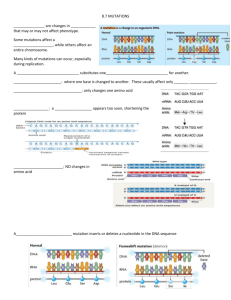
After receiving the samples from ICGC, Libraries were prepared and
advertisement

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Supplementary Files Genomic and epigenomic co-evolution in follicular lymphomas Markus Loeffler1*, Markus Kreuz1*, Andrea Haake2*, Dirk Hasenclever1*, HeikoTrautmann3*, Christian Arnold4, Karsten Winter5, Karoline Koch6, Wolfram Klapper6, René Scholtysik7, Maciej Rosolowski1, Steve Hoffmann8, Ole Ammerpohl2, Monika Szczepanowski6, Dietrich Herrmann3, Ralf Küppers7, Christiane Pott3, Reiner Siebert2 on behalf of the Haematosys-Project * these authors contributed equally to this work 1Institute for Medical Informatics Statistics and Epidemiology, University of Leipzig, Germany; 2Institute of Human Genetics, Christian-Albrechts-University Kiel, Germany; 3Second Medical Department, University Hospital Schleswig-Holstein, Campus Kiel, Kiel, Germany; 4Interdisciplinary Centre for Bioinformatics (IZBI), University of Leipzig, Germany; 5Translational Centre for Regenerative Medicine (TRM-Leipzig); Germany; 6Hematopathology Section, Christian-Albrechts-University, Kiel, Germany; 7Institute of Cell Biology (Cancer Research), Faculty of Medicine, University of Duisburg-Essen, Essen, Germany; 8Transcriptome Bioinformatics, LIFE Research Center for Civilization Diseases, University of Leipzig, Germany; 23 24 25 26 1. Materials Supplementary Table 1a: Summary of patient characteristics All Number of patients Number of samples Number of pair-wise comparisons* Sex Diagnosis: FLI/II FLIIIa FL NOS Age at biopsy (median, range) 27 28 29 30 n=33 (25 pairs; 6 trios; 2 quadruples) n=76 n=55 n=15 (45%) male n=18 (55%) female Core set (Cases with IGHV-sequences) n=19 (17 pairs; 2 trios) n=40 n=23 n=11 (58%) male n=8 (42%) female n=58 n=2 n=16 59 [27-88] n=33 n=1 n=6 54 [27-74] Time between paired probes in months (median, range) IGHV sequencing Number of samples measured 24 [0-101]** 29 [6-101] n=40 (53%) n=40 (100%) Number of pair-wise comparisons* n=23 (42%) n=9 validated using NGS n=23 (100%) n=9 validated using NGS Methylation analysis Number of samples measured n=76 (100%) n=40 (100%) Number of pair-wise comparisons* n=55 (100%) n=23 (100%) NGS analysis Number of samples measured n=69 (91%) n=40 (100%) Number of pair-wise comparisons* n=50 (91%) n=23 (100%) SNP 6.0 analysis Number of samples measured n=35 (46%) n=16 (40%) Number of pair-wise comparisons* n=19 (35%) n=9 (39%) * Patients with 2 samples result in 1 pair-wise comparison, trios in 3 (primary vs. first relapse, primary vs. second relapse and first- vs. second relapse ) and quadruples in 6 pair-wise comparisons. ** 7 pairs with time between samples less than 4 months were excluded from integrated correlation analyses (see section 4F). 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 2. Methods DNA extraction: DNA extraction from tissue was done using the QIAamp DNA Mini Kit (Qiagen, Hilden, Germany) according to the manufacturer´s protocol with minor modifications. For DNA extraction, 15-20 sections à 20 µm of frozen tissue were used. The modifications are as follows: For lysis, 360 µl ATL buffer and 40 µl proteinase K and for precipitation 400 µl AL Buffer and 400 µl ethanol were used. Finally, the DNA was extracted using a total volume of 400 µl AE buffer (200 µl twice). DNA extraction from cells in DMSO was done using the Gentra Puregene Blood Isolation Kit (Qiagen). According to the manufacturer’s instructions elution was done in ddH2O. Quality control of the DNA was performed by agarose gel electrophoresis and showed a discrete band visible at a size 20 kb. Quantification and determination of purity (A260/280 > 1.8) was carried out using a Nanodrop photometer (Thermo Scientific, Braunschweig, Germany). Detection and sequencing of immunoglobulin gene rearrangements: To identify each patient’s clonal immunoglobulin heavy chain (IGHV) gene rearrangement, PCR amplification was performed according to the BIOMED-2 IGH Tube A protocol,1 including six consensus forward primers binding to framework region 1 (VH-FR1) in combination with one consensus reverse primer for all JH-segments. For each reaction, 200 ng DNA from fresh-frozen lymph node specimens were used. Clonal expansion and Sanger sequencing of clonal VDJ rearrangements: Clonal IGH VH-JH PCR products from tumor samples were subcloned into pCR4-TOPO-TA vectors (Life Technologies, Carlsbad, CA) according to the manufacturer´s instructions and expanded in bacterial colonies. We picked and sequenced between 8 and 59 individual colonies per tumor sample (median 36 colonies) via colony-PCR using M13 primers on a 3500 Genetic Analyzer (Life Technologies). Sanger sequencing was conducted with the BigDye Terminator v1.1 Cycle Sequencing Kit (Life Technologies). 454 sequencing of clonal VDJ rearrangements: To perform 454 sequencing analysis of the rearranged IGHV loci, barcoded amplicons were prepared for NGS analysis by adding 5’ linker sequences to IGHV-FR1 gene segment family primers and the consensus JH-primer from the original primer sets published by the BIOMED-2 / EuroClonality consortium1. All amplifications were performed using a two-step PCR in a total volume of 50 µl. The first round PCR using 200 ng genomic DNA, 2.5 U FastStart High Fidelity polymerase (Roche) for 35 cycles was followed by a second amplification step using a 1/500 dilution of the first round PCR product as a template. During this second PCR step, adaptors including multiplex-identifier (MID) and sequencing adapter sequences for emulsion-PCR and 454 sequencing were added to both ends of the amplicons, applying universal-tailed fusion primers for bi-directional sequencing according to the manufacturer´s protocol. Parallel pyrosequencing was performed on a GS-Junior (Roche Diagnostics, Mannheim, Germany) following the manufacturer´s instructions. 1120 to 19311 (median 8600) reads per sample were evaluable. Base calls and quality scores were extracted using the GS-Data-Analysis Software package (Version 2.5; Roche Diagnostics). 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 Sequencing of candidate genes: Four different sequencing approaches were taken: I) To investigate somatic mutations in CREBBP, TNFRSF14, TP53, CDKN2A, EP300, MLL2 and MEF2B, all coding exons of these genes were analyzed. II) For the genes RHOH, PAX5, IRF4, CIITA, REL and PIM1, which are putative targets of the SHM machinery, we analyzed the region 2.5 kb downstream of the transcription start sites (TSS). III) The genes BCL2, BCL6 und MYC are associated with somatic mutations in coding regions as well as aberrant SHM, so that both regions of these three genes were investigated. IV)Finally, for detection of somatic mutations in EZH2 and MYD88, we analyzed ± 75 bp around the known mutational hotspots (Tyr641 in EZH2 and L265P in MYD88). In total, we sequenced 176 regions from 18 genes with high coverage spanning 90,164 bases. The regions analyzed are described in Suppl. Table 2. To achieve a coverage on target of 1000-10000 reads the target regions were enriched using the RainDance Technology (http://raindancetech.com/). RainDance amplification and next generation sequencing was performed as custom service at Atlas Biolabs. Supplementary Table 2: Candidate genes for mutation analysis I) Potential driver mutations - all exons were analyzed gene No. exons chromosome start (Hg19) end (Hg19) CREBBP 31 16 3,775,053 3,930,123 TNFRSF14 7 1 2,487,802 2,495,269 TP53 10 17 7,571,717 7,590,865 CDKN2A 4 9 21,967,748 21,975,124 EP300 31 22 41,488,611 41,576,083 MLL2 54 12 49,412,755 49,449,109 MEF2B 13 E 19 19,256,373 19,303,402 II) Aberrant somatic hypermutation – 2.5 kb from transcription start site were analyzed gene region chromosome start (Hg19) end (Hg19) RHOH approx. 2.5 kb 4 40,198,527 40,201,027 PAX5 approx. 2.5 kb 9 37,031,976 37,034,476 IRF4 approx. 2.5 kb 6 391,752 394,252 CIITA approx. 2.5 kb 12 10,971,055 10,973,555 REL approx. 2.5 kb 2 61,108,752 61,111,252 PIM1 approx. 2.5 kb 6 37,137,922 37,140,422 III) Potential driver mutations and aberrant somatic hypermutation gene region chromosome start (Hg19) end (Hg19) BCL6 approx. 2.5 kb 3 187,439,162 187,463,475 BCL2 approx. 2.5 kb 18 60,790,576 60,987,380 MYC approx. 2.5 kb 8 128,747,765 128,750,815 IV) Known mutation position gene 107 108 109 position chromosome start (Hg19) end (Hg19) MYD88 L265P 3 38,179,966 38,184,514 EZH2 Trr641 7 148,504,461 148,581,443 110 111 112 113 114 115 116 For validation of selected SNVs detected by next generation sequencing in CREBBP, TNFRSF14, TP53, CDKN2A, EP300, MLL2 and MEF2B, Sanger sequencing using an ABI Sequencer 3100 (Applied Biosystems) was performed using the primers presented in Supplementary Table 3. Supplementary Table 3: Primer sequences Gene analyzed region fwd-primer (Sequence 5'-3') rev-primer (Sequence 5'-3') Temp Amplicon Chrom [°C] length (HG19) Start (HG19) End (HG19) EZH2* TYR-641 tttgtccccagtccattttc tggcaattcatttccaatca 55 267 bp 7 148508598 148508873 TNFRSF14 Exon 1 TCCTCTGCTGGAGTTCATCC CATGGGGAAGAGATCTGTGG 60 209 bp 1 2488044 2488252 TNFRSF14 Exon 2 ATCTCCCAATGCCTGTCCT AGAAGGGGGCAAGAGTGTCT 60 202 bp 1 2489135 2489336 TNFRSF14 Exon 3 TAGCTGGTGTCTCCCTGCTT GGCTGTGCTGGCCTCTTAC 60 250 bp 1 2489677 2489926 TNFRSF14 Exon 4 TCCACGTACCCCTCTCAGC GAAATGGGAGGGGTGTCC 60 228 bp 1 2491224 2491451 TNFRSF14 Exon 6 CTCCCTGAGGCTGAGTGAAC GGTGACAGAGCTCCAAGAGG 60 277 bp 1 2493043 2493319 TNFRSF14 Exon 8 AAAATGAACCCGAGAACCTG AGGTGGACAGCCTCTTTCAG 60 267 bp 1 2494514 2494780 CREBBP Exon 13 CATCCTCTGGGGTTGTGAAG CATGAAATGTGCATTCTGGA 55 401 bp 16 3823635 3824033 CREBBP Exon 14 TCCATTTCTGGTAGGGACAGGT GC GGCCCAAAAACAGCAGAGACAG A 60 463 bp 16 3820539 3821001 CREBBP Exon 15 TTGTAGGTTGCATGAGCAGC CAGGGATACCCATGGCAG 55 356 bp 16 3819081 3819436 CREBBP Exon 2223 GGACGCACACACAGACTTCTAC AACCAAAGAACAATGGGGAC 60 621 bp 16 3794816 3795436 CREBBP Exon 25 GGTGTGCAGAAGCACCTTG GAAGGCTCACAGGCTCCTC 65 306 bp 16 3789484 3789789 CREBBP Exon 26 aatgacagagcaagaccctg TTAAAATACCCATTATTTCACGG 55 315 bp 16 3788474 3788788 CREBBP Exon 27 TAACTCCTTAAAGGCAGGGC AAAAGGCACACAAATATCCTCC 55 300 bp 16 3786584 3786883 CREBBP Exon 28 CATGGGACTCTGCCACAC GACACCACCACAGGAAGGAC 60 388 bp 16 3785931 3786318 CREBBP Exon 29 TGACCTACTTTGGCCTGAGC ACTTCCCTCCCACCACAGAC 65 377 bp 16 3781671 3782047 CREBBP Exon 30 CTATTCTGCAGGCTGGGTG AAAGGGACAGGATGCTTCG 60 442 bp 16 3781127 3781568 CREBBP Exon 31 CCTGTACCGGGTGAACATCAAC GCTGCCTCCGTAACATTTCTCG 60 677 bp 16 3778459 3779135 CREBBP Exon 31 CCAAGTACGTGGCCAATCAG ACCGCACCTGGTTACTAAGG 65 717 bp 16 3778015 3778731 TP53 Exon 5-6 TAGTGGGTTGCAGGAGGTG tcaaataagCAGCAGGAGAAAG 65 594 bp 17 7578076 7578669 TP53 Exon 12 TGGGGTAAGGGAAGATTACG TTCTGACGCACACCTATTGC 58 399 bp 17 7572815 7573213 CDKN2A Exon 1 AGTTAAGGGGGCAGGAGTG GGCTCCTCAGTAGCATCAGC 60 246 bp 9 21994174 21994419 EP300 Exon 4 gaaatagcacattatgactcctacca tccctggctgtaaaaattgc 60 363 bp 22 41523440 41523802 EP300 Exon 14 ttctgttctgaattgctgtcttg atggaaatggcccagaagta 55 558 bp 22 41545721 41546278 EP300 Exon 17 tggtaactaatttcaaatgcacttttt tggctatactgtttggaatgtga 60 243 bp 22 41550963 41551205 EP300 Exon 26 gaactcattatgtgacctgacttttt tgttacgtaagaactaaaatgaggaaa 60 295 bp 22 41565449 41565743 EP300 Exon 27 caacttgtggtttaaaatgtagcc ccagatctattgtcagcacctg 65 285 bp 22 41566333 41566617 MLL2 Exon 3 gcgtggtactgatgcttgtg cagcccttatcccatttcct 60 293 bp 12 49448271 49448563 MLL2 Exon 5 ggctgacactgaggctcttt tctcatttgccctatgacca 60 235 bp 12 49447723 49447957 MLL2 Exon 6 gcaatgtgctgaggcttaca tcctgcccttccattcctac 60 247 bp 12 49447239 49447485 MLL2 Exon 10 aggagcatcgtgttgttgtg GGAGACAGGCGAGATGCT 65 490 bp 12 49445745 49446234 MLL2 Exon 10 CCGCCACCTGAGGAATTG GTGGGGAAGCAGGTGAGTC 63 463 bp 12 49445338 49445800 MLL2 Exon 10 GTGTCACGCCTGTCTCCAC GCATAGGCATGGCTCCTC 63 366 bp 12 49445126 49445491 MLL2 Exon 10 TGAGGAGCCGCAACTCTG CTCCTCAGGGGGCTTTTC 55 424 bp 12 49444856 49445279 MLL2 Exon 11 GGGGACAGTGACCCTGAGT CCCCCACTACCTTCCCTATG 65 298 bp 12 49444181 49444478 MLL2 Exon 14 tgactctggtcgcaaatcag attccccagcctacacctct 65 242 bp 12 49441712 49441953 MLL2 Exon 23 ctccttgactgccccaca ccatcaaataacttgccagctc 65 243 bp 12 49437342 49437584 MLL2 Exon 27 acaggtgggagtggtctgaa cagatggagggaaaggacaa 65 232 bp 12 49436287 49436518 MLL2 Exon 29 gcctgccaagtcttctctga cagttcccacgctaatccat 65 152 bp 12 49435663 49435814 MLL2 Exon 31 GTTACCCCTCGCTTCCAGTC GCCCAAAATGGCTGTTGAT 60 385 bp 12 49433851 49434235 MLL2 Exon 31 TTCACTTTCCCTCAGGCAGT ggagcgatatagggggctta 60 481 bp 12 49433467 49433947 MLL2 Exon 32 tgggcttattcctcttctctttt ccactatcccttgccactct 60 242 bp 12 49433192 49433433 MLL2 Exon 33 gggccaggatattgaaggtt atccatcccccttggtttac 60 234 bp 12 49432959 49433192 MLL2 Exon 34 ttccagGCAACTGGTAGGAG GTGGGGTGTTGGATGAAGAC 65 493 bp 12 49432286 49432778 MLL2 Exon 34 GCTGCTGATGCCTCTGAAC CTGAAAGCTGCTGCTTCTTCT 65 496 bp 12 49431337 49431832 Gene analyzed region fwd-primer (Sequence 5'-3') rev-primer (Sequence 5'-3') Temp Amplicon Chrom [°C] length (HG19) Start (HG19) End (HG19) MLL2 Exon 34 GCATCTGGGGATGAGCTAGA tggctatgttaccagctgagg 65 575 bp 12 49430884 49431457 MLL2 Exon 35 cgcagatattcactggagca gggtgtgactgggaaagaaa 58 237 bp 12 49428543 49428779 MLL2 Exon 38 tcctgacacccagcttcttt tctgggtgctaggctgaagt 60 293 bp 12 49427816 49428108 MLL2 Exon 39 GCACACTAATCTCATGGCAGA GGATTGCCACCTGTCCTAGA 65 500 bp 12 49427228 49427728 MLL2 Exon 39 GAAGCCTCGGACCTGATTC CCTTGCTGTTGGTGCTGTT 65 484 bp 12 49426885 49427369 MLL2 Exon 39 AGGGCCTTATGGGACACAG GGCCCATCTGCTGCTGTT 63 396 bp 12 49426559 49426955 MLL2 Exon 39 TCTCCTCAGCAACAACAGCA AGGCTGATCCCCTAAGGAAA 65 480 bp 12 49426053 49426532 MLL2 Exon 39 GCAGCTAGGCAGTGGATCAT GTGGGGTCTGGCGTACTG 65 374 bp 12 49425764 49426137 MLL2 Exon 39 AAGGAGTCCTGGCCAAAAAC GCAGCAGCAGGTGAGACC 60 484 bp 12 49425400 49425883 MLL2 Exon 39 ACCTCAGGGGCCAACCTT GTTCCTGGTGCCCCTATTG 65 300 bp 12 49425154 49425453 MLL2 Exon 40 ggctctgaggaggagggtag ctatcctgggatgggaccag 60 233 bp 12 49424632 49424864 MLL2 Exon 48 tacagggcaccctcctacag ATGTCTCGCGGTACCTTGTC 60 463 bp 12 49420663 49421125 MLL2 Exon 48 CCTTGCGACCTGACAAGGTA ACAGGGCCCCTTGATCTTAT 60 371 bp 12 49420323 49420693 MLL2 Exon 50 ctttggcctaaccccaaaaa gaccagaggatccctgtcaa 60 249 bp 12 49418299 49418547 MLL2 Exon 51 cagaggaggtgggtggtatg gccagctcatacCTGCTCTT 60 368 bp 12 49416361 49416728 MLL2 Exon 5253 agaagggaaaggcaggagaa aggaggaggagctgctttgt 55 491 bp 12 49415780 49416270 MLL2 Exon 54 gcattgattctgccctcttc CAATGGCTGCTTCTGTCTGG 60 390 bp 12 49415295 49415684 MEF2B Exon 5 ggcagacagaggagaggtgt tcaggtcagtcccttgccta 60 246 bp 19 19261413 19261658 MEF2B Exon 6 acaccaccccacattcatct taaagcacgtcagccacaaa 55 389 bp 19 19259911 19260299 MEF2B Exon 10 gggtgtgggcctcagttt taaccacccccagtgacagt 55 248 bp 19 19257252 19257499 MEF2B Exon 11 gaaggcttaaggagatgtccag gtgcgcagtaccagggatg 60 249 bp 19 19256995 19257243 CREBBP Exon 31 CACAGCAGCCCAGCACAC TTGTTGATGTTCACCCGGTA 60 256 bp 16 3779112 3779367 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 * described in (Pellissery et al, 2010)2 Temp indicates the annealing temperature in the PCR. SNP array analysis: SNP array experiments were performed according to the standard protocol for Affymetrix GeneChip SNP 6.0 arrays (Affymetrix). Briefly, a 500 ng sample of DNA was digested with StyI and NspI, ligated to adaptors, amplified by PCR, fragmented with DNAse I, and biotinlabeled. The labeled samples were hybridized to Affymetrix GeneChip SNP 6.0 arrays, followed by washing, staining and scanning. The complete dataset comprised 35 FL samples in total (16 cases included within the core set) and 33 lab-specific euploid samples (17 females and 16 males) for controls. DNA methylation analysis: Bisulfite conversion of the DNA was performed using the “Zymo EZ DNA methylation Kit” (Zymo Research, Orange, CA) according to the manufacturer´s instructions with the modification described in the Infinium Assay Methylation Protocol Guide (Illumina, San Diego, CA). All further analysis steps were performed according to the “Infinium II Assay Lab Setup and Procedures” and the “Infinium Assay Methylation Protocol Guide”. The processed DNA samples were hybridized to the HumanMethylation 27 BeadChips (Illumina, San Diego, CA). This array was developed to assay 27,578 CpG sites selected from more than 14,000 genes. Raw hybridization signals were processed using Bead Studio software (version 3.1.3.0, Illumina) applying the default settings. 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 3. Bioinformatic and statistical analyses Detecting selection by mutation analysis in the IGHV region sequences The objective of the mutation analysis was to compare the ratio of the observed number of replacement mutations and the observed number of silent mutations with their expected ratio, assuming no selection for both the structural regions of the heavy chain known as „framework regions“ (FWR) and the „complementarity determining regions“ (CDR). For each tumour sample the analysis consisted of the following steps: (1) All tumour IGHV sequences were aligned with their most likely germline sequences using the IMGT/HighV-QUEST online tool.3 (2) The number of different replacement (R) and silent (S) mutations in the set of clonally related sequences was determined for FWR and CDR resulting in counts Rfwr, Sfwr, Rcdr, Scdr. (3) A model4,5 for SHM assuming no selection, accounting for micro-sequence specificity of SHM targets and transition bias was used to determine expected counts given the total number of observed mutations resulting in numbers eRfwr, eSfwr, eRcdr, eScdr. Step (2) and (3) was performed using the web server http://clip.med.yale.edu/selection.4 (4) The web tool provides p-values on the null-hypothesis of no selection (separately for FWR and CDR) using the so called focused binomial test. P-values do not lend itself to meaningful meta-analyses. In addition, we wanted quantitative comparisons of strength of selection within tumour pairs from the same patient. Therefore we defined the logRSoddsratio=log( (R/S) / (eR/eS) ) as a quantitative measure of selection strength (compare Yaari et al 20126). This quantity compares the observed R/S ratio to the one expected under the null-hypothesis of no selection. The logarithm transforms the measure to its natural scale such that the estimates are approximately normally distributed. (5) The logRSoddsratio can be estimated using the numbers from step (2) and (3). In line with the ‘focused binomial test’ outlined in Uduman et al, 20114 and Hershberg et al, 20085 we gain power assuming that silent mutations are neutral concerning selection and thus Sfwr/Scdr = eSfwr/eScdr (we assume the mutation model that generates the expectations). Under this assumption logRSoddsratio=log( (R/S) / (eR/eS) )= log( (R/(Sfwr + Scdr)) / (eR/(eSfwr + eScdr)) ). 95% confidence intervals can be obtained sampling from the posterior distribution Dirichlet(eRfwr/E+Rfwr, eRcdr/E+Rcdr, (eSfwr + eScdr)/E + (Sfwr + Scdr)) [with E= eRfwr + eSfwr + eRcdr + eScdr]. P-values dual to these CIs are in good concordance with the p-values of the focused binomial test. (6) Standard methods7 for fixed and random effect meta-analyses and forest-plots are used to analyse logRSoddsratios across samples. We further wanted to distinguish evolution in times before tumor onset and after tumor initiation. Therefore, three computations were performed for each sample, each time using a different rooting sequence. Supplementary Figure 1 illustrates the three types of reference sequences: 1. The first rooting sequence was a consensus germline sequence constructed from all germline sequences assigned to the tumour sequences of the patient using the IMGT/V-QUEST online tool. Bases which differed among these germline sequences were substituted by „N“ (any base) in the consensus germline sequence. 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 2. The second rooting sequence consisted of bases common to all sequences from the primary tumour and the relapse tumour of the same patient. At positions where we observed different bases among these tumour sequences we inserted the corresponding base from the consensus germline sequence (the first reference sequence) into this common rooting sequence. 3. The third rooting sequence was constructed from bases common to the sequences found in each single tumour sample. Positions which varied among these sequences were filled with the corresponding base from the germline consensus sequence. Supplementary Figure 1. An illustration of the chronological position of the three types of rooting sequences used for detecting selection in each sample. Using three different rooting sequences allowed us to investigate how strongly selection acted on the observed sequences a) at any time since the VHDHJH recombination of the B-cell from which the primary and the relapse tumours originated (evaluation with respect to the germline rooting sequence), b) since the time of the last common somatic mutation in the precursor of the primary tumour and the relapse (evaluation with respect to the common tumor rooting sequence), and c) since the last somatic mutation which was common to the sequences of the investigated tumour sample (evaluation with respect to the tumor specific rooting sequence), respectively. NGS candidate genes Sequence data of all 69 samples was mapped to hg19 using the segemehl algorithm8 with default parameters. Samtools mpileup version 0.1.189 was applied to each sample with parameter “–d” set to 25000, thus allowing a maximum coverage of 25000 reads per position. For further analysis positions with effective enrichment were selected. Therefore all positions within enriched genomic regions (see Supplementary Table 2) with coverage >1000 reads and coverage of high quality (HQ) reads >500 (Phred quality score Q≥13) were selected for further investigation. Median HQ-base coverage over all target positions and lymphoma samples was 5343 bases (range: 4149-6653). Over all analyzed samples >99.3% of the enriched genomic positions showed both a coverage >1000 and a HQ coverage >500. Prior to variant calling for each position the number of reference and alternative alleles were summarized for forward and backward strand separately. This was repeated for high quality bases (Q≥13). 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 For the variant calling, the proportion of the most frequent alternative allele was analyzed for each position in each lymphoma sample. A variant was called if ≥10% of all HQ-bases showed a concordant alternative allele. To achieve a high specificity and avoid false positive variant calls, additional quality filters were applied. Variants showing a proportion of low quality reads of >40% were rejected. In addition variants with a high allelic imbalance between forward and reverse strand for reference and mutant alleles were removed. Therefore for each variant the |logOR| of the number of reference alleles and mutated alleles, each for forward and reverse strand was calculated. To avoid zeros 0.5 was added to each count. Variants with a |logOR|≥5 were removed from further analysis. After filtering, all variants were annotated with dbSNP build 135 for overlap with known single nucleotide polymorphisms. All variants overlapping positions with known SNPs were excluded from further analysis. In addition, functional annotation was added to all variants using vcfCodingSnps version 1.5 (http://genome.sph.umich.edu/wiki/VcfCodingSnps). a b Supplementary Figure 2. A) shows the histogram of the differences of the allele frequencies for detected mutations on the logit scale. The histogram indicates 3 peaks representing mutations present in both samples or either in primary (PT) or relapse tumor (RT) exclusively. A threshold of -2 and 2 (indicated by red vertical lines) is applied to distinguish these 3 groups. B) displays the allele frequency of mutated alleles for paired primary and relapse tumors. Red dots indicate mutations selected as differential between primary and relapse sample using the thresholds described in A). To compare mutations between paired samples of the same patient, for each variant identified (see Supplementary Table 5) the frequency of the mutant allele was compared. If a variant was called only in one sample the allele frequency of the second sample was calculated from the raw data. When comparing the differences of the allele frequencies on the logit scale for all non-SNP positions 3 groups appear (see tri-modal histogram in Supplementary Figure 2a). Using a threshold of 2 respectively -2 allows distinguishing concordant variants from variants present in only one of the lymphoma samples (see Supplementary Figure 2b). The proportion of discordant variants within pairs was determined for candidate genes and 2.5 kb downstream of TSS regions (non-IG SHM targets) separately and used as a summary measure of divergence. A schematic overview over the analysis pipeline for the sequencing data is shown in Supplementary Figure 3. 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 Supplementary Figure 3. A schematic overview over the analysis pipeline for the NGS data. (HQ=high quality) Methylome data analysis: “HumanMethylation27 DNA Analysis BeadChip” array data of 76 FL tumor samples were analyzed in combination with 8 control samples previously measured on the beta-test version of the same array (described in ref. 10). For the analysis, only CpG positions represented on both beta and final version of the array were included (n=27568). The raw fluorescent signals of methylated and unmethylated alleles were normalized across chips using the vsn method.11 The anti-log of normalized signals was used to calculate beta values as described.10 CpGs were classified into “hypermethylated in FL”, “hypomethylated in FL”, “methylated in FL and controls”, “unmethylated in FL and controls” and remnant as outlined.10 To compare methylation between lymphoma samples of the same patient, CpGs were selected as differentially methylated if the difference of the methylation level between paired 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 samples was >0.25. The proportion of discrepant CpGs within a pair is used as a summary measure of methylation divergence. Analysis of chromosomal alterations based on SNP arrays: Genotyping and copy number analysis was performed using Affymetrix Genotyping-Console version 4.1.1. Copy number segmentation was calculated using the R package DNAcopy.12 Parameters for prior data smoothing were adapted to data quality. Significant copy number aberrations were detected using an adapted implementation of histogram entropy minimization,13 whereas for data sets with bad data quality subsequent manual correction was necessary. Comparison of paired samples was performed on differences of copy number profiles from primary and relapse tumor, and carried out in the same manner. Results of segmented differences from paired samples were depicted for visual evaluation considering the individual profiles of primary and relapse tumors to distinguish qualitative and quantitative differences. A Hidden Markov Model based method14 implemented in dChip (64bit, build date: Apr 13 2010)15,16 was used to infer LOH from tumor samples. The LOH call threshold was set to the default value of 0.5. Comparison of paired samples was performed on differences of LOH profiles from primary and relapse tumor. Differences were determined by detecting changes from heterozygous in primary tumor to homozygous in relapse tumor (AB -> AA | BB) and vice versa (AA | BB -> AB). Positions with LOH were coded with "1", positions without LOH were coded with "0" and positions without information were coded with "NA", resulting in binary profiles. Segmentation of LOH profile differences was calculated using DNAcopy and its implementation of the circular binary segmentation algorithm for binary data. The segmentation parameter alpha was adapted manually (ranging from 0.4 to 0.99) to account for differences in data quality. Integrative correlation analysis: The integrated analysis correlated several quantitative measures of divergence between primary and secondary samples. We address the question whether and to which extent the biological processes generating divergence in various genomic and epigenomic dimensions correlated. A measure of divergence in a specific type of data is designed to capture the overall degree by which paired samples differ. Measures of divergence are chosen symmetrically in the samples with the aim to quantify overall drift on a common scale across pairs with small (but not necessarily zero) values if the samples are close/undistinguishable and large values if the samples have drifted apart and appear clearly distinct. Measures are scale transformed such that the distribution of divergences across pairs is approximately normal. IGHV sequences: IGHV_divergence is calculated as the average Hamming distance between the observed sequences from the primary and the secondary sample (normalized to a common sequence length of 100). The Hamming distance between two aligned sequences is the number of positions in which they differ. The average Hamming distance is log transformed to achieve an approximately normal distribution. This measure can be calculated both for clone sequences and NGS results yielding nearly identical results in 9 cases with both measurements available. SHM of non-IG genes: For each tumor pair, we observe N mutations found in at least one of the samples. k out of them will be discordant (i.e. found only in one but not the other sample). Aberrant_SHM_divergence is defined as the proportion of mutations found which are discordant. Since we deal with varying denominators some may be small and we want to avoid zeros, we use the non-informative Bayesian estimate (k+0.5)/(N+1). The proportion is logit transformed to achieve an approximately normal distribution across pairs on the real 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 line. Besides overall aberrant_SHM_divergence we also consider sub-divergences in BCL2 sites only and transcription sites outside BCL2 only. Mutations in candidate genes: Candidate_Gene_Mutation_divergence analogously to aberrant_SHM_divergence. is defined Differentially methylated CpG islands: DNA_Methylation_divergence is calculated as the proportion of CpG islands in which we observe a difference in methylation degree of >25% between the pairs. The cut-value at 25% has been used before9 and cut-points between 20% and 35% do not change results. The proportions are logit transformed to achieve an approximately normal distribution across pairs on the real line. SNP chip data: Chromosomal_divergence is defined as the proportion of SNPs investigated which differed between primary and secondary sample in copy number or LOH status. The proportions are logit transformed to achieve an approximately normal distribution across pairs. Time difference: The number of days elapsed between obtaining the samples is log10 transformed to achieve an approximately normal distribution across pairs. Correlation methods: For pairs of measures of divergence Pearson linear correlation coefficients were estimated with 95% BCa-bootstrap confidence intervals.17 Correlations were considered “significant” if the confidence interval excluded zero. 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 4. Supplementary Results A. Detecting selection by mutation analysis in the IGHV region sequences As described in section 3E, the observed ratio of the number of replacement and silent mutations was compared with the expected ratio, separately for „framework regions“ (FWR) and „complementarity determining regions“ (CDR). To distinguish selection in times before tumor onset and after tumor initiation, three computations using different rooting sequences were performed (see Suppl. Figure 4 and Suppl. Table 4a and 4b). a b c d e f Supplementary Figure 4. LogRSoddsratios quantifying selection together with their highest credibility intervals. Each interval corresponds to one sample. (a, b, c) Results for the FWRs using the reference sequences 1, 2 and 3, respectively, (d, e, f) Results for the CDRs using the reference sequences 1, 2, and 3, respectively. The result of a meta-analysis is shown in blue at the bottom of each plot. Supplementary Table 4a. Results of a meta-analysis of selection in the IGHV regions. Shown are the estimates of the logRSoddsratios, their confidence intervals, values of the Q statistic testing for heterogeneity of the effects and the corresponding P-values for heterogeneity (see also Figure 2). Germline rooting sequence estimate (95% CI) 397 398 399 400 401 402 Common tumor rooting sequence Q P estimate (95% CI) Q P Single tumor rooting sequence estimate (95% CI) Q P FWR -0.77 (-0.88; -0.67) 43 0.229 -0.89 (-1.02; -0.75) 36 0.517 -0.91 (-1.06;-0.76) 41.3 0.290 CDR -0.32 (-0.45; -0.19) 46 0.147 -0.58 (-0.76; -0.39) 55.4 0.026 -0.65 (-0.87; -0.43) 43.9 0.202 Supplementary Table 4a provides the summary statistics and Supplementary Table 4b (external Excel file) the results for each sample. The following observations can be made regarding the FWRs: 1. The FWRs are clearly preserved (selection against replacement mutations). 2. There is no heterogeneity in the logRSoddsratios between samples (Q-test). 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 3. These results are valid independent of the choice of the rooting sequence. 4. There are fewer numbers of mutations with respect to later rooting sequences and thus the corresponding confidence intervals are wider. Hence we conclude that FL depends on a functional BCR. Regarding to the CDRs, we observe that: 1. The estimates of the logRSodds ratios show higher variability due to smaller number of mutations than in the FWRs. 2. Similar to the FWRs, there is no evident heterogeneity in logRSoddsratios between samples (Q-test). 3. Global meta-analytic estimate shows overall significant preservation but a. The effect for CDR is quantitatively (significantly) less pronounced than that for the FWRs. b. The estimates tend to become stronger using later rooting sequences Hence, these results are consistent with ongoing dependence of FL on affinity against a tumor specific but unknown antigen. Taken together, the data strongly suggest that the malignant clone is affected by ongoing SHM during tumor evolution. The data also indicate that in most cases the SHM process is not only working before the primary tumor is detected but also during the period until relapse. B. IGH mutation analysis – comparison of VH clone sequencing and NGSsequencing Visual inspection of the phylogenetic trees (see section 3D) resulted in 8, 5, 6 and 4 pairs of samples classified to the “no evolution”, “sequential evolution”, “divergent evolution” and “complex evolution” categories, respectively. Examples of trees from each category are shown in Figure 1 of the manuscript. We also quantified the evolutionary divergences between the primary and the matching relapse specimen using a measure IGHV_divergence which we developed for this purpose (section 3D). We observed that the IGHV_divergence values were small in the “no evolution” category, but progressively increased in the “sequential evolution” and the “divergent evolution” categories (Supplementary Figure 5). This indicated that the measure reflected the biologic intuition expressed in the visual classification of the phylogenetic trees while being more objective and quantitative. Using this, we were able to correlate the data from the sequencing with other biological and clinical parameters. 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 Supplementary Figure 5. The IGHV_divergence values conforms well with the diversity seen in pedigrees regarding “no evolution”, “sequential evolution” and “divergent evolution” categories (points jittered to avoid overlaps). To validate the results obtained from Sanger sequencing, we performed NGS of the IGHV rearrangements in a subset of our cases (paired measurements from 9 patients). The measures of divergence between the primary and the relapse samples using the Sanger and the NGS data were highly correlated (Supplementary Figure 6). This measure can be calculated both for clone sequences and NGS results yielding nearly identical results in N=9 cases with both measurements available. Supplementary Figure 6. Correlation between the measures of divergence of the IGHV sequences of the primary and the corresponding relapse tumors measured by Sanger sequencing (x-axis) and NGS (y-axis). We further asked whether the evolutionary divergence of the paired samples of tumors could be explained by the time elapsed between the two biopsies. However, we found no correlation (Figure 3e of the manuscript). C. Methylation analysis Classification of CpGs in “hypermethylated in FL”, “hypomethylated in FL”, “methylated in FL and controls”, “unmethylated in FL and controls” showed a high concordance to previously analyzed DLBCL.10 Of 26604 CpGs analyzed in both datasets, 66.58% showed a concordant classification. The majority of discordantly classified CpGs (98.85%) were classified as remnant in either FL or DLBCL. As previously reported10,18 hypermethylated CpGs were highly enriched among known polycomb target genes. Hypermethylated CpGs were enriched for loci repressed by PcG marks in embryonic stem cells.19 663/1458 (45.5%) of all hypermethylated CpGs were polycomb target genes compared to 2247/21826 (9.3%) in all other groups (OR=8.1/p<0.001). Similar results were observed for embryonic fibroblasts 20 with 785/1560 (50.3%) polycomb targets among hypermethylated CpGs compared 4935/25679 (19.2%) in all other classes (OR=4.3/p<0.001). Unsupervised cluster analysis of CpG array data for all samples showed clustering of the vast majority of paired samples from the same patient rather than separation of initial and 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 relapse samples (Supplementary Figure 7). This indicates that each tumor has its unique DNA methylation profile which is largely conserved over evolution, although permitting for minor variations as seen below. Supplementary Figure 7. Correlation heatmap of the methylation dataset. All samples are ordered according to the patients. Patients are indicated by color bars for rows and columns, i.e. neighbored samples marked by the same color belong to the same patient. Each point in the heatmap represents the correlation (R²) of 2 samples. For the majority of patients all related samples show high correlation indicated by light green squares along the diagonal. The average degree of methylation was higher in relapses compared to primary samples. On average the ratio “increased methylation in relapse / increased methylation in primary sample” was 1.43 (Supplementary Figure 8). Supplementary Figure 8. Histogram of pair-wise differences of the proportion of hypermethylated CpGs in the relapse sample – hypermethylated CpGs in the primary tumor on the logit scale. On average the CpGs showed slightly higher methylation levels for the relapse samples. Included were all pairs from the complete dataset with exclusion of pairs with time between biopsies <4 months. It is, however, also noticeable that both gains and losses of methylation are found simultaneously. 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 D. Analysis of chromosomal alterations based on SNP arrays The average call rate for all tumor samples was 98.42% [96.39%–99.19%] and 98.33% [96.39%–99.19%] for the core set. Genotypes of paired samples showed a concordance of 98.99% [94.63%–99.93%]. In contrast, genotype concordance of randomly paired samples from different patients was typically about 61.7%, thus confirming that all paired samples originate from the same patient. Supplementary Figure 9 shows the profile of copy number aberrations and uniparental disomies (UPD) for the analyzed dataset. Most notable gains were detected at chromosomes 1q, 2p, 5p, 7, 11, 12, 16q, and 18 while notable losses can be seen at chromosomes 1p, 6q, 7p, 17p, 19 and 22 concordant with previous copy number analyzes by arrayCGH.21 Supplementary Figure 9. Copy number and UPD profile of the analyzed SNP-6.0 dataset. The proportion of gains (green), losses (red) and UPD (cyan) is displayed in genomic order. Supplementary Figure 10 shows the changes of structural aberrations between primary and relapse tumors in 19 tumor pairs. For each analyzed pair changes in copy number or UPD are shown in genomic order. Green color indicates an aberration only present in the primary tumor, red indicates an aberration in the relapse that is lacking in the primary tumor. Sup plementary Figure 10. Heatmap of discrepant copy number / LOH regions. Each column 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 shows discrepant copy number / LOH regions within a sample pair of the same patient. Green regions are only aberrant in the primary tumor, regions shown in red are exclusively aberrant in the relapse sample. E. Mutation analysis of coding genes and aSHM target regions Variant calling in potential lymphoma driver genes and aSHM target regions for all 69 lymphoma samples resulted in 3043 variants (see Supplementary Table 5, external Excel file) of which 1134 showed no overlap with known SNP positions. Of these 1134, 954 (84%) were up to 2.5 kB downstream of TSS (non-IG SHM targets) and 180 (16%) within the candidate genes. This can be taken as a strong indication of genetic damage inflicted by an active somatic hypermutation machinery. Within the TSS regions, 28/954 (3%) mutations were annotated as non-synonymous, affecting splice sites or affecting/generating stop codons. For the candidate gene regions, 139/180 (77%) were annotated as nonsynonymous, affecting splice sites or affecting/generating stop codons. 219 mutations were validated using Sanger sequencing. In 215 (98%) validations, the mutations were confirmed, 2 showed wild-type by Sanger sequencing and 2 were n.a. (see Supplementary Table 5). In addition, 118 mutations rejected by our quality filters were validated by Sanger sequencing, resulting in 26 (22%) confirmed mutations, 85 (72%) were disproved and 7 n.a. These results illustrate a high specificity for the applied variant calling, but indicate on the other hand a reduction in the sensitivity due to the quality filtering. In a second step the mutations were compared within paired samples. To this end the allele frequency of each mutation (SNP positions excluded) that was present in one of the paired samples was analyzed in the remaining sample. The allele frequency difference was analyzed as outlined in section 3F and each mutation was classified as present in both samples or as discrepant (i.e. only present in one of the samples). Within 5' regions of genes, 379/904 (41.9%) mutations were discrepant between paired samples, mutations in coding regions were discrepant in 32/145 (22.1%) compared variants (see Supplementary Table 6, external Excel file). Mutations not detected in single case analysis but detected as present in both samples within the paired analysis were considered as mutated in both samples for further analyses. Thus the number of mutations in non-IG SHM target regions increased from 954 to 1059 and from 180 to 197 for the candidate genes. Distribution of mutations in candidate genes and TSS regions are summed up in Supplementary Tables 7a and 7b. 560 561 562 563 564 565 566 567 568 569 Supplementary Table 7a. Mutations in candidate genes. The table shows the number of mutations and the number of protein-changing mutations for each analyzed gene locus. In addition the number and percentage of samples affected by at least 1 protein-changing mutation is shown. As indication for mutations occurring early in tumor development the allele frequency of the mutated alleles was analyzed. For each locus the mean allele frequency of detected mutations is displayed (in case of multiple mutations in the same gene for single samples only the mutation with the highest allele frequency was included). In the last column the number of patients affected by at least 1 single discrepant mutation in the related gene locus is shown. 0.28 0.37 0.45 0.22 0.35 0.41 0.25 0 7 4 2 1 0 1 0 0 2 / 69 2.90 0.31 1 0 0 / 69 0.00 - 0 0 0 / 69 0.00 - 0 BCL2 MLL2 CREBBP TNFRSF14 EZH2 EP300 MEF2B BCL6 MYC 10 81 55 19 15 8 3 2 2 0 54 52 15 15 4 1 0 2 0 / 69 39 / 69 43 / 69 15 / 69 11 / 69 4 / 69 1 / 69 0 / 69 2 / 69 TP53 2 2 CDKN2A 0 MYD88 0 % samples affected by proteinchanging mutations Supplementary Table 7b. Mutations in a 2.5 kB region downstream of TSS (non-IG SHM targets). The table shows the number of mutations for each locus analyzed. In addition, the number and percentage of samples affected by at least 1 mutation is shown. Region CIITA_SHM BCL2_SHM RHOH_SHM BCL6_SHM PAX5_SHM REL1_SHM IRF4_SHM MYC_SHM PIM1_SHM 574 575 576 577 578 579 580 581 582 0.00 56.52 62.32 21.74 15.94 5.80 1.45 0.00 2.90 Number of mutations Number of proteinchanging mutations Gene 570 571 572 573 mean allele frequency of mutations Number of patients with ≥1 discordant proteinchanging mutations Number of samples affected by proteinchanging mutations Number of mutations Number of samples affected % samples affected 41 718 104 144 17 5 14 11 24 / 69 68 / 69 54 / 69 37 / 69 7 / 69 5 / 69 9 / 69 11 / 69 34.78 98.55 78.26 53.62 10.14 7.25 13.04 15.94 5 4 / 69 5.80 The majority of the protein-changing mutations within the exons of candidate genes affect CREBBP (52 mutations in 43/69 (62%) samples) and MLL2 (54 mutations in 39/69 (57%) samples). This indicated a strong mutation effect on genes regulating histone modifications and transcriptional control. An overview over the mutations affecting the non-IG SHM targets is shown in Supplementary Table 7b. The majority of the mutations affect the BCL2 locus. This is in line with the fact that the BCL2 locus is translocated to the IGH region by t(14;18) translocation and therefore frequently targeted by the SHM machinery. 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 The characteristic WRCY/RGYW motif was highly enriched among mutations in the non-IG SHM targets. When considering each mutation only once per patient, 104/618 mutations were overlapping the C/G base of the motif. Considering the genomic sequence of the analyzed regions, the number of expected overlaps is 35/618 (OR=3.4; binomial test p<0.001). In comparison, no enrichment for mutations overlapping C/G of the WRCY/RGYW motif could be shown for the mutations affecting the candidate genes. Only 4/100 mutations (again each mutation was only considered once per patient) overlapped the C/G base. Considering the genomic sequence, one would expect 7/100 overlapping mutations (OR=0.55; binomial test p=0.33). We compared mutation status of the analyzed candidate genes and DNA_Methylation_divergence as well as Aberrant_SHM_divergence (see Figure 4). Pairs in which at least one of the samples was affected by a CREBBP mutation were compared to unaffected pairs and showed significantly higher median DNA-methylation-divergence (p=0.008) and aSHM-divergence (p=0.024). Thus, CREBBP may be involved in generating evolutionary divergence particularly with regard to DNA methylation patterns. Supplementary Table 7c.Comparison of the observed mutation frequency affecting candidate genes for lymhomagenesis between our cohort and the FL / tFL cohorts of Okosun et al. 201422 (% affected samples) Gene CREBBP MLL2 TNFRSF14 EZH2 EP300 MYC TP53 MEF2B BCL6 BCL2 CDKN2A 602 603 604 605 606 607 608 Our series on FL (primary and relapse pooled) 62% 57% 22% 16% 6% 3% 3% 1.5% 0% 0% Okosun et al. for FL* 64% 82% 35% 20% 18% - Okosun et al. for tFL** 70% 73% 40% 24% 12% - 0% - - MYD88 0% 2% * according to Fig. 3 of Okosun et al. 201422 **according to Suppl. Fig. 7B of Okosun et al. 201422 12% Supplementary Table 7d. Comparison of the observed frequency of mutations affecting aSHM targets between our cohort and the FL / tFL cohort of Pasqualucci et al. 201423 (% affected samples) Region Our series on FL (primary and relapse pooled) Pasqualucci et al. FL* Pasqualucci et al. transformed FL* CIITA_SHM BCL2_SHM RHOH_SHM BCL6_SHM PAX5_SHM REL1_SHM IRF4_SHM MYC_SHM 35% 99% 78% 54% 10% 7% 13% 16% 7% 87% 7% 60% 0% 7% 46% 87% 36% 64% 38% 23% 13% 46% PIM1_SHM 6% * according to Fig. 6 of Pasqualucci et al. 201423 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 F. Integrated correlation analysis We correlated the measures of divergence (see section 3I) for all analyzed genetic and epigenetic read outs with the time elapsed between samples to examine whether the observed divergence is increasing over time. However, we found no support for this expectation. Supplementary table 8 summarizes the correlation coefficients and confidence intervals from Supplementary Figure 11. Correlation with time between samples IGHV_divergence DNA_Methylation_divergence Aberrant_SHM_divergence Candidate_Gene_Mutation_divergence Chromosomal_divergence rhoEst 0.010 0.033 0.066 0.173 0.319 Lower [-0.35 [-0.23 [-0.22 [-0.16 [-0.03 Upper ; 0.44] ; 0.28] ; 0.33] ; 0.44] ; 0.57] Supplementary Table 8: Correlation of measures of divergence with time between samples (log10TimeDiff) with 95% confidence intervals 21 627 628 a b 629 630 c d 631 632 633 634 635 636 637 e Supplementary Figure 11. There is no evidence for a correlation of measures of divergence with time. In particular, SHM related measures and methylation appear to be completely uncorrelated with time. Note that the grey dots label observations for whom no IGHV sequences and hence no pedigrees were available. 22 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 We also investigated the correlation between IGHV-divergence and divergence in the other genetic and epigenetic readouts. There were pronounced correlations in all comparisons (see Supplementary Table 9 and Supplementary Figures 12-14). Correlation with IGHV-divergence rhoEst Lower Upper Aberrant_SHM_divergence 0.724 [ 0.40 ; 0.88] Aberrant_SHM_divergence_BCL2only 0.723 [ 0.41 ; 0.88] Aberrant_SHM_divergence_BCL2excluded 0.461 [-0.03 ; 0.76] DNA_Methylation_divergence 0.516 [ 0.24 ; 0.72] Candidate_Gene_Mutation_divergence 0.372 [-0.03 ; 0.67] Chromosomal_divergence 0.475 [ 0.07 ; 0.70] Supplementary Table 9: Correlation of measures of divergence and IGHV-divergence with 95% confidence intervals a b c Supplementary Figure 12. IGHV-divergence is strongly correlated with Aberrant_SHM_divergence. This is expected since SHM is a common biological process behind both measures of divergence. This correlation is still strong when restricted to 23 661 662 663 664 665 666 667 668 669 670 671 672 673 674 aberrant SHM in BCL2 only, which is translocated near the IGHV locus. Excluding BCL2 sites reduces the observed correlation (not significant anymore). Supplementary Figure 13. IGHV-divergence is also clearly correlated with DNA_Methylation_divergence. Note that the correlation estimate is attenuated due to two outliers. a b Supplementary Figure 14. IGHV-divergence is also correlated to Chromosomal_divergence, while the correlation with discrepant mutations in candidate genes is not significant. 24 675 676 677 678 679 680 681 G. Display of all data levels for prototypic cases The following graphics illustrate the correlation between primary and relapse samples for all analyzed omics levels. Each figure represents a prototypical case for the respective class of the phylogenetic IGHV tree. Clinical characteristics of each sample are available via MPI/SYS identifiers in Suppl. Table 1b. a b c d 682 683 684 685 686 Supplementary Figure 15: Integrative display of a case with “No evolution”. The sample IDs are MPI-775 (primary tumor), MPI-776 (relapse). a) Phylogenetic tree of the Ig heavy-chain sequences (Sanger sequencing). Blue (red) leaves indicate sequences from the primary (relapse) tumor. b) Allele frequency of mutations in both samples. Shown are mutations in the transcription start sites and in the protein coding regions of the sequenced genes. Red dots indicate discrepant mutations. c) Scatter plot of methylation in both samples. Red dots indicate differentially methylated CpGs. d) Copy number alterations and loss of heterozygosity (LOH) events as measured by SNP arrays. Two upper panels show the copy number in the primary and the relapse tumor, respectively. The third panel shows the difference between the two profiles. The fourth panel depicts LOH regions for each sample in red. The bottom panel shows 25 regions where heterozygous calls in the primary tumor change to homozygous genotypes in the relapse (brown) and vice versa (purple). a 687 688 689 690 691 692 693 694 695 b c Supplementary Figure 16: Integrative display of a case with “Sequential evolution”. The sample IDs are MPI-871 (primary tumor), MPI-891 (relapse). a) Phylogenetic tree of the Ig heavy-chain sequences (Sanger sequencing). Blue (red) leaves indicate sequences from the primary (relapse) tumor. b) Allele frequency of mutations in both samples. Shown are mutations in the transcription start sites and in the protein coding regions of the sequenced genes. Red dots indicate discrepant mutations. c) Scatter plot of methylation in both samples. Red dots indicate differentially methylated CpGs. (No copy number data available for relapse sample) 26 a b c d 696 697 698 699 700 701 702 703 704 705 706 707 708 709 Supplementary Figure 17: Integrative display of a case with “Divergent evolution”. The sample IDs are MPI-772 (primary tumor), MPI-771 (relapse). a) Phylogenetic tree of the IGHV sequences (Sanger sequencing). Blue (red) leaves indicate sequences from the primary (relapse) tumor. b) Allele frequency of mutations in both samples. Shown are mutations in the transcription start sites and in the protein coding regions of the sequenced genes. Red dots indicate discrepant mutations. c) Scatter plot of methylation in both samples. Red dots indicate differentially methylated CpGs. d) Copy number alterations and loss of heterozygosity (LOH) events as measured by SNP arrays. Two upper panels show the copy number in the primary and the relapse tumor, respectively. The third panel shows the difference between the two profiles. The fourth panel depicts LOH regions for each sample in red. The bottom panel shows regions where heterozygous calls in the primary tumor change to homozygous genotypes in the relapse (brown) and vice versa (purple). 27 a b c d 710 711 712 713 714 715 716 717 718 719 720 721 722 723 Supplementary Figure 18a: Integrative display of a case with “Complex evolution”. The sample IDs are SYS-016 (primary tumor), SYS-017 (first relapse) and SYS-018 (second relapse). a) Phylogenetic tree of the Ig heavy-chain sequences (Sanger sequencing). Blue, red and brown leaves indicate sequences from the primary tumor, the first and the second relapse tumor, respectively. b) Allele frequency of mutations in both samples. Shown are mutations in the transcription start sites and in the protein coding regions of the sequenced genes. Red dots indicate discrepant mutations. c) Scatter plot of methylation in both samples. Red dots indicate differentially methylated CpGs. d) Copy number alterations and loss of heterozygosity (LOH) events as measured by SNP arrays. Two upper panels show the copy number in the primary and the relapse tumor, respectively. The third panel shows the difference between the two profiles. The fourth panel depicts LOH regions for each sample in red. The bottom panel shows regions where heterozygous calls in the primary tumor change to homozygous genotypes in the relapse (brown) and vice versa (purple). 28 a b c 724 725 726 727 728 729 730 731 732 733 734 735 Supplementary Figure 18b: Integrative display of a case with “Complex evolution”. The sample IDs are SYS-016 (primary tumor), SYS-018 (second relapse). a) Allele frequency of mutations in both samples. Shown are mutations in the transcription start sites and in the protein coding regions of the sequenced genes. Red dots indicate discrepant mutations. b) Scatter plot of methylation in both samples. Red dots indicate differentially methylated CpGs. c) Copy number alterations and loss of heterozygosity (LOH) events as measured by SNP arrays. Two upper panels show the copy number in the primary and the relapse tumor, respectively. The third panel shows the difference between the two profiles. The fourth panel depicts LOH regions for each sample in red. The bottom panel shows regions where heterozygous calls in the primary tumor change to homozygous genotypes in the relapse (brown) and vice versa (purple). 29 a b c 736 737 738 739 740 741 742 743 744 745 746 747 Supplementary Figure 18c: Integrative display of a case with “Complex evolution”. The sample IDs are SYS-017 (first relapse), SYS-018 (second relapse). a) Allele frequency of mutations in both samples. Shown are mutations in the transcription start sites and in the protein coding regions of the sequenced genes. Red dots indicate discrepant mutations. b) Scatter plot of methylation in both samples. Red dots indicate differentially methylated CpGs. c) Copy number alterations and loss of heterozygosity (LOH) events as measured by SNP arrays. Two upper panels show the copy number in the primary and the relapse tumor, respectively. The third panel shows the difference between the two profiles. The fourth panel depicts LOH regions for each sample in red. The bottom panel shows regions where heterozygous calls in the primary tumor change to homozygous genotypes in the relapse (brown) and vice versa (purple). 30 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 Supplementary References: 1. van Dongen JJ, Langerak AW, Brüggemann M, Evans PA, Hummel M, Lavender FL, et al. Design and standardization of PCR primers and protocols for detection of clonal immunoglobulin and T-cell receptor gene recombinations in suspect lymphoproliferations: report of the BIOMED-2 Concerted Action BMH4-CT98-3936. Leukemia 2003; 17: 2257-317 2. Pellissery S, Richter J, Haake A, Montesinos-Rongen M, Deckert M, Siebert R. Somatic mutations altering Tyr641 of EZH2 are rare in primary central nervous system lymphoma. Leuk Lymphoma 2010; 51: 2135-6. 3. Alamyar E, Giudicelli V, Li S, Duroux P, Lefranc MP. IMGT/HighV-QUEST: the IMGT® web portal for immunoglobulin (IG) or antibody and T cell receptor (TR) analysis from NGS high throughput and deep sequencing. Immunome Res 2012; 8: 26 4. Uduman M, Yaari G, Hershberg U, Stern JA, Shlomchik MJ, Kleinstein SH. Detecting selection in immunoglobulin sequences. Nucleic Acids Res 2011; 39: W499-504 5. Hershberg U, Uduman M, Shlomchik MJ, Kleinstein SH. Improved methods for detecting selection by mutation analysis of Ig V region sequences. International Immunology 2008; 20: 683-694 6. Yaari G, Uduman M, Kleinstein SH. Quantifying selection in high-throughput Immunoglobulin sequencing data sets. Nucleic Acids Res 2012; 40: e134 7. Whitehead A, Whitehead J. A general parametric approach to the meta-analysis of randomized clinical trials. Statistics in Medicine 1991; 10: 1665-77 8. Hoffmann S, Otto C, Kurtz S, Sharma CM, Khaitovich P, Vogel J, et al. Fast mapping of short sequences with mismatches, insertions and deletions using index structures. PLoS Comput Biol 2009; 5: e1000502 9. Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics 2009; 25: 2078-9 10. Martín-Subero JI, Kreuz M, Bibikova M, Bentink S, Ammerpohl O, Wickham-Garcia E, et al. New insights into the biology and origin of mature aggressive B-cell lymphomas by combined epigenomic, genomic, and transcriptional profiling. Blood 2009; 113: 2488-97 11. Huber W, von Heydebreck A, Sueltmann H, Poustka A, Vingron M. Parameter estimation for the calibration and variance stabilization of microarray data. Stat Appl Genet Mol Biol 2003; 2 12. Venkatraman ES, Olshen AB. A faster circular binary segmentation algorithm for the analysis of array CGH data. Bioinformatics 2007; 23: 657-63 13. Kapur JN, Sahoo PK, Wong AKC. A new method for gray-level picture thresholding using the entropy of the histogram. Comput Vision Graph 1985; 29: 273-85 14. Beroukhim R, Lin M, Park Y, Hao K, Zhao X, Garraway LA, et al. Inferring loss-ofheterozygosity from unpaired tumors using high-density oligonucleotide SNP arrays. PLoS Comput Biol 2006; 2: e41 15. Lin M, Wei LJ, Sellers WR, Lieberfarb M, Wong WH, Li C. dChipSNP: significance curve and clustering of SNP-array-based loss-of-heterozygosity data. Bioinformatics 2004; 20: 1233-1240 16. Zhao X, Li C, Paez JG, Chin K, Jänne PA, Chen TH, et al. An integrated view of copy number and allelic alterations in the cancer genome using single nucleotide polymorphism arrays. Cancer Research 2004; 64:3060-3071 17. DiCiccio TJ, Efron B. Bootstrap Confidence Intervals. Stat Sci 1996; 11: 189-212 18. O'Riain C, O'Shea DM, Yang Y, Le Dieu R, Gribben JG, Summers K, et al. Arraybased DNA methylation profiling in follicular lymphoma. Leukemia 2009; 23: 1858-66 19. Lee TI, Jenner RG, Boyer LA, Guenther MG, Levine SS, Kumar RM, et al. Control of developmental regulators by Polycomb in human embryonic stem cells. Cell 2006; 125: 301-13 31 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 AUTHOR CONTRIBUTIONS 821 822 823 824 825 826 827 828 829 830 831 832 WK, CP and AH provided patient samples and clinical data; AH, MS, KK and WK provided the respective quality controlled DNA analytes and immunohistological staining; CP and HT performed IGHV sequencing (Sanger + NGS); CP, DHe and HT provided bioinformatic analysis of IGHV sequencing; CA performed phylogenetic analyses; DH, MR and RK performed analysis of R/S ratio in IGHV regions; AH and OA performed methylation array experiments; MK and DH provided biometric analysis of methylation arrays; RSc and RK provided SNP-6.0 array data; KW and MK provided bioinformatic analysis of SNP6.0 arrays; AH coordinated NGS analyses for non-IG SHM and candidate genes; MK, SH and DH provided bioinformatic analysis of NGS data; DH performed the integrative biometric analysis; RS and ML designed the project and the grant application (PIs); RS, RK, MK, DH, ML interpreted data and wrote the manuscript; all authors read and approved the final manuscript. 20. Bracken AP, Dietrich N, Pasini D, Hansen KH, Helin K Genome-wide mapping of Polycomb target genes unravels their roles in cell fate transitions. Genes Dev 2006; 20: 1123-36 21. Schwaenen C, Viardot A, Berger H, Barth TF, Bentink S, Döhner H, et al. Microarraybased genomic profiling reveals novel genomic aberrations in follicular lymphoma which associate with patient survival and gene expression status. Genes Chromosomes Cancer 2009; 48: 39-54 22. Okosun J, Bödör C, Wang J, Araf S, Yang CY, Pan C, et al. Integrated genomic analysis identifies recurrent mutations and evolution patterns driving the initiation and progression of follicular lymphoma. Nat Genet. 2014; 46:176-81 23. Pasqualucci L, Khiabanian H, Fangazio M, Vasishtha M, Messina M, Holmes AB, et al. Genetics of follicular lymphoma transformation. Cell Rep. 2014; 6:130-40 32