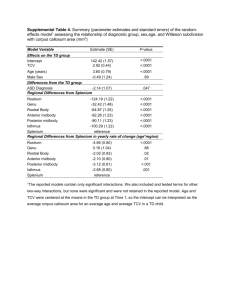
Supplementary Information (doc 495K)
advertisement
")
1 Supplemental material 2 Gene by stress genome-wide interaction analysis and path 3 analysis identify EBF1 as a cardiovascular and metabolic 4 risk gene 5 Abanish Singh1,2,4, *, Michael A. Babyak1,4, Daniel K. Nolan2, Beverly H. Brummett1,4, Rong 6 Jiang1,4 , Ilene C. Siegler1,4, William E. Kraus2,3,6, Svati H. Shah2,3, Redford B. Williams1,4, 7 Elizabeth R. Hauser2,3,5 8 1 Behavioral Medicine Research Center, Duke University Medical Center, Durham, NC 9 2 Center for Human Genetics, Duke University Medical Center, Durham, NC 10 3 Department of Medicine, Duke University Medical Center, Durham, NC 11 4 Department of Psychiatry and Behavioral Sciences, Duke University Medical Center, 12 Durham, NC 13 5 14 Affairs Medical Center, Durham, NC, USA 15 6 16 *Correspondence: 17 Abanish Singh, Ph.D. 18 Duke University Medical Center, Duke Box 3445 19 905 LaSalle St. Durham, NC 27710 20 Tel: +1 919 681 2133 Fax: +1 919 684 0934 21 Email: abanish.singh@duke.edu Durham Epidemiologic Research and Information Center, Durham Veterans Duke Center for Living, Duke University Medical Center, Durham, NC 1 22 Study Populations and Phenotypes 23 Discovery Dataset: We obtained the publicly available Multi-Ethnic Study of Atherosclerosis 24 (MESA) Cohort GWAS dataset from dbGaP under the standard data user agreement and Duke 25 IRB approval. The MESA GWAS data set includes a total of 8,227 samples (3,790 males, 4,437 26 females), including White, Chinese American, Black, and Hispanic ancestries. We chose the 27 MESA dataset for testing the GxE interaction hypothesis based on the availability of a well- 28 characterized phenotype psychosocial stress chronic burden (i.e. chronic psychosocial stress) that 29 was quantified on an ordinal scale of 0 to 5 (0, 1, 2, 3, 4, and 5) based on questionnaires in five 30 domains including questions about ongoing serious health problems, serious health problems 31 with someone close, work related problems, financial strains, and difficulties in relationships. 32 The severity of stress was rated based on how stressful (not very, moderately or very stressful) 33 each problem was perceived to be by the participant, and classified as chronic for each of the 34 five domains if the problem was experienced for at least 6 months. 35 We were interested in the relationship between genes and stress in modifying CVD risk 36 factors and common carotid intimal-media thickness, a surrogate marker for atherosclerosis that 37 is a strong predictor of future vascular events. Thus, we included measures of central obesity, 38 hip circumference (HIPCM), body mass index (BMI), waist circumference (WAISTCM), along 39 with fasting glucose (GLUC), triglycerides (TRIG), low-density lipoprotein (LDL), high-density 40 lipoprotein (HDL), systolic blood pressure (SYSTBP), diastolic blood pressure (DIASTBP), type 41 II diabetes status (DIABSTAT), common carotid intimal-media thickness (CCIMT), and chronic 42 psychosocial stress (STRESS). Table 1 provides the summary of these traits in the MESA exam 43 1 data. A total of 5,805 individuals had both phenotype and quality controlled genotype data 44 available, comprised of 2,460 Whites (1,174 Male, 1,286 Female), 548 Chinese Americans (359 2 45 Male, 189 Female), 1,547 Blacks (721 Male, 826 Female), and 1,250 Hispanics (630 Male, 620 46 Female). For all the selected traits we checked for departure from normality using STATA SE 47 11.1 and performed a transformation to achieve approximate normality within each ancestry. 48 For Whites, we performed log transformation for waist circumference, triglyceride, HDL, 49 systolic and diastolic blood pressures; square root inverse transformation for BMI; inverse 50 transformation for glucose; and square root transformation for LDL. Hip circumference and 51 common carotid intimal-media thickness did not require transformation. Also in the GxE 52 GWAS for hip circumference, we performed an inverse transformation in Chinese Americans, 53 and square inverse transformation in Blacks and Hispanics. 54 Replication Dataset: We obtained the publicly available Framingham Cohort dataset under the 55 standard data user agreement and Duke IRB approval and used Generation 2 (or Offspring) 56 dataset for our replication analysis. The original Framingham Study started in 1948 with the 57 recruitment of 5,209 men and women between the ages of 30 and 62 from the town of 58 Framingham, Massachusetts. In 1971, 5,124 adult children and their spouses were enrolled in the 59 Offspring cohort in Framingham Study. The cohort is primarily white including 2,483 males and 60 2,641females. A total of 3,157 individuals had both phenotype and quality controlled genotype 61 data available, comprised of 1,515 males and 1,642 females. 62 We used selected replication phenotypes hip girth (HIPGIRTH), waist girth 63 (WAISTGIRTH) from exam 4, average of body mass index (BMI), glucose (GLUC), diabetes 64 status (DIABSTAT ) from exam 3 and 4 (hip girth and waist girth was not available in exam 3), 65 and common carotid IMT (CCIMT) from exam 6. We used a computed ordinal measure of 66 chronic psychosocial stress (STRESS) as the sum of indicators of financial strain, marital 67 problems, work related difficulties, and health problems of someone close from the exam 3 3 68 psychosocial data, employing a generalized stress calibration computational method (Singh et 69 al., unpublished). We did not use self health problem and disease status (such as CVD and 70 diabetes) to infer corresponding stress indicator as it would have been confounding in the 71 interaction analysis, unlike in MESA where it was based on a questionnaire. The stress measure 72 ranged from 0-3. Table S1 in Supplemental Material provides the summary of these variables 73 along with age and sex. We checked for departure from normality using STATA SE 11.1 and 74 performed a transformation to achieve approximate normality: log transformation for hip girth 75 and BMI, square root transformation for waist girth, cube inverse transformation for glucose and 76 inverse transformation for common carotid IMT. To adjust analysis for the family relatedness, 77 we implemented robust Huber-White familial clustering using family ID. 78 SNP Data and Quality Control Procedure 79 Discovery Dataset: We used the SNP data from the MESA SNP Health Association Resource 80 (SHARe). Funding for SHARe genotyping was provided by NHLBI Contract N02-HL-64278. 81 The genotyping was performed at Affymetrix (Santa Clara, California, USA) and the Broad 82 Institute of Harvard and MIT (Boston, Massachusetts, USA) using the Affymetrix Genome-Wide 83 Human SNP Array 6.0. The total number of SNPs was 909,622. We performed standard quality 84 control procedures as implemented in PLINKS1 v1.07. Our quality control criteria were: 85 minimum minor allele frequency (MAF) of 0.01 (1%), maximum missing genotypes of 0.05 86 (5%) per individual, maximum missing individuals per SNP of 0.05 (5%), and significant 87 departure from Hardy-Weinberg equilibrium (HWE) (P<0.00001). The 11,748 SNPs failed 88 frequency test, 6,755 SNPs failed missing individual SNPs, and 365,902 SNPs were excluded 89 based on HWE test. The final number of SNPs used in the GxE GWAS was 528,298. We 90 estimated principal components (PCs) based on 162,072 LD-pruned SNPs in each ethnic group 4 91 using EIGENSTRATS2 and used five PCs in Whites, five PCs in Chinese Americans, three PCs 92 in Blacks, and three PCs in Hispanics based on eigenvalue scree plots. 93 Replication Dataset: We used SNPs from the Framingham SNP Health Association Resource 94 (SHARe). Funding for Framingham SHARe Affymetrix genotyping was provided by NHLBI 95 Contract N02-HL-64278. SHARe Illumina genotyping was provided under an agreement 96 between Illumina and Boston University using Affymetrix Mapping250K (Nsp and Sty) Arrays 97 and Mapping50K (Hind240 and Xba240) Arrays. Although we used only a couple of selected 98 SNPs in our analysis, we performed similar quality control as described above before selecting 99 SNPs. There were a total of 549,782 SNPs, 20,825 SNPs were excluded based on HWE test, 100 37,756 SNPs failed missing individual test, and 66,965 SNPs failed frequency test. We estimated 101 principal components (PCs) based on 95,650 LD-pruned SNPs using EIGENSTRATS2 and used 102 five PCs based on eigenvalue scree plot. 103 Structural equation path analysis 104 We were interested in the correlation structure among the related phenotypes when assuming a 105 particular model of interaction among chronic stress and genetic variation. In addition to 106 comparing genotypes on the magnitude of zero-order correlations among the variables under 107 study, we expanded our analysis of the correlations for MESA White and Framingham Offspring 108 Cohorts in Tables S9 and S10 by using them to estimate a path model. Path modelling provides 109 several pieces of information over and above the raw correlations. We used a structural equation 110 path analysis as implemented in MplusS3 version 6.11 to evaluate possible mediated causal 111 pathsS4 from stress through risk factors to CCIMT. Path analysis uses a series of simultaneous 112 equations to estimate possible mediating paths. For example, if it is hypothesized that the 113 association between x and y is mediated by the variable m, the mediated or indirect effect of x on 5 114 y can be estimated by the simultaneous equations y = b1*x + b2*m and m = b3*x, where b 115 represents a regression slope. The indirect effect can be represented graphically as: x → m → y, 116 where the directed (single-headed) arrows represent the regression slope between two variables 117 involved. The magnitude of a mediating effect is then calculated by taking the product of all 118 path coefficients along a given proposed path. In the example above, the indirect effect would be 119 the product of b2 and b3. The standard error for the product is then used to test the null 120 hypothesis that the product is zero. 121 For our analysis, the model can be expressed as three simultaneous equations: CCIMT = 122 g1*Glucose + g2*Hip Circumference + g3*Stress + g4*Age + g5*Male; Glucose=g6*Hip 123 Circumference + g7*Stress + g8*Age + g9*Male; and Hip Circumference =g10*Stress + 124 g11*Age + g12*Male. In each equation the term on the left is equivalent to the dependent 125 variable in a regression-type model, while the terms of the right are the predictor variables. The 126 terms g1 through g12 represent the association of the corresponding predictor with the dependent 127 variable, adjusted for all other variables in a given equation. For example, g1 is the slope 128 coefficient of the association between Stress and CCIMT, adjusted for Glucose, Hip 129 Circumference, Age, and Sex. (Stress, Hip Circumference, Glucose, and CCIMT were adjusted 130 for ancestry prior to analysis). The three path model equations also imply three mediated effects 131 from stress to CCIMT: stress chronic burden ⇒ hip circumference ⇒ CCIMT; stress chronic 132 burden ⇒ glucose ⇒ CCIMT; and stress chronic burden ⇒ hip circumference ⇒ glucose ⇒ 133 CCIMT. The model was estimated simultaneously for the TT and CT/CC groups using 1000 134 bootstrap samples to generate standard errors. 135 6 136 137 Figures 138 Figure S1: Q-Q plot of GxE GWAS on Hip Circumference (HIPCM) in MESA Whites where 139 the environmental factor (E) was chronic psychosocial stress (STRESS). This plot demonstrated 140 a departure of the observed P-values from the assumed distribution (inflation factor 1.1524), 141 therefore, we performed genomic control as shown in Figure S2. 142 143 7 144 145 Figure S2: Genomic control Q-Q plot of GxE GWAS on Hip Circumference (HIPCM) in MESA 146 Whites where the environmental factor (E) was chronic psychosocial stress 147 (STRESS). 148 149 8 150 151 Figure S3: Manhattan plot of GxE GWAS on Hip Circumference (HIPCM) in MESA Chinese- 152 Americans where the environmental factor (E) was chronic psychosocial stress (STRESS). 153 154 9 155 156 Figure S4: Manhattan plot of GxE GWAS on Hip Circumference (HIPCM) in MESA Blacks 157 where the environmental factor (E) was chronic psychosocial stress (STRESS). 158 159 10 160 161 Figure S5: Manhattan plot of GxE GWAS on Hip Circumference (HIPCM) in MESA Hispanics 162 where the environmental factor (E) was chronic psychosocial stress (STRESS). 163 164 11 165 166 Figure S6: LocusZoomS5 plot of chromosome 5 (156mb-160mb) region around the EBF1 gene 167 which includes the five most significant EBF1 SNPs of MESA Whites GxE GWAS. 168 169 170 12 171 172 Figure S7: The plot shows age (years) group-wise mean and SE bars of raw values of CCIMT 173 (mm) in Framingham Offspring cohort and MESA White in panel A, and number of individuals 174 in each age group for the two datasets in panel B. 175 176 13 177 Figure S8: Mean hip circumference stratified by chronic stress and rs4704963:T>C carrier status 178 in the four ethnic groups of the MESA dataset for samples having QC genotype and phenotype 179 data. 180 14 181 Tables 182 Table S1: Summary of phenotypic traits in Framingham Offspring for the samples having 183 quality-controlled genotype data. Trait Mean (SD) Min – Max AGE (Years) 47.76 (9.89) 18 – 77 SEX (M / F) 47.99% / 52.01% Binary (1/2) HIPGIRTH (Inches) 40.03 (3.84) 30 – 64 WAISTGIRTH (Inches) 35.22 (5.71) 22 – 57 BMI (kg/m^2) 26.49 (4.63) 15 – 60.37 GLUC (mg/dl) 94.55 (20.63) 64 – 306 DIABSTAT (N/D*) 87.76% / 12.24% Binary (0/1) CCIMT (mm) 0.59 (0.18) 0.29 –3.23 STRESS (Score) 0.84 (0.79) 0–3 *Normal/Disease 184 15 185 186 Table S2: The GxE P-values (P-val) and MAF of ten SNPs with the lowest P-values (top hits) 187 from MESA Whites GxE GWAS on Hip Circumference (HIPCM). The Table also shows GxE 188 P-values and MAF of these ten SNPs in other ancestries – i.e. Chinese American, Blacks, and 189 Hispanics. The environment (E) component in this GWAS was chronic psychosocial stress 190 (STRESS). SNPs significant at Bonferroni correction threshold are shown in bold. All genomic 191 locations were numbered based on Genome Reference Consortium Human Build 37 patch 192 release 10 (GRCh37.p10). rs4704963 Gene Type POS AND ALLELE CHANGE CHR SNP 193 Whites P-val Chinese MAF P-val MAF Blacks Hispanics P-val MAF P-val MAF 5 g.158247378T>C Intronic EBF1 7.14E-09 0.07 0.66 0.07 0.87 0.02 0.87 0.05 rs17056278 5 g.158252438C>G Intronic EBF1 7.14E-09 0.07 0.66 0.07 0.87 0.02 0.74 0.05 rs17056298 5 g.158268679C>G Intronic EBF1 1.30E-08 0.06 0.52 0.06 0.90 0.02 0.51 0.05 rs10077799 5 g.158272083T>C Intronic EBF1 1.71E-08 0.06 0.51 0.06 0.65 0.05 0.66 0.06 rs17056318 5 g.158285953T>C Intronic EBF1 2.33E-08 0.07 0.52 0.05 0.53 0.02 0.91 0.06 1.15E-07 0.48 0.61 0.48 0.15 0.29 0.26 0.36 - 0.001 0.051 0.01 0.36 0.04 rs686708 6 g.117091683T>C Upstream GPRC6A rs1536274 14 g.67824636C>T Intronic ATP6V1D 3.37E-07 0.07 rs10872796 6 g.104685134T>G Intergenic N/A 4.93E-07 0.28 0.17 0.01 0.22 0.21 0.88 0.29 rs10092697 8 g.57960820C>T 8.71E-07 0.34 0.43 0.37 0.96 0.46 0.60 0.33 1.13E-06 0.29 0.45 0.29 0.10 0.26 0.12 0.31 rs7763618 Intergenic N/A 6 g.148621930A>C Intronic SASH1 194 16 195 196 Table S3: Ten SNPs with the lowest P-values (top hits) from GxE GWAS on Hip 197 Circumference (HIPCM) in MESA Chinese Americans. The environment (E) component in this 198 GWAS was chronic psychosocial stress (STRESS). All genomic locations in this and 199 subsequent Talbles were numbered based on Genome Reference Consortium Human Build 37 200 patch release 10 (GRCh37.p10). SNP CHR POS & ALLELE Type Gene MAF P-val rs907349 12 g.51789449C>T Intronic SLC4A8 0.28 2.50E-05 rs2180086 14 g.94444787A>G 5Upstream ASB2 0.013 4.06E-05 rs3749107 2 g.109539774G>A Intronic EDAR 0.012 5.09E-05 rs4905125 14 g.94442455C>T Intronic ASB2 0.014 7.73E-05 rs4939458 11 g.60564804A>G Intronic MS4A10 0.144 1.07E-04 rs10897113 11 g.60556218G>A Intronic MS4A10 0.141 1.13E-04 rs10775622 19 g.17230199C>T Intronic MYO9B 0.30 1.46E-04 rs654680 11 g.63361442G>C Intronic PLA2G16 0.49 1.51E-04 rs13158501 5 g.15261054G>A Non-cod intronic RP1-137K24.1 0.043 1.63E-04 rs1790361 11 g.71118568A>C Non- cod intronic AP002387.1 0.16 1.64E-04 201 17 202 203 Table S4: Ten SNPs with the lowest P-values (top hits) from GxE GWAS on Hip 204 Circumference (HIPCM) in MESA Blacks. The environment (E) component in this GWAS was 205 chronic psychosocial stress (STRESS). 206 SNP CHR POS & ALLELE Type Gene MAF P-val rs4427965 2 g.214802528C>T Intronic SPAG16 0.20 1.12E-05 rs12443351 15 g.98673011G>A Intergenic N/A 0.064 1.16E-05 rs3748358 14 g.21789794G>A Intronic RPGRIP1 0.22 2.21E-05 rs12265226 10 g.25670435G>A Intronic GPR158 0.19 2.51E-05 rs6052830 20 g.4729789G>C Intergenic N/A 0.25 2.58E-05 rs12867694 13 g.43902183C>T Intronic ENOX1 0.014 2.82E-05 rs6037950 20 g.4731022C>T Intergenic N/A 0.24 2.82E-05 rs17071864 3 g.64939606T>C Non-cod intronic CTD-2230D16.1 0.12 3.03E-05 rs12061877 1 g.147264252T>C Intergenic N/A 0.12 3.20E-05 rs2022211 2 g.36801857T>C Intronic FEZ2 0.40 3.44E-05 207 18 208 209 Table S5: Ten SNPs with the lowest P-values (top hits) from GxE GWAS on Hip 210 Circumference (HIPCM) in MESA Hispanics. The environment (E) component in this GWAS 211 was chronic psychosocial stress (STRESS). 212 213 SNP CHR POS & ALLELE Type Gene MAF P-val rs7094310 10 g.6791034C>G Intergenic N/A 0.036 1.68E-06 rs11254430 10 g.6795454G>A Intergenic N/A 0.036 2.49E-06 rs564309 1 g.228585562C>A Intronic TRIM11 0.064 4.32E-06 rs7863100 9 g.18640590T>C Intronic ADAMTSL1 0.22 8.44E-06 rs13115750 4 g.182480575G>C Intergenic N/A 0.28 8.71E-06 rs2571342 12 g.94317979C>T Non-cod intronic RP11-1060G2.1 0.33 1.43E-05 rs2827258 21 g.23521786A>G Intergenic N/A 0.075 1.78E-05 rs17084244 18 g.69017186A>G Intergenic N/A 0.028 1.90E-05 rs2888734 12 g.103846180G>T Intronic C12orf42 0.14 2.27E-05 rs17281463 20 g.40278357G>C Intergenic N/A 0.020 2.58E-05 214 19 215 216 Table S6 : The SNP term (G) and gene-by-stress interaction term (GxE) terms P-values of the 5 217 most significant GxE GWAS SNPs (Table 3) in MESA Whites hip circumference (HIPCM), 218 waist circumference (WAISTCM), body mass index (BMI), fasting glucose (GLU), type II 219 diabetes status (DIABSTAT), common carotid intimal-media thickness (CCIMT), high-density 220 lipoprotein (HDL), systolic blood pressure (SYSTBP), diastolic blood pressure (DIASTBP), 221 low-density lipoprotein (LDL), and triglycerides (TRIG). SNP→ PHENO↓ rs4704963:T>C G / GxE P-val rs17056278:C>G G / GxE P-val rs17056298:C>G G / GxE P-val rs10077799:T>C G / GxE P-val rs17056318:T>C G / GxE P-val HIPCM 0.0154 / 7.14E-09 0.0154 / 7.14E-09 0.01907 / 1.30E-08 0.02305 / 1.72E-08 0.0318 / 2.33E-08 WAISTCM 0.1853 / 3.47E-05 0.1853 / 3.47E-05 0.2332 / 6.00E-05 0.2658 / 7.52E-05 0.3357 / 9.67E-05 BMI 0.398 / 0.0007209 0.398 / 0.0007209 0.4618 / 0.000936 0.5348 / 0.001239 0.6487/ 0.001658 GLU 0.06293 / 0.00015 0.0629 / 0.00015 0.04528 / 7.32E-05 0.1132 / 0.000244 0.1012/ 0.00114 DIABSTAT 0.941 / 0.01723 0.941 / 0.01723 0.777 / 0.009345 0.9641 / 0.01706 0.9173 / 0.03232 CCIMT 0.7167 / 0.2518 0.7167 / 0.2518 0.9524 / 0.1704 0.9638 / 0.173 0.9228 / 0.222 HDL 0.626 / 0.14 0.626 / 0.14 0.4397 / 0.1061 0.4807 / 0.1168 0.4696 / 0.2769 SYSTBP 0.7522 / 0.2128 0.7522 / 0.2128 0.5462 / 0.1164 0.6196 / 0.1351 0.4142 / 0.07616 DIASTBP 0.6969 / 0.4003 0.6969 / 0.4003 0.5799 / 0.3279 0.6096 / 0.3432 0.5609 / 0.5064 LDL 0.1057 / 0.348 0.1057 / 0.348 0.1825 / 0.5857 0.2046 / 0.619 0.2482 / 0.7256 TRIG 0.6309 / 0.6295 0.6309 / 0.6295 0.5398 / 0.6925 0.429 / 0.7873 0.5734 / 0.8064 222 20 223 224 Table S7: SNP term (G), chronic stress term (E) and gene-by-stress interaction term (GxE) beta 225 (β) and P-values for GxE GWAS lead SNP rs4704963:T>C in MESA Whites phenotypes: waist 226 circumference (WAISTCM), body mass index (BMI), fasting glucose (GLU), type II diabetes 227 status (DIABSTAT), common carotid intimal-media thickness (CCIMT), high-density 228 lipoprotein (HDL), systolic blood pressure (SYSTBP), diastolic blood pressure (DIASTBP), 229 low-density lipoprotein (LDL), and triglycerides (TRIG). PHENO Transformation Beta(G) P-val(G) Beta(E) P-val(E) Beta(GxE) P-val(GxE) -2.06 -1.50E-02 1.54E-02 1.85E-01 4.31E-01 9.19E-03 2.58E-02 6.24E-04 2.98 2.96E-02 7.14E-09 3.47E-05 BMI Square Root Inverse 1.15E-03 3.98E-01 -1.06E-03 6.16E-04 -2.79E-03 7.21E-04 GLU Inverse 2.45E-04 6.29E-02 -5.10E-05 8.81E-02 -3.02E-04 1.50E-04 DIABSTAT Identity 9.74E-01 9.41E-01 1.34 2.30E-04 1.48 1.72E-02 CCIMT Identity 5.19E-03 7.17E-01 4.57E-03 1.59E-01 9.89E-03 2.52E-01 HDL Logarithmic 1.04E-02 6.26E-01 -4.66E-03 3.35E-01 -1.90E-02 1.40E-01 SYSTBP Logarithmic -3.89E-03 7.52E-01 4.52E-04 8.72E-01 9.28E-03 2.13E-01 DIASTBP Logarithmic -4.35E-03 6.97E-01 -5.95E-04 8.15E-01 5.68E-03 4.00E-01 LDL Square Root -1.90E-01 1.06E-01 -4.40E-02 1.01E-01 6.67E-02 3.48E-01 TRIG Logarithmic 2.12E-02 6.31E-01 2.84E-02 4.60E-03 1.29E-02 6.30E-01 HIPCM Identity WAISTCM Logarithmic 230 21 231 232 Table S8: Replication analysis in the Framingham Offspring Cohort: The Table includes P- 233 values of the SNP term (G P-val) and gene-by-stress interaction term (GxE P-val) in the 234 interaction model on analysis for six phenotypes under study ( Figure 1B) from Framingham 235 Offspring Cohort, i.e. Hip Girth, Waist Girth, body mass index (BMI), fasting glucose (Gluco), 236 type II diabetes status (Diab Status), and common carotid intimal-media thickness (CCIMT), and 237 three of the five most significant MESA GxE GWAS (Table 3) SNPs. The Table also includes 238 P-values of the SNP-only Model (SNP P-val) i.e. the conventional model with no interaction 239 term for these SNPs. rs17056278:C>G Phenotype Transformation rs17056298:C>G rs17056318T>C SNP G GxE SNP G GxE SNP G GxE P-val P-val P-val P-val P-val P-val P-val P-val P-val HipGirth Logarithmic 0.308 0.097 0.007 0.230 0.169 0.012 0.152 0.215 0.008 WaistGirth Square Root 0.099 0.272 0.001 0.063 0.406 0.002 0.034 0.502 0.001 BMI Logarithmic 0.152 0.354 0.011 0.148 0.322 0.008 0.111 0.315 0.003 Gluco Cube Inverse 0.887 0.522 0.343 0.740 0.597 0.335 0.507 0.752 0.312 Diab Status Identity 0.351 0.442 0.041 0.318 0.467 0.039 0.261 0.522 0.039 CCIMT Inverse 0.571 0.603 0.960 0.475 0.624 0.887 0.362 0.655 0.647 240 241 22 242 243 Table S9: Comparison of correlations between the study variables from Figure 1B pathway 244 model for TT and CT/CC genotype groups of EBF1 SNP rs4704963:T>C using MESA Whites 245 data. aP-value for null hypotheses that rho=0, bP-value calculated using Fisher’s z- 246 transformation for null hypothesis rho1-rho2=0. TT Group CT/CC Group Difference Var 1 Var 2 Rho1 a P-value Rho2 a P-value b P-value STRESS HIPCM 0.06 0.003 0.27 <.0001 <.0001 STRESS WAISTCM 0.02 0.383 0.20 <.0001 0.002 STRESS BMI 0.06 0.004 0.20 <.0001 0.019 STRESS GLUC -0.03 0.172 0.08 0.153 0.068 STRESS DIABSTAT 0.06 0.009 0.12 0.038 0.323 STRESS CCIMT -0.08 0.0004 -0.05 0.415 0.609 HIPCM BMI 0.85 <.0001 0.87 <.0001 0.180 HIPCM GLUC 0.24 <.0001 0.20 <.0001 0.515 HIPCM DIABSTAT 0.14 <.0001 0.20 0.001 0.352 HIPCM CCIMT 0.12 <.0001 0.04 0.447 0.181 WAISTCM HIPCM 0.77 <.0001 0.82 <.0001 0.059 WAISTCM BMI 0.86 <.0001 0.87 <.0001 0.479 WAISTCM GLUC 0.39 <.0001 0.36 <.0001 0.565 WAISTCM DIABSTAT 0.21 <.0001 0.25 <.0001 0.517 WAISTCM CCIMT 0.24 <.0001 0.16 0.005 0.133 BMI GLUC 0.34 <.0001 0.29 <.0001 0.389 BMI DIABSTAT 0.19 <.0001 0.24 <.0001 0.388 BMI CCIMT 0.18 <.0001 0.10 0.070 0.174 GLUC DIABSTAT 0.36 <.0001 0.45 <.0001 0.091 GLUC CCIMT 0.21 <.0001 0.30 <.0001 0.095 DIABSTAT CCIMT 0.13 <.0001 0.23 <.0001 0.091 247 248 23 249 250 Table S10: Comparison of correlations between the study variables from Figure 1B pathway 251 model for CC and GC/GG genotype groups of EBF1 SNP rs17056278:C>G using Framingham 252 Offspring data. aP-value for null hypotheses that rho=0, bP-value calculated using difference in 253 likelihoods under robust maximum likelihood (MLR) estimation, where null hypothesis is rho1- 254 rho2=0. Difference tests are adjusted for family clustering. CC Group GC/GG Group Difference Var 1 Var 2 Rho1 a P-value Rho2 a P-value b P-value STRESS HIPCM -0.01 0.582 0.10 0.047 0.028 STRESS WAISTCM -0.02 0.382 0.09 0.066 0.034 STRESS BMI -0.01 0.53 0.07 0.133 0.093 STRESS GLUC -0.04 0.034 0.01 0.885 0.327 STRESS DIABSTAT -0.06 0.001 0.07 0.115 0.030 STRESS CCIMT 0.02 0.252 -0.02 0.67 0.388 HIPCM BMI 0.83 <.0001 0.84 <.0001 0.599 HIPCM GLUC 0.29 <.0001 0.19 <.0001 0.069 HIPCM DIABSTAT 0.21 <.0001 0.17 <.0001 0.612 HIPCM CCIMT 0.13 <.0001 0.13 0.01 0.845 WAISTCM HIPCM 0.74 <.0001 0.74 <.0001 0.708 WAISTCM BMI 0.84 <.0001 0.84 <.0001 0.689 WAISTCM GLUC 0.44 <.0001 0.35 <.0001 0.076 WAISTCM DIABSTAT 0.29 <.0001 0.28 <.0001 0.922 WAISTCM CCIMT 0.25 <.0001 0.26 <.0001 0.776 BMI GLUC 0.39 <.0001 0.33 <.0001 0.203 BMI DIABSTAT 0.27 <.0001 0.26 <.0001 0.849 BMI CCIMT 0.21 <.0001 0.23 <.0001 0.687 GLUC DIABSTAT 0.44 <.0001 0.40 <.0001 0.688 GLUC CCIMT 0.26 <.0001 0.13 0.018 0.029 DIABSTAT CCIMT 0.15 <.0001 0.08 0.187 0.320 255 24 256 257 REFERENCE: 258 S1 Purcell S, Neale B, Todd-Brown K et al.: PLINK: a toolset for whole-genome association 259 and population-based linkage analysis. American Journal of Human Genetics 2007; 81: 260 560–575. 261 S2 Price AL, Patterson NJ, Plenge RM, Weinblatt ME, Shadick NA Reich D: Principal 262 components analysis corrects for stratification in genome-wide association studies. Nature 263 Genetics 2006; 38: 904–909. 264 265 266 267 268 S3 Muthen LK Muthen BO: Mplus User’s Guide. Sixth Edition., Muthen & Muthen, Los Angeles, CA, 1998-2010. S4 Streiner DL: Finding our way: an introduction to path analysis. Can J Psychiatry 2005; 50: 115–122. S5 Pruim RJ*, Welch RP*, Sanna S, Teslovich TM, Chines PS, Gliedt TP, Boehnke M, 269 Abecasis GR, Willer CJ. (2010) LocusZoom: Regional visualization of genome-wide 270 association scan results. Bioinformatics 2010 September 15; 26(18): 2336.2337. 25