12.13 residual analysis in multiple regression (optional)
advertisement
")
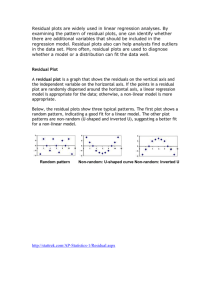
12.13 Residual Analysis in Multiple Regression (Optional) Although Excel and MegaStat are emphasized in Business Statistics in Practice, Second Canadian Edition, some examples in the additional material on Connect can only be demonstrated using other programs, such as MINITAB, SPSS, and SAS. Please consult the user guides for these programs for instructions on their use. 12.13 RESIDUAL ANALYSIS IN MULTIPLE REGRESSION (OPTIONAL) In Section 11.10, we showed how to use residual analysis to check the regression assumptions for a simple linear regression model. In multiple regression, we proceed similarly. Specifically, for a multiple regression model we plot the residuals given by the model against (1) values of each independent variable, (2) predicted values of the dependent variable, and (3) the time order in which the data have been observed (if the regression data are time series data). A fanning-out pattern on a residual plot indicates an increasing error variance; a funneling-in pattern indicates a decreasing error variance. Both violate the constant-variance assumption. A curved pattern on a residual plot indicates that the functional form of the regression model is incorrect. If the regression data are time series data, a cyclical pattern on the residual plot versus time suggests positive autocorrelation, while an alternating pattern suggests negative autocorrelation. Both violate the independence assumption. On the other hand, if all residual plots have (at least approximately) a horizontal band appearance, then it is reasonable to believe that the constant-variance, correct functional form, and independence assumptions approximately hold. To check the normality assumption, we can construct a histogram, stem-and-leaf display, and normal plot of the residuals. The histogram and stem-and-leaf display should look bell-shaped and symmetric about 0; the normal plot should have a straight-line appearance. To illustrate these ideas, consider the sales territory performance data in Table 12.2 (page 422). Figure 12.7 (page 430) gives the MegaStat output of a regression analysis of these data using the model y 5 b0 1 b1x1 1 b2 x2 1 b3 x3 1 b4 x4 1 b5 x5 1 e. The least squares point estimates on the output give the prediction equation ŷ 5 21,113.7879 1 3.6121x1 1 0.0421x2 1 0.1289x3 1 256.9555x4 1 324.5334x5 . Using this prediction equation, we can calculate the predicted sales values and residuals given on the MegaStat output of Figure 12.50. For example, observation 10 on this output corresponds to a sales representative for whom x1 5 105.69, x2 5 42,053.24, x3 5 5,673.11, x4 5 8.85, and x5 5 0.31. If we insert these values into the prediction equation, we obtain a predicted sales value of ŷ10 5 4,143.597. Since the actual sales for the sales representative are y10 5 4,876.370, the residual e10 equals the difference between y10 5 4,876.370 and ŷ10 5 4,143.597, which is 732.773. The normal plot of the residuals in Figure 12.51(a) has a straight-line appearance. The plot of the residuals versus predicted sales in Figure 12.51(b) has a horizontal band appearance, as do the plots of the residuals versus the independent variables (the plot versus x3, advertising, is shown in Figure 12.51(c)). We conclude that the regression assumptions approximately hold for the sales territory performance model (note that because the data are cross-sectional, a residual plot versus time is not appropriate). 1 2 Chapter 12 Multiple Regression and Model Building FIGURE 12.50 MegaStat Output of the Sales Territory FIGURE 12.51 MegaStat Residual Plots for the Sales Territory Performance Model Residuals Predicted Residual 3,504.990 3,901.180 2,774.866 4,911.872 5,415.196 2,026.090 5,126.127 3,106.925 6,055.297 4,143.597 2,503.165 1,827.065 2,478.083 2,351.344 4,797.688 2,904.099 3,362.660 2,907.376 3,625.026 4,056.443 1,409.835 2,494.101 1,617.561 4,574.903 2,488.700 164.890 2427.230 2479.766 2236.312 710.764 108.850 294.467 260.525 464.153 732.773 234.895 706.245 269.973 213.964 2210.738 2174.859 273.260 2106.596 2360.826 2602.823 331.615 2458.351 239.561 2407.463 311.270 (a) Normal plot of the residuals 1,000.000 500.000 Residual Sales 3,669.880 3,473.950 2,295.100 4,675.560 6,125.960 2,134.940 5,031.660 3,367.450 6,519.450 4,876.370 2,468.270 2,533.310 2,408.110 2,337.380 4,586.950 2,729.240 3,289.400 2,800.780 3,264.200 3,453.620 1,741.450 2,035.750 1,578.000 4,167.440 2,799.970 0.000 ⫺500.000 ⫺1,000.000 ⫺3.0 ⫺2.0 ⫺1.0 0.0 1.0 2.0 3.0 Normal Score (b) Plot of the residuals versus predicted sales Residual (gridlines ⫽ std. error) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 860.464 430.232 0.000 ⫺430.232 ⫺860.464 0 2,000 4,000 6,000 8,000 Predicted (c) Plot of the residuals versus advertising Residual (gridlines ⫽ std. error) Observation Performance Model 860.464 430.232 0.000 ⫺430.232 ⫺860.464 0.0 5,000.0 10,000.0 15,000.0 Adver To conclude this section, we consider the Durbin–Watson test for first-order autocorrelation. This test is carried out for a multiple regression model exactly as it is for a simple linear regression model (see Section 11.10), except that we consider k, the number of independent variables used by the model, when looking up the critical values dL,a and dU,a. For example, Figure 12.52 gives n 5 16 weekly values of Folio Bookstore sales (y), Folio’s advertising expenditure (x1), and competitors’ advertising expenditure (x2). The Durbin–Watson statistic for the model y 5 b0 1 b1x1 1 b2x2 1 e n k52 dL,0.05 dU,0.05 15 16 17 18 0.95 0.98 1.02 1.05 1.54 1.54 1.54 1.53 is d 5 1.63. If we set a equal to 0.05, then we use Table A.12—a portion of which is shown in the page margin. Because n 5 16 and k 5 2, the appropriate critical values for a test for first-order positive autocorrelation are dL,0.05 5 0.98 and dU,0.05 5 1.54. Because d 5 1.63 is greater than dU,0.05 5 1.54, we conclude that there is no first-order positive autocorrelation. The Durbin–Watson test carried out in Figure 12.52 indicates that this autocorrelation does exist for the model relating y to x1. Therefore, adding x2 to this model seems to have removed the autocorrelation. 12.13 Residual Analysis in Multiple Regression (Optional) FIGURE 3 12.52 Folio Bookstore Sales and Advertising Data, and Residual Analysis (a) The data and the MegaStat output of the residuals from a simple linear regression relating Folio’s sales to Folio’s advertising expenditure Observation 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Adver 18 20 20 25 28 29 29 28 30 31 34 35 36 38 41 45 Compadv 10 10 15 15 15 20 20 25 35 35 35 30 30 25 20 20 Sales 22 27 23 31 45 47 45 42 37 39 45 52 57 62 73 84 Predicted Residual 18.7 3.3 23.0 4.0 23.0 20.0 33.9 22.9 40.4 4.6 42.6 4.4 42.6 2.4 40.4 1.6 44.7 27.7 46.9 27.9 53.4 28.4 55.6 23.6 57.8 20.8 62.1 20.1 68.6 4.4 77.3 6.7 Durbin–Watson 5 0.65 (b) MegaStat output of a plot of the residuals versus time Residual (gridlines ⫽ std. error) 10.1 5.0 0.0 ⫺5.0 ⫺10.1 0 5 10 15 20 Observation Exercises for Section 12.13 CONCEPTS 12.63 Discuss how to use the residuals to check the regression assumptions for a multiple regression model. 12.64 Discuss how to carry out the Durbin–Watson test for a multiple regression model. METHODS AND APPLICATIONS 12.65 THE HOSPITAL LABOUR NEEDS CASE Consider the hospital labour needs data in Table 12.5 (page 424). Figure 12.53 gives residual plots that are obtained when we perform a regression analysis of these data by using the model y 5 b0 1 b1x1 1 b2x2 1 b3x3 1 e. a. Interpret the normal plot of the residuals. b. Interpret the residual plots versus predicted labour hours, BedDays (x2), and Length (x3). Note: The first two of these plots, as well as the plot versus Xray (x1) (not shown), indicate that 3 hospitals are substantially larger than the other 13 hospitals. We will discuss the potential influence of these three large hospitals in Section 12.14. 12.66 THE FRESH DETERGENT CASE Recall that Table 12.4 (page 424) gives values for n 5 30 sales periods of demand for Fresh liquid laundry detergent (y), price difference (x4), and advertising expenditure (x3). a. Figure 12.54(a) gives the residual plot versus x3 that is obtained when the regression model relating y to x4 and x3 is used to analyze the Fresh detergent data. Discuss why the residual plot indicates that we should add x23 to the model. b. Figure 12.54(b) gives the residual plot versus time and the Durbin–Watson statistic that are obtained when the regression model relating y to x4, x3, and x23 is used to analyze the Fresh detergent data. Test for positive autocorrelation by setting a equal to 0.05. 4 Chapter 12 Multiple Regression and Model Building FIGURE 12.53 MegaStat and Excel Residual Analysis for the Hospital Labour Needs Model (for Exercise 12.65) (a) MegaStat normal plot of the residuals (b) MegaStat plot of the residuals versus predicted hours Residual (gridlines ⫽ std. error) 600.000 400.000 Residual 200.000 0.000 ⫺200.000 ⫺400.000 ⫺600.000 ⫺800.000 ⫺2.0 ⫺1.5 ⫺1.0 ⫺0.5 0.0 0.5 1.0 1.5 774.320 387.160 0.000 ⫺387.160 ⫺774.320 0 2.0 5,000 Normal Score 1,000 1,000 500 500 5,000.00 10,000.00 15,000.00 20,000.00 ⫺1,000 FIGURE 15,000 20,000 (d) Excel plot of the residuals versus Length Residuals Residuals (c) Excel plot of the residuals versus BedDays 0 0.00 ⫺500 10,000 Predicted 0 0.00 ⫺500 2.00 4.00 ⫺1,000 BedDays 6.00 8.00 10.00 12.00 Length 12.54 MegaStat Output for the Fresh Detergent Data (Exercise 12.66) (b) Output for Exercise 12.66(b) (a) Residual plot for Exercise 12.66(a) 0.664 0.715 0.477 0.238 0.000 ⫺0.238 ⫺0.477 ⫺0.715 Residual (gridlines = std. error) Residual (gridlines ⫽ std. error) Residuals 4.00 5.00 6.00 7.00 8.00 X3 0.443 0.221 0.000 -0.221 -0.443 -0.664 0 5 10 15 20 25 30 35 Observation Durbin - Watson = 1.62 12.67 THE QHIC CASE Consider the quadratic regression model describing the QHIC data. Figure 12.55 shows that the residual plot versus x for this model fans out, indicating that the error term ´ tends to become larger as x increases. To remedy this violation of the constant-variance assumption, we divide all terms in the quadratic model by x. This gives the transformed model y 1 e 5 b0 a b 1 b1 1 b2x 1 . x x x Figure 12.56(a) and (b) gives a regression output and a residual plot versus x for this model. a. Does the residual plot indicate that the constant-variance assumption holds for the transformed model? b. Consider a home worth $220,000. Let m0 represent the mean yearly upkeep expenditure for all homes worth $220,000 and y0 represent the yearly upkeep expenditure for an individual home worth $220,000. The bottom of the output in Figure 12.56(a) says that ŷy220 5 5.635 is a point estimate of m0y220 and a point prediction of y0y220. Multiply this result by 220 to obtain ŷ. Multiply the ends of the confidence interval and prediction interval shown on the output by 220. This will give a 95 percent confidence interval for m0 and a 95 percent prediction interval for y0. 5 12.13 Residual Analysis in Multiple Regression (Optional) FIGURE 12.55 MegaStat Plot of the Quadratic QHIC Model Residuals Versus x Residuals by Value X Residual (gridlines = std. error) 440.692 293.795 146.897 0.000 -146.897 -293.795 -440.692 0 FIGURE 50 100 150 200 Value X 250 300 350 12.56 MegaStat Output of the Transformed QHIC Model for Exercise 12.67 (a) Regression output SUMMARY OUTPUT Regression Statistics Multiple R R Square Adjusted R Square Standard Error Observations 0.7134 0.508939 0.482395 0.793459 40 ANOVA Regression Residual Total df SS MS F Significance F 2 37 39 24.14244 23.29437 47.43681 12.07122 0.629577 19.17353 1.93E-06 Coefficients Standard Error Intercept 1/X Value X 3.408925 253.50053 0.011224 t Stat 1.32082 2.580915 83.19955 20.643039 0.004627 2.425865 P-value Lower 95% Upper 95% Lower 95.0% Upper 95.0% 0.013954 0.524164 0.020266 0.732691 2222.0787 0.001849 6.085158 115.0776 0.020598 0.732691 2222.0787 0.001849 (b) Residual plots Residuals 1/X Residual Plot 2 0 -2 0 0.005 0.01 0.015 0.02 0.025 1/X Residuals Value X Residual Plot 2 0 -2 0 100 200 Value X 300 400 6.085158 115.0776 0.020598