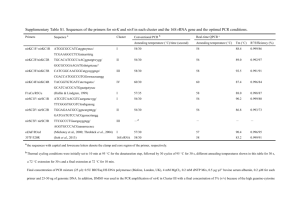
Supplementary Information (doc 64K)
")
Soil DNA extraction, gene amplification and high-throughput sequencing
Total soil DNA was isolated using the MoBio PowerSoil® DNA Isolation Kit.
Partial 16S rRNA gene amplicons were produced using the primers UnivBactF 9 (5’-
GAGTTTGATYMTGGCTC-3’) and BSR534/18 (5’- ATTACCGCGGCTGCTGGC-3’)
which target the V1–V4 hypervariable regions as in Yergeau et al. (2012). Partial ITS
amplicons were produced using the primer set ITS1F (5’-
CTTGGTCATTTAGAGGAAGTAA-3’) and ITS2 (5’-GCTGCGTTCTTCATCGATGC-
3’) as in Ghannoum et al. (2010). Each sample was amplified using unique multiplex
identifier (MID) tags from the extended MID set recommended by Roche Diagnostics
(Roche 2009). PCR reactions were performed in 50 μl volumes containing 5 μM of each
primer, 100 ng/μl of bovine serum albumin, and 200 μM of dNTP mix, 2 mM MgCl
2
, 5
μl of 10X Taq polymerase buffer, and 2.5 U of Taq polymerase from the Qiagen Taq
PCR Core Kit (Qiagen, Germantown, MD, USA). For 16S rRNA gene amplifications, cycling conditions were as follows: 5 min at 95°C, 25 cycles of 30 sec at 95°C, 30 sec at
55°C, and 30 sec at 72°C, and a final elongation step of 15 min at 72°C. Amplification of
ITS was identical except with 30 cycles and 1 min of elongation rather than 30 sec at the end of each cycle. Amplicons were gel purified using the PureLink® Quick Gel
Extraction Kit (Invitrogen, Life Technologies, Carlsbad, CA, USA), quantified using the
Quant-iT PicoGreen dsDNA assay kit (Invitrogen, Life Technologies), pooled in an equimolar ratio, and were sequenced at the Genome Quebec Innovation Centre at McGill
University using the 454 GS FLX Titanium platform (Roche, Branford, CT, USA). One full sequencing plate was used for each primer set (72 samples per plate).
Sequence classification and OTU analysis
Original .sff files were separated into .fasta and .qual files with ‘sffinfo’, after which sequences were binned by MID and quality filtered with a moving 50 bp window using ‘trim.seqs’, with the following parameters: maxambig=0, maxhomop=8, bdiffs=1, pdiffs=2, qwindowaverage=30, qwindowsize=50, minlength=200. Sequences were reduced to only unique sequences using ‘unique.seqs’ and aligned to the Mothurinterpreted Silva bacterial database (contains unique sequences from the SSU Ref database (v.102)) with ‘align.seqs’ (ksize=9, align=needleman, gapopen=-1). Aligned sequences were reduced to only the overlapping region using ‘screen.seqs’ (start=1044, optimize=end, criteria=95) and ‘filter.seqs’ (vertical=T, trump=.). The ‘pre.cluster’
(diffs=2) and ‘chimera.uchime’ commands were used to further reduce sequencing error prior to clustering. A distance matrix was generated with ‘dist.seqs’ and OTUs were formed using average-neighbour clustering with the command ‘cluster.split’. All sequences were classified using the Silva bacterial database mentioned above with
‘classify.seqs’.
Pre-alignment steps for fungal ITS sequences were as described above, except that for ‘trim.seqs’ minlength=250, sequences were reduced to only the front 250 bases using ‘chop.seqs’, after which chimeras were eliminated using ‘chimera.uchime’.
Unaligned sequences were pre-clustered at 99% nucleotide similarity, and were then
default parameters. Output cluster files were reformatted as Mothur .list files, which were used for downstream OTU and community similarity analyses that could be
compared with 16S rRNA analyses in Mothur. Initial classification of sequences was performed in Mothur using the UNITE/QIIME 12_11 ITS reference database (alpha release, accessed February 2013).
Determination of willow phylogeny
PCR of extracted willow DNA was performed under the following cycling parameters: initial denaturation at 94°C for 3 min followed by 33 cycles of 30 s at 94°C,
30 s at 52°C, 60 s at 72°C, and a final extension at 72°C for 5 min. PCR reactions were carried out in 20 μL volumes containing 1 μL of genomic DNA (approximately 50-70 ng), 0.75X of PCR buffer (Bio Basic, Markham, ON, Canada), 0.25 μM of each primer
(F: CGTAACAAGGTTTCCGTAGG ; R: TGCTTAAACTCAGCGGGTAG), 0.25 mM of dNTPs, 2.25 mM of MgCl2, 1 U Taq DNA polymerase (Bio Basic). PCR products were sequenced at McGill University and Génome Québec Innovation Centre. All sequences were assembled by Geneious Pro version 4.8.5. The alignments were
performed in SeaView version 4.2.6 (Gouy et al 2010) using Muscle default parameters
analysis (10 000 replicates) were conducted to obtain the best trees under the parameters
of evolution model selected: GTR+G (jModeltest 2; Guindon and Gascuel 2003, Darriba et al 2012).
References
Darriba D, Taboada GL, Doallo R, Posada D. (2012). jModelTest 2: more models, new heuristics and parallel computing. Nat Methods 9: 772-772.
Edgar RC. (2004). MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res 32: 1792-1797.
Ghannoum MA, Jurevic RJ, Mukherjee PK, Cui F, Sikaroodi M, Naqvi A et al. (2010).
Characterization of the oral fungal microbiome (mycobiome) in healthy individuals.
PLoS Pathog 6: e1000713.
Gouy M, Guindon S, Gascuel O. (2010). SeaView Version 4: a multiplatform graphical user interface for sequence alignment and phylogenetic tree building. Mol Biol Evol
27: 221-224.
Guindon S, Gascuel O. (2003). A simple, fast, and accurate algorithm to estimate large phylogenies by maximum likelihood. Syst Biol 52: 696-704.
Guindon S, Dufayard JF, Lefort V, Anisimova M, Hordijk W, Gascuel O. (2010). New algorithms and methods to estimate maximum-likelihood phylogenies: assessing the performance of PhyML 3.0. Syst Biol 59: 307-321.
Li WZ, Godzik A. (2006). Cd-hit: a fast program for clustering and comparing large sets of protein or nucleotide sequences. Bioinformatics 22: 1658-1659.
Roche. (2009). Using multiplex identifier (MID) adaptors for the GS FLX titanium chemistry–extended MID set. Technical Bulletin: Genome Sequencer FLX System TCB
no 005-2009 Roche, Branchburg, NJ.
Yergeau E, Bokhorst S, Kang S, Zhou JZ, Greer CW, Aerts R et al. (2012). Shifts in soil microorganisms in response to warming are consistent across a range of Antarctic environments. ISME J 6: 692-702.