cDNA FAQs
advertisement

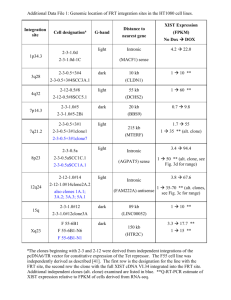
c DNA FAQs 1. What would you suggest I do if my cDNA clone is not growing? Try using broth culture instead of plate culture to jumpstart growth. * Use shaking during growth of the broth culture. * Double check to make sure you are using the correct antibiotic and concentration. * Try inoculating from thawed source tube rather than frozen. (frozen often works but sometimes it does not). * Gently mix the source tube by inversion (with the lid on) to ensure the cells are not settled in the bottom before the inoculum is taken. * Try increasing the inoculum (i.e. 10ul inoculum into 2ml broth). * Try spinning the tube to pellet the cells and take from the pellet to inoculate a broth culture. 2. How should I store my cDNA clone? For short term storage (one week or less), store at 4°C. For long term storage (indefinitely), store at -80°C. 3. Can I use tetracycline to induce expression of the mature microRNA in SMARTchoice Inducible shMIMIC microRNAs? No, Tet-On 3G has been optimized for binding doxycycline, and it responds poorly to tetracycline. 4. How does the IMAGE pipeline for production of cDNA clones work? The IMAGE consortium puts clones into the catagories of EST, Putative Full-Length and Full-Length. This is because there is a pipeline that the clones go through to be analyzed to see if they are full-length or not. A cDNA library is made and the clones are arrayed out into individual wells in a microtiter plate. At this point a clone will be labeled as EST or Putative Full-length depending on the library that it came from. All of the clones are end-sequenced on the 5' end of the clone. They do this end read to analyze the clones looking for a start codon. This sequence is posted to GenBank associated with the clone ID. If a start codon is found, the clone is then fully sequenced and the SAME clone is re-arrayed onto a NEW PLATE (if it is an EST) where it is labeled PUTATIVE FULL-LENGTH. (This sequence is also posted to GenBank associated with the clone ID. You can tell that a sequence posted to GenBank is a full insert read, because the accession number of a full insert read STARTS WITH "BC".) If the clone was already on a putative-full length plate, then it does not move at this point. Putative full-length seems to be the most misunderstood of all the labels. All that Putative Full-length means is that the IMAGE consortium thinks that it might be full-length. Whether or not it is found to be full-length later, the clone in that particular plate will ALWAYS be known as Putative full-length. After full-insert sequencing, the sequence of the clone is analyzed and must pass 8 or 9 criteria put forth by the IMAGE consortium in order to be called "Full-length". If the clone passes all criteria, it is moved to a NEW PLATE and labeled as FULL-LENGTH. THIS IS A LABEL PUT ON THE CLONE BY IMAGE, WE HAVE NOTHING TO DO WITH THESE LABELS. EVEN IF IMAGE CALLS A CLONE FULL-LENGTH, THE RESEARCHER NEEDS TO LOOK AT THE "BC" SEQUENCE TO MAKE SURE THE CLONE MEETS THEIR EXPECTATIONS FOR A FULL-LENGTH CLONE. Plate location group labels (EST, Putative Full-length, or Full-length) are permanantly associated with each clone based on the plate location. So one particular clone can be found labeled as all 3 - EST, Putative-full Length, and Full-length. It is still the SAME clone in all 3 types of microtiter plates, it has just made it's way through the pipeline. 5. Can I locate clones with specific 5' UTR sequence attributes? There is not a text search strategy for finding cDNA clones with particularly long, or otherwise unique 5' UTR sections with the Gene Search tool on our web site. There are other options, however. If you have the desired base pair sequence you can BLAST it against our clone collections to locate matches. The web tool is available here: http://dharmacon.gelifesciences.com//tools-and-calculators/blast-tool/ 6. Do you have suggestions for using Gene Search and BLAST tools to find cDNA clones? 1.) Performing a standard gene query using our gene search tool. a.) Use gene symbol(s), accession numbers, or clone IDs. Unfortunately, duplicates do exist so refer to the Oligo/Clone ID when identifying whether or not a clone is truly a duplicate. IMAGE ID is a unique identifier given to each cDNA clone by the I.M.A.G.E. Consortium. b.) cDNA clones are referenced against a GenBank accession number. Full length cDNA clone accessions typically begin with the ‘BC’ prefix. These clones have been derived from tissue, are fully sequenced (we guarantee the sequence will match NCBI’s record), and are different from RefSeq accession numbers (beginning with ‘NM_’ prefix). From NCBI’s website: “The Reference Sequence (RefSeq) database is a non-redundant collection of richly annotated DNA, RNA, and protein sequences from diverse taxa. The goal is to provide a comprehensive, standard dataset that represents sequence information for a species. It should be noted, though, that RefSeq has been built using data from public archival databases only. RefSeq biological sequences (also known as RefSeqs) are derived from GenBank records but differ in that each RefSeq is a synthesis of information, not an archived unit of primary research data. Similar to a review article in the literature, a RefSeq represents the consolidation of information by a particular group at a particular time.” c.) Clone IDs are IMAGE IDs, not MGC IDs. d.) Restriction enzymes, vector map, sequence, and other useful information is available by clicking on the blue "+" for each result opens tabs below including "details". e.) Clicking on the Accession number for each result opens the NCBI record on a new tab f.) Clicking on the vector in the "details" tab for each result opens the vector map”. ***** ****** ***** ***** 2.) Use our BLAST tool to find clones by amino acid or nucleotide sequence - also will find 'non-queryable' clones (We have cDNA collections whose data was not submitted to GenBank, thus the clones do not have GenBank accession numbers.) a.) Choose BLAST tType "Nucleotide" to work with nucleotide sequences. b.) When working with a protein sequence, choose "Peptide" for your BLAST Type. ***** ****** ****** ****** 3.) Using NCBI for BLAST and to find protein/gene information a.) http://www.ncbi.nlm.nih.gov/BLAST/ is the link for NCBI’s multiple BLAST options. As mentioned, you can search nucleotides using protein accession numbers and vice versa. At the bottom of the page is an option to perform a pairwise BLAST, which is aligning two sequences. http://www.ncbi.nlm.nih.gov/BLAST/bl2seq/wblast2.cgi b.) Searching on NCBI using gene name, gene symbol, accession number (either RefSeq or GenBank), or protein accession (NP_ for protein against NM_ or other prefix against GenBank accession number) offers numerous options for searching to find information. One of the most comprehensive views is via Entrez, which will provide all related sequences and proteins to that particular gene. 7. Can you get expression from a CMV promoter in mouse cells? Yes. The reference below shows CMV expression in mouse 3T3 and X63-Ag8.653 cells. Human c-fos Promoter Mediates High-Level, Inducible Expression in Various Mammalian Cell Lines. Biotechnol Bioeng 81: 848–854, 2003. Bi, et al. 8. Why are there multiple accession numbers for a cDNA clone? In short, all the accession numbers are relevant to the clone. Some records are the result of quick sequencing end reads and others from a full sequence read of the clone/insert. Full sequence read accessions always start with "BC". *Additional details IMAGE clones are generally sequenced on one end first (for newer clones it is the 5' end). This is because IMAGE makes MILLIONS of clones looking for full-length ones and it is too expensive to fully sequence all clones. So, they use the initial 5' end read as a screening tool to look for start codons and to see which clones are worth their time and money to fully sequence. Once they get that 5' end read, it gets a GenBank accession and the sequence is posted on GenBank. If they fully sequence a clone, that sequence also gets posted on GenBank and gets a different accession number. Full sequence reads always start with "BC". So, for clones that are fully sequenced, they should have a minimum of two sequence reads posted on GenBank. One is the initial 5' end read (which can start with anything except "NM", "XM", or "BC"). The other is the full sequence read of the clone - the one starting with "BC". 9. Where can I get Gene Ontology (GO) data? Can I buy a set of products based on a GO relationship? You can find GO data for genes from a variety of web based sources. *GO (http://www.geneontology.org/) *GOA (http://www.ebi.ac.uk/GOA/) *NCBI's RefSeq (http://www.ncbi.nlm.nih.gov/sites/entrez?db=gene) General resource for GO http://wiki.geneontology.org/index.php/Main_Page We can prepare a list of available expression or RNAi resources based on your GO terms of interest! We also have many pre-defined sets already available: http://www.openbiosystems.com/GeneSets/GeneFamiliesAndPathways/ Contact us for additiional information: http://www.openbiosystems.com/Support/ 10. What does an 8 digit IMAGE clone ID mean? Many of the 8 digit IMAGE clone ID numbers have been listed as "subject to analysis" by the IMAGE consortium. This means that they will not send these to the distributors unless the clones can be determined to be unique (no others contain the same sequence). We have to contact the IMAGE consortium/HAIB to ask whether or not we can get the individual clones. Customers may receive them if they are available to the distributor network. 11. Is my cDNA clone sense or antisense with respect to the gene? cDNA is made from RNA derived from a tissue of interest. The cDNA is double-stranded (thus containing sense and antisense strands with respect to the gene of interest). Each clone is inserted into a specific vector. Orientation can be determined by looking at the cloning sites listed in genbank (or the details of our clone query). Genbank lists sequences from 5' to 3'. An example is below: Clone 4504850 (BC014748) is cloned into pCMVSPORT6 at the SalI and NotI sites of the vector. The 5' end of the insert sits at the SalI site and the 3' end sits at the NotI site. By looking at the vector map, you can see that the CMV promoter in the vector is closest to the SalI site. The promoter should then theoretically read through the insert from 5'-3' end. If the complete protein coding sequence is present in the insert, the clone should theoretically express this protein in mammalian cells. (pCMVSPORT6 is a mammalian expression vector). The CMV promoter reads through the sense strand. **NOTE: We do not test our clones for expression so we do not guarantee protein expression. 12. How can I get information on any IMAGE produced cDNA clone? Below is an example of how to get information on any IMAGE cDNA clone. Put the catalog number, clone ID, or accession number associated with the clone you are interested in into the Search on our website. An example is catalog number MHS6278-202828338, clone ID 3506845, accession number BC000784. Click this link to query for this clone on our website: http://www.thermoscientificbio.com/search/?term=3506845 Click on the blue "+" to the left of the search result. For general cloning details, click on the appropriate tab in the query results to see details, sequence, resources, etc. Things to keep in mind: IMAGE clones were created using OligoDT priming and then directionally cloned into the various vectors using adaptors and ligators containing the restriction sites listed for each clone. These sites were used to clone the insert INTO the vector and we cannot make any guarantees that they will work to clone the insert OUT of the vector. You should always check the sequence of your insert for cut sites to ensure that you can use the restriction sites listed. To do this, go back to the search result for your cDNA clone using our Gene search and click on the BC accession number associated with your clone. The BC accession number is the sequence of the insert for this clone. Clicking on the BC accession from our website will take you to the NCBI record. Link to the BC accession number: http://www.ncbi.nlm.nih.gov/entrez/viewer.fcgi?db=nuccore&id=34783885 To check for restriction sites in the sequence of your insert, copy the insert sequence and then using a tool like Restriction Mapper (www.restrictionmapper.org), you can analyze the sequence for all or select restriction sites. To do this, go to the site above, paste your copied insert sequence into the box, select your enzymes, and then hit "map sites". This will show you the location of the requested restriction enzyme cut sites in your sequence. Another thing to keep in mind, is that the vector maps as posted on our website have been run through a general program that sometimes does not display all of the relevant cut sites for the clone. We have alternate maps available by request, or you can go back to the IMAGE website, click on "resources" and then "vector" to view maps and sequences of all vector used in the IMAGE collection. *IMAGE project status = terminated -image.llnl.gov is no longer available - The clone collections have been transfered to HAIB. The new IMAGE web site is http://www.imageconsortium.org/ For specific information that is not included on our website, you can look up the details submitted to IMAGE by the lab that created this clone. From the cloning details on our website, in the field labeled "Detailed Description", copy the library name. For this clone it is NIH_MGC_14. Go to the IMAGE website (http://www.imageconsortium.org/) click on the word "resources", and then the species for your clone, in this case "human". Now search for the library name on the page. In this case it is line 275. Click on the library name to view the information reported by the lab that created this clone. This is the most accurate and complete source of information for any IMAGE clone. If the info is not there it is not available. 13. What cDNA or ORF clone verification methods should be taken before and after purchase? The plate-row-column coordinates, DNA sequences, and annotations of our cDNA and ORF clones originate from the supplier and have not been independently verified by Dharmacon. We do, however, curate and act upon customer reported problems with clones. We therefore strongly recommend the following routine precautions: 1. Prior to purchase, the customer should analyze the GenBank sequence for the clone of interest using BLAST or other bioinformatics tools. 2. After purchase, the customer should end-sequence the clone and BLAST the result against the GenBank sequence. 14. What is the total plasmid map for my cDNA? We were not provided with complete maps for the clones in this collection, but the information on line can be used to create a map. You can find the details for your clone by clicking on the “+” sign next to your clone’s description. The first tab includes a hyperlink to the plasmid sequence as well as an indication of the 5’ and 3’ cloning restriction sites, and the second tab includes a link the clone’s insert sequence. 15. Do you sell the empty pCMV-SPORT6 vector? No, we do not. Dharmacon is the distributor of the IMAGE clone collection where some of the cDNA clones are cloned into the pCMV-SPORT6 vector but we did not do any of this cloning and did not have access to the empty pCMV-SPORT6 vector. The pCMV-SPORT6 vector is an Invitrogen vector so we would suggest contacting them for purchasing details. 16. Why does the pCMV-SPORT6 vector map that Dharmacon shows differ from what Invitrogen shows? The reason that the orientation of what is shown on the pCMV-SPORT6 vector map differs between Invitrogen and Dharmacon is because Invitrogen shows the minus (-) strand of the plasmid whereas Dharmacon shows the plus (+) strand. The reason that Dharmacon shows the pCMV-SPORT6 vector map this way is so that the promoter and cloning sites can visualized from left to right with respect to the way that most people view vector maps and sequences. 17. What antibiotic do I use to grow my cDNA clone? You can find the details for your clone by clicking on the “+” sign next to your clone’s description. The first tab includes information on the antibiotic and concentration to use for clone growth. 18. Why am I having trouble isolating any plasmid DNA from my clone? This could be a few things: 1. Bad antibiotic - check to see if bacteria that don't harbor the same resistance will grow/not grow in the media or on the plate. 2. Something wrong with the method of DNA prep - try to prep other plasmids using the same kit/reagents. Try to prep plasmids with the same antibiotic resistance. 3. No plasmid to prep - Use a method of 'colony cracking' where you take some of the culture, pop the bacteria and run it straight on a gel without prepping for clean plasmid. This will let you know if anything is there to prep. In general, clones should not be able to grow on a particular antibiotic if there is no plasmid expressing resistance. 19. Why don't I get the correct PCR product when using primers to amplify my gene with added restriction sites? If you are using a primer that adds a restriction site to the portion of DNA that you are trying to PCR, you need to use the Tm of just the portion of the primer that will initially bind in the first several rounds of PCR, then you can adjust the temperature to match the Tm for the entire primer. 20. I am having trouble dissolving my chloramphenicol into the media - any suggestions? Our lab recommends the following: Make a solution of chloramphenicol in 100% EtOH by shaking or vortexing to dissolve the antibiotic. Then just add the appropriate volume of this solution to your media. 21. Is it possible to use the BLAST tool on the website with multiple FASTA files? Yes, it is possible. Paste the FASTA of multiple sequences into the search for the BLAST. They need to be separated by headers like below: >SEQ1 ACGTTTCATATTTATAGCTACTTATTCACCT >SEQ2 GCCCTACATAAAACCCAGGAGTCA The results for each sequence can be seen by using the ‘next sequence’ or ‘previous sequence’ selection at the top of the BLAST result. The center label on the BLAST results page shows heading for the results that you are viewing (ex. "SEQ1"). The ‘Next Query’ hyperlink will allow you to see the results for the next header (ex. "SEQ2"), etc. 22. What is your cDNA clone guarantee? cDNA guarantee: Plate-row-column coordinates, accessions, DNA sequences, and annotations originate from the supplier and have not been independently verified by us. We will be responsible for replacing or crediting clones that clearly do not correspond to the associated clone ID, even though such errors almost always originate from the supplier organization (usually the IMAGE consortium). However, we will not be responsible for errors or changes in clone accessions, sequences, and annotations. The Unigene cluster ID for an EST is a particularly volatile (and untrustworthy) identifier and we will not replace a clone merely because this has been changed by the NCBI. 23. What is the insert and vector sequence for my cDNA? You can find the details for your clone by clicking on the “+” sign next to your clone’s description. The first tab includes a hyperlink to the plasmid sequence, and the second tab includes a link the clone’s insert sequence. 24. Where is the URL location of IMAGEne search 4.9 query page? LLNL decided to discontinue IMAGEne because it would have been nearly impossible to transfer to HAIB - it was way too unwieldy. LLNL recommended that customers use NCBI's Unigene program instead: http://www.ncbi.nlm.nih.gov/