hw4
advertisement

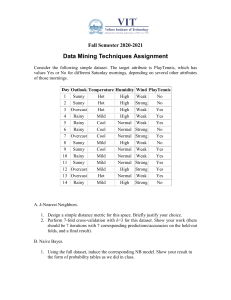
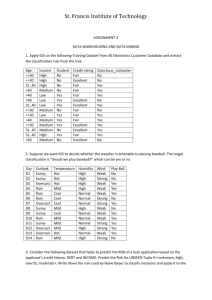
56:166 PRODUCTION SYSTEMS Homework No. 4 Due: T, Sep. 27, 2005 Posted: T, Sept 20, 2005 Due: T, Sept 27, 2005 Problem 1 (20%) Table 1. Weather data from WEKA outlook temperature humidity windy sunny hot high FALSE sunny hot high TRUE overcast hot high FALSE rainy mild high FALSE rainy cool normal FALSE rainy cool normal TRUE overcast cool normal TRUE sunny mild high FALSE sunny cool normal FALSE rainy mild normal FALSE sunny mild normal TRUE overcast mild high TRUE overcast hot normal FALSE rainy mild high TRUE 1. 2. play no no yes yes yes no yes no yes yes yes yes yes no Calculate the information content, entropy and information gain for the 4 parameters (features) in Table 1 (assume the “play” is the desired decision variable). Select out the parameter with the highest information gain and see whether this is the same as the one (tree root) selected by WEKA’s decision tree algorithm (J48). Problem 2 (30%) A small manufacturing company produces a small tractor. And the customers can go to the company’s homepage and configure their desired tractors by selecting different option codes provided by the company. Now the company realized that the sales data collected through their “web product configuring system” could contain important information about the customers’ buying behavior. Thus they decided to use data mining to extract knowledge out from the sales data. The knowledge can be used to guide the company’s manufacturing. Currently the company is interested in finding some knowledge about the “Comfort Package”. That is to say, what option codes are usually going with “Comfort Package 1200”, and what option codes are usually going with “Comfort Package 1210”. Based on this piece of information, the company can pre-assemble some options together with the “Comfort Package 1210” or “Comfort Package 1200”, thus reduce the response time and improve the customer satisfaction. Data is provided in the separate Excel file. List all the knowledge found by you in terms of rules. Submit the confusion matrix and 10-cross validation accuracy. Justify why you select those rules? Hint: Use WEKA’s PART Algorithm and make the “Comfort Package” as decision variable Problem 3 (30%) An energy company is very interested in improving their coal-fired boilers’ combustion efficiency. High combustion efficiency will optimize fuel usage and have positive impact on emissions. The company has set up a collection of sensors continuously monitoring and recording real-time values of the boiler parameters, such as the feeder speed, fan speed, pressure, steam temperature, megawatt load, etc., all saved to a database every minute. At the same time, the boiler’s efficiency is computed by the predefined equations and experimental data. Based on the data collected by sensors and the calculated boiler 1 efficiency, the company is going to apply data mining approach to find strong rules for improving the combustion efficiency. Thus the boiler operator can adjust the parameters’ value according to the strong rules (knowledge) which indicate higher efficiency levels. Use WEKA’s PART algorithm to mine the dataset 2 in the Excel file, find out the strong rules for each efficiency level. Submit the strong rules selected by you and justify why you select them? Problem 4 (10%) Apply the neural network model in WEKA to dataset 2, tune the parameters of neural network and see whether you can improve your 10-cross validation accuracy? (Try at least 3 settings of the parameters and report the corresponding cross-validation accuracies) Problem 5 (10%) Apply the simple k-means clustering algorithm in WEKA to the dataset 1 with 10 clusters. Try at least 3 different seeds and compare whether there are differences among the centroids? Report your cluster centroids and the corresponding seeds, and explanations. 2