ICS 273A
Spring 2011
Homework 5
Read section 9.1 and 14.1, 14.2, 14.4 from Bishop
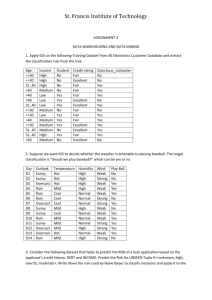
1) Imagine you have a dataset, X. You wish to send the data to a friend. You decide to
discover the regularities in the data by fitting a model. You send the model-specification
(say, the cluster means), a code-vector for each data-case (say, the assignment of each
data-case to a cluster) and the errors in predicting the data-case from the code and the
model (say, the vector xi zi ). Your objective is to send as few bits as possible
without losing any information (assuming you are only interested in knowing the data up
to finite precision or a fixed quantization level).
Argue why for small datasets you expect simple models to be optimal while for large
datasets you would expect more complex models to be optimal for this purpose.
2) Derive K-means from the cost function C (see slides) by showing that the two steps
correspond to coordinate descend on C with respect to the variables {z i , c } .
3) Is it possible for a probability density such as a normal density to have p(x) > 1?
4) Show that the K-means update equations is a special case of the EM update equations
(hint: take some limit).
Continues next page!
ICS 273A
Spring 2011
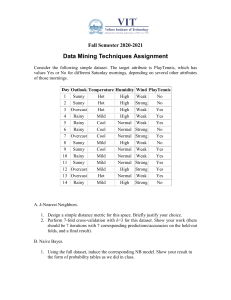
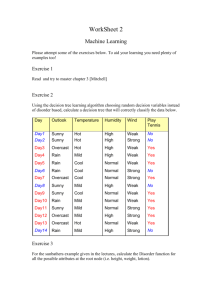
5) Consider the following table of observations:
No. Outlook Temperature Humidity Windy Play Golf?
1 sunny hot
high
false N
2 sunny hot
high
true
N
3 overcast hot
high
false Y
4 rain
mild
high
false Y
5 rain
cool
normal
false Y
6 rain
cool
normal
true
N
7 overcast cool
normal
true
Y
8 sunny mild
high
false N
9 sunny cool
normal
false Y
10 rain
mild
normal
false Y
11 sunny mild
normal
true
Y
12 overcast mild
high
true
Y
13 overcast hot
normal
false Y
14 rain
mild
high
true
N
From the classified examples in the above table, construct two decision trees (by hand) for
the classification "Play Golf." For the first tree, use Temperature as the root node. (This is a
really bad choice.) Continue, using your best judgment for selecting other attributes.
Remember that different attributes can be used in different branches on a given level of the
tree. For the second tree, follow the Decision-Tree-Learning algorithm. As your ChooseAttribute function, choose the attribute with the highest information gain. Work out the
computations of information gain by hand (or use MATLAB to do the computations for
you). Draw the decision tree.
2) Proof that if the same attribute appears twice in a decision tree, than the information gain
equals zero when you apply it for the second time. You should assume that it is possible
that other attributes are tested between the two applications of this attribute.
 0
0