emi412016-sup-0010-si
advertisement

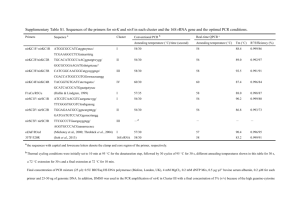
Materials and methods Sampling Using a remotely operated underwater vehicle (ROV) equipped with a hydraulic pump device, we collected samples of microbial mats from a actively venting hydrothermal chimney at a depth of approximately 2350 meters at the Loki’s Castle vent field (73°30´ N and 8°E) in June 2009. The samples were transported through the water column at ambient temperature (-0.7 °C – 2 °C) for approximately 2 hours. After arrival on the ship, the samples were kept on ice for less than 30 minutes before they were frozen in liquid nitrogen and stored at -80 °C until further processing. The sampling device was rinsed with sterile seawater between subsequent dives. Further processing of the samples, designated BSROV3 and BSROV4, were done in an onshore laboratory. DNA and RNA extraction Total DNA was extracted from the BSROV4 sample using the FastDNA spinkit for soil (MP Biomedicals). Total DNA and RNA from the BSROV3 was extracted from the same starting material using RNA power soil total RNA isolation kit and RNA power soil DNA elution accessory kit (MoBio Laboratories Inc.). As suggested by the manufacturer, we used a Phenol:Chloroform:Isoamyl-alcohol solution with pH 6.6 (Ambion). Amplification of 16S rRNA genes was performed as previously described (Roalkvam et al., 2011) using a two-step PCR approach. The first PCR step was run with less than 20 ng template in 25 cycle reactions using primers universal for Archaea and Bacteria - Un787f (50-ATTAGATACCCNGGTAG) (Roesch et al., 2007) and Un1392r (50-ACGGGCGGTGWGTRC) (modified from Lane et al., 1985). In order to minimize PCR bias, reactions were run in triplicates. The triplicate PCR products were pooled and rinsed with the MinElute PCR purification kit (Quiagen). In the second PCR step, approximately 20 ng PCR product from the first PCR step was used as template in a 5 cycle PCR reaction, using the same primers as used in the first step except that a sample specific MID sequence, and a GX FLX Titanium primer A was attached to the forward primer and GS FLX Titanium primer B was attached to the reverse primer. All PCR reactions were run in 25 µl reactions. PCR product quantification, rinsing of PCR products after the second PCR step and sequencing were performed as previously described (Roalkvam et al., 2011). cDNA synthesis The extracted RNA was treated with RNase-Free DNase (Promega) in order to remove any residual DNA. Conversion of RNA to cDNA was performed in triplicate via random hexamer priming and reverse transcription by applying the Superscript Double-Stranded cDNA synthesis Kit (Invitrogen) using the manufacturer’s protocol. The triplicate cDNA conversions were pooled and concentrated by vacuumcentrifugation (Eppendorf Concentrator 5301) to obtain 10 µl cDNA with a concentration of 119 ng/µl. The cDNA concentration was determined by SYBR-Green staining as previously described (Roalkvam et al., 2011). A total of 949 µg of double stranded cDNA was subjected to 454pyrosequencing at the Norwegian Sequencing Centre (http://www.sequencing.uio.no/). Sequence filtering and extraction of rRNA reads Removal of sequencing noise, PCR point error and chimeric sequences from the amplicon reads was performed using AMPLICONNOISE (Quince et al., 2011). Filtering of the cDNA reads was done in MOTHUR (Schloss et al., 2009) by removing sequences with one or more ambiguous bases, or which had an average quality score below 25. The filtered cDNA reads were compared to SSU and LSU rRNA gene sequences retrieved from the National Center for Biotechnological Information (NCBI) (http://www.ncbi.nlm.nih.gov/), using BLASTN (Altschul et al., 1997). Reads with a bitscore above 50 to any rRNA gene were regarded as derived from rRNA and extracted from the dataset by use of in house Perl scripts. OTU clustering, rarefaction and calculation of diversity indices The amplicon reads from both samples were concatenated and clustered in operational taxonomic units (OTUs) using AMPLICONNOISE (Quince et al., 2011) with the maximum linkage clustering algorithm and a 3 % cutoff. Chao1 estimates with confidence intervals were calculated using MOTHUR (Schloss et al., 2009). Other diversity indices and data for construction of rarefaction curves were calculated using the Vegan package in R. Taxonomic and functional analyses For taxonomic analyses of amplicon and rRNA derived cDNA reads, sequences were compared to the modified version of the Silva SSURef release 104 (Pruesse et al., 2007; Lanzén et al., 2011), using BLASTN. In this modified version the taxonomy within several taxa, including the Epsilonproteobacteria, is manually reviewed and edited (Lanzén et al., 2011). Non-rRNA derived cDNA sequences were compared to protein coding sequences in NCBI using BLASTX. BLASTN and BLASTX result files were uploaded to the MEGAN software (version 4.62.2) (Huson et al., 2011), which assigns reads to taxa using the last common ancestor (LCA) algorithm. For amplicon reads and rRNA derived cDNA reads we used a MEGAN bitscore threshold of 150 whereas for protein coding reads the MEGAN bitscore threshold was 50. In all analyses in MEGAN the minimum support parameter was set to 1. Otherwise the default parameters were used. Functional assignments of non-rRNA reads were done with MG-RAST (Meyer et al., 2008) and with BLASTX. The BLASTX searches were based on top hits and a bitscore treshold of 50. The database used in BLASTX searches was either NCBIs RefSeq protein or proteins from Sulfurovum sp. NBC37-1 only. The analyses in MG-RAST were performed using an e-value cutoff of 10-5 in searches against the SEED subsystems database. Phylogenetic analyses Phylogenetic analyses were performed in ARB (Ludwig et al., 2004) using the following approach: First, nearly full length 16S rRNA gene sequences (E.coli positions 28-1392) were used to make a backbone tree by applying the Neighbor-Joining algorithm (Saitou and Nei, 1987) with the Jukes-Cantor correction (Jukes and Cantor, 1969). Shorter sequences (OTU representatives from the amplicon datasets) were added to the tree using ARBs quick add option. The phylogenetic tree was constructed by applying a bacterial positional variability filter (pos_var_Bacteria_102). Deposition of sequence data All sequence data are publically available as raw data (sff files) in the Sequence Read Archive (SRA, http://www.ncbi.nlm.nih.gov/sra) under the accession number SRA051260. Non-rRNA sequences are publically available from MGRAST (http://metagenomics.anl.gov/) under the accession number 4460441.3. A fasta file of one representative sequence of each OTU constructed from the 16S rRNA gene amplicon analyses is available as supplementary material. References Altschul, S.F., Madden, T.L., Schäffer, A.A., Zhang, J., Zhang, Z., Miller, W., and Lipman, D.J. (1997) Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res 25: 3389-3402. Huson, D.H., Mitra, S., Ruscheweyh, H.-J., Weber, N., and Schuster, S.C. (2011) Integrative analysis of environmental sequences using MEGAN4. Genome Res 21: 1552-1560. Jukes, T.H., and Cantor, C.R. (1969) Evolution of protein molecules. In Mammalian protein metabolism. Munro, H.N. (ed). New York: Academic Press, pp. 21-132. Lane, D.J., Pace, B., Olsen, G.J., Stahl, D.A., Sogin, M.L., and Pace, N.R. (1985) Rapid determination of 16S ribosomal RNA sequences for phylogenetic analyses. PNAS 82: 6955-6959. Lanzén, A., Jørgensen, S.L., Bengtsson, M.M., Jonassen, I., Øvreås, L., and Urich, T. (2011) Exploring the composition and diversity of microbial communities at the Jan Mayen hydrothermal vent field using RNA and DNA. FEMS Microbiol Ecol 77: 577-589. Ludwig, W., Strunk, O., Westram, R., Richter, L., Meier, H., Yadhukumar et al. (2004) ARB: a software environment for sequence data. Nuc Acids Res 32: 1363-1371. Meyer, F., Paarmann, D., D'Souza, M., Olson, R., Glass, E.M., Kubal, M. et al. (2008) The metagenomics RAST server: a public resource for the automatic phylogenetic and functional analysis of metagenomes. BMC Bioinformatics 9. Pruesse, E., Quast, C., Knittel, K., Fuchs, B.M., Ludwig, W., Peplies, J., and Glöckner, F.O. (2007) SILVA: a comprehensive online resource for quality checked and aligned ribosomal RNA sequence data compatible with ARB. Nuc Acids Res 35: 7188-7196. Quince, C., Lanzen, A., Davenport, R., and Turnbaugh, P. (2011) Removing noise from pyrosequenced amplicons. BMC Bioinformatics 12: 38. Roalkvam, I., Jørgensen, S.L., Chen, Y., Stokke, R., Dahle, H., Hocking, W.P. et al. (2011) New insight into stratification of anaerobic methanotrophs in cold seep sediments. FEMS Microbiol Ecol 78: 233-243. Roesch, L.F.W., Fulthorpe, R.R., Riva, A., Casella, G., Hadwin, A.K.M., Kent, A.D. et al. (2007) Pyrosequencing enumerates and contrasts soil microbial diversity. ISME J 1: 283-290. Saitou, N., and Nei, M. (1987) The neighbor-joining method: a new method for reconstructing phylogenetic trees. Mol Biol Evol 4: 406-425. Schloss, P.D., Westcott, S.L., Ryabin, T., Hall, J.R., Hartmann, M., Hollister, E.B. et al. (2009) Introducing mothur: Open-source, platform-independent, communitysupported software for describing and comparing microbial communities. Appl Environ Microbiol 75: 7537-7541.