2(b)
Naïve Baye’s classifier:
Consider the problem of classifying an object based on the evidence provided by the
feature vector x; A Naïve Baye’s classifier chooses a class that is most probable given the
feature vector x; In other words it maximizes the a posteriori probability. If we assume
that the priors are equal, then the likelihood is maximized;
For a simple two class case, if 1, 2 represent the two classes; x denotes an observation
then decide
Class label = 1 if P(1 | x) > P(2 | x)
Class label = 2 if P(1 | x) < P(2 | x);
In our case (as the features are discrete), the probabilities (priors and likelihood) can be
estimated using the counts of occurrence of each feature vector; For a continuous case
one could use the kernel density estimation techniques;
For instance
P(class = yes) = 9/14 = 0.64
P(class = no) = 5/14 = 0.36 appx
P(yes/sunny,hot,high,false) = 1/14;
(if the features are assumed to be independent, then the joint distributions can be spilt into
product of marginals); Estimation of N-d histogram is computationally expensive; So
independence assumption is generally used;
The experiment is repeated using a naïve baye’s classifier. Again, the test set is same as
the training set. Results indicate that decision tree performs better than the baye’s
classifier. Small number of samples may be the reason for the low classification rate
(inaccurate estimation of density); However, it is observed to be a little faster than the
decision trees which can be ignored for all practical purposes; One can asses the
computational complexity and resource requirement of each algorithm more accurately,
by using a larger dataset; Of the 14 samples that are used for testing, 13 of them are
correctly classified and 1 is incorrectly classified;
References:
(1) Pattern Classification by Duda, Hart and Stork, 2nd edition, ISBN: 0-471-05669-3;
(2) http://research.cs.tamu.edu/prism/lectures/pr/pr_l4.pdf
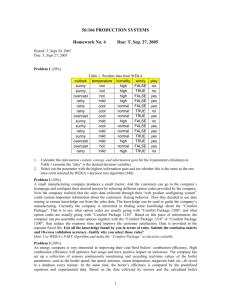
(1 b) Path to be chosen at each node is decided by the attribute value; the numbers at each
leaf denotes the number of occurrences of that selection (of attribute values);Attributes
are listed on top of each node; All the leaves are named after the classes;
(1 c)
@attribute keyword followed by the attribute name and the set values the attribute can
have
@attribute outlook {sunny, overcast, rainy}
@attribute temperature {hot, mild, cool}
@attribute humidity {high, normal}
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
(1 d)
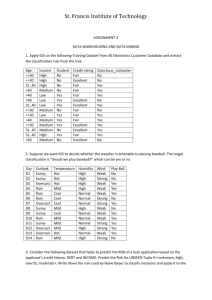
@data
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,no
overcast,hot,high,FALSE,yes
rainy,mild,high,FALSE,yes
rainy,cool,normal,FALSE,yes
rainy,cool,normal,TRUE,no
overcast,cool,normal,TRUE,yes
sunny,mild,high,FALSE,no
sunny,cool,normal,FALSE,yes
rainy,mild,normal,FALSE,yes
sunny,mild,normal,TRUE,yes
overcast,mild,high,TRUE,yes
overcast,hot,normal,FALSE,yes
rainy,mild,high,TRUE,no
(1 e) %
(1 f) 5 attributes (4 independent and 1 dependent)
(1 g) To Play or not is decided by the attributes outlook, temperature, windy, and
humidity; so {yes, no} are the two class labels;
(3a)
(3b)
(3c)
(3d)
Aode can handle only nominal attributes (weather.nominal.arff);
Linear regression handles numeric attributes (veteran.arff)
wNearest works for sonar.arff
Assosiations can handle Weather.nominal.arff
(3e) Aode – sonar.arff
(3f) Linear regression cannot handle discrete types. (weather.nominal.arff)
(3g) Clustering learners can handle everything as per the table; However I am not sure
how this will be able to handle missing attributes; Weka cannot even handle huge
datasets as it dumps everything into the memory;
(3h) Associations cannot handle numeric discrete attributes. (sonar.arff)
(4a) 11 ; lower bound = 0 is obtainted when Num = min; similarly Upperbound = N when
Num = max; {0,1,..N} =>N+1;
(4b &h) When M < N, I don’t see any potential problem except for the computational
overhead. So this could be avoided if we make the number of bins a function of the
number of unique values the attributes can take; nbins takes a log function; One could use
any monotonic function which would map the unique(i) to (1 to unique(i)); sucha s
sqrt[Doherty] , inversetan etc; Emperical Study conducted by doherty shows that the log
functions performance is comparable to the Fayyad Irani’s supervised entropy based
method; Authors mention that the SAS software uses the expression
max (1, 2*log(unique(i)) ; The max function ensures that the number of bins is positive;
The same expression can be used in the nbins code as well;
The underlying assumption for the method to work is that the data is uniformly
distributed. Several other methods are proposed in literature [Doherty] to handle nonuniform distributions. One simple way is apply a transform (log or tanh) to make the data
uniform if it is not uniform. This process is referred to as normalization in Biometrics
literature. Strictly speaking, any transformation would alter the joint density of the data
and so should affect the classification performance. How ever experimental evidences do
not show any significant influence on the performance of density based classification
schemes; however, these normalization or transformation greatly affects simple
combination rules and rules which make use of the distance metrics;
Inorder to understand the affect of the bin size on the classification accuracy,
One could conduct a simple experiment in which the error rate is calculated by varying
the bin size. The experimental results are as indicated
(4c) Inititally, data is being read and the max and min values of each attribute is being
calculated; Then these values are being used to quantize; if bin log is one then one would
use the adaptive scheme mentioned above; then the disctretised data is being written to a
new arff file.
(4d) round and label;
(4e) initially the continuos data is classified using naïve bayes; Later data is subjected to
discretisation and then is classified using the classifier again;
(4f) FS is the formation specifier; for the input; so the values with in this separator is
treated as one entity;
OFS this is the output field separator
Ignorecase would Ignore the case when set;
4(g) sub function in this code basically substituting the comments and other things with
next;
4(i) replace log(unique(i) with int(max(1,2*log(unique(i))) as is done in SAS;
Define the functions int, max;
 0
0