成的) solutions. Noncovalent interactions are the basis of specific recognition. 1. Hydrogen bonding gives water its unusual properties Like sp3, two H atoms and two empty orbitals(轨道) make a tetrahedron(四面体). Electronegative oxygen causes two dipoles( 偶 极 ), forming hydrogen bond, expressed by three parallel lines. It’s about 10% covalent( 共 价 ) and 90% electrostatic(静电). Bond dissociation energy is the energy required to break a bond. 2. Water forms hydrogen bonds with polar solutes An electronegative atom as the hydrogen acceptor and a hydrogen atom bonded to another electronegative atom as the hydrogen donor can form hydrogen bond. When H and the two electronegative atoms are in a line the hydrogen bonds are strongest, so to be directional. 3. Water interacts electrostatically with charged solutes As a polar solvent(溶剂), hydrophilic compounds easily dissolve while hydrophobic compounds not. Water can weaken the electrostatic interactions between solute(溶质) parts, in some degree because it has a high dielectric(介电) constant ε=78.5 when 25°C(F=Q1Q2/εrr). So ionic interactions are stronger in less polar environments. 4. Entropy increases as crystalline substances dissolve 5. Nonpolar gases are poorly soluble in water Entropy decreases when gas goes into water, making it harder for nonpolar gases to dissolve in water. Some organisms have water-soluble carrier proteins to facilitate( 促 进 ) O2 transport. CO2 becomes H2CO3 and is transported as bicarbonate(HCO3-盐) or bound to hemoglobin. 6. Nonpolar compounds force energetically unfavorable changes in the structure of water Hydrophobic solutes interfere(干扰) the hydrogen bonds without compensation(补偿), so to add enthalpy(焓) as well as decrease entropy for water molecules near the compounds form cagelike shell. Amphipathic( 两 亲 ) compounds like proteins, pigments, certain vitamins and membranes’ sterols( 固 醇 ) and phospholipids(磷脂) can form micelles(胶束) by hydrophobic interactions. Micelles’ strength is due to thermodynamic(热力学) stability by minimizing the number of ordered water molecules. Hydrophobic interactions among lipids and between lipids and proteins are the most important determinants of structure in membranes. Hydrophobic interactions between nonpolar amino acids stabilize the proteins’ three-dimensional structures. When enzyme displaces ordered water from the polar substrate the entropy increases, too. 7. Van der waals interactions are weak interatomic attractions When van der Waals attraction balances repulsive(排斥) force the nuclei are in van der Waals contact. Atoms have van der Waals radii(pl. radius) shown in space-filling models. 8. Weak interactions are crucial to macromolecular structure and function They form and break continually. Number makes them strong. When weak-bonding possibilities are maximized the macromolecules reach the most stable structure. Some water molecules are tightly bound to protein, RNA and DNA essential to function, for example, cytochrome(细胞色素) f has a chain of five water molecules that may provide a path for protons(质子) to move through the membrane-“proton hopping”. 9. Solutes affect the colligative properties(依数性) of aqueous solutions They are vapor pressure(蒸气压), boiling point, melting/freezing point and osmotic pressure(渗透压) changing because solutes change the concentration of water so to be determined by number of solute particles(颗粒). Van’t Hoff equation: osmotic pressure Π=(i1c1+i2c2+i3c3+…)*RT, ic is osmolarity(克分渗透压浓度), i is van’t Hoff factor measuring the extent(程度) of the solute’s dissociation. Water moves from lower to higher osmolarity. Cells neither gain nor lose water when surrounded by isotonic(等渗) solution, lose water in hypertonic(高渗) solution and get water in hypotonic(低渗) solution. There are many mechanisms to balance the high osmotic pressure caused by biomolecules and ions in cells. Storing fuel as polysaccharides can prevent high osmotic pressure. Osmotic pressure against the cell wall-turgor pressure(紧张压) stiffens(使硬) plants cells and help touch-sensitivity. 2.2 Ionization of water, weak acids, and weak bases 1. Pure water is slightly ionized 2H2O H3O+(hydronium ions 水合氢离子)+OH-. The ionization can be measured by electrical conductivity(电导率). Proton hopping makes ionic mobility high, so acid-base reactions in aqueous solutions are fast. 2. The ionization of water is expressed by an equilibrium constant Keq=[H+][OH-]/[H2O]=Kw/55.5M=1.8E-16M at 25°C, when ion product(溶度积/离子积) Kw=1.0E-14M^2 and neutral pH=7. 3. The pH scale designates the H+ and OH- concentrations pH=-lg[H+]. Indicator dyes(指示剂) like litmus(石蕊), phenolphthalein(酚酞) and phenol red(酚红) can tell pH. pH affects function, for example, diabetes(糖尿病) blood plasma(血浆) pH is lower than normal 7.4. 4. Weak acids and bases have characteristic dissociation constants There are monoprotic( 一 元 ), diprotic( 二 元 ) and triprotic( 三 元 ) acids. Hydrochloric(HCl), sulfuric(H2SO4) and nitric(HNO3) acids are strong acids. Conjugate acid-base pair( 共 轭 酸 碱 对 ) has: HA H++A-, Keq=[H+][A-]/[HA]=dissociation constants Ka. pKa=-lgKa. 5. Titration curves(滴定曲线) reveal the pKa of weak acids When pH=pKa, acid=conjugate base. 2.3 Buffering against pH chages in biological systems Cells and organisms usually maintain pH near 7. 1. Buffers are mixtures of weak acids and their conjugate bases The titration curve has a relatively flat zone in about 1 pH on either side of midpoint. That’s the buffering region. At the midpoint, the buffering power is maximal. That of the H2PO4-/HPO42- pair(pKa=6.86) is from 5.9 to 7.9, the NH4+/NH3 pair(pKa=9.25) from 8.3 to 10.3. 2. A simple expression relates pH, pKa and buffer concentration Henderson-Hasselbalch equation: pH=pKa+log([A-]/[HA]). 3. Weak acids or bases buffer cells and tissues against pH changes Amino acids and ATP can give some buffering power, for example, the side chain of histidine’s(组氨酸) pKa=6.0. Organic acids buffer vacuoles(液泡), and ammonia(氨) buffers urine(尿). Phosphate(磷酸盐) and bicarbonate(碳酸氢盐) systems are important. H2PO4H++HPO42- buffers cytoplasm(细胞 质). H2CO3 H++HCO3- buffers blood plasma whose pH is about 7.4. The pH of bicarbonate buffer exposed to gas phase is determined by [HCO3-] and the partial pressure of CO2. Enzymes have pH optimum(最适条件). 2.4 Water as a reactant Condensation(缩水 ) and hydrolysis(水 解 ) reactions. Hydrolases(水 解酶 ) is enzymes. Condensation reactions are endergonic(吸能) so they need exergonic(放能) processes like ATP reaction. Glucose oxidation produces metabolic water and the produced CO2 is converted to HCO3- in erythrocytes(红血球) where water is substrate and helps transfer proton. Photosynthesis(光合作用): 2H2O+2A 光照 O2+2AH2, water serves as the electron donor. 2.5 The fitness of the aqueous environment for living organisms Water’s high specific heat(比热容) is useful. The high degree of internal cohesion(内聚) due to hydrogen bonding is used to transport dissolved nutrients from plants roots to leaves. Macromolecules’ many physical and biological properties derive from their interactions with water molecules of the surrounding medium. Chapter 3 Amino acids, peptides, and proteins Proteins are most abundant and in great variety. 20 amino acids make up proteins. The Lambert-Beer law: absorbance A=lg(I0/I)=εcl, assuming the light is parallel and monochromatic(单色) and molecules are randomly oriented(取向). 3.1 Amino acids 1. Amino acids share common structural features They are α-amino acids: NH3+,H,COO- and R are linked to the same C(α carbon, C-2). The carboxyl carbon is C-1, and the first linked C in R is β, C-3, and so forth. α carbon is chiral center except glycine(甘氨酸), so to have optically active(旋光 性) and enantiomers(对映体). To specify the absolute configuration(绝对构型), there are D,L system and RS system. D,L system: define 上 CHO 下 CH2OH 左 OH 右 H glyceraldehyde(甘油醛) L, 上 CHO 下 CH2OH 左 H 右 OH glyceraldehyde D. Configurations related to L-glyceraldehyde are L and related to D-glyceraldehyde are D(COO- compared with CHO). Attention: l and d are used for levorotatory(左旋光) and dextrorotatory(右旋光). 2. The amino acid residues in proteins are L stereoisomers That’s because the enzymes are asymmetric(不对称). D-amino acid are found only in a few, generally small peptides including some in bacterial cell walls and certain peptide antibiotics(抗生素). 3. Amino acids can be classified by R group Nonpolar, aliphatic R groups are nonpolar and hydrophobic, tending to cluster together within proteins, stabilizing protein structure by hydrophobic interactions. Glycine is simplest with actually no real contribution to hydrophobic interactions. Methionine has a nonpolar thioether(硫醚) group. Proline’s imino group(亚胺基) is held in a rigid(刚性) conformation reducing flexibility. Aromatic R groups are relatively nonpolar and hydrophobic. Tryosine can form hydrogen bonds. Tryptophan and tyrosine, and phenylalanine much lesser, absorb ultraviolet light(紫外光), so most proteins strongly absorb light of 280nm wavelength. Polar, uncharged R groups are more hydrophilic. Asparagine and glutamine are easily hydrolyzed(水解) by acid or base to aspartate and glutamate. Cysteine is readily oxidized to form dimeric(二聚) amino acid called cystine(胱氨酸) by disulfide bond(二硫键). Positively charged(basic 碱性) R groups are most hydrophilic with negatively charged(acidic 酸性) R groups. Lysine has another NH3 at ε position so to have significant positive charge at pH 7.0. Arginine has a guanidine group(胍基). Histidine has an imidazole(咪唑) group and the N can help His to be a proton donor or acceptor. His is the only one with pKR near neutrality. R group nonpolar aliphatic (脂肪族) aromatic (芳香族) polar uncharged glycine alanine name Gly G Ala A proline valine leucine Pro P Val V 脯氨酸 缬氨酸 1.99 2.32 Leu L 亮氨酸 pKR pI 5.97 6.01 R H CH3 10.96 9.62 6.48 5.97 CH2*3回连NH2 CH(CH3)CH3 2.36 9.60 5.98 CH2CH(CH3)CH3 Ile I 异亮氨酸 2.36 9.68 6.02 CH(CH3)CH2CH3 methionine phenylalanine Met M 甲硫氨酸 Phe F 苯丙氨酸 Tyr Y 酪氨酸 2.28 1.83 9.21 9.13 5.74 5.48 CH2CH2SCH3 CH2苯环 2.20 9.11 5.66 CH2苯环OH(对位) tyrosine 10.07 tryptophan Trp W 色氨酸 2.38 9.39 5.89 CH2C(CHNH)邻位双连苯环 serine Ser S 丝氨酸 2.21 9.15 5.68 CH2OH threonine Thr T 苏氨酸 2.11 9.62 5.87 CH(OH)CH3 cysteine Cys C 半胱氨酸 Asn N 天冬酰胺 Gln Q 谷酰胺 1.96 10.28 5.07 CH2SH 2.02 8.80 5.41 CH2CONH2 2.17 9.13 5.65 CH2CH2CONH2 glutamine negatively charged NH3+pKa 9.60 9.69 isoleucine asparagine positively charged 甘氨酸 丙氨酸 COOHpKa 2.34 2.34 8.18 lysine Lys K 赖氨酸 2.18 8.95 10.53 9.74 CH2CH2CH2CH2NH3+ histidine His H 组氨酸 1.82 9.17 6.00 7.59 CH2环C,NH,CH,N,CH arginine Arg R 精氨酸 2.17 9.04 12.48 10.76 CH2CH2CH2NHC(NH2)=NH2+ aspartate Asp D 门冬氨酸 Glu E 谷氨酸 1.88 9.60 3.65 2.77 CH2COO- 2.19 9.67 4.25 3.22 CH2CH2COO- glutamate 4. Uncommon amino acids also have important functions 4-hydroxyproline and 5-hydroxylysine are found in collagen(胶原) and the former is found in plant cell wall proteins. 6-N-methyllysine is a constituent of myosin. γ-carboxyglutamate is found in prothrombin(凝血素) and proteins binding Ca2+. A four Lys derivative(衍生物) desmosine(锁链素) is found in elastin(弹性蛋白). Selenocysteine(硒代半胱氨酸) replaces S of cysteine for selenium(Se), actually derived from serine during protein synthesis, called 21st amino acid. Ornithine(鸟氨酸) and citrulline(瓜氨酸) are key intermediates/metabolites in the biosynthesis of arginine and the urea cycle(尿素循环). 5. Amino acids can act as acids and bases They are zwitterion(两性离子), amphoteric(两性), ampholytes(两性电解质). 6. Amino acids have characteristic titration curves From COOHNH3+ to COO-NH3+(pI) to COO-NH2. pI is isoelectric(等电位) point/pH. Taking glycine as an example, COOHpKa is lower because of the repulsion from positive charged amino group, and NH3+pKa is lower because of the oxygen atoms pulling electrons. 7. Titration curves predict the electric charge of amino acids If there’s no pKR, pI=0.5*(COOHpKa+NH3+pKa). The farther away from pI, the greater charge amino acid takes. 8. Amino acids differ in their acid-base properties If there’s pKR, titration curves are more complex with three stages(added pKR). 3.2 Peptides and proteins 1. Peptides are chains of amino acids By peptide bond they form dipeptides(二肽), tetrapeptides(四肽), pentapeptides(五肽), and so forth. The equilibrium favors amino acids over the dipeptide, so the carboxyl group needs to be modified or activated to get off hydroxyl. Usually the division of oligopeptide(寡肽) and polypeptide(多肽) is 10,000. The chain has amino-terminal and carboxyl-terminal. Because of the high activation energy, the exergonic hydrolysis is slow, so the peptide bonds are stable, with a half-life of about 7 years. 2. Peptides can be distinguished by their ionization behavior Peptides have titration curves and pI, but many factors can affect the pKa. 3. Biologically active peptides and polypeptides occur in a vast range of sizes Some vertebrate hormones are small peptides, including oxytocin(催产素) secreted by the posterior pituitary(垂体后叶) and stimulates(刺激) uterine(子宫) contractions(收缩); bradykinin(缓激肽) inhibiting inflammation(炎症) of tissues; thyrotropin-releasing(促甲状腺素释放激素) formed in hypothalamus(下丘脑) and stimulates the release of thyrotropin(促甲 状腺激素) from the anterior pituitary gland(脑垂体腺). Some antibiotics(抗生素) and mushroom poisons like amanitin(鹅膏 蕈碱) are small peptides. Slightly larger polypeptides include glucagon( 胰 高 血 糖 素 ) opposing( 拮 抗 ) the action of insulin( 胰 岛 素 ) and corticotropin(促肾上腺皮质激素) stimulating the adrenal cortex(肾上腺皮质) as a hormone of the anterior pituitary gland. The longest polypeptide is titin(肌连蛋白). Multisubunit(多亚基) proteins have many polypeptides associated noncovalently(a few covalently, like insulin by disulfide bonds). If there are some identical polypeptide chains they are called protomers(原体) and the protein is oligomeric(低聚物). On average, in protein the amino acid residue molecule weight is 110. 4. Polypeptides have characteristic amino acid compositions 5. Some proteins contain chemical groups other than amino acids Simple proteins like ribonuclease(核糖核酸酶) and chymotrypsinogen(胰凝乳蛋白酶原) contain only amino acid residues. Conjugated proteins(结合蛋白) contain some additional chemical components, i.e. prosthetic(补体) group, by which they are classified. Lipoproteins(脂蛋白) contain lipids, glycoproteins(糖蛋白) sugar and metalloproteins(金属蛋白) metal. 6. There are several levels of protein structure Primary structure is the sequence, secondary structure is recurring structural patterns, tertiary structure is the three-dimensional folding, quaternary structure is the arrangement of subunits. 3.3 Working with proteins Near pI proteins are likely to become sediment(沉淀). 1. Proteins can be separated and purified Size, charge and binding properties can help. Crude extract(粗提取) is to break open cells to dissolve proteins. Then there are many ways to purify proteins. Fractionation(分级提取) according to protein solubility include salting out(盐析) where ammonium sulfate((NH4)2SO4) is effective. Dialysis(透析) is a way to get rid of salt. Column chromatography(柱层析) is the most powerful methods for fractionation according to protein charge, size and binding affinity(键合力). For example, cation-exchange chromatography(阳 离子交换柱) has negatively charged solid matrix to make positively charged proteins move more slowly. Separation can be optimized(优化) by changing pH and salt concentration. The longer the column, the better resolution(分辨率), but the less protein able to pass the column and because of diffusional spreading, the resolution may decline. Size-exclusion chromatography according to size uses cavities to make small proteins move slowly. Affinity chromatography according binding affinity has beads(珠) with covalently attached chemical group. High-performance liquid chromatography(HPLC, 高 效液相色谱) uses high-pressure pumps to speed the movement of proteins to improve resolution by limiting diffusional spreading. 2. Proteins can be separated and characterized by electrophoresis(电泳) Because it often affects the proteins structure, usually it’s not used to purify proteins. Polymer polyacrylamide(聚丙烯酰胺) gel(凝胶) acts as molecular sieve(分子筛) according to charge-to-mass ratio and protein shape, which can minimize convection(对流) currents. Electrophoretic mobility(迁移率) μ= velocity(速度) V/potential(电势) E=charge Z/frictional coefficient(摩擦系数) f. Sodium dodecyl sulfate (SDS, 十二烷基硫酸钠) binds one molecule to every two amino acid residues so to make similar charge-to-mass ratios. SDS can also change proteins conformations, so proteins can be separated only according to mass(smaller faster). It can separate subunits. Coomassie blue(考马斯蓝) can add a dye. Isoelectric focusing can determine pI using a pH gradient. Where the protein stops, there is its pI. Two-dimensional electrophoresis can show they both together. 3. Unseparated proteins can be quantified Enzymes’ amount can be measured by the increase reaction rate caused by enzyme. To do this, we should know the equation, the analytical procedure, cofactors, dependence of activity, the optimum pH and the temperature range. High substrate concentrations are used to measure initial rate. 1 unit enzyme activity causes transformation of 1μmol of substrate per minute at 25°C. Activity is total units, and specific activity is the number of units per milligram(mg) total protein. When the enzyme is pure, the specific activity becomes maximal and constant and only a single protein species can be detected. After each purification step, activity and total protein decrease but if successful the loss of nonspecific protein is much greater than the loss of activity. For those are not enzymes, transport proteins can be assayed by their binding to the molecule and hormones and toxins by the effect they produce. 3.4 The covalent structure of proteins 1. The function of a protein depends on its amino acid sequence Ubiquitin(泛激素) is identical in fruit flies and humans. Some proteins are polymorphic(多形), but most proteins contain crucial regions essential to function whose sequence is conserved. 2. The amino acid sequences of millions of proteins have been determined Frederick Sanger worked out the sequence of insulin in 1953. 3. Short polypeptides are sequenced using automated procedures 1-fluoro-2,4-dinitrobenzene(FDNB, 1-氟-2,4-二硝基苯) can keep amino-terminal residue during hydrolyzation, so to be used to determine the number of different polypeptides. Edman degradation carried out on sequenator(序列分析仪) uses phenylisothiocyanate(异硫氰酸苯酯) under mildly alkaline(碱性) conditions to convert the amino-terminal residue to phenylthiocarbamoly(PTC) adduct(加成产物) and in anhydrous trifluoroacetic(无水三氟醋酸) cleave the bond of next residue. PTC becomes anilinothiazolinone derivative and then more stable phenylthiohydantoin(乙内酰苯硫脲) derivative by acid. 4. Large proteins must be sequenced in smaller segments Because of the limit of efficiency, the protein length has limitation. There are some steps: (1) Breaking disulfide bonds: oxidation by performic acid(过甲酸) or reduction by dithiothreitol(二硫苏糖醇). (2) Cleaving the polypeptide chain: proteases(蛋白酶). Trypsin(胰蛋白酶) cleaves C of Lys and Arg, submaxillarus protease cleaves C of Arg, chymotrypsin(胰凝乳蛋白酶) cleaves C of Phe, Trp and Tyr, staphylococcus aureus(金黄色葡萄球 菌) V8 protease cleaves C of Asp and Glu, Asp-N-protease cleaves N of Asp and Glu, pepsin(胃蛋白酶) cleaves N of Phe, Trp and Tyr, endoproteinase(内蛋白酶) Lys C cleaves C of Lys, cyanogens bromide(溴化氰) cleaves C of Met. (3) Sequencing of peptides. (4) Ordering peptide fragments: overlaps caused by different enzymes. (5) Locating disulfide bonds: another cleavage without breaking the disulfide bonds and then electrophoresis. Two parts having disulfide bonds will miss and produce a new one. 5. Amino acid sequences can also be deduced(推断) by other methods Mass spectrometry(质谱) can work. DNA sequencing is better but without the information like disulfide bonds. New term: proteome(蛋白质组). 6. Small peptides and proteins can be chemically synthesized Three ways to get proteins: purification, genetic engineering and synthesis. For synthesis purifying is a problem. R. Bruce Merrifield solves this with a solid support of an insoluble polymer(聚合物) resin(树脂) contained within a column on which the peptide is built up and after each successive step in the cycle the protective chemical groups block(阻滞) unwanted reactions. Many methods are for the efficient ligation(连接) of peptides to make larger proteins. 7. Amino acid sequences provide important biochemical information Family members usually share 25% identical sequences. Some amino acid sequences serve as signals determining the cellular location, chemical modification and half-life of a protein. Special signal sequences usually at the amino terminus are used to target certain proteins for export from cells or distribution to the nucleus, cell surfaces, cytosol(细胞液), and so on. Some act as attachment sites for prosthetic(补体) groups. 3.5 Protein sequences and evolution 1. Protein sequences can elucidate the history of life on Earth Residues essential for the activity are conserved while those are less important to function may vary. To maintain the function, the substitutions(替换) have limitations. Lateral(侧旁) gene transfer(a group of genes transfer from one organism to another) is rare, for example, the antibiotic-resistance genes. To avoid that, we choose families with essential functions present in the earliest viable(活的) cells. The members of protein families are homologous proteins or homologs(同源蛋白质). If they are in the same species they are paralogs(种内同源), or else they are orthologs(种间同源). When aligned there may be gaps reducing the alighment score. Besides, the three-dimensional structural similarities can reveal evolutionary relationships, too. Signature(标记) sequences can be used to distinguish taxonomic(分类学) groups. Chapter 4 The three-dimensional structure of proteins Protein can has many conformations because of free rotation of bonds. There are five themes: amino acid sequence determines three-dimensional structure, the structure determines function, protein has some stable structural forms, mainly noncovalent interactions maintain structures, there are some common structural patterns. 4.1 Overview of protein structure Conformation is spatial arrangement of atoms. When proteins have reactions changes, sometimes they change conformations. Proteins in functional folded conformations are native proteins. 1. A protein’s conformation is stabilized largely by weak interactions Stability is the tendency to maintain native conformations. Conformation with the lowest free energy is the most stable, when there is the maximum number of weak interactions(Rule 1). The free energy change from hydrogen bond to water to that to others is close to zero, so the stability is not simply the result of free energy. Water can form structured shell called salvation layer(which can be formed around polar molecules, too) around hydrophobic molecules so to decrease entropy, but if the nonpolar groups cluster, the entropy can be increased, which is the major thermodynamic driving force. So hydrophobic amino acids side chains tend to cluster in protein’s interior away from water(Rule 2). Besides, partners are important for hydrogen bonding or ionic interactions. Ion pair(salt bridge) can also help. 2. The peptide bond is rigid and planar That shows a resonance or sharing of electrons between carbonyl oxygen and amide nitrogen. The six atoms of the peptide group lie in a single plane with O and H in CONH trans(反) to each other. The peptide C-N bonds are unable to rotate because of partial double-bond character. The backbone of polypeptide chain is a series of rigid planes sharing common points at Cα. The angle of N-Cα is Ф and Cα-C is Ψ. When all peptide groups are in the same plane it is fully extended and two angles are 180°. In principle they can change between -180° and 180° but Ramachandran plot shows the limitation. 4.2 Protein secondary structure Α helix and β conformations are the most prominent(显著). 1. The α helix is a common protein secondary structure The polypeptide backbone is tightly wound around an imaginary axis drawn longitudinally through the middle of the helix, and the Rs protrude outward. Ф is -60° and Ψ is -45°~-50°. The repeating distance is about 5.4Å with 3.6 amino acids in each turn. α helix makes optimal use of internal hydrogen bonds, the H on N linking the O of CO of the fourth amino acid on the amino-terminal side. All resides should be one stereoisomeric series(L/D). Though in principle there can be right- or left-handed, but there are only right-handed ones. 2. Amino acid sequence affects α helix stability Interactions between residues can stabilize or destabilize it(1). If there is a long block of Glu, α helix can’t form at pH 7.0 because the negatively charged carboxyl groups repel each other. Lys and Arg are also not able to because of positively charged R groups. The bulk and shape of Asn, Ser, Thr and Cys can destabilize it if they are close(2). The twist of α helix allows interactions 3 or 4 residues away(3). Positively charged amino acids are often found three residues away from negatively ones to form ion pairs. Two aromatic(芳香的) residues are often like that resulting in a hydrophobic interaction. In Pro, N-Cα rotation is impossible so it introduces a destabilizing kink(扭结) in an α helix. Besides it doesn’t has H on N to form hydrogen bonds. Gly has more conformational flexibility so polymers of Gly tend to coil rather than form α helix(4). Residues near the ends can affect the stability(5). There is a small electric dipole, amino-terminal positive and carboxyl-terminal negative. So negatively charged amino acids are often found near amino terminus and positively charged ones near carboxyl terminus. 3. The β conformation organizes polypeptide chains into sheets The backbone is extended into a zigzag(之字形), Rs are trans. The zigzag polypeptide chains can be arranged side by side to form pleats(褶状物) called β sheet, which can be parallel(平行, 斜线形成氢键) with 6.5Å repeats and antiparallel(反平行, 直线形成氢键) with 7Å. When β sheets are layered close the Rs should be small, so Gly and Ala are better. 4. β turns are common in proteins β turns connect ends of adjacent segments of an antiparallel β sheet with O on C of the first residue forming a hydrogen bond with the H on N of the fourth. Gly and Pro often occur there because Gly is small and flexible and Pro involves imino(亚 氨基) nitrogen helpful to cis configuration amenable(服从)to a tight turn. Type I and type II are most common and type II always have Gly as the third residue. γ turn is less common as a three-residue turn with a hydrogen bond between the first and third residues. 5. Common secondary structures have characteristic bond angles and amino acid content There are high concentrations in the angle regions for α helix and β conformation. Glycine is exception because it’s R is H. 4.3 Protein tertiary and quaternary structures Tertiary structure is the overall three-dimensional arrangement. Pro, Thr, Ser and Gly are bend-producing residues. Quaternary structure is the arrangement of subunits. Two groups of proteins: fibrous(纤维) and globular(球状). Fibrous proteins usually consist largely of a single type of secondary structure while globular ones often contain several. Fibrous proteins are important for support, shape and external protection while globular ones are important to enzymes, transport proteins, motor proteins, immunoglobulins and regulatory. 1. Fibrous proteins are adapted for a structural function They are insoluble(不溶) because of a high concentration of hydrophobic residues both in the interior and on the surface. (1) α-keratin(角蛋白): They are members of intermediate filament(IF, 中间丝) proteins. Others are in the cytoskeletons(细 胞骨架). α-keratin is a right-handed α helix. Two α-keratins in parallel(amino termini at the same end) are wrapped(缠绕) to form a left-handed supertwisted coiled coil(quaternary structure, one polypeptide formed from α helix is tertiary structure) with hydrophobic residues on the surface they two touch and Rs meshed together in a regular interlocking(连结) pattern. So Ala, Val, Leu, Ile, Met and Phe are better. Disulfide bonds stabilize quaternary structure. Coiled coils form protofilament(初纤维) and protofibril(原纤维) and four protofibrils(32 α-keratin) form intermediate filament. (2) Collagen(胶原质): it has a left-handed helix with 3 residues per turn. 3 α chains(polypeptides) form a right-handed coiled coil(collagen molecule/tropocollagen 原 胶 原 ). Typically it contain 35% Gly, 11% Ala, 21% Pro and 4-Hyp(4-hydroxyproline). In collagen the amino acid sequence is generally a repeating tripeptide unit Gly-X(often Pro)-Y(often 4-Hyp). Gly can be adapt to the tight junctions and Pro and 4-Hyp permit the sharp twisting. Collagen molecules form collagen fibrils(原纤维). Covalent bonds can help cross-link, involving Lys, HyLys(5-hydroxylysine) or His at X and Y positions. This creating uncommon residues such as dehydrohydroxylysinonorleucine. Gly in α chain can’t be replaced by another residue without deleterious effects. Osteogenesis(骨生成) imperfecta causes abnormal bone formation in babies, Ehlers-Danlos syndrome(埃-丹二氏综合征) causes loose joints. (3) Silk Fibroin(蚕丝蛋白): its polypeptide chains are β conformation rich in Ala and Gly. Because β conformation is highly extended, silk doesn’t stretch(伸展) but it’s flexible because of less covalent bonds. 2. Structural diversity reflects functional diversity in globular proteins Folding provides that. 3. Myoglobin provided early clues about the complexity of globular protein structure Myoglobin is a small oxygen-binding protein of muscle cells storing oxygen and facilitating(促进) oxygen diffusion in muscle tissue. Myoglobin contains a single chain and a single iron protoporphyrin(原卟啉) i.e. heme(血红素) group which makes myoglobin and hemoglobin deep red-brown. Myoglobin’s backbone has 8 segments of right-handed α helix containing 70% residues of all interrupted by bends, some bends are β turns. Hydrophobic interactions make hydrophobic Rs in the interior, occupying nearly all the space, forming globular proteins’ typical hydrophobic core. The interior is narrow enough for only 4 water molecules. The fraction of space(空间利用率) is 0.75(crystal is 0.70 to 0.78). The nonpolar side chains are so close that van der Waals interactions greatly stabilize hydrophobic interactions. At the bends there are 75% Pro of the whole myoglobin. The fourth Pro is in an α helix creating a kink necessary for tight helix packing. There are also Ser, Thr and Asn whose bulk and shape make them incompatible(不协调) with α-helical structure. The iron has two bonding positions perpendicular(垂直) to the plane of the heme, on bound to the R group of His at position 93, the other bound O2. In the pocket heme group’s accessibility to solvent(溶剂) is restricted. 4. Globular proteins have a variety of tertiary structures Cytochrome c is a heme protein and a component of respiratory(呼吸) chain of mitochondria(线粒体). The protoporphyrin is covalently attached to the polypeptide. 40% residues are in α-helical segments. Lysozyme(胞壁质酶) is rich in egg white and human tears catalyzing the hydrolytic cleavage of polysaccharides in the protective cell walls of some families of bacteria. 40% residues are in α-helical segments and there are some β sheets. 4disulfide bonds stabilize the structure. The α helices form a long crevice(裂缝) in the side of the molecule as active site. Ribonuclease(核糖核酸酶) is secreted by the pancreas(胰) into the small intestine(小肠). There are few α helices but many β conformations. 4 disulfide bonds are between loops(环) of the chain. Because of the lower ratio of volume to surface area and fewer potential weak interactions, small proteins need covalent bonds. 5. Analysis of many globular proteins reveals common structural patterns Supersecondary structures, also called motifs(花纹) or folds, are particularly stable arrangements of several secondary structure and the connections between them, for example, the coiled coil of α-keratin. Polypeptides with hundreds residues often fold into some stable globular units called domains. When separated from a protein, a domain can retain its three-dimensional structure. Domains can be distinguished by globular lobe(叶) but more often it’s hard because of extensive contacts between domains. (1) Burial of hydrophobic Rs needs at least two layers of secondary structure. β-α-β loop and α-α corner create two layers. (2) α helices and β sheets are usually in different structural layers because the backbone of a polypeptide segment in β conformation can’t readily hydrogen-bond to α helix. (3) Adjacent segments in sequence are usually stacked adjacent when folded. (4) Connections between elements of secondary structure can’t cross or form knots(结). (5) β conformation is most stable when segments are slightly(轻微) right-handed twisted. Right-handed connections tend to be shorter and bend through smaller angles. For example, two parallel β strands are usually connected by a crossover strand in right-handed way. When many segments are put together, the twisting of β sheets form β barrel and twisted β sheet, which form the core of many larger structures. A series of β-α-β loops and β barrel can together form α/β barrel, in which each parallel β segment is attached to its neighbour by an α-helical segment. All connections are right-handed. α/β barrel is found in many enzymes often with a binding site for cofactors or substrates in the form of a pocket near one end of the barrel. 6. Protein motifs are the basis for protein structural classification Four classes of protein structures: all α, all β, α/β(not separated) and α+β(separated). There are fewer than 1000 different folds or motifs in all proteins. Class and fold are top two levels of organization purely structural. Below the fold level, categorization is based on evolutionary relationships. Recurred domains or motifs reveal that protein tertiary structure is more reliably conserved than primary sequence. Protein family has proteins with similar sequence, structure and function. Some families with quite difference sequences sometimes use the same major structural motif so they have similar functions. These families are called superfamilies. Structural motifs are important to define protein families and superfamilies. 7. Protein quaternary structures range from simple dimmers to large complexes Multimer(多体) is a multisubunit protein. Oligomer(低聚体) is a multimer with just a few subunits. The repeating structural unit in a multimeric protein is a protomer(原体). For example, hemoglobin’s subunits are arranged in symmetric pairs, each pair having 1 α and 1 β, so it can be described as a tetramer(四聚物) or a dimer(二聚物). Oligomers can have either rotational symmetry(轴向对称) or helical symmetry(螺旋对称). In rotational symmetry, the subunits pack about the axes to form closed structures. In helical symmetry proteins tend to form open-ended structures with subunits added in a spiraling(螺旋状) array(排列). Of rotational symmetry, there are: (1) Cyclic(周期) symmetry: it’s simplest rotation about one axis called n-fold rotational axis. It’s marked as Cn with n for the number of subunits related by the axis. (2) Dihedral(二面) symmetry: a twofold rotational axis intersects(交叉) an n-fold axis at right angles, defined as Dn and having 2n protomers. (3) Icosahedral(二十面体) symmetry: a common structure in virus coats/capsids(衣壳). 8. There are limits to the size of proteins Two factors: the genetic coding capacity and the accuracy of the protein biosynthetic process, the error frequency during protein biosynthesis. 4.4 Protein denaturation and folding 1. Loss of protein structure results in loss of function Denaturation(变性) is a loss of three-dimensional structure causing loss of function. Heat affects the weak interactions so it can cause denaturation in an abrupt(突变) way. The abruptness suggests unfolding is a cooperative process. Other ways: extremes of pH, certain miscible(混溶) organic solvents such as alcohol or acetone(丙酮), certain solutes such as urea(尿素) and guanidine hydrochloride(盐酸胍) and detergents(清洁剂). Organic solvents, urea and detergents disrupt the hydrophobic interactions, extremes of pH change the charge on the protein. 2. Amino acid sequence determines tertiary structure Renaturation(复性) is the process that some denatured proteins regain native structure and biological activity if returned to conditions where the native conformation is stable. Christian Anfinsen’s experiment in the 1950s shows that the sequence of a polypeptide chain contains all the information of structure. 3. Polypeptides fold rapidly by a stepwise process Levinthal’s paradox(佯谬) shows protein folding can’t be random. There are some models. In one the folding process is hierarchical(分层). Local secondary structures form first, followed by longer-range interactions between secondary structures to form supersecondary structures. In another one folding is initiated(开 始) by a spontaneous(自发的) collapse(坍塌) of the polypeptide into a compact state i.e. molten globule(熔球), mediated by hydrophobic interactions among nonpolar residues. The compact state may have a high content of secondary structure. Actual process may be a mixture of both models. The process may be a kind of free-energy funnel(漏斗). Proteins fold in many ways, but the number of different conformations decreases as folding nears completion. At the bottom of the funnel there is only one native conformation or a small set of native conformations. Defects in protein folding come from genetic disorders. Cystic fibrosis(囊性纤维变性) is often caused by the deletion of a Phe at position 508 in cystic fibrosis trans-membrane conductance(跨膜电导) regulator(CFTR). A protein has regions of high and low stability. The regions of low stability allow a protein to alter its conformation between states. 4. Some proteins undergo assisted folding Molecular chaperones(分子伴侣) facilitate correct folding pathways or provide microenvironments suitable for folding. Some chaperones facilitate the quaternary assembly of oligomeric proteins. Hsp70 is rich in cells stressed(受压) by high temperature. Hsp70 bind to regions of unfolded polypeptides rich in hydrophobic residues, preventing inappropriate aggregation(聚合). Chaperonins(陪伴蛋白) are required for the folding of many cellular proteins. In E. coli 10% to 15% cellular proteins require GroEL/GroES(up to 30% when stressed by heat). GroEs forms a lid of GroEL complex for the proteins to fold. Isomerization(异构化) reactions need protein disulfide isomerase(PDI) catalyzing the elimination of folding intermediates with inappropriate disulfide cross-links and peptide prolyl(脯氨酰) cis-trans isomerase(PPI) catalyzing the intercoversion of the cis and trans isomers of Pro peptide bonds. Chapter 5 Protein function Protein conformation changes give molecules interactions deciding protein functions. Key principles: Proteins have transient(瞬变) nature being reversibly(可逆) bound by ligand(配基) to binding site, in which water can be treated as a specific ligand. Induced fit (conformational change) is often coupled to the binding. Proteins are flexible -“breathe” in conformation. Conformational change in one subunit often affects others, so the binding can be regulated. To enzymes, ligands are called substrates(底物), binding sites are called catalytic site or active site. 5.1 Reversible binding of a protein to a ligand: oxygen-binding proteins 1. Oxygen can be bound to a heme(血红素) prosthetic(补体——对蛋白质功能永久辅助的复合物) group Iron and copper can bind oxygen strongly, but free iron cause highly reactive oxygen species such as hydroxyl(OH) radicals(根) that damage DNA and other macromolecules, so it’s often sequestered(螯合) to heme(or haem). Heme has a protoporphyrin(原卟啉) bound by a ferrous iron(亚铁) to, which binds oxygen reversibly. The iron has four coordination bonds(配位键) binding to nitrogen atoms which prevent it from ferric(三价) state, which can’t bind oxygen. Cytochromes(细胞色素) in oxidation-reduction(氧化还原) reactions have heme, too. If one O2 is bound to two Fe2+ at the same time, they will become Fe3+, so heme is sequestered deep in the protein and one bond is occupied by a side-chain nitrogen of a Histidine(组氨酸) residue(残基)-proximal(邻近) His, leaving the other bond for O2 molecule. Binding brings electronic properties change and colour change, from dark purple oxygen-depleted venous(静 脉) blood to bright red oxygen-rich arterial(动脉) blood. Carbon monoxide(CO) and nitric oxide(NO) bind to the site more easily. 2. Myoglobin(肌红蛋白,Mb) has a single binding site for oxygen Mb can transport (hemoglobin is better with multiple subunits and O2-binding sites) and store oxygen as a typical globin(珠蛋白). The polypeptide is made up of 8 α-helices named from A to H, also with AB meaning one of the bends. His93(右上角,从氨基起第 93 个氨基酸) is also His F8. 3. Protein-ligand interactions can be described quantitatively P+L PL. Ka (association( 结 合 ) constant)=[PL]/[P][L], showing the affinity( 亲 合 力 ) of L. Ka[L]=[PL]/[P]. θ=[PL]/([PL]+[P])=[L]/([L]+1/Ka). So when θ=0.5 [L]=1/Ka=Kd (dissociation(分解) constant), showing the release of L. When L is a gas, because the concentration of a volatile(挥发) substance in solution is always proportional to the local partial pressure, we use pressure pL, and P50 for [L]0.5. 4. Protein structure affects how ligands bind When linked to Fe2+, O2 has a angle but CO is straight. His64 (His E7)-distal(末梢的) His forms hydrogen bond with O2 may precluding(排除) linear binding of CO. The binding of O2 also depends on protein breathing which gives cavities for O2, His64’s side chain rotation giving one major route. When linked to CO, the affinity of O2 is increased but the level of releasing also becomes lower. 5. Oxygen is transported in blood by hemoglobin Oxygen is carried by spherical(球形) hemoglobin(血红蛋白,Hb) dissolved in cytosol(细胞液) in biconcave(两面凹) disk erythrocytes(红血球) formed from hemocytoblasts(血胚细胞) in maturation(成熟) process. Blood releases 1/3 oxygen (about 6.5mL) when passing a tissue. The modulation(调整) of oxygen binding respond to tissues oxygen demand. 6. Hemoglobin subunits are structurally similar to myoglobin It’s tetrameric(四部分的) with two α chains and two β chains and each polypeptide chain associates a heme prosthetic group. Four chains and myoglobin are all globins and similar in structure, so the helix-naming convention is the same, except α subunit lack of D. E and F mainly made up heme-binding pocket. The interactions at α1β1 (and α2β2) are strong so mild treatment of urea(尿素) can disassemble tetramer(四聚体) into intact αβ dimmers. Hydrophobic interactions predominate at the interfaces of α1β2 (and α2β1), but there are hydrogen bonds and ion pairs (sometimes referred to as salt bridges). 7. Hemoglobin undergoes a structural change on binding oxygen It has two states: R (relaxed, higher affinity) and T (tense, predominant of deoxyhemoglobin). T is stabilized by ion pairs many of which are above ones. Oxygen binding stabilizes R and triggers(触发) change from T to R. When changing, αβ pairs slide past each other and rotate narrowing the pocket between β subunits. In T, porphyrin(卟啉) is slightly puckered(折叠) causing iron protrude(突出) on proximal His (His F8) side. The binding of O2 causes the heme to assume a more planar conformation, shifting His F8 and attached F helix position, leading to adjustments in the ion pairs at α1β2 interface. 8. Hemoglobin binds oxygen cooperatively It has a sigmoid(S 形)/cooperative binding curve of θ to be sensitive to difference of O2 concentration by undergoing T to R transition. Because it has many subunits, so the binding of first O2 can cause conformational changes of other subunits. β subunit’s carboxyl termini is His HC3, in T they are involved in ion pairs, while in R they rotate toward center where they are not in ion pairs. In the transition, the pocket between the β subunits becomes narrow. Allosteric(变构) protein is that binding of a ligand in which affects the binding properties of another site, or to say, be induced by modulators(调节分子), which can be inhibitors(抑制剂) or activators(促进剂). The binding sites of allosteric proteins usually consist of stable segments closed to unstable segments. If the ligand is modulator, the interaction is homotropic(同位), or it’s heterotropic(异向). 9. Cooperative ligand binding can be described quantitatively P+nL PLn, Ka=[PLn]/[P]([L]n 次方), θ=([L]n 次方)/ [([L]n 次方) +Kd], Kd=[L] 的 n 次方 0.5, θ/(1-θ)=[L]n 次方/Kd. Hill equation: lg[θ/(1-θ)]=nlg[L]-lgKd. Hill plot(图): lg[θ/(1-θ)]-lg[L]图, the slope(斜率) is nH (Hill coefficient 系数, reflecting the degree of interaction between protein and ligand, not equal to n). If nH is 1 the binding is not cooperative, greater than 1 is positively cooperative, less than 1 is negatively cooperative, is n means completely cooperative when all binding sites bind ligand simultaneously(同时) and there will be no partially saturated(饱和) protein. The same, we use pO2 and Pn 次方 50. The nHs of myoglobin, T, R are 1 and the nH of hemoglobin is 3. 10. Two models suggest mechanisms for cooperative binding MWC/concerted model: Assuming subunits are functionally identical and each can exist in at least two conformations and they undergo transition simultaneously. In this model two conformations are in equilibrium(平衡). When there are no ligands, low-affinity conformation is more stable, and successive binding of ligand makes a transition to the high-affinity conformation more likely. Sequential(连续的) model: Binding makes change in individual subunit and it induces similar change in adjacent subunits. 11. Hemoglobin also transports H+ and CO2 It do this from tissues to the lungs and the kidneys. CO2 is hydrated(水合) to form bicarbonate(碳酸氢盐) catalyzed by carbonic anhydrase(碳脱水酶) rich in erythrocytes(红细胞). pH and CO2 concentration influence the binding of oxygen inversely(负相关)-Bohr effect. O2+HHb+ HbO2+H+. Not the same with O2, H+ is bound to any of several amino acid residues like His146 (His HC3) of the β subunits making major contribution. When protonated(质子注入) His HC3 forms one ion pairs to Asp94 (Asp FG1) to stabilize deoxyhemoglobin in the T state and the protonated form of His HC3 with a high pKa in the T state of it. In the R state it’s normal 6.0 because the ion pair cannot form. In the lung the pH is 7.6, and this residue is largely unprotonated in oxyhemoglobin. CO2 binds as a carbamate(氨基酸甲酯) group to the α-amino group at the amino-terminal end of each globin chain forming carbaminohemoglobin(氨基甲酰血红蛋白) producing H+, also forming additional salt bridges to stabilize the T state and promote the release of oxygen. 12. Oxygen binding to hemoglobin is regulated by 2,3-bisphosphoglycerate It(2,3-二磷酸甘油酸盐, BPG) a heterotropic allosteric modulator. HbBPG+O2 HbO2+BPG. When the concentration of BPG rises, it has a small effect on the binding of O2 in the lungs but a considerable effect on the release of O2 in the tissues so it can regulate the transport of O2. In people suffering from hypoxia(低氧症) it’s high to help release O2. The site is the cavity between the β subunits in the T state which is lined with positively charged amino acid residues. BPG has negatively charged groups. Only one BPG can be linked to hemoglobin. BPG stabilizes the T state to lower hemoglobin’s affinity of O2. The transition to the R state narrows the binding pocket for BPG. A fetus synthesizes γ subunits rather than β subunits with a lower affinity for BPG to get more O2. 13. Sickle-cell anemia is a molecular disease of hemoglobin There are many crescent(月牙)-shaped erythrocytes in the blood, because when hemoglobin S is deoxygenated it becomes insoluble and forms polymers that aggregate into tubular(管状的) fibers, making the erythrocytes deform(变形) sickle shape. The reason is a Val takes the place of a Glu residue at position 6 in the two β chains. Glutamate(谷氨酸盐) has a negative charge at pH 7.4, but the R group of valine(缬氨酸) has no electric charge, creating a sticky hydrophobic contact point at position 6 of the β chain. Heterozygous have sickle-cell trait. 5.2 Complementary interactions between proteins and ligands: the immune system and immunoglobulins 1. The immune response features a specialized array of cells and proteins Immunity is brought about by a variety of leukocytes(白细胞) including macrophages(巨噬细胞) and lymphocytes(淋巴细 胞), which all develop from undifferentiated stem cells in the bone marrow. There are two systems. The humoral(体液) immune system: B lymphocytes, or B cells, which complete their development in the bone marrow, produce antibodies(抗体) or immunoglobulins(Ig, 免疫球蛋白), which bind pathogen(病原体) for destruction. The cellular(细胞) immune system: One kind of T lymphocytes, or T cells, which complete their development in the thymus(胸腺), is cytotoxic(细胞毒素) T cells (TC cells, killer T cells). On their surface there are T-cell receptors. TH cells (helper T cells) produce soluble signaling proteins called cytokines(细胞因子) and interact with macrophages(巨噬细胞). Antigen(抗原, usually the Mr is equal to or larger than 5,000) has antigenic determinant or epitope(抗原决定基), and by genetic recombination mechanisms antibody reassemble a set of immunoglobulin gene segments to make diversity. When covalently attached to large proteins, some molecules may become antigen, and they are haptens(半抗原). 2. Self is distinguished from nonself by the display of peptides on cell surfaces Major histocompatibility(组织相容性) complex(MHC) proteins bind digested peptide fragments and present them on the surface, so T-cell receptors can bind to foreign fragments as antigens(抗原) to start the immune response. Clonal selection can increase the number of immune system cells. Class I MHC proteins bind and display peptides derived from the proteolytic(蛋白水解) degradation. They’re the targets of TC cells. One TC cell can bind to one target specifically, and during the maturation there is a selection process eliminating more than 95% cells to avoid self-destroying. Class II MHC proteins are on the surfaces of macrophages(小噬细胞) and B lymphocytes with foreign antigens. They’re the targets of helper T(TH) cells. 3. Antibodies have two identical antigen-binding sites Five immunoglobulins: IgA, IgD, IgE, IgG and IgM with α, δ, ε, γ and μ type heavy chain and κ and λ type light chain. IgG has two heavy chains and two light chains linked by noncovalent and disulfide bonds like a Y. The straight part is Fc and the branches are Fab i.e. the antigen-binding fragments. Each branch has a antigen-binding site. There are 3 constant domains immunoglobulin fold motif in heavy chain and one in each light chain. IgM is the first antibody made by B lymphocytes and is the major antibody in the early stages of a primary immune response. IgG is the major antibody in secondary immune responses initiated by memory B cells, and is the most abundant immunoglobulin in the blood. IgE is important to allergic(过敏) response interacting with basophils(嗜碱性粒细胞) and mast cells(肥大细胞). When bound by Fc, the cells secrete amines like histamine causing dilation(膨胀) and permeability(渗透). Some macrophages receptors recognize and bind IgG’s Fc and engulf(内吞) the complex by phagocytosis(吞噬作用). 4. Antibodies bind tightly and specifically to antigen A typical antibody-antigen interaction is induced fit with Kd of 10^-10M(65KJ/mol). 5. The antibody-antigen interaction is the basis for a variety of important analytical procedures Polyclonal(多克隆) antibodies and monoclonal(单克隆) antibodies. Chromatography column is used to get proteins. Enzyme-linked immunosorbent assay(ELISA) allows for rapid screening and quantification of antigen. Immunoblot assay allows for the detection of a minor component and provides an approximate molecular weight. 5.3 Protein interactions modulated by chemical energy: actin, myosin, and molecular motors Kinesins(驱动蛋白) and dyneins(动力蛋白) move along microtubules(微管) pulling organelles and chromosomes. 1. The major proteins of muscle are myosin(肌球蛋白) and actin(肌动蛋白) Myosin forming thick filaments has 2 heavy chains and 4 light chains. The heavy chains have extended α helices at carboxyl termini in left-handed coiled coil. Each heavy chain has a globular domain at amino terminus with an ATP site. The light chains are associated with the domains. Myosin can be cleaved into heavy and light meromyosin(酶解肌球蛋白) by trypsin(胰蛋白酶), and heavy meromyosin into the head group and rest by papain(木瓜蛋白酶). F-actins form thin filaments with troponin(肌钙蛋白) and tropomyosin(原肌球蛋白). 2. Additional proteins organize the thin and thick filaments into ordered structures Skeletal muscle consists of muscle fibers, muscle fibers consist of myofibrils(肌原纤维) surrounded by sarcoplasmic reticulum(肌质网). In myofibrils there are I bands(only thin filaments) and darker A bands(thick filaments and overlap). In the middle of A bands there are M lines. In the middle of I bands there are Z disks as anchors thin filaments are attached to. Sarcomeres(肌小节) are between Z disks. α-actinin(α-辅肌动蛋白), desmin(肌间线蛋白), vimentin(波形蛋白), nebulin(伴肌动蛋白), paramyosin(副肌球蛋白), titins(肌联蛋白), C-protein and M-protein are additional. Titins regulate the length of sarcomeres and prevent overextension. 3. Myosin thick filaments slide along actin thin filaments First ATP binds to myosin(an ATPase), actin is released, ATP is hydrolyzed making the myosin head move to next F-actin. Then ADP is released strengthening the myosin-actin binding. The interaction is regulated by a complex of tropomyosin and troponin. Tropomyosin binds to the thin filament blocking the sites for the head groups. When impulsed by nerve, the sarcoplasmic reticulum releases Ca2+ changing the conformation to expose the sites. Chapter 6 Enzymes Two fundamental conditions for life: self-replicate and catalyze reactions. Enzymes have a high specificity for substrates(底物), accelerate reactions and function in aqueous solutions and mild temperature and pH. Measurements of enzymes in systems are important for diagnosing illnesses, and some drugs make effects through interaction with enzymes. They are important to chemical industry. 6.1 An introduction to enzymes Haldane suggested weak bonding interactions between enzymes and substrates are used to catalyze reactions. 1. Most enzymes are proteins A small group are RNA. Protein enzymes’ catalytic activity depends on the integrity(完整) of conformation. Molecular weights: 12000 to over 1 million. Some need cofactor(辅因子)-transient(短暂的) carriers of specific functional groups-such as inorganic ions or coenzyme(辅酶) to catalyze and they are called prosthetic group(辅基). Enzyme and prosthetic group together are called holoenzyme(全酶) and protein part is called apoenzyme or apoprotein(脱辅基酶蛋白). Some enzyme proteins are modified by phosphorylation(磷酸化作用), glycosylation(糖基化). 2. Enzymes are classified by the reactions they catalyze Many of them are named “substrate or activity-ase”. Others are named by their broad functions. Naming system divides enzymes into six classes: (1)oxidoreductases(氧化还原酶), (2)transferases(转移酶), (3)hydrolases(水解酶), (4)lyases(裂合酶), (5)isomerases(异构酶) and (6)ligases(连接酶). We use for numbers to number enzymes: class.subclass.acceptor on the enzyme.group to accept. 6.2 How enzymes work Enzymes provide specific environment in which reactions occur rapidly, that’s active site, whose surface is lined with amino acid residues to bind substrates. It usually sequesters(螯合) substrates from solution. 1. Enzymes affect reaction rates, not equilibria E+S ES EP E+P. Biochemical standard free-energy change ΔG’° in pH7.0 is different from standard free-energy change ΔG°. The ΔG’° between ground states(基态) S and P decides the equilibrium(平衡). The energy between transition state and ground state is activation energy ΔG‡ deciding the rate. Enzymes can lower activation energies by introduce reaction intermediates(中间体) and accelerate both sides. Reaction intermediates have a longer chemical lifetime than molecular vibration(振动) which is about 10 的-13 次方 seconds. The overall rate is determined by the step or steps with the highest activation energy called the rate-limiting step. 2. Reaction rates and equilibria have precise thermodynamic definitions K’eq(K’)=[P]/[S], ΔG’°=-RTlnK’eq. Rate equation: V=k[S] (first-order) or V=k[S1][S2] (second-order). k=e^(-ΔG‡/RT)kT/h. 3. A few principles explain the catalytic power and specificity of enzymes Two ways to lower the energy: Rearrangements of covalent bonds occurring in the enzyme active site, noncovalent interactions between enzyme and substrate providing binding energy ΔGB, which is the major source of free energy. Two principles: much catalytic power of enzymes is derived from the released free energy, active sites are complementary(补充) to the transition states per se(本质上) rather than the substrates. 4. Weak interactions between enzyme and substrate are optimized in the transition state They fit together like a lock and key. The optimal interactions occur only in the transition state. ΔGB is added to ΔG‡ to make a lower net activation energy. The weak interactions formed only in the transition state make the primary contribution to catalysis. The size of protein shows the superstructure keeping interacting groups position and the cavity not collapsing. 5. Binding energy contributes to reaction specificity and catalysis Binding energy can also provide enzyme specificity between a substrate and a competing(竞争) molecule. (1) Binding energy can provide entropy reduction to restrict the relative motions of two substrates. (2) Formation of weak bonds can cause desolvation(去溶剂化) of the substrate. (3) Binding energy helps to compensate(补偿) for distortion, primarily electron redistribution(重分配). (4) Induced fit makes specific functional groups into the proper position. 6. Specific catalytic groups contribute to catalysis They are different from mechanisms based on binding energy because there are transient(瞬时) covalent interaction. (1) General acid-base catalysis In the active site, amino acid side chains can act as proton donors and acceptors. Proton transfers are most common. Specific acid-base catalysis uses only H+ and OH- of water. (2) Covalent catalysis Some amino acid side chains and cofactors’ functional groups can be as nucleophiles(亲核试剂) to form covalent bonds. (3) Metal ion catalysis Ionic interactions can help orient the substrate for reaction or stabilize charged reaction transition states. 6.3 Enzyme kinetics as an approach to understanding mechanism Enzyme kinetics(动力学) shows the mechanism determining the rate and how it changes. 1. Substrate concentration affects the rate of enzyme-catalyzed reactions When [S]>>[E] initial rate/velocity(初始速率) V0 is easy to measure. It reflects steady state because the pre-steady state is too short. V0 increases more and more slowly when [S] increases, until it reaches maximum velocity Vmax. Saturation(饱和) kinetics is the characteristic of enzymatic catalysts. E+S ES(k1 k-1) E+P(k2 k-2). The second reaction limit the whole rate, so the rate is depended on [ES]. 2. The relationship between substrate concentration and reaction rate can be expressed quantitatively Ignoring k-2, V0=k2[ES]. Rate of ES formation=k1([Et](total)-[ES])[S], rate of ES breakdown=k-1[ES]+k2[ES]. They are equal according steady-state assumption, so [ES]=[Et][S]/([S]+(k2+k-1)/k1)=[Et][S]/(Km+[S]), Km is Michaelis constant. So V0=k2[Et][S]/(Km+[S])=Vmax[S]/(Km+[S]). That’s the rate equation for a one-substrate enzyme-catalyzed reaction: Michaelis-Menten equation. When V0=0.5Vmax, Km=[S]. 3. Kinetic parameters are used to compare enzyme activities Enzymes following Michaelis-Menten kinetics have a hyperbolic(双曲线) dependence of V0 on [S]. Regulatory enzymes are important exceptions. When k2<<k-1, Km≈Kd. kcat can replace k2 for wider equations. kcat is also called the turnover number. When [S]<<Km, V0=[Et][S]kcat/Km. kcat/Km is called specificity constant. If it’s 10^8~9M-1s-1 the enzymes have achieved catalytic perfection. 4. Many enzymes catalyze reactions with two or more substrates There is a noncovalent ternary complex or not showed by steady-state kinetics according to the time two substrates bind. 5. Pre-steady state kinetics can provide evidence for specific reaction steps During pre-steady state the rates of many reaction steps can be measured independently. Energy changes during the reaction can help. 6. Enzymes are subject to reversible or irreversible inhibition Enzyme inhibitors are among the most important pharmaceutical(药物的) agents known. One common type of reversible inhibition is competitive(竞争性抑制) by competitive inhibitor(I). The Michaelis-Menten equation becomes V0=Vmax[S]/(αKm+[S]), α=1+[I]/KI, KI=[E][I]/[EI]. Now apparent Km is αKm. The competition can be biased(偏见) to the substrate by adding substrate. Another type is uncompetitive. Uncompetitive inhibitor binds at a site different from the active site on the ES. The Michaelis-Menten equation becomes V0=Vmax[S]/(Km+α’[S]), α’=1+[I]/K’I, K’I=[ES][I]/[ESI]. So uncompetitive inhibitor lowers the measured Vmax and appearnt Km. Mixed inhibitor binds at a site different the active site on either E or ES. The Michaelis-Menten equation becomes V0=Vmax[S]/(αKm+α’[S]). When α=α’ it’s noncompetitive inhibition just affecting Vmax. Usually some reaction products can be inhibitors. In irreversible inhibition irreversible inhibitors bind covalently with or destroy enzymes’ functional group. A special class is the suicide inactivators(灭活剂) producing mechanism-based inactivators. 7. Enzyme activity depends on pH Amino acid side chains in the active site can act as weak acids and bases. Uncommonly substrate groups can be important to pH sensitivity. The pH range can provide a clue to the type of residues involved, for example, an activity change near pH 7.0 reflects His. A nearby positive charge can lower the pKa of Lys, and negative charge can increase it. 6.4 Examples of enzymatic reactions 1. The chymotrypsin(胰凝乳蛋白酶) mechanism involves acylation(酰化) and deacylation(脱酰) of a Ser residue It’s a general acid-base and covalent catalysis specific for peptide bonds adjacent to aromatic(芳香) residues. Functional groups in the active site are His57, Asp102 and Ser195. Ser195 is linked to other two in a hydrogen-bonding network as the catalytic triad(三联体). When bound by a peptide substrate the bond between His57 and Asp102 becomes stronger as low-barrier hydrogen bond, enhancing the pKa of His57 to make it as a base to remove the proton from the Ser195 hydroxyl group. It also catalyzes the hydrolysis of small esters(酯) and amides(酰胺). When catalyzing, a transient covalent acyl-enzyme intermediate is formed. In the acylation phase the bond is cleaved and an ester linkage(酯键) is formed between the carbonyl C and the enzyme. In the deacylation phase the ester linkage is hydrolyzed and the nonacylated enzyme regenerated. When pH increases, kcat increases and be stable because His57 has protonation(质子化) at low pH so it can’t extract a proton from Ser195(whose oxygen is nucleophile in the acylation phase). 1/Km changes in opposite way. The rate changes in a bell-shaped way. When Ser195 oxygen attacks the carbonyl group of the substrate a transient tetrahedral(四面体) intermediate is formed where the carbonyl O acquires a negative charge, forming within the oxyanion hole, stabilized by hydrogen bonds of amide groups. The bond from Gly193 reduces the energy for the states. 2. Hexokinase(己糖激酶) undergoes induced fit on substrate binding It’s a bisubstrate enzyme. ATP and ADP always bind to enzymes as a complex with Mg2+. When there is no glucose the enzyme’s active-site side chains is out of reaction position so it’s in an inactive conformation. The binding energy from glucose and Mg·ATP binding induces a conformational change. The specificity is not in the formation of ES but in the rates of catalytic steps. Reaction rates increase greatly in the presence of functional phosphoryl(磷酰基) group acceptor like glucose. 3. The enolase(烯醇化酶) reaction mechanism requires metal ions It’s a dimer. First Lys345 acts as a base abstracting a proton from C-2 of 2-phosphoglycerate(磷酸甘油酸), then Glu211 acts as a acid donating a proton to the OH leaving group. In the active site, 2-phosphoglycerate has strong ionic interaction with two Mg2+ making the C-2 proton more acidic and easier to abstract. 4. Lysozyme(溶菌酶) used two successive nucleophilic displacement reactions It has 4 disulfide bonds and a cleft(裂缝) containing the active site. The substrate is peptidoglycan(肽聚糖). There are 2 possible mechanisms: dissociative and alternative. 6.5 Regulatory enzymes Regulatory enzymes have increased or decreased catalkytic activity in response to certain signals. Often the first enzyme of the whole reaction is a regulatory enzyme. Allosteric enzymes function through reversible noncovalent binding of regulatory compounds called allosteric modulators/effectors. Other regulatory enzymes are regulated by reversible covalent modification. Two other mechanisms: some enzymes are stimulated(促进) or inhibited when bound by regulatory proteins, others are activated when peptide segments are removed by irreversible proteolytic(蛋白水解) cleavage. 1. Allosteric(变构) enzymes undergo conformational changes in response to modulator binding Often the modulator is the substrate. Homotropic(同位) regulatory enzymes have the same modulators and substrates, heterotropic(异位) not. It’s different from uncompetitive and mixed inhibitors because they don’t necessarily mediate conformational changes. Allosteric enzymes have some regulatory/allosteric sites for modulator in addition to active sites. 2. In many pathways a regulated step is catalyzed by an allosteric enzyme In some multienzyme systems the regulatory enzyme is inhibited by end product over cell’s requirements. This is called feedback inhibition(反馈抑制). The conversion of L-threonine to L-isoleucine in bacteria is a heterotropic example. 3. The kinetic properties of allosteric enzymes diverge from Michaelis-Menten behavior Some allosteric enzymes’ plots of V0 versus [S] is a sigmoid saturation curve(S 型饱和曲线). Now when V0=0.5Vmax [S]≠Km. Instead we use [S]0.5 or K0.5 to represent the substrate concentration now. Sigmoid kinetic is explained by the concerted(协调) and sequential(连续) models. Often for homotropic allosteric enzymes the substrate is a positive modulator, so small changes of modulator can cause large changes in activity. For heterotropic allosteric enzymes modulators can be activators changing Vmax or K0.5, or inhibitors producing a more sigmoid curve with an increase in K0.5. 4. Some regulatory enzymes undergo reversible covalent modification Modifying groups include phosphoryl(磷酰基), adenylyl(腺嘌呤), uridylyl(尿嘧啶), methyl(甲基) and adenosine diphosphate ribosyl(二磷酸腺苷核糖). Phosphorylation(磷酸化) is the most common and entral to many regulatory pathways. Methyl-accepting chemotaxis(趋药性) protein permits a bacterium to wium toward an attractant and away from repellent chemicals. The methylating agent is S-adenosylmethionine(腺苷甲硫氨酸).ADP-ribosylation occurs for the bacterial enzyme dinitrogenase(固氮酶) reductase(还原酶).Diphtheria(白喉) and cholera(霍乱) toxin catalyze the ADP-ribosylation(核糖基化). Cholera toxin acts on a G protein. 5. Phosphoryl groups affect the structure and catalytic activity of proteins Protein kinases(激酶) catalyze the attachment of phosphoryl and protein phosphatases(磷酸酶) catalyze removal. The O can form hydrogen-bond with some groups in the protein commonly the amide groups of the peptide backbone at the start of α-helix or the charged guanidinium(胍盐) group of Arg. It’s negative charges repel Asp and Glu. Another way for phosphorylation affecting catalysis is altering substrate-binding affinity, for example, phosphorylated isocitrate(异柠檬酸盐) dehydrogenase(脱氢酶) inhibits the binding of citrate because of electrostatic repulsion. One example: (glucose)n+Pi=(glucose)n-1+glucose 1-phosphate, which can be used to form ATP or converted to glucose. Phosphorylase a(more active with 2 Ser phosphorylated at hydroxyl group) and b can catalyze. a+2H2O=b+2Pi, 2ATP+b=2ADP+a. 6. Multiple phosphorylations allow exquisite regulatory control Phosphorylated Ser, Thr or Tyr occur within common motifs called consensus( 一 致 ) sequences. Sometimes the phosphorylation is hierarchical(分级). Phosphoprotein phosphatases act only on a subset(子装置) of phosphoproteins but with less substrate specificity than protein kinases. 7. Some enzymes and other proteins are regulated by proteolytic cleavage of an enzyme precursor(前体) Inactive precursor called zymogen(酶原), or more generally proproteins/proenzymes, is cleaved irreversibly to form the active enzyme. 8. Some regulatory enzymes use several regulatory mechanisms Glycogen phosphorylase’s primary regulation is covalent modification, and also modulated allosterically by AMP as activator of phosphorylase b and other inhibitors. Bacterial glutamine synthetase is regulated allosterically, by reversible covalent modification and by the association of other regulatory proteins. Chapter 7 Carbohydrates and glycobiology Carbohydrates(糖) are polyhydroxy aldehydes(醛) or ketones(酮) or substances yielding such compounds on hydrolysis. Monosaccharides(单糖) are simple sugars and if carbons are more than 4 they tend to have cyclic structures. Six-carbon sugar D-glucose or dextrose(葡萄糖) are common. Oligosaccharides(低聚糖) join the units by O-glycosidic bonds(糖苷键). Disaccharides(二 糖 ) are common. In cells most oligosaccharides form glycoconjugates. Polysaccharides( 多 聚 糖 ) are glycans(聚糖) such as cellulose(纤维素) is linear and glycogen(糖原) is branched. Some carbohydrate polymers covalently attached to proteins or lipids forming glycoconjugates(复合糖) act as signals determining the intracellular location or metabolic fate. 7.1 Monosaccharides and disaccharides 1. The two families of monosaccharides are aldoses(醛糖) and ketoses(酮糖) In monosaccharide carbon atoms are linked by single bonds unbranched. The simplest monosaccharides are aldotriose(三 碳醛糖) glyceraldehyde(甘油醛) and ketotriose(三碳酮糖) dihydroxyacetone(二羟丙酮). Monosaccharides are aldo-/ketotetroses(四)/pentoses(五)/hexoses(六)/heptoses(七). 2. Monosaccharides have asymmetric centers Except dihydroxyacetone monosaccharides all have asymmetric/chiral(手性) carbon atoms. Fischer projection formulas can show it. Put C=O up and see the most below chiral carbon, if the OH is on the right it’s D, if left it’s L. Epimers(差向异构 体)’s configurations differ only in one carbon. Most hexoses of living organisms are D. L-arabinose(阿拉伯糖) is exceptional. Cs are numbered from the end nearest the carbonyl(羰基). 4 or 5 carbon ketoses insert “ul” before –ose than aldoses. 3. The common monosaccharides have cyclic structures The C=O forms a covalent bond with the O of OH in the reaction hemiacetals(半缩醛) or hemiketals(半缩酮), containing an additional chiral carbon anomeric carbon(异头碳) forming anomers(异头物) α(OH 与 CH2OH 异面) and β. They can interconvert by mutarotation(变旋光). Six-membered ring is pyranose(吡喃糖) and five-membered is furanose(呋喃糖). Haworth perspective formulas can show the circle. 4. Organisms contain a variety of hexose derivatives OH is replaced or C is oxidized to COOH can form sugar derivatives. Glucosamine(葡萄糖胺) derivative is part of many structural polymers. N-acetylmannosamine derivative N-acetylneuraminic acid is in many glycoproteins and glycolipids. Oxidation of the aldehyde carbonyl carbon to carboxyl produces aldonic acid and oxidation of the carbon at the other end forms uronic acid. Both form stable lactones(内酯). Sugar phosphates are relatively stable at neutral pH and bear a negative charge, helping trapping the sugar inside the cell. Phosphorylation also activates sugars for subsequent(后续) chemical transformation(变化). 5. Monosaccharides are reducing agents Reducing sugars can be oxidized by relatively mild oxidizing agents like Fe3+ or Cu2+ changing C of carbonyl to carboxyl. It’s the basis of Fehling’s reaction. 6. Disaccharides contain a glycosidic bond Glycosidic bonds are readily hydrolyzed by acid but resist cleavage by base. The oxidation above only occurs with the linear form, so when anomeric carbon(reducing end) is in a glycosidic bond the sugar can’t be oxidized and becomes a nonreducing sugar. Maltose(麦芽糖) has a free anomeric C so it’s a reducing sugar. The configuration of the anomeric C in the glycosidic linkage is α. To name a reducing d isaccharides we use α/β-D/L-residue linked by anomeric C-(linked number→next linked number)-D/L-next residue. So maltose is α-D-glucopyranosyl-(1→4)-D-glucopyranose and for short Glc(α1→4)Glc. Lactose( 乳 糖 ) is Gal(β1→4)Glc. Nonreducing disaccharides are named as glycosides( 苷 ), so sucrose( 蔗 糖 ) is Glc(α1←→2β)Fru or Fru(β2←→1α)Glc, trehalose(海藻糖) is Glc(α1←→1α)Glc. Some abbreviations: abequose(阿比可糖) Abe, arabinose(阿拉伯糖) Ara, fructose(果糖) Fru, fucose(岩藻糖) Fuc, galactose (半乳糖) Gal, glucose(葡萄糖) Glc, mannose(甘露糖) Man, rhamnose(鼠李糖) Rha, ribose(核糖) Rib, xylose(木糖) Xyl, glucuronic acid( 葡 糖 醛 酸 ) GlcA, galactosamine( 半 乳 糖 胺 ) GalN, glucosamine( 葡 萄 糖 胺 ) GlcN, N-acetylgalactosamine(乙酰半乳糖胺) GalNAc, N-acetylglucosamine(乙酰氨基葡糖) GlcNAc, iduronic acid(艾杜糖醛酸) IdoA, muramic acid(氨基糖酸) Mur, N-acetylmuramic acid(乙酰胞壁酸) Mur2Ac, N-acetylneuraminic acid(乙酰神经氨酸) Neu5Ac(it’s a sialic(含硅) acid). 7.2 Polysaccharides Homopolysaccharides(同多糖) contain only one kind of monomer(单体) while heteropolysaccharides(异多糖) not. Some homopolysaccharides like starch(淀粉) and glycogen(糖原) are storage forms of fuels, some like cellulose(纤维素) and chitin(几丁质) are structural elements. Heteropolysaccharides provide extracellular support. 1. Some homopolysaccharides are stored forms of fuel Starch and glycogen are heavily hydrated(水合). Starch has two kinds: amylose(直链) and amylopectin(支链). The former is (α1→4) and the latter has some (α1→6). Glycogen is more extensively branched and more compact. Glycogen has many nonreducing ends and only 1 reducing end. Glucoses are removed from the nonreducing ends. Dextrans(葡聚糖) are in bacterial and yeast. They are (α1→6) and all have (α1→3) branches, some have (α1→2) or (α1→4) branches. They can be used in some chromatography products. 2. Some homopolysaccharides serve structural roles In cellulose the glucose residues are β linked by (β1→4) so it can’t be digested by α-enzymes. Chitin is made of N-acetylglucosamine residues in β linkage. It forms the hard exoskeletons of arthropods(节肢动物). 3. Steric factors and hydrogen bonding influence homopolysaccharide folding Hydrogen bonding has an especially important influence. All are like polypeptide. The most stable structure for starch and glycogen is a tightly coiled helix with 6 residues per turn. For amylose the core is suitable for I3- or I5-. For cellulose the most stable conformation is a straight extended chain. 4. Bacterial and algal(藻) cell walls contain structural heteropolysaccharides Bacterial cell walls are alternating N-acetylglucosamine and N-acetylmuramic acid residues linked by (β1→4) which can be hydrolyzed by lysozyme. Some seaweeds(海藻) have cell walls containing agar(琼脂). Two major components of agar are unbranched agarose(琼脂糖) and branched agaropectin(琼脂胶). When cooled agarose forms a double helix to make gel(凝胶). 5. Glycosaminoglycans(粘多糖) are heteropolysaccharides of the extracellular matrix Extracellular matrix is also called ground substance. Glycosaminoglycans are linear polymers composed of disaccharide units, always N-acetylglucosamine or N-acetylgalactosamine+uronic acid like D-glucuronic or L-iduronic acid. Sometimes the combination of sulfate and the carboxylate groups of uronic acid gives it a high negative charge, so it extends in solution. Glycosaminoglycans are attached to proteins to form proteoglycans(蛋白多糖). Hyaluronic acid(透明质酸) serves as lubricants(润滑剂) in synovial(滑膜) fluid of joints and gives the vitreous(玻璃状) humor(液) to eyes. It also serves in cartilage(软骨) and tendons(腱). Hyaluronidase is important for sperms entering ovum(卵 子). Other glycosaminoglycans are shorter and covalently linked to specific proteins. There are chondroitin sulfate(软骨素硫酸 盐), dermatan sulfate(皮肤素硫酸盐) and keratan sulfates(角质素硫酸盐). Heparin(肝素) inhibits thrombin(凝血酶). 7.3 Glycoconjugates: proteoglycans, glycoproteins, and glycolipids They can be destination labels(标志) for some proteins and as mediators of specific cell-cell and cell-matrix interactions. The informational carbohydrate is covalently joined to a protein or a lipid forming a glycoconjugate(复合糖). Proteoglycans(蛋白多糖) are on the cell surface or in extracellular matrix rich in connective tissue, mainly made by glycosaminoglycan(糖胺聚糖) joined to membrane protein or secreted protein. Glycosaminoglycan is often the main biological activity site. Glycoproteins(糖蛋白) are on the surface of plasma membrane, in the extracellular matrix, in Golgi complexes, secretory granules(颗粒), lysosomes(溶酶体) and in the blood. They are made of some oligosaccharides joined to a protein. The oligosaccharides are more complex so rich in information, forming highly specific recognition sites and high-affinity binding. Glycolipids(糖脂) are membrane lipids whose heads are oligosaccharides. They act as specific sites for recognition(识别). 1. Proteoglycans are glycosaminoglycan-containing macromolecules of the cell surface and extracellular matrix Proteoglycan superfamily members act as tissue organizers and influence the tissues development, mediate growth factors activities and regulate collagen fibrils extracellular assembly. Proteoglycan basic unit is a core protein(核心蛋白) with glycosaminoglycans often attached at Ser through a trisaccharide bridge as Ser-Gly-X-Gly. Some proteoglycans are secreted, some are integral(固有) membrane proteins. Syndecans(多配体) and glypicans(磷脂酰肌醇) are two families of core proteins. Glypicans are attached to the membrane by a lipid anchor. In proteoglycans heparan sulfate(类肝素硫酸盐) bind extracellular ligands and modulate their interaction with receptors. The glycan chain is made by enzymes introducing alterations in specific regions, so the result is Highly sulfated domains(S domains) alternate with N-acetylated/NA domains having unmodified GlcNAc and GlcA. S domains bind to extracellular proteins and signaling molecules to alter their activities. Sometimes the activity changes come from the conformation change, or because the heparan sulfate adjacent domains bind two proteins enhancing protein-protein interactions, or because the binding increases the concentrations of signal molecules, or S domains interact with soluble molecules maintaining high concentrations on the cell surface. Many core proteins bound to a single hyaluronate(透明质酸盐) form proteoglycan aggregates(集合体) which interact strongly with collagen contributing to the development and tensile(可拉长的) strength of cartilage. Proteoglycans are interwoven(交织) by fibrous matrix proteins. Some proteins are multiadhesive with many binding sites for different matrix molecules. The cell-matrix interactions serve to anchor cells to the extracellular matrix, and provide paths directing the migration of cells, and through integrins(整联蛋白) exchange information across the plasma membrane. To make proteins on membrane, some core proteins are anchored by a single transmembrane helix, some attached membrane glycolipid and some released into the extracellular space forming part of the basement membrane. 2. Glycoproteins have covalently attached oligosaccharides The carbohydrate is attached at anomeric C to the OH of Ser or Thr through a glycosidic link(O-linked), or to the amide N of Asn through N-glycosyl link(N-linked). There are many glycoproteins on the external plasma membrane surface and many secreted proteins are glycoproteins including most proteins in blood. Tissue glycoforms(糖形) have tissue-specific marker on oligosaccharide chains. The hydrophilic clusters of carbohydrate alter the polarity and solubility of the proteins. The bulkiness and negative charge of oligosaccharide chains also influence the folding and can also protect proteins from proteolytic(蛋白水解) enzymes. 3. Glycolipids and lipopolysaccharides(脂多糖) are membrane components Gangliosides(神经节苷脂) are important to blood group type. They are membrane lipids in which the polar head group, the part of the lipid forms the membrane outer surface. Lipopolysaccharides are the dominant part of the outer membrane of gram-negative bacteria. They are targets of the antibodies and are important to the serotype(血清型) of bacterial strains. Some bacteria lipopolysaccharides are toxic. 7.4 Carbohydrates as informational molecules: the sugar code Branches are common in oligosaccharides. Oligosaccharides are rich in structural information. 1. Lectins(凝集素) are proteins that read the sugar code and mediate many biological processes Lectins bind carbohydrates with high affinity and specificity and serve in cell-cell recognition, signaling and adhesion processes and in intracellular targeting of newly synthesized proteins. A lectin can recognize luteinizing hormone(黄体生成素) and thyrotropin(促甲状腺素)’s N-linked oligosaccharides ending with disaccharide GalNAc4S(β1→4)GlcNac to reduce them. Neu5Ac(a sialic(唾液) acid) at the ends of many plasma glycoproteins’ oligosaccharide chains protect the proteins from uptake(吸收) and degradation in the liver. Hepatocytes(肝细胞) has lectin specifically binding oligosaccharide chains with galactose residues not protected by that. Receptor-ceruloplasmin(血浆铜蓝蛋白) interaction triggers(触发) endocytosis(内吞) and destruction of ceruloplasmin. The body can mark old proteins through removal of the sialic acid residues by sialidase/neuraminidase(唾液酸酶/神经氨 酸苷酶) to destruct them. That for erythrocytes(红血球) is similar. Some viruses attach to host cells through interactions with oligosaccharides on the host cell surface. The lectin of the influenza virus is the HA protein. The removal of terminal sialic acid residue triggers the entry of the virus into the cell. Selectins(选择蛋白) are a family of plasma membrane lectins mediating cell-cell recognition and adhesion, like the movement of immune cells. At an infection site, P-selectin on the surface of capillary endothelial(毛细血管内皮) cells interacts with T cells’ oligosaccharide, slowing the T cells. Another interaction between integrin(整联蛋白) in the T cells’ plasma membrane and adhesion protein on the endothelial cell surface stops the T cells and makes them pass the capillary wall. E-selectin and L-selectin also have functions. Some microbial pathogens(病原体) hve lectins mediating bacterial adhesion to host cells or toxin entry into cells. Intracellularly(细胞内), oligosaccharide containing mannose 6-phosphate marks newly synthesized proteins in the Golgi complex for transfer to the lysosome. Signal patch(斑) is common structural feature of these glycoproteins, making them recognized by enzyme phosphorylating a mannose(甘露糖) residue at the terminus of oligosaccharide chain. Mannose phosphate makes protein dragged into the forming bud, the vesicel(小泡) then moves to and fuses with a lysosome. When the protein tagged(标签) with mannose 6-phosphate reaches the lysosome(pH lower than Golgi complex) the receptor loses affinity for mannose 6-phosphate. Protonation of His105 may be responsible for this change in binding. 2. Lectin-carbohydrate interactions are very strong and highly specific The oligosaccharides have unique structures so the recognition by lectins is highly specific. Besides there are general interactions contributing to the binding of carbohydrates to lectins. Many sugars have a more polar side hydrogen-bonding with the lectin and a less polar side undergoing hydrophobic interactions with nonpolar amino acid residues. 7.5 Working with carbohydrates Oligosaccharides are removed from protein or lipid conjugates before analysis by glycosidases, and the mixtures are separated by fractional precipitation(沉淀), ion-exchange and size-exclusion chromatography.Highly purified lectins are commonly used in affinity chromatography. Then oligosaccharides are degraded revealing bond position or stereochemistry. Exoglycosidases(外切糖苷酶) are used to remove residues one at a time from the nonreducing end. Endoglycosidases can be used to split(切) specific glycosidic bonds. Mass spectrometry(质谱) and NMR spectroscopy(核磁共振) are also used. Comparison of masses of each fragment gives information about the sequence of monosaccharide units. NMR can give information about sequence, linkage position and anomeric C configuration. Chapter 8 Nucleotides and Nucleic acids Nucleotides(核苷酸) are energy currency, chemical links in cells response to hormones(激素) and extracellular stimuli(胞 外促因子), structural components of some enzyme cofactors(辅因子) and metabolic intermediates(中间物), constituents of nucleic acids-deoxyribonucleic acid(DNA) and ribonucleic acid(RNA). 8.1 Some basics DNA’s functions are storage and transmission of biological information. Ribosomal RNAs are components of ribosomes, messenger RNAs are intermediaries carrying genetic information, transfer RNAs are adapter molecules translating the information, and other kinds of RNAs. 1. Nucleotides and nucleic acids have characteristic bases(碱基) and pentoses(戊糖) A nitrogenous(含氮) base, a pentose(forming a nucleoside(核苷)) and a phosphate(磷酸) compose a nucleotide. Two kinds of bases are pyrimidine(嘧啶)-cytosine(C), thymine(T) and uracil(U) and purine(嘌呤)-adenine(A) and guanine(G). See page 274 figures. Commonly bases and pentoses are heterocyclic(杂环). The numbers of pentose-see chapter 7-are added a prime(’). Base is joined by N-1 of pyrimidines or N-9 of purines(losing hydrogen) to 1’ carbon of the pentose by an N-β-glycosyl bond(losing hydroxyl(羟基)), and the phosphate(losing H) is joined to the 5’ carbon. DNA has 2’-deoxy-D-ribose(核糖) and RNA has D-ribose, both are β-furanose(呋喃糖) and have some conformations of 2’ and 3’ carbon at the same(endo) or the opposite(exo) side with 5’carbon. Page 276 figure 8-5 shows some minor purine and pyrimidine. In DNA methylated(甲基化) forms of major bases are common. In some viral DNAs, certain bases may be hydroxymethylated or glucosylated. In RNAs, minor bases are usually found in tRNAs. They often regulate or protect the genetic information. Words: adenosine(腺嘌呤核苷), adenylate(腺嘌呤核苷酸), deoxyadenosine(腺嘌呤脱氧核苷酸), guanosine(鸟嘌呤核 苷 ), guanylate( 鸟 嘌 呤 核 苷 酸 ), cytidine( 胞 嘧 啶 核 苷 ), cytidylate( 胞 嘧 啶 核 苷 酸 ), thymidine( 胸 腺 嘧 啶 脱 氧 核 苷 ), thymidylate(胸腺嘧啶脱氧核苷酸), ribothymidine(胸腺嘧啶核苷), uridine(尿嘧啶核苷), uridylate(尿嘧啶核苷酸). Derivative: 5-methylcytosine for example. If the substituted atom is exocyclic(环外) we use the word for the atom with the number of the carbon linked on the right top. We also have adenosine 2’-monophosphate or adenosine 2’,3’-cyclic monophosphate for examples. 2. Phosphodiester(磷酸二酯) bonds link successive nucleotides in nucleic acids Formed by joining 5’-phosphate to another 3’ carbon phosphodiester bonds form hydrophilic(亲水的) backbones of DNAs and RNAs because hydroxyl groups of the sugar residues(残基) form hydrogen bonds with water. So there is 5’ end and 3’ end. Phosphate group’s pKa is near 0 and completely negatively charged at pH 7. Under alkaline(碱性的) conditions RNA is hydrolyzed(水解) rapidly when 2’hydroxyl(羟基) group is directly involved but DNA is not because losing that. First cyclic 2’,3’-monophosphate nucleotides are produced and then hydrolyzed to a mixture of 2’- and 3’-nucleoside monophosphates. Schematically representation: 带圈 P 的折线表示主链,支链上用字母表示碱基,左 5’右 3’,末端左圈 P 右 OH. Other simple representations: pA-C-G-T-AOH, pApCpGpTpA, pACGTA. 3. The properties of nucleotide bases affect the three-dimensional structure of nucleic acids The bases are highly conjugated(共轭) and resonance(共振) gives most bonds partial double-bond character. As results: pyrimidines are planar, purines are nearly planar with a slight pucker(折叠); they all absorb UV light strongly near 260nm; they have some tautomeric(互变异构体) forms depending on the pH, for example, uracil has lactam(两个氧), lactim(氧中间氮上氢 到外面氧上) and double lactim. At neutral pH the bases are hydrophobic and relatively insoluble in water. The solubility increases at acidic or alkaline pH. They are positioned with the planes of their rings parallel. Base stacking minimizes contact between bases and water. A=T, CΞG. The most important functional groups are ring nitrogens, carbonyl groups and exocyclic amino groups. 8.2 Nucleic acid structure Of a nucleic acid, the primary structure is sequence, the secondary structure is regular or stable structure and the tertiary structure is the folding of large chromosomes in eukaryotic chromatin(染色质) and bacterial nucleoids(核状体). 1. DNA stores genetic information Friedrich Miescher found substance from bandages. Oswald T. Avery, Colin MacLeod and Maclyn McCarty’s experiment of pneumococcus(肺炎双球菌). Alfred D.Hershey and Martha Chase’s experiment using radioactive phosphorus(磷) and sulfur(硫) tracers(示踪原子) and bacterial virus(bacteriophage) T2. 2. DNA molecules have distinctive base compositions Chargaff’s rules-Erwin Chargaff’s conclusions: (1) Species’ DNA base compositions are different. (2) DNAs from the same species have the same base composition. (3) The base composition of DNA of a certain organism doesn’t change. (4) A=T, C=G and A+G=T+C. 3. DNA is a double helix Rosalind Franklin and Maurice Wilkins’ result of x-ray diffraction is important. Watson and Crick’s right-handed antiparallel(反平行) double complementary helix model of DNA(B-form DNA), all furanose ring is C-2’ endo conformation, bases are perpendicular(垂直) to the axis. There is a major groove(沟) and a minor groove on different surfaces. The distance between bases is 3.4Å(primary structure) and there are ten base pairs in a complete turn(secondary structure). Hydrogen bonding and base-stacking interactions which are nonspecific found duplex(双螺旋). 4. DNA can occur in different three-dimensional forms Free rotation can happen about backbone and the C-1’-N-glycosyl bond. Syn(扣向里) and anti(翻向外) are two stable conformations for purines. Pyrimidines are usually restricted to anti because two O. Besides B-DNA, there are A and Z forms. A is right-handed wider double helix with 11 pairs per turn, favored in solutions devoid(缺乏) of water. It deepens the major groove and makes minor groove shallower. Most short DNA tend to crystallize in A form. Z is left-handed with 12 pairs per turn. It’s thinner than B with a zigzag backbone. The major groove is not apparent and the minor groove is narrow and deep. Syn purines alternating with anti pyrimidines usually form Z. 5. Certain DNA sequences adopt unusual structures 4 or more adenosine sequentially in one strand form bends. Palindrome(回文) is common. Inverted repeats(反向重复) is palindrome of two strands. It’s self-complementary so can form hairpin(发夹) or cruciform(十字) structures. Mirror repeat is palindrome on one strand. Some unusual DNAs have 3 or 4 strands, often occurring where important events in DNA metabolism are initiated or regulated. The atoms participating in the hydrogen bonding are N-7, O6 and N6 of purines, and they are called Hoogsteen positions, forming non-Watson-Crick pairing Hoogsteen pairing. It allow the formation of triplex(三螺旋) DNAs. Triplexes are most stable at low pH because C≡G•C+ requires a protonated cytosine. They are also stable with strands only of pyrimidines or purines. Tetraplex/quadruplex(四螺旋) occurs when there is a high proportion guanosines. G tetraplex is stable and antiparallel is alternating up and down. H-DNA has a mirror repeat and forms a partly triple helix of two pyrimidines strands and a purines strand, producing a sharp bend. 6. Messenger RNAs code for polypeptide chains Transcription is from DNA to mRNA. Monocistronic(单作用子) is mRNA carrying the code for only one polypeptide while polycistronic(多作用子) for many. Noncoding RNA has sequences regulating protein synthesis. Besides there are transfer RNAs linked to amino acids and ribosomal RNAs in ribosomes. Some RNAs are ribozymes(RNA 构成酶). 7. Many RNAs have more complex three-dimensional structures mRNA tends to be a right-handed helical by base-stacking interactions. The purine-purine interaction is strong so pyrimidine between two purines is often displaced. Base pairing G and U is common in RNA. When there are complementary sequences, formed double-stranded structure is A rather than B. Mismatched bases form bulges(凸出) or internal loops(内环). 8.3 Nucleic acid chemistry 1. Double-helical DNA and RNA can be denatured(变性) When exposed to extreme pH or temperatures above 80°C DNA loses viscosity(黏性), because the hydrogen bonds are broken. Anneal(退火) can cause rewinding(重绕). Finding another half randomly is slower than forming of base pairs. Hypochromic(浅色) effect is the decreased absorption of UV caused by nucleic acids strands pairing. Hyperchromic(深色) effect is opposite. So this can be used to detect denaturing. For not known reasons, RNA duplexes are more stable than DNA. Each species has denaturation temperature or called melting point(tm), which can be used to estimate the base composition. Strand separation often occurs where A=T are rich. 2. Nucleic acids from different species can form hybrids(杂合子) Hybridization(杂交) techniques can be used to detect similar DNA sequences reflecting evolutionary heritage(遗传). 3. Nucleotides and nucleic acids undergo nonenzymatic transformations Some bases undergo deamination(脱氨基作用) losing exocyclic(环外) amino groups, like C to U. U can be removed by repair system, so T makes long-term storage of genetic information possible. Hydrolysis of N-β-glycosyl bond between base and pentose occurs more often for purines than pyrimidines forming apurinic(无嘌呤) acids. UV induces adjacent pyrimidine bases(often T) forming cyclobutane(环丁烷) or 6-4 photoproduct pyrimidine dimers. Ionizing radiation(X and γ rays) can break the backbone. DNA can be damaged by chemicals such as deaminating agents like HNO2 and alkylating agents(烷化剂). Bisulfite(亚硫 酸盐) has similar effects to nitrous acid(亚硝酸). Oxidative damage is perhaps the most important mutagenic(诱变的) alterations. Hydroxyl radicals(基) are important causing oxidation of deoxyribose and base and strand breaks. Catalase(过氧化氢酶) and superoxide dismutase(过氧化物歧酶) can convert reactive oxygen species to harmless products. DNA is the only macromolecule with biochemical repair systems. 4. Some bases of DNA are methylated(甲基化) A and C are more often. Methylases(甲基酶) use S-adenosylmethionine(腺苷甲硫氨酸) as methyl donor. Methylation can serve as part of defense mechanism(restriction-modification system) helping the cell distinguish self-DNA marked with methyl and destroying foreign DNA without methyl, or be a component of system repairing mismatched base pairs by methylating adenosine in GATC to N6-methyladenosine(甲基腺苷). It can also suppress(抑制) transposons(转座). 5-methylcytosine in alternating CpG increases the tendency for Z form. 5. The sequences of long DNA strands can be determined Electrophoretic(电泳) methods can separate DNA strands of different sizes. Polyacrylamide(聚丙烯酰胺) is often used as gel matrix for short DNA and agarose for longer. In both Sanger and Maxam-Gilbert sequencing the general principle is to reduce DNA to four sets of labeled(标签) fragments. The lengths show the positions. Primer and dideoxynucleotides are used. 6. The chemical synthesis of DNA has been automated The synthesis is carried out with the growing strand attached to a solid support. 8.4 Other functions of nucleotides 1. Nucleotides carry chemical energy in cells The phosphate may be linked to additional phosphates. From the ribose the phosphates are α, β and γ. ATP is adenosine 5’-triphosphate and can carry energy at phosphoanhydrides. Nucleoside triphosphates also serve as activated precursors(前导) of DNA and RNA synthesis. 2. Adenine nucleotides are components of many enzyme cofactors The binding energy used in catalysis and in stabilizing the initial enzyme-substrate complex is important. The nucleotide of β-ketoacyl-CoA transferase(转移酶) is a binding helping pull the substrate acetoacetyl-CoA(乙酰乙酰辅酶 A) into the active. Nucleotide-binding fold is common in many enzymes binding ATP and nucleotide cofactors. 3. Some Nucleotides are regulatory molecules First messengers often lead to the production of second messengers(often nucleotide). Adenosine 3’,5’-cyclic monophosphate(cyclic AMP/cAMP) is common. cGMP also has functions. ppGpp is in bacteria to slowdown protein synthesis during amino acid starvation by inhibiting the synthesis of rRNA and tRNA. Chapter 9 DNA-based information technologies 9.1 DNA cloning: the basics Five general procedures for recombinant( 重 组 ) DNA technology/genetic engineering: cutting DNA with sequence-specific/restriction endonucleases(限制性内切酶), selecting cloning vectors(载体), DNA recombination, moving recombinant DNA into host cells, selecting or identifying host cells containing recombinant DNA. 1. Restriction endonucleases and DNA ligase(连接酶) yield recombinant DNA Restricted DNA can be cleaved by restriction endonucleases. Self-DNA is protected by methylation as part of restriction-modification system. In restriction endonucleases, types I and III are multisubunit complexes containing endonuclease and methylase activities. They move along DNA with the help of ATP. Type II requires no ATP and cleave the DNA within the recognition sequence(I and III are some pairs away from recognition site). The recognition sequences are usually 4 to 6 bp and palindromic(回文). Cleaving can form sticky ends(黏性末端) or blunt ends(钝端). Inserted DNA to vectors is linkers, and those with multiple recognition sequences are polylinkers. 2. Cloning vectors allow amplification of inserted DNA segments (1) Plasmids(质粒) are circular DNA. Transformation(转化) can make them into E.coli. Rapidly shifting temperature or electroporation(电穿孔) can help. Selectable marker is used to distinguish the cells. As plasmid size increases, transformation becomes less successful. Shuttle(穿梭) vectors are plasmids able to be used in different species. (2) Bacteriophages(噬菌体) can be used for larger DNA segments by in vitro(体外) packaging. The size restriction for inserted DNA can ensure packaging of recombinant DNA only. (3) Bacterial artificial chromosomes(BACs) are plasmids designed for the cloning of very long DNA segments. Electroporation and mutated bacteria are used for transformation. (4) Yeast artificial chromosomes(YACs) are for yeasts and their stability increases with size. DNA is prepared by pulsed field gel electrophoresis(脉冲场凝胶电泳). 3. Specific DNA sequences are detectable by hybridization(杂交) Probes(探针) are labeled DNA or RNA fragments complementary to the DNA being sought. 4. Expression of cloned genes produces large quantities of protein Regulatory sequences need to be inserted into vectors to form expression vectors. Overexpressed proteins can kill cells. 5. Alterations in cloned genes produce modified proteins Site-directed mutagenesis(点突变) is powerful to research proteins. Oligonucleotide-directed mutagenesis can create a specific DNA sequence change. Slightly mismatched duplex recombinant plasmid is used to transform bacteria. Fused(融合) gene can make fusion protein. 9.2 From genes to genomes 1. DNA libraries provide specialized catalogs of genetic information The largest types of NDA library has genomic library. Contig(重叠群) is a long contiguous segment of a genome catalogued by overlaps. Sequence-tagged site(STS) can provide landmarks for sequencing. mRNA can be used to make cDNA(complementary DNA) library. Expressed sequence tag(EST) can be made to provide markers for expressed genes. Two useful markers are green fluorescent(荧光) protein(GFP) gene and epitope tags(抗原决定基) gene. 2. The polymerase chain reaction amplifies specific DNA sequences In PCR, two synthetic oligonucleotides are prepared as primers(引物). Taq polymerase is used because it’s heat-stable. 3. Genome sequences provide the ultimate genetic libraries Shotgun approach sequences random segments and then assembles them by overlaps. Our genes are 30000 to 35000. Only 1.1% to 1.4% encode proteins. Single nucleotide polymorphisms(SNPs, 单核苷酸多态性) make us different. 9.3 From genomes to proteomes Phenotypic(表型) function, cellular function and molecular function are three levels of protein function. To research proteins, we can sequence and compare structures with known genes and proteins, find when and where a gene is expressed and invest the protein-protein interactions. 1. Sequence or structural relationships provide information on protein function Comparative genomics shows orthologs(种间同源) and paralogs(种内同源). Synteny(同线性) is conserved gene order providing orthologous relationship between genes in the related segments. Sequences associated with structural motifs suggest functions. 2. Cellular expression patterns can reveal the cellular function of a gene (1) Two-dimensional gel electrophoresis can display protein spots. Mass spectrometry is used to sequence each protein. (2) DNA microarrays( 微 点 阵 )/chips puts PCR amplified model DNA segments on a solid surface or uses photolithography(光刻法) to synthesize DNA on the solid surface, each gene separated. (3) Protein chips uses antibodies to immobilize(固定) proteins. 3. Detection of protein-protein interactions helps to define cellular and molecular function Two genes always appearing together suggest the proteins may be functionally related. We also can immunoprecipitate(免疫沉淀) the protein by antibody binding to the epitope. Identification of the associated proteins reveals some protein-protein interactions. Histidine tag is a string of six His as a common tag. A poly-His sequence binds tightly to nickel(Ni). Gal4 protein activates transcription of certain genes in yeast. Yeast two-hybrid analysis fuses the two domains of Gal4 to different protein and test reporter gene’s expression to determine whether there are protein-protein interactions. 9.4 Genome alterations and new products of biotechnology 1. A bacterial plant parasite(寄生物) aids cloning in plants Agrobacterium(土壤杆菌) containing Ti plasmid can invade plants. Ti plasmid has T DNA, encoding plant growth hormones and opines serving as food source for the bacterium. After removing T DNA, it can be used to genetic engineering on plants. It’s faster than traditional plant breeding. 2. Manipulation(操作) of animal cell genomes provides information on chromosome structure and gene expression Cells derived from tissues under appropriate tissue culture conditions can maintain differentiated properties. Microinjection(微注射) is useful for transformation. Liposomes(脂粒体) or viral vectors are efficient. Viral vectors keep the ability to enter the cells but lack the ψ sequence required for packaging and the genes for RNA producing. Because DNA is integrated(整合) randomly to the genome, the cellular functions may be affected. 3. New technologies promise to expedite(加快) the discovery of new pharmaceuticals(制药) Identifying enzyme or receptor and discovering inhibitor is important to treatment. Another objective is to identify new agents treating diseases caused by pathogens(病原体). The enzyme essential to the pathogen cell’s survival, well-conserved among a wide range of pathogens and absent or significantly different in humans is ideal target. 4. Recombinant DNA technology yields new products and challenges Chapter 10 Lipids Lipids(脂质) are compounds(化合物) whose common and defining feature is insolubility(不溶) with lower gravities. Functions: (1) Principal ( 主 要 的 )Stored forms of energy-fats and oils. (2) Major structural elements of membranes-phospholipids( 磷 脂 ) and sterols( 固 醇 ). (3) Enzyme cofactors( 辅 因 子 ), electron carriers, light absorbing pigments(色素), hydrophobic anchors(位点) for proteins, chaperones(用以帮助膜蛋白折叠), emulsifying(乳化) agents in the digestive tract(消化道), hormones(激素), intracellular messengers. 10.1 Storage lipids Common forms of fats and oils to store energy are derivatives of fatty acids(脂肪酸衍生物)- low oxidation(氧化) state. Cellular oxidation of fatty acids to CO2 and H2O is exergonic(供能). 1. Fatty acids are hydrocarbon(CH) derivatives They are carboxylic(羧酸), 4 to 36 carbons long, usually even(偶数) because of the synthesis involving acetate(乙酸盐) condensation. They are saturated(饱和) or monounsaturated(单不饱和), some are unbranched and some are with hydroxyl group(羟基) or methyl-group(甲基) branches. Free fatty acids circulate in the blood bound noncovalently to a protein carrier-serumalbumin(血清蛋白), but mostly are present as carboxylic acid derivatives such as esters(酯) or amides(酰胺), less soluble for lacking free carboxylate group. Nomenclature(命名): chain length:double bonds(Δ,在右上角写 position of double bond, position of double bond…). The carboxyl carbon is 1. Systematic name: n-cis/trans-number-Dodecanoic( 十 二 )/Tetradecanoic( 十 四 )/Hexadecanoic( 十 六 )/Octadecanoic( 十 八 )/Eicosanoic( 二 十 )/Tetracosanoic( 二 十 四 )/Hexadecenoic( 十 六 烯 )/Octadecenoic( 十 八 烯)/Octadecadienoic(十八二烯)/Octadecatrienoic(十八三烯)/Icosatetraenoic(二十四烯) acid, n means normal unbranched. Double bond is usually at 9 and 10 in monounsaturated ones. In polyunsaturated(聚不饱和) ones are at 12 and 15 (Arachidonic acid(花生烯酸) is an exception) and are usually not conjugated(共轭) but separated by a methylene group(亚甲 基), usually cis configuration(顺式). Trans(反式) are produced by fermentation(发酵) in the rumen(瘤胃) of dairy(反刍) animals or the hydrogenation(氢化) of fish, vegetable oils, which increase LDL(bad cholesterol(胆固醇)) and decrease HDL(good cholesterol). Physical properties: longer chain and fewer double bonds mean lower solubility. The carboxylic acid group is polar. The melting points increase from unsaturated to saturated ones(oily to waxy(蜡)). 2. Triacylglycerols(甘油三酸酯) are fatty acid esters of glycerol(甘油) They are the simplest constructure also referred to as triglyceride, fat, neutral fat, and are composed of three fatty acids each in ester linkage with a glycerol. They are nonpolar,hydrophobic molecules and insoluble in water. Simple triacylglycerols are the ones that the fatty acids are the same such as tristearin(三硬脂酸甘油酯), tripalmitin(三棕榈酸甘油酯) and triolein(三 油酸甘油酯). 3. Triacylglycerols provide stored energy and insulation(绝缘) In aqueous cytosol(胞液质) they form a separate and are mainly stored in adipocytes(脂肪细胞) as fat droplets and plants seeds as oils, providing energy and biosynthetic precursors during seed germination(发芽). There are lipases(脂肪酶) catalyzing(催化) the hydrolysis(水解) of triacylglycerols. Advantages to polysaccharides(多糖) such as glycogen(糖原) and starch(淀粉): more reduced carbon atoms-oxidation yields(给) more energy, unhydrated-avoid extra water to carry. But slow. Fat tissue is under the skin in the abdominal cavity(腹腔) and mammary glands(乳腺). Triacylglycerols can also be insulation against low temperatures and offer buoyancy(浮力) of some sea animals. 4. Many foods contain triacylglycerols Unsaturated ones can be converted into saturated ones by catalytic hydrogenation converting other double bonds to trans ones. When lipid-rich food are exposed too long in the air they may spoil(变质) and become rancid(酸败) producing aldehydes(醛) and shorter chain carboxylic acids which have higher volatility(挥发). 5. Waxes serve as energy stores and water repellents(防水物质) Waxes are esters of fatty acids with long-chain alcohols(醇) with higher melting point, water-repellent properties and firm consistency(硬度). They can protect hair and skin and keep it pliable(柔顺), lubricated(润滑) and waterproof(防水), prevents excessive evaporation(蒸发) of water and protects against parasites(寄生生物). Waxes are widely used. 10.2 Structural lipids in membranes Phospholipids and glycolipids are two kinds. Membrane lipids are amphipathic(两亲). There are five general types of membrane lipids: glycerophospholipids( 甘 油 磷 酸 脂 ), galactolipids( 半 乳 糖 脂 ) and sulfolipids( 硫 脂 ), archaebacterial tetraether(四醚) lipids, sphingolipids(鞘脂) and sterols(固醇). 1. Glycerophospholipids are derivatives of phosphatidic acid They are also called phosphoglycerides(磷酸甘油酯). Two fatty acids(usually a C16 or C18 saturated one at C-1 and a C18 or C20 unsaturated one at C-2) are attached to the Cs of glycerol(甘油) by ester linkage and another C a negative charged phosphate by phosphodiester(磷酸二酯) linkage. The charge of OH is important to surface properties of membranes. 2. Some phospholipids have ether-linked fatty acids Ether lipids like plasmalogens(缩醛磷脂) have ether linkage rather than ester linkage. Platelet(血小板)-activating factor stimulating platelet aggregation and the release of serotonin(5-羟色胺). It’s also important to inflammation(炎症) and allergic(过敏) response. 3. Chloroplasts(叶绿体) contain galactolipids and sulfolipids In galactolipids one or two galactose residues are connected by a glycosidic linkage to C-3 of glycerol. They are probably the most abundant membrane lipids. The acyl(酰基) groups are always derived from linoleic acid. In sulfolipids a sulfonated glucose residue is joined to the glycerol in glycosidic linkage. 4. Archaebacteria contain unique membrane lipids They are ether bonds because they are more stable to hydrolysis at low pH and high temperature. Their general name is glycerol dialkyl(二烷基) glycerol tetraethers(四醚) (GDGTs). The central carbon is R rather than S of the other kingdoms. 5. Sphingolipids are derivatives of sphingosine(鞘氨醇) They replace glycerol for 4-sphingosine or its derivative. Acyl is linked to the NH of C-2 forming ceramide(神经酰胺), which is the structural parent. There are 3 subclasses: sphingomyelins(神经鞘磷脂), glycosphingolipids(糖鞘脂) and gangliosides(神经节苷脂). Sphingomyelins have phosphocholine(胆碱磷酸) or phosphoethanolamine(磷酸乙醇胺) as polar head. They are important in myelin(髓鞘质). Glycosphingolipids have one or more sugars as polar head. Cerebrosides(脑苷脂) have a single sugar, in neural tissue often galactose and in nonneural tissues often glucose. Globosides(红细胞糖苷脂) are neutral with more sugars and often called neutral glycolipids. Gangliosides have oligosaccharides as polar head groups and some Neu5Ac(sialic acid) at the termini, which gives negative charge. Gangliosides with one, two, three or four sialic acids are GM, GD, GT or GQ. 6. Sphingolipids at cell surfaces are sites of biological recognition The carbohydrate of certain sphingolipids defines blood groups. Gangliosides are on the outer surface of cells, presenting recognition points. 7. Phospholipids and sphingolipids are degraded in lysosomes Phospholipases of the A type remove one fatty acid, and lysophospholipases(磷脂酶 B) remove another. 8. Sterols have four fused carbon rings They are synthesized from isoprene(异戊二烯) subunits. Three rings have six Cs and one with five. The steroid nucleus is almost planar and rigid. Cholesterol(胆固醇) is amphipathic. Stigmasterol(豆甾醇) in plants and ergosterol(麦角固醇) in fungi are similar. Steroid hormones are biological signals regulating gene expression. Bile acids(胆汁酸) act as detergents in the intestine. 10.3 Lipids as signals, cofactors and pigments They can serve as hormones, messengers, enzyme cofactors in electron-transfer reactions or the transfer of sugar in glycosylation(糖基化) reactions. Pigments(色素) are lipids with conjugated double bonds. 1. Phosphatidylinositols(磷脂酰肌醇) and sphingosine(鞘氨醇) derivatives act as intracellular signals Phosphatidylinositol 4,5-bisphosphate on the inner face of plasma membranes serves as a specific binding site for proteins during exocytosis(胞吐). It can also serve as reservoir(储藏) of messenger molecules. Enzymes remove phospholipids head and activate the signals. Phospholipase C hydrolyzes the bond between glycerol and phosphate in phosphatidylinositol 4,5-bisphosphate releasing diacylglycerol and inositol(肌醇) 1,4,5-trisphosphate(IP3). IP3 triggers release of Ca2+ and the combination of diacylglycerol and Ca2+ activates protein kinase C which can transfer phosphoryl from ATP to target proteins. Inositol phospholipids also serve as nucleation(形成核) points. Membrane sphingolipids also serve as intracellular messengers. 2. Eicosanoids(二十酸) carry messages to nearby cells They are paracrine(旁分泌) hormones. They are derived from arachidonic acid(20:4(Δ5,8,11,14)) (花生四烯酸). There are 3 classes: prostaglandins(前列腺素), thromboxanes(凝血氧烷) and leukotrienes(白三烯). Prostaglandins(PG) have a 5C ring. There are 2 groups: PGE for ether-soluble and PGF for phosphate buffer-soluble. PGs regulate the synthesis of cAMP. Some PGs stimulate contraction of the smooth muscle of uterus(子宫). Some affect blood flow, the wake-sleep cycle and the responsiveness of some tissues to epinephrine(肾上腺素) and glucagon(高血糖素). Some elevate temperature and cause inflammation and pain. Thromboxanes have a six-membered ring containing an ether. They act in blood clots. Leukotrienes are in leukocytes(白血球) containing three conjugated double bonds. They are signals. Overproduction causes asthmatic(气喘) attacks. 3. Steroid hormones carry messages between tissues Steroids(类固醇) are oxidized derivatives of sterols. They lack the alkyl chain attached to ring D. Some important kinds are sex hormones and adrenal cortex(肾上腺皮质) hormones cortisol(皮质醇) and aldosterone(醛甾酮). Prednisone(泼尼松) and prednisolone(氢化泼尼松) inhibit arachidonate(花生四烯酸酯) release and the synthesis of PGs, thromboxanes and leukotrienes. 4. Plants use phosphatidylinositols, steroids, and eicosanoidlike compounds in signaling Brassinolide(布拉西诺内酯) and the related group of brassinosteroids are growth regulators. Jasmonate(茉莉酮酸酯) is a signal triggering the plant’s defenses. Its methyl ester gives fragrance(芬芳) of jasmine oil. 5. Vitamins A and D are hormone precursors Vitamin D3(cholecalciferol 胆 钙 化 固 醇 ) forms in the skin from 7-dehydrocholesterol by UV. It’s converted to 1,25-dihydroxycholecalciferol regulating calcium uptake in the intestine and calcium levels in kidney and bone. Vitamin D2(ergocalciferol 麦角骨化醇) is similar. Vitamin A(retinol 瑞叮醇)’s derivative retinoic acid regulates the development of epithelial(上皮) tissue. Its derivative retinal(视黄醛) is the pigment initiating the response of retina(视网膜) rod(视杆) and cone(视锥) cells to light. 6. Vitamins E and K and the lipid quinines(奎宁) are oxidation-reduction cofactors Vitamin E is tocopherols(生育酚) containing a aromatic(芳香) ring and a isoprenoid(类异戊二烯) side chain. They are antioxidants(抗氧化剂) because of the aromatic ring. Vitamin K has aromatic ring participating in the formation of active prothrombin(凝血酶原). Prothrombin converts fibrinogen(纤维蛋白原) to fibrin(纤维蛋白). Warfarin(丙酮苄羟香豆素) inhibits the formation of active prothrombin. It’s used to kill mice and treat coronary thrombosis(冠状动脉血栓). Ubiquinone(泛醌/辅酶 Q) and plastoquinone(叶绿醌) are isoprenoids function as lipophilic(亲油) electron carriers. 7. Dolichols(长醇) activate sugar precursors for biosynthesis They are isoprenoid alcohols activating sugar adding to proteins and lipids. They have strong hydrophobic interactions with membrane lipids anchoring the attached sugars and participating in sugar-transfer reactions. 10.4 Working with lipids Nonpolar solvents are used to separate lipids according to polarity or solubility differences. 1. Lipid extraction requires organic solvents Polar organic solvents are effective by reducing the hydrophobic interactions among lipid molecules and weakening the hydrogen bonds and electrostatic interactions binding membrane lipids to membrane proteins. A mixture of chloroform(氯仿), methanol(甲醇) and water(V1:2:0.8) is common. After extraction, more water is added to make the mixture to two phases and the lipids are in the chloroform layer, polar molecules in methanol/water layer. 2. Adsorption(吸附) chromatography separates lipids of different polarity Insoluble polar material like silica gel(硅胶) is used. The polar lipids bind. Acetone(丙酮) is used to wash uncharged polar ones, and methanol(甲醇) for very polar or charged ones. Thin-layer(薄层) chromatography is similar. 3. Gas-liquid chromatography resolves mixtures of volatile(挥发的) lipid derivatives Inert(惰性) gas is used. First the lipids are heated in a methanol/HCL or NaOH mixture to convert glycerol ester-linkage to methyl ester-linkage. Less soluble lipids emerge first from the column. 4. Specific hydrolysis aids in determination of lipid structure Enzymes specifically hydrolyzing certain lipids are useful. 5. Mass spectrometry reveals complete lipid structure It can establish exact length of the chain and the position of double bonds. Chapter 11 Biological membranes and transport Membranes define the boundaries and regulate the molecular traffic across that. 11.1 The composition and architecture of membranes 1. Each type of membrane has characteristic lipids and proteins 2. All biological membranes share some fundamental properties 3. A lipid bilayer is the basic structural element of membranes 4. Peripheral membrane proteins are easily solubilized 5. Many membrane proteins span the lipid bilayer 6. Integral proteins are held in the membrane by hydrophobic interactions with lipids 7. The topology of an integral membrane protein can be predicted from its sequence 8. Covalently attached lipids anchor some membrane proteins 11.2 Membrane dynamics 1. Acyl groups in the bilayer interior are ordered to varying degrees 2. Transbilayer movement of lipids requires catalysis 3. Lipids and proteins diffuse laterally in the bilayer 4. Sphingolipids and cholesterol cluster together in membrane rafts 5. Caveolins define a special class of membrane rafts 6. Certain integral proteins mediate cell-cell interactions and adhesion 7. Membrane fusion is central to many biological processes 11.3 Solute transport across membranes 1. Passive transport is facilitated by membrane proteins 2. Transporters can be grouped into superfamilies based on their structures 3. The glucose transporter of erythrocytes mediates passive transport 4. The chloride-bicarbonate exchanger catalyzes electroneutral cotransport of anions across the plasma membrane 5. Active transport results in solute movement against a concentration or electrochemical gradient 6. P-type ATPases undergo phosphorylation during their catalytic cycles 7. P-type Ca2+ pumps maintain a low concentration of calcium in the cytosol 8. F-type ATPases are reversible, ATP-driven proton pumps 9. ABC transporters use ATP to drive the active transport of a wide variety of substrates 10. Ion Gradients provide the energy for secondary active transport 11. Aquaporins form hydrophilic transmembrane channels for the passage of water 12. Ion-selective channels allow rapid movement of ions across membranes 13. Ion-channel function is measured electrically 14. The structure of a K+ channel reveals the basis for its specificity 15. The neuronal Na+ channel is a voltage-gated ion channel 16. The acetylcholine receptor is a ligand-gated ion channel Chapter 12 Biosignaling 1. 12.1 Molecular mechanisms of signal transduction 1. 12.2 Gated ion channels 1. 12.3 Receptor enzymes 1. 12.4 G protein-coupled receptors and second messengers 1. 12.5 Multivalent scaffold proteins and membrane rafts 1. 12.6 Signaling in microorganisms and plants 1. 12.7 Sensory transduction in vision, olfaction, and gustation 1. 12.8 Regulation of transcription by steroid hormones 1. 12.9 Regulation of the cell cycle by protein kinases 1. 12.10 Oncogenes, tumor suppressor genes, and programmed cell death 1. Chapter 13 Principles of bioenergetics 1. 13.1 Bioenergetics and thermodynamics 1. 13.2 Phosphoryl group transfers and ATP 1. 13.3 Biological oxidation-reduction reactions 1. Chapter 14 Glycolysis, Gluconeogenesis, and the pentose phosphate pathway 1. 14.1 Glycolysis 1. 14.2 Feeder pathways for glycolysis 1. 14.3 Fates of pyruvate under anaerobic conditions: fermentation 1. 14.4 Gluconeogenesis 1. 14.5 Pentose phosphate pathway of glucose oxidation 1.