bcb 311 conservation genetics - University of the Western Cape

BDC 312 CONSERVATION GENETICS & CONSERVATION
BIOLOGY
2010
COURSE MANUAL
This book belongs to:
Compiled by Alan Channing & Richard Knight
COURSE INFORMATION
This course is expected to take you 300 hours of work, made up of lectures, practicals, discussions, and reading and working on your own. The approximate breakdown of time is 100 hours for lectures, practicals, and associated work during the third quarter; 100 hours for lectures, computer exercises and associated work during the fourth quarter; 50 additional hours (ie 10 days of 5 hours per day) to complete the assignment in the third quarter, and 50 additional hours (ie 10 days of 5 hours per day, to complete the assignment in the fourth quarter.
Classes are scheduled for Mondays (8.30-9.30), Tuesdays (12.00-13.00), and (Thursdays (9.40-
10.40). Practicals take place on Tuesdays (14.00-17.00), and Thursdays (14.00-17.00).
Each part of the course builds on what has been learned before, so it is to your advantage not to miss classes, or arrive late.
This is a fast-moving field, with many excellent books. We suggest that you find the latest books and publications on molecular biology, molecular evolution, conservation genetics, and molecular systematics; and read as much as possible.
There are FIVE main sources of information for this course.
1) The prescribed textbook: R. Frankham, JD Ballou and DA Briscoe. 2004. A primer of conservation genetics. Cambridge. (Available from either Van Schaiks in Parow, or the bookstore on campus)
2) Any introductory text covering DNA structure and function (such as a first-year text book)
3) The research papers that form the core part of the classes
4) The lectures, and
5) The practicals
For the Conservation section it is such a wide area that no text book is prescribed. To replace the text book you will be given video material that you will need to review before class.
COURSE ASSESSMENT
(as a percentage of Final Mark)
Coursework mark:
1) Midterm test 1 (covers 50 hours) (3 August)
2) Assignment 1 (Practical plus 50 hours work)
12%
18%
3) Midterm test 2 (covers 50 hours) (20 Sept) 12%
4) Assignment 2 (50 hours work
– completed in sections)
18%
Exam
6) End of second semester 40%
WEEK
1
2
3
4
5
6
7
DATE
12 July Mon 8.30-
9.30
15 July Thur 9.40-
10.40
16 July Fri 8.30-
9.30
19 July Mon 8.30-
9.30
22 July Thur 9.40-
10.40
23 July Fri 8.30-
9.30
26 July Mon 8.30-
9.30
29 July Thur 9.40-
10.40
2010 Programme
CONTENT
Lecture: Revision of DNA
PRACTICAL
Tuesday14-17/
Thursday 11-14
TUES:
1a MR BAYES,
1b Laboratory
Lecture: PCR THURS:
2. Laboratory practice
Lecture: Species: The sixth extinction and other topics
Lecture: Genetic diversity
Lecture: Evolutionary genetics
Lecture: Advanced phylogenetics
Lecture: Forensics and biology
Lecture: Taxonomic uncertainty in conservation
Lecture: Cave bears
TUES:
3. Restriction enzyme digestion
THURS:
4. Electrophoresis
TUES:
5a. Molecular forensics
5b. DNA extraction
THURS:
6. Control PCR
30 July Fri 8.30-
9.30
2 Aug Mon 8.30-
9.30
5 Aug Thur 9.40-
10.40
Lecture: Molecular Clocks
6 Aug Fri 8.30-9.30 Lecture: Phylogeny of
Mabuya atlantica
9 Aug Mon 8.30-
9.30
12 Aug Thur 9.40-
10.40
13 Aug Fri 8.30-
9.30
16 Aug Mon 8.30-
9.30
19 Aug Thur 9.40-
10.40
20 Aug Fri 8.30-
9.30
WOMENS DAY
Lecture: Domestication of cattle
Discussion: Chytrid fungus and amphibians
Lecture: Lippizan horse history
23 Aug Mon 8.30-
9.30
26 Aug Thur 9.40-
10.40
Revision
Lecture: What is
Conservation Biology
27 Aug Fri 8.30-
9.30
Lecture: Galapagos tortoises (Ciofi et al)
Lecture: Analysis of human impact historically and spatially
TUES:
7. PCR product
Electrophresis
TEST 1
THURS:
8. Species-specific PCR amplification
THURS
Epidemics in wild animals
TUES:
TUES:
Epidemics in wild animals Chytrid fungus
THURS:
Continued
TUES
Continued
THURS
Populating the world:
Use of genetic markers
WEEK
8
9
10
11
12
13
14
DATE
6 Sept Mon 8.30-
9.30
9 Sept Thur 9.40-
10.40
10 Sept Fri 8.30-
9.30
MID TERM BREAK 28 AUGUST TO 5 SEPTEMBER
CONTENT
PRACTICAL
Tuesday14-17/Thursday 11-14
13 Sept Mon 8.30-
9.30
16 Sept Thur 9.40-
10.40
17 Sept Fri 8.30-
9.30
20 Sept Mon 8.30-
9.30
23 Sept Thur 9.40-
10.40
24 Sept Fri 8.30-
9.30
27 Sept Mon 8.30-
9.30
Lecture: Biodiversity
Analysis: over-exploitation
Lecture: Biodiversity
Analysis: Environmental factors
Lecture: Biodiversity
Analysis: Invasive Alien
Species
Lecture: Managing
Biodiversity: Restoration
Lecture: Managing
Biodiversity: Information
Systems
Lecture: Managing
Biodiversity: Incentives
(WfW project_
Lecture: Biodiversity:
Tools for sustainable use
Lecture: Biodiversity:
Tools for sustainable use
HERITAGE DAY
Lecture: Biodiversity:
Protected Areas Network
TUES:
Discussion: Impact of Hunters and Gatherers
THURS:
Discussion: Impact of the first agriculturalists
TUES:
Discussion: Impacts of the first Urbanisation
THURS:
Discussion: Impacts of the first industrialists
TUES:
Understanding Landscape Change
TEST 2
THURS:
Detecting changes in our environment
TUES:
Estimating environmental trends in our environment
THURS:
Developing Land-change models
30 Sept Thur 9.40-
10.40
Lecture: Biodiversity:
Protected Areas Network
1 Oct Fri 8.30-9.30 Lecture: Biodiversity:
Protected Areas Network
4 Oct Mon 8.30-
9.30
Lecture: Biodiversity:
Regulation and Policy:
Carbon footprint
7 Oct Thur 9.40-
10.40
11 Oct Mon 8.30-
9.30
Lecture: Biodiversity:
Climate Change
8 Oct Fri 8.30-9.30 Lecture: Biodiversity:
International frameworks
Lecture: Biodiversity
14 Oct Thur 9.40-
10.40
TUES:
Developing Land-change models
THURS
Developing Land-change models
TUES:
Developing Reserve Network designs
THURS
Developing Reserve Network designs
15 Oct Fri 8.30-
9.30
18 Oct Mon 8.30-
9.30
21 Oct Thur 9.40-
10.40
22 Oct Fri 8.30-
9.30
Lecture: Biodiversity:
National Law and
Regulation Frameworks
Lecture: Biodiversity:
National Law, NEMA and
CARA
Lecture: Conservation
Future: Ex situ conservation
Lecture: Conservation
Future: Can extinction be contained
Lecture: Revision and catch-up
TUES
Developing Reserve Network designs
THUR:
Developing Reserve Network designs
PRACTICAL 1
Computers and DNA
1.1 Arrangement of the practical course
There are four main tasks for you to complete during this module. The first is to master the software MRBAYES, which is used to derive a phylogeny using a maximum likelihood approach.
The other three are to become familiar with basic laboratory techniques used in molecular biology.
1.2 Mr Bayes
Follow the instructions carefully, after you have reviewed the use of the computer. There will be a lecture in week 1 on Advanced Phylogenetics, which will provide background to the computer exercise. Use free time during the molecular practicals to master the software. Do not just follow the “recipe” and assume that you know everything.
BEFORE USING MRBAYES YOU SHOULD
1) BE VERY FAMILIAR WITH MAXIMUM PARSIMONY, SUCH AS IS IMPLEMENTED IN PAUP*
2) HAVE WORKED THROUGH THE INTRODUCTORY MATERIAL ON BAYSIAN ANALYSIS,
FOR EXAMPLE THESE NOTES OR THE LECTURE IN THIS COURSE
You will be using the software MrBayes, written by J.P. Huelsenbeck and F. Ronquist. This handout is based on a tutorial by F. Ronquist. It is available on the web
(http://mrbayes.csit.fsu.edu/wiki/indix.php/Tutorial_3.2
INTRODUCTION
In this practical you will learn how to run the program, firstly by attempting a simple analysis, and then interpreting the results. We will be running the software on Macintosh computers, but there are versions that will run on PCs or on UNIX machines. The software is command-line driven, which means that you must type in the appropriate commands in order to interact with the program.
You should first carefully read through these instructions, and make a summary of the key points for yourself.
THREE BITS OF ADVICE FOR BEGINNING WITH MR BAYES
1) Be accurate. Every space and punctuation mark, such as a semicolon (;), period (.), or hash (#), counts.
2) Be accurate.
3) Be accurate.
QUICKSTART
There are four steps to a typical Bayesian phylogenetic analysis using MrBayes:
1. Read the Nexus data file
2. Set the evolutionary model
3. Run the analysis
4. Summarize the samples
In more detail, each of these steps is performed as described in the following paragraphs.
1. At the MrBayes > prompt, type execute primates.nex
. This will bring the data into the program.
When you only give the data file name (primates.nex), the MrBayes program assumes that the file is in the current directory. If this is not the case, you have to use the full or relative path to your data file, for example execute ../taxa/primates.net
. If you are running your own data file for this tutorial, beware that it may contain some MrBayes commands that can change the behavior of the program; delete those commands or put them in square brackets to follow this tutorial.
2. At the MrBayes > prompt, type lset nst=6 rates=invgamma . This sets the evolutionary model to the GTR model with gamma-distributed rate variation across sites and a proportion of invariable sites. If your data are not DNA or RNA, if you want to invoke a different model, or if you want to use non-default priors, refer to the rest of this manual, particularly sections 3 to 5 and the
Appendix.
3.1. At the MrBayes > prompt, type mcmc ngen=10000 samplefreq=10 . This will ensure that you get at least thousand samples from the posterior probability distribution. For larger data sets you probably want to run the analysis longer and sample less frequently (the default sampling frequency is every hundredth generation and the default number of generations is one million).
You can find the predicted remaining time to completion of the analysis in the last column printed to screen.
3.2. If the standard deviation of split frequencies is below 0.01 after 10,000 generations, stop the run by answering no when the program asks "Continue the analysis? (yes/no)". Otherwise, keep adding generations until the value falls below 0.01.
4.1. Summarize the parameter values by typing sump burnin=250 (or whatever value corresponds to 25 % of your samples). The program will output a table with summaries of the samples of the substitution model parameters, including the mean, mode, and 95 % credibility interval of each parameter. Make sure that the potential scale reduction factor (PSRF) is reasonably close to 1.0 for all parameters; if not, you need to run the analysis longer.
4.2. Summarize the trees by typing sumt burnin=250 (or whatever value corresponds to 25 % of your samples). The program will output a cladogram with the posterior probabilities for each split and a phylogram with mean branch lengths. The trees will also be printed to a file that can be read by tree drawing programs such as TreeView ( http://taxonomy.zoology.gla.ac.uk/rod/treeview.html
),
MacClade ( http://macclade.org/macclade.html
), and Mesquite ( http://mesquiteproject.org
).
It does not have to be more complicated than this; however, as you get more proficient you will probably want to know more about what is happening behind the scenes. The rest of this section explains each of the steps in more detail and introduces you to all the implicit assumptions you are making and the machinery that MrBayes uses in order to perform your analysis.
Getting Data into MrBayes
To get data into MrBayes, you need a so-called Nexus file that contains aligned nucleotide or amino acid sequences, morphological ("standard") data, restriction site (binary) data, or any mix of these four data types. The Nexus file that we will use for this tutorial, primates.nex, contains 12 mitochondrial DNA sequences of primates. A Nexus file is a simple text (ASCII) file that begins with #NEXUS on the first line. The rest of the file is divided into different blocks. The primates.nex
file looks like this:
#NEXUS begin data;
dimensions ntax=12 nchar=898;
format datatype=dna interleave=no gap=-;
matrix
Saimiri_sciureus AAGCTTCATAGGAGC ... ACTATCCCTAAGCTT Tarsius_syrichta
AAGCTTCACCGGCGC ... ATTATGCCTAAGCTT Lemur_catta AAGCTTCACCGGCGC
... ACTATCTATTAGCTT Macaca_fuscata AAGCTTCACCGGCGC ...
CCTAACGCTAAGCTT M_mulatta AAGCTTCACCGGCGC ... CCTAACACTAAGCTT
M_fascicularis AAGCTTTACAGGTGC ... CCTAACACTAAGCTT M_sylvanus
AAGCTTTTCCGGCGC ... CCTAACATTAAGCTT Homo_sapiens AAGCTTTTCTGGCGC
... GCTCTCCCTAAGCTT Pan AAGCTTCTCCGGCGC ...
GCTCTCCCTAAGCTT Gorilla AAGCTTCTCCGGTGC ... ACTCTCCCTAAGCTT
Pongo AAGCTTCACCGGCGC ... ACTCTCACTAAGCTT Hylobates
AAGTTTCATTGGAGC ... ACTCTCCCTAAGCTT ; end;
The file contains only one block, a DATA block. The DATA block is initialized with begin data; followed by the dimensions statement, the format statement, and the matrix statement. The dimensions statement must contain ntax, the number of taxa, and nchar, the number of characters in each aligned sequence. The format statement must specify the type of data, for instance datatype=DNA (or RNA or Protein or Standard or Restriction). The format statement may also contain gap=- (or whatever symbol is used for a gap in your alignment), missing=? (or whatever symbol is used for missing data in your file), interleave=yes when the data matrix is interleaved sequences, and match=. (or whatever symbol is used for matching characters in the alignment).
The format statement is followed by the matrix statement, usually started by the word matrix on a separate line, followed by the aligned sequences. Each sequence begins with the sequence name separated from the sequence itself by at least one space. The data block is completed by an end; statement. Note that the begin, dimensions, format, and end statements all end in a semicolon.
That semicolon is essential and must not be left out. Note that, although it occupies many lines in the file, the matrix description is also a regular statement, a matrix statement, which ends with a semicolon just as any other statement. Our example file contains sequences in non-interleaved
(block) format. Non-interleaved is the default but you can put interleave=no in the format statement if you want to be sure.
The Nexus data file can be generated by a program such as MacClade or Mesquite. Note, however, that MrBayes version 3 does not support the full Nexus standard, so you may have to do a little editing of the file for MrBayes to process it properly. In particular, MrBayes uses a fixed set of symbols for each data type and does not support the options of the upported symbols are {A, C,
G, T, R, Y, M, K, S, W, H, B, V, D, N} for DNA data, {A, C, G, U, R, Y, M, K, S, W, H, B, V, D, N} for RNA data, {A, R, N, D, C, Q, E, G, H, I, L, K, M, F, P, S, T, W, Y, V, X} for protein data, {0, 1} for restriction (binary) data, and {0, 1, 2, 3, 4, 5, 6, 5, 7, 8, 9} for standard (morphology) data. In addition to the standard one-letter ambiguity symbols for DNA and RNA listed above, ambiguity
can also be expressed using the Nexus parenthesis or curly braces notation. For instance, a taxon polymorphic for states 2 and 3 can be coded as (23), (2,3), {23}, or {2,3} and a taxon with either amino acid A or F can be coded as (AF), (A,F), {AF} or {A,F}. Like most other statistical phylogenetics programs, MrBayes effectively treats polymorphism and uncertainty the same way
(as uncertainty), so it does not matter whether you use parentheses or curly brackets. If you have other symbols in your matrix than the ones supported by MrBayes, you need to replace them before processing the data block in MrBayes. You also need to remove the "Equate" and
"Symbols" statements in the "Format" line if they are included. Unlike the Nexus standard,
MrBayes supports data blocks that contain mixed data types as described in section 3 of this manual.
To put the data into MrBayes type execute <filename> at the MrBayes > prompt, where
<filename> is the name of the input file. To process our example file, type execute primates.nex
or simply exe primates.nex
to save some typing. Note that the input file must be located in the same folder (directory) where you started the MrBayes application (or else you will have to give the path to the file) and the name of the input file should not have blank spaces. If everything proceeds normally, MrBayes will acknowledge that it has read the data in the DATA block of the
Nexus file by outputting the following information:
Executing file "primates.nex"
UNIX line termination
Longest line length = 915
Parsing file
Expecting NEXUS formatted file
Reading data block
Allocated matrix
Matrix has 12 taxa and 898 characters
Data is Dna
Data matrix is not interleaved
Gaps coded as -
Taxon 1 -> Tarsius_syrichta
Taxon 2 -> Lemur_catta
Taxon 3 -> Homo_sapiens
Taxon 4 -> Pan
Taxon 5 -> Gorilla
Taxon 6 -> Pongo
Taxon 7 -> Hylobates
Taxon 8 -> Macaca_fuscata
Taxon 9 -> M_mulatta
Taxon 10 -> M_fascicularis
Taxon 11 -> M_sylvanus
Taxon 12 -> Saimiri_sciureus
Successfully read matrix
Setting default partition (does not divide up characters)
Setting model defaults
Setting output file names to "primates.nex.<run<i>.p/run<i>.t>"
Exiting data block
Reached end of file
Specifying a Model
All of the commands are entered at the MrBayes > prompt. At a minimum two commands, lset and prset, are required to specify the evolutionary model that will be used in the analysis. Usually, it is also a good idea to check the model settings prior to the analysis using the showmodel command.
In general, lset is used to define the structure of the model and prset is used to define the prior probability distributions on the parameters of the model. In the following, we will specify a GTR + I
+ _ model (a General Time Reversible model with a proportion of invariable sites and a gammashaped distribution of rates across sites) for the evolution of the mitochondrial sequences and we will check all of the relevant priors. If you are unfamiliar with stochastic models of molecular evolution, we suggest that you consult a general text, such as Felsenstein (2004) .
In general, a good start is to type help lset . Ignore the help information for now and concentrate on the table at the bottom of the output, which specifies the current settings. It should look like this:
Model settings for partition 1:
Parameter Options Current Setting
------------------------------------------------------------------
Nucmodel 4by4/Doublet/Codon 4by4
Nst 1/2/6 1
Code Universal/Vertmt/Mycoplasma/
Yeast/Ciliates/Metmt Universal
Ploidy Haploid/Diploid Diploid
Rates Equal/Gamma/Propinv/Invgamma/Adgamma Equal Ngammacat <number>
4
Usegibbs Yes/No No
Gibbsfreq <number> 100
Nbetacat <number> 5
Omegavar Equal/Ny98/M3 Equal Covarion No/Yes
No
Coding All/Variable/Noabsencesites/ Nopresencesites
All
Parsmodel No/Yes No
------------------------------------------------------------------
First, note that the table is headed by Model settings for partition 1. By default, MrBayes divides the data into one partition for each type of data you have in your DATA block. If you have only one type of data, all data will be in a single partition by default. How to change the partitioning of the data will be explained in section 3 of the manual.
The Nucmodel setting allows you to specify the general type of DNA model. The Doublet option is for the analysis of paired stem regions of ribosomal DNA and the Codon option is for analyzing the
DNA sequence in terms of its codons. We will analyze the data using a standard nucleotide substitution model, in which case the default 4by4 option is appropriate, so we will leave
Nucmodel at its default setting.
The general structure of the substitution model is determined by the Nst setting. By default, all substitutions have the same rate (Nst=1), corresponding to the F81 model (or the JC model if the stationary state frequencies are forced to be equal using the prset command, see below). We want the GTR model (Nst=6 instead of the F81 model so we type lset nst=6 . MrBayes should acknowledge that it has changed the model settings.
The Code setting is only relevant if the Nucmodel is set to Codon. The Ploidy setting is also irrelevant for us. However, we need to change the Rates setting from the default Equal (no rate variation across sites) to Invgamma (gamma-shaped rate variation with a proportion of invariable sites). Do this by typing lset rates=invgamma . Again, MrBayes will acknowledge that it has changed the settings. We could have changed both lset settings at once if we had typed lset nst=6 rates=invgamma in a single line.
We will leave the Ngammacat setting (the number of discrete categories used to approximate the gamma distribution) at the default of 4. In most cases, four rate categories are sufficient. It is possible to increase the accuracy of the likelihood calculations by increasing the number of rate categories. However, the time it will take to complete the analysis will increase in direct proportion to the number of rate categories you use, and the effects on the results will be negligible in most cases.
The default behaviour for the discrete gamma model of rate variation across sites is to sum site probabilities across rate categories. To sample those probabilities using a Gibbs sampler, we can set the Usegibbs setting to Yes. The Gibbs sampling approach is much faster and requires less memory, but it has some implications you have to be aware of. This option and the Gibbsfreq option will be discussed in the next section of this manual.
Of the remaining settings, it is only Covarion and Parsmodel that are relevant for single nucleotide models. We will use neither the parsimony model nor the covariotide model for our data, so we will leave these settings at their default values. If you type help lset now to verify that the model is correctly set, the table should look like this:
Model settings for partition 1:
Parameter Options Current Setting
------------------------------------------------------------------ Nucmodel
4by4/Doublet/Codon 4by4
Nst 1/2/6 6
Code Universal/Vertmt/Mycoplasma/ Yeast/Ciliates/Metmt
Universal
Ploidy Haploid/Diploid Diploid
Rates Equal/Gamma/Propinv/Invgamma/Adgamma Invgamma Ngammacat <number>
4
Usegibbs Yes/No No
Gibbsfreq <number> 100
Nbetacat <number> 5
Omegavar Equal/Ny98/M3 Equal
Covarion No/Yes No
Coding All/Variable/Noabsencesites/ Nopresencesites
All
Parsmodel No/Yes No
------------------------------------------------------------------
Setting the Priors
We now need to set the priors for our model. There are six types of parameters in the model: the topology, the branch lengths, the four stationary frequencies of the nucleotides, the six different nucleotide substitution rates, the proportion of invariable sites, and the shape parameter of the gamma distribution of rate variation. The default priors in MrBayes work well for most analyses, and we will not change any of them for now. By typing help prset you can obtain a list of the default settings for the parameters in your model. The table at the end of the help information reads:
Model settings for partition 1:
Parameter Options Current Setting -------------------
----------------------------------------------- Tratiopr Beta/Fixed
Beta(1.0,1.0) Revmatpr Dirichlet/Fixed
Dirichlet(1.0,1.0,1.0,1.0,1.0,1.0)
Aamodelpr Fixed/Mixed Fixed(Poisson) Aarevmatpr
Dirichlet/Fixed Dirichlet(1.0,1.0,...) Omegapr Dirichlet/Fixed
Dirichlet(1.0,1.0) Ny98omega1pr Beta/Fixed Beta(1.0,1.0)
Ny98omega3pr Uniform/Exponential/Fixed Exponential(1.0) M3omegapr
Exponential/Fixed Exponential Codoncatfreqs Dirichlet/Fixed
Dirichlet(1.0,1.0,1.0) Statefreqpr Dirichlet/Fixed
Dirichlet(1.0,1.0,1.0,1.0) Shapepr Uniform/Exponential/Fixed
Uniform(0.0,200.0)
Ratecorrpr Uniform/Fixed Uniform(-1.0,1.0) Pinvarpr
Uniform/Fixed Uniform(0.0,1.0) Covswitchpr
Uniform/Exponential/Fixed Uniform(0.0,100.0) Symdirihyperpr
Uniform/Exponential/Fixed Fixed(Infinity) Topologypr Uniform/Constraints
Uniform
Brlenspr Unconstrained/Clock Unconstrained:Exp(10.0) Treeheightpr
Exponential/Gamma Exponential(1.0) Speciationpr
Uniform/Exponential/Fixed Uniform(0.0,10.0) Extinctionpr
Uniform/Exponential/Fixed Uniform(0.0,10.0) Sampleprob <number>
1.00
Thetapr Uniform/Exponential/Fixed Uniform(0.0,10.0) Nodeagepr
Unconstrained/Calibrated Unconstrained Treeagepr Fixed/Uniform/
Offsetexponential Fixed(1.00)
Clockratepr Strict/Cpp/Bm Strict
Cppratepr Fixed/Exponential Exponential(0.10) Psigammapr
Fixed/Exponential/Uniform Fixed(1.00)
Nupr Fixed/Exponential/Uniform Fixed(1.00)
Ratepr Fixed/Variable=Dirichlet Fixed
------------------------------------------------------------------
We need to focus on Revmatpr (for the six substitution rates of the GTR rate matrix), Statefreqpr
(for the stationary nucleotide frequencies of the GTR rate matrix), Shapepr (for the shape parameter of the gamma distribution of rate variation), Pinvarpr (for the proportion of invariable sites), Topologypr (for the topology), and Brlenspr (for the branch lengths).
The default prior probability density is a flat Dirichlet (all values are 1.0) for both Revmatpr and
Statefreqpr. This is appropriate if we want estimate these parameters from the data assuming no prior knowledge about their values. It is possible to fix the rates and nucleotide frequencies but this is generally not recommended. However, it is occasionally necessary to fix the nucleotide frequencies to be equal, for instance in specifying the JC and SYM models. This would be achieved by typing prset statefreqpr=fixed(equal) .
If we wanted to specify a prior that put more emphasis on equal nucleotide frequencies than the default flat Dirichlet prior, we could for instance use prset statefreqpr = Dirichlet(10,10,10,10) or, for even more emphasis on equal frequencies, prset statefreqpr=Dirichlet(100,100,100,100) .
The sum of the numbers in the Dirichlet distribution determines how focused the distribution is, and the balance between the numbers determines the expected proportion of each nucleotide (in the order A, C, G, and T). Usually, there is a connection between the parameters in the Dirichlet distribution and the observations. For example, you can think of a Dirichlet (150,100,90,140) distribution as one arising from observing 150 A's, 100 C's, 90 G's and 140 T's in some set of reference sequences. If your set of sequences is independent of those reference sequences, but this reference set is clearly relevant to the analysis of your sequences, it might be reasonable to use those numbers as a prior in your analysis.
In our analysis, we will be cautious and leave the prior on state frequencies at its default setting. If you have changed the setting according to the suggestions above, you need to change it back by typing prset statefreqpr=Dirichlet(1,1,1,1) or prs st = Dir(1,1,1,1) if you want to save some typing. Similarly, we will leave the prior on the substitution rates at the default flat
Dirichlet(1,1,1,1,1,1) distribution.
The Shapepr parameter determines the prior for the α(shape) parameter of the gamma distribution of rate variation. We will leave it at its default setting, a uniform distribution spanning a wide range of
αvalues. The prior for the proportion of invariable sites is set with Pinvarpr. The default setting is a uniform distribution between 0 and 1, an appropriate setting if we don't want to assume any prior knowledge about the proportion of invariable sites.
For topology, the default Uniform setting for the Topologypr parameter puts equal probability on all distinct, fully resolved topologies. The alternative is to constrain some nodes in the tree to always be present but we will not attempt that in this analysis.
The Brlenspr parameter can either be set to unconstrained or clock-constrained. For trees without a molecular clock (unconstrained) the branch length prior can be set either to exponential or uniform. The default exponential prior with parameter 10.0 should work well for most analyses. It has an expectation of 1/10 = 0.1 but allows a wide range of branch length values (theoretically from 0 to infinity). Because the likelihood values vary much more rapidly for short branches than for long branches, an exponential prior on branch lengths is closer to being uninformative than a uniform prior.
Checking the Model
To check the model before we start the analysis, type showmodel . This will give an overview of the model settings. In our case, the output will be as follows:
Model settings:
Datatype = DNA
Nucmodel = 4by4
Nst = 6 Substitution rates, expressed as proportions
of the rate sum, have a Dirichlet prior
(1.00,1.00,1.00,1.00,1.00,1.00)
Covarion = No
# States = 4
State frequencies have a Dirichlet prior
(1.00,1.00,1.00,1.00)
Rates = Invgamma
Gamma shape parameter is uniformly dist- ributed on the interval (0.00,200.00).
Proportion of invariable sites is uniformly dist- ributed on the interval (0.00,1.00). Gamma distribution is approximated using 4 categories. Likelihood summarized over all rate categories in each generation.
Active parameters:
Parameters
------------------
Revmat 1
Statefreq 2
Shape 3
Pinvar 4
Topology 5
Brlens 6
------------------
1 -- Parameter = Revmat
Type = Rates of reversible rate matrix
Prior = Dirichlet(1.00,1.00,1.00,1.00,1.00,1.00)
2 -- Parameter = Pi
Type = Stationary state frequencies
Prior = Dirichlet
3 -- Parameter = Alpha
Type = Shape of scaled gamma distribution of site rates
Prior = Uniform(0.00,200.00)
4 -- Parameter = Pinvar
Type = Proportion of invariable sites
Prior = Uniform(0.00,1.00)
5 -- Parameter = Tau
Type = Topology
Prior = All topologies equally probable a priori
Subparam. = V
6 -- Parameter = V
Type = Branch lengths
Prior = Unconstrained:Exponential(10.0)
Note that we have six types of parameters in our model. All of these parameters will be estimated during the analysis (see section 5 for information on how to fix parameter values). To see more information about each parameter including it's starting value, one can use the showparams command.
[ edit ]
Setting up the Analysis
The analysis is started by issuing the mcmc command. However, before doing this, we recommend that you review the run settings by typing help mcmc . The help mcmc command will produce the following table at the bottom of the output:
Parameter Options Current Setting
-----------------------------------------------------
Seed <number> 456025217
Swapseed <number> 1179134547
Ngen <number> 1000000
Nruns <number> 2 Nchains
<number> 4 Temp
<number> 0.200000 Reweight
<number>,<number> 0.00 v 0.00 ^ Swapfreq <number>
1 Nswaps <number> 1
Samplefreq <number> 100
Printfreq <number> 100
Printall Yes/No Yes
Printmax <number> 8
Mcmcdiagn Yes/No Yes
Diagnfreq <number> 1000
Diagnstat Avgstddev/Maxstddev Avgstddev
Minpartfreq <number> 0.20
Allchains Yes/No No
Allcomps Yes/No No
Relburnin Yes/No Yes Burnin
<number> 0 Burninfrac
<number> 0.25 Stoprule Yes/No
No Stopval <number> 0.05
Savetrees Yes/No No
Checkpoint Yes/No No
Checkfreq <number> 100000
Filename <name> primates.nex.<p/t> Startparams
Current/Reset Current Starttree
Current/Random Current Nperts
<number> 0 Data Yes/No
Yes Ordertaxa Yes/No No
---------------------------------------------------------------------------
The Seed is simply the seed for the random number generator, and Swapseed is the seed for the separate random number generator used to generate the chain swapping sequence (see below).
Unless they are set to user-specified values, these seeds are generated from the system clock, so your values are likely to be different from the ones in the screen dump above. The Ngen setting is the number of generations for which the analysis will be run. It is useful to run a small number of generations first to make sure the analysis is correctly set up and to get an idea of how long it will take to complete a longer analysis. We will start with 10,000 generations. To change the Ngen setting without starting the analysis we use the mcmcp command, which is equivalent to mcmc except that it does not start the analysis. Type mcmcp ngen=10000 to set the number of generations to 10,000. You can type help mcmc to confirm that the setting was changed appropriately.
By default, MrBayes will run two simultaneous, completely independent analyses starting from different random trees (Nruns = 2). Running more than one analysis simultaneously is very helpful in determining when you have a good sample from the posterior probability distribution, so we suggest that you leave this setting as is. The idea is to start each run from different randomly chosen trees. In the early phases of the run, the two runs will sample very different trees but when they have reached convergence (when they produce a good sample from the posterior probability distribution), the two tree samples should be very similar.
To make sure that MrBayes compares tree samples from the different runs, make sure that
Mcmcdiagn is set to yes and that Diagnfreq is set to some reasonable value, such as every 1000th generation. MrBayes will now calculate various run diagnostics every Diagnfreq generation and print them to a file with the name <Filename>.mcmc. The most important diagnostic, a measure of
the similarity of the tree samples in the different runs, will also be printed to screen every
Diagnfreq generation. Every time the diagnostics are calculated, either a fixed number of samples
(burnin) or a percentage of samples (burninfrac) from the beginning of the chain is discarded. The relburnin setting determines whether a fixed burnin (relburnin=no) or a burnin percentage
(relburnin=yes) is used. If you , MrBayes will by default discard the first 25 % samples from the cold chain (relburnin=yes and burninfrac=0.25).
By default, MrBayes uses Metropolis coupling to improve the MCMC sampling of the target distribution. The Swapfreq, Nswaps, Nchains, and Temp settings together control the Metropolis coupling behavior. When Nchains is set to 1, no heating is used. When Nchains is set to a value n larger than 1, then n - 1 heated chains are used. By default, Nchains is set to 4, meaning that
MrBayes will use 3 heated chains and one "cold" chain. In our experience, heating is essential for problems with more than about 50 taxa, whereas smaller problems often can be analyzed successfully without heating. Adding more than three heated chains may be helpful in analyzing large and difficult data sets. The time complexity of the analysis is directly proportional to the number of chains used (unless MrBayes runs out of physical RAM memory, in which case the analysis will suddenly become much slower), but the cold and heated chains can be distributed among processors in a cluster of computers using the MPI version of the program (see below), greatly speeding up the calculations.
MrBayes uses an incremental heating scheme, in which chain i is heated by raising its posterior probability to the power 1 / (1 + i
λ), where λ is the temperature controlled by the Temp parameter.
The effect of the heating is to flatten out the posterior probability, such that the heated chains more easily find isolated peaks in the posterior distribution and can help the cold chain move more rapidly between these peaks. Every Swapfreq generation, two chains are picked at random and an attempt is made to swap their states. For many analyses, the default settings should work nicely. If you are running many more than three heated chains, however, you may want to increase the number of swaps (Nswaps) that are tried each time the chain stops for swapping.
The Samplefreq setting determines how often the chain is sampled. By default, the chain is sampled every 100th generation, and this works well for most analyses. However, our analysis is so small that we are likely to get convergence quickly, so it makes sense to sample the chain more frequently, say every 10th generation (this will ensure that we get at least 1,000 samples when the number of generations is set to 10,000). To change the sampling frequency, type mcmcp samplefreq=10.
When the chain is sampled, the current values of the model parameters are printed to file. The substitution model parameters are printed to a .p file (in our case, there will be one file for each independent analysis, and they will be called primates.nex.run1.p and primates.nex.run2.p). The
.p files are tab delimited text files that can be imported into most statistics and graphing programs.
The topology and branch lengths are printed to a .t file (in our case, there will be two files called primates.nex.run1.t and primates.nex.run2.t). The .t files are Nexus tree files that can be imported into programs like PAUP* and TreeView. The root of the .p and .t file names can be altered using the Filename setting.
The Printfreq parameter controls the frequency with which the state of the chains is printed to screen. Leave Printfreq at the default value (print to screen every 100th generation).
The default behavior of MrBayes is to save trees with branch lengths to the .t file. Since this is what we want, we leave this setting as is. If you are running a large analysis (many taxa) and are not interested in branch lengths, you can save a considerable amount of disk space by not saving branch lengths.
The Startingtree parameter can be used to feed the chain(s) with a user-specified starting tree.
The default behavior is to start each chain with a different random tree; this is recommended for general use.
Running the Analysis
Finally, we are ready to start the analysis. Type mcmc. MrBayes will first print information about the model and then list the proposal mechanisms that will be used in sampling from the posterior distribution. In our case, the proposals are the following:
The MCMC sampler will use the following moves:
With prob. Chain will change
5.26 % param. 1 (Revmat) with Dirichlet proposal
5.26 % param. 2 (Pi) with Dirichlet proposal
5.26 % param. 3 (Alpha) with Multiplier
5.26 % param. 4 (Pinvar) with Sliding window
78.95 % param. 5 (Tau) and 6 (V) with Extending TBR
Note that MrBayes will spend most of its effort changing topology (Tau) and branch lengths (V) parameters. In our experience, topology and branch lengths are the most difficult parameters to integrate over and we therefore let MrBayes spend a large proportion of its time proposing new values for those parameters. The proposal probabilities can be changed with the propset command, but be warned that inappropriate changes of proposal probabilities may destroy any hopes of achieving convergence. After the initial log likelihoods, MrBayes will print the state of the chains every 100th generation, like this:
Chain results:
1 -- [-5723.498] (-5729.634) (-5727.207) (-5731.104) * [-5721.779] (-5731.701)
(-5737.807) (-5730.336)
100 -- (-5726.662) (-5728.374) (-5733.144) [-5722.257] * [-5721.199] (-5726.193)
(-5732.098) (-5732.563) -- 0:03:18
200 -- [-5729.666] (-5721.116) (-5731.222) (-5731.546) * (-5726.632) [-5731.803]
(-5738.420) (-5729.889) -- 0:02:27
300 -- [-5727.654] (-5725.420) (-5736.655) (-5725.982) * (-5722.774) (-5743.637)
(-5729.989) [-5729.954] -- 0:02:09
400 -- [-5728.809] (-5722.467) (-5742.752) (-5729.874) * (-5723.731) (-5739.025)
[-5719.889] (-5731.096) -- 0:02:24
500 -- [-5728.286] (-5723.060) (-5738.274) (-5726.420) * [-5724.408] (-5733.188)
(-5719.771) (-5725.882) -- 0:02:13
600 -- [-5719.082] (-5728.268) (-5728.040) (-5731.023) * (-5727.788) (-5733.390)
[-5723.994] (-5721.954) -- 0:02:05
700 -- [-5717.720] (-5725.982) (-5728.786) (-5732.380) * (-5722.842) (-5727.218)
[-5720.717] (-5729.936) -- 0:01:59
800 -- (-5725.531) (-5729.259) (-5743.762) [-5731.019] * (-5729.238) [-5731.272]
(-5722.135) (-5727.906) -- 0:02:06
900 -- [-5721.976] (-5725.464) (-5731.774) (-5725.830) * (-5727.845) [-5723.992]
(-5731.020) (-5728.988) -- 0:02:01
1000 -- (-5724.549) [-5723.807] (-5726.810) (-5727.921) * (-5729.302) [-5730.518]
(-5733.236) (-5727.348) -- 0:02:06
Average standard deviation of split frequencies: 0.000000
1100 --[-5724.473] (-5726.013) (-5723.995) (-5724.521) * (-5734.206) (-5720.464)
[-5727.936] (-5723.821) -- 0:02:01
...
9000 -- (-5741.070) (-5728.937) (-5738.787) [-5719.056] * (-5731.562) [-5722.514]
(-5721.184) (-5731.386) -- 0:00:13
Average standard deviation of split frequencies: 0.000116
9100 -- (-5747.669) [-5726.528] (-5738.190) (-5725.938) * (-5723.844) (-5726.963)
[-5723.221] (-5724.665) -- 0:00:11
9200 -- (-5738.994) (-5725.611) (-5734.902) [-5723.275] * [-5718.420] (-5724.197)
(-5730.129) (-5724.800) -- 0:00:10
9300 -- (-5740.946) (-5728.599) [-5729.193] (-5731.202) * (-5722.247) [-5723.141]
(-5729.026) (-5727.039) -- 0:00:09
9400 -- (-5735.178) (-5726.517) [-5726.557] (-5728.377) * (-5721.659) (-5723.202)
(-5734.709) [-5726.191] -- 0:00:07
9500 -- (-5731.041) (-5730.340) [-5721.900] (-5730.002) * (-5724.353) [-5727.075]
(-5735.553) (-5725.420) -- 0:00:06
9600 -- [-5726.318] (-5737.300) (-5725.160) (-5731.890) * (-5721.767) [-5730.250]
(-5742.843) (-5725.866) -- 0:00:05
9700 -- [-5726.573] (-5735.158) (-5728.509) (-5724.753) * (-5722.873) [-5729.740]
(-5744.456) (-5723.282) -- 0:00:03
9800 -- (-5728.167) (-5736.140) (-5729.682) [-5725.419] * (-5723.056) (-5726.630)
(-5729.571) [-5720.712] -- 0:00:02
9900 -- (-5738.486) (-5737.588) [-5732.250] (-5728.228) * (-5726.533) (-5733.696)
(-5724.557) [-5722.960] -- 0:00:01
10000 -- (-5729.797) (-5725.507) (-5727.468) [-5720.465] * (-5729.313) (-5735.121)
(-5722.913) [-5726.844] -- 0:00:00
Average standard deviation of split frequencies: 0.000105
Continue with analysis? (yes/no):
If you have the terminal window wide enough, each generation of the chain will print on a single line.
The first column lists the generation number. The following four columns with negative numbers each correspond to one chain in the first run. Each column corresponds to one physical location in computer memory, and the chains actually shift positions in the columns as the run proceeds. The numbers are the log likelihood values of the chains. The chain that is currently the cold chain has its value surrounded by square brackets, whereas the heated chains have their values surrounded by parentheses. When two chains successfully change states, they trade column positions (places in computer memory). If the Metropolis coupling works well, the cold chain should move around among the columns; this means that the cold chain successfully swaps states with the heated chains. If the cold chain gets stuck in one of the columns, then the heated chains are not successfully contributing states to the cold chain, and the Metropolis coupling is inefficient. The analysis may then have to be run longer or the temperature difference between chains may have to be lowered.
The star column separates the two different runs. The last column gives the time left to completion of the specified number of generations. This analysis approximately takes 1 second per 100 generations. Because different moves are used in each generation, the exact time varies somewhat for each set of 100 generations, and the predicted time to completion will be unstable in the beginning of the run. After a while, the predictions will become more accurate and the time will decrease predictably.
When to Stop the Analysis
At the end of the run, MrBayes asks whether or not you want to continue with the analysis. Before answering that question, examine the average standard deviation of split frequencies. As the two runs converge onto the stationary distribution, we expect the average standard deviation of split frequencies to approach zero, reflecting the fact that the two tree samples become increasingly similar. In our case, the average standard deviation is about 0.07 after 1,000 generations and then drops to less than 0.000001 towards the end of the run. Your values can differ slightly because of stochastic effects. Given the extremely low value of the average standard deviation at the end of the run, there appears to be no need to continue the analysis beyond 10,000 generations so when
MrBayes asks "Continue with analysis? (yes/no):", stop the analysis by typing no .
Although we recommend using a convergence diagnostic, such as the standard deviation of split frequencies, to determine run length, we want to mention that there are simpler but less powerful methods of determining when to stop the analysis. Arguably the simplest technique is to examine the log likelihood values (or, more exactly, the log probability of the data given the parameter values) of the cold chain, that is, the values printed to screen within square brackets. In the beginning of the run, the values typically increase rapidly (the absolute values decrease, since these are negative numbers). This phase of the run is referred to as the "burn-in" and the samples from this phase are typically discarded. Once the likelihood of the cold chain stops to increase and starts to randomly fluctuate within a more or less stable range, the run may have reached stationarity, that is, it is producing a good sample from the posterior probability distribution. At stationarity, we also expect different, independent runs to sample similar likelihood values. Trends in likelihood values can be deceiving though; you're more likely to detect problems with convergence by comparing split frequencies than by looking at likelihood trends.
When you stop the analysis, MrBayes will print several types of information useful in optimizing the analysis. This is primarily of interest if you have difficulties in obtaining convergence. Since we apparently have a good sample from the posterior distribution already, we will ignore this information for now.
Summarizing Samples of Substitution Model Parameters
During the run, samples of the substitution model parameters have been written to the .p files every samplefreq generation. These files are tab-delimited text files that look something like this:
[ID: 9409050143]
Gen LnL TL r(A<->C) ... pi(G) pi(T) alpha pinvar
1 -5723.498 3.357 0.067486 ... 0.098794 0.247609 0.580820 0.124136
10 -5727.478 3.110 0.030604 ... 0.072965 0.263017 0.385311 0.045880
....
9990 -5727.775 2.687 0.052292 ... 0.086991 0.224332 0.951843 0.228343
10000 -5720.465 3.290 0.038259 ... 0.076770 0.240826 0.444826 0.087738
The first number, in square brackets, is a randomly generated ID number that lets you identify the analysis from which the samples come. The next line contains the column headers, and is followed by the sampled values. From left to right, the columns contain: (1) the generation number
(Gen); (2) the log likelihood of the cold chain (LnL); (3) the total tree length (the sum of all branch lengths, TL); (4) the six GTR rate parameters (r(A<->C), r(A<->G) etc); (5) the four stationary nucleotide frequencies (pi(A), pi(C) etc); (6) the shape parameter of the gamma distribution of rate variation (alpha); and (7) the proportion of invariable sites (pinvar). If you use a different model for your data set, the .p files will of course be different.
MrBayes provides the sump command to summarize the sampled parameter values. Before using it, we need to decide on the burn-in. Since the convergence diagnostic we used previously to determine when to stop the analysis discarded the first 25 % of the samples and indicated that convergence had been reached after 10,000 generations, it makes sense to discard 25 % of the samples obtained during the first 10,000 generations. Since we sampled every 10th generation, there are 1,000 samples (1,001 to be exact, since the first generation is always sampled) and 25
% translates to 250 samples. Thus, summarize the information in the .p file by typing sump burnin=250 . By default, sump will summarize the information in the .p file generated most recently, but the filename can be changed if necessary.
The sump command will first generate a plot of the generation versus the log probability of the data (the log likelihood values). If we are at stationarity, this plot should look like "white noise", that is, there should be no tendency of increase or decrease over time. The plot should look something like this:
+-----------------------------------------------------------5718.96 |
2 12 | | 2
| | 1 2 2 2 | | 1
22 1*1 2 22 2 1 2 | | 2 2 2 1 2 2 2
2 1 | | 11 1 2 1 2 2 2 2 2 2 | |
1 2 1 1 12 1 1 * 2 2 | | 1 11 2 * 2 1
1 2 2 1 *| | *2 2 1 22 2 1 211
22 | | 2 1 1 1 11 1 22 1 | |* 1
2 2 1 1 2 1* | | 2
1 1 1 | | 1 111 2 1 1 1
| | 22 1 1 | |
1 1 |
+------+-----+-----+-----+-----+-----+-----+-----+-----+-----+5729.82 ^
^
2500 10000
If you see an obvious trend in your plot, either increasing or decreasing, you probably need to run the analysis longer to get an adequate sample from the posterior probability distribution.
At the bottom of the sump output, there is a table summarizing the samples of the parameter values:
Model parameter summaries over the runs sampled in files "primates.nex.run1.p" and
"primates.nex.run2.p": (Summaries are based on a total of 1502 samples from 2 runs) (Each run produced 1001 samples of which 751 samples were included)
95% Cred. Interval
----------------------
Parameter Mean Variance Lower Upper Median
PSRF *
---------------------------------------------------------------------------------------
--
TL 2.954334 0.069985 2.513000 3.558000 2.941000
1.242 r(A<->C) 0.044996 0.000060 0.030878 0.059621 0.044567
1.016 r(A<->G) 0.470234 0.002062 0.386927 0.557040 0.468758
1.025 r(A<->T) 0.038107 0.000073 0.023568 0.056342 0.037172
1.022 r(C<->G) 0.030216 0.000189 0.007858 0.058238 0.028350
1.001 r(C<->T) 0.396938 0.001675 0.317253 0.476998 0.394980
1.052 r(G<->T) 0.019509 0.000158 0.001717 0.047406 0.018132
1.003 pi(A) 0.355551 0.000150 0.332409 0.382524 0.357231
1.010 pi(C) 0.320464 0.000131 0.298068 0.343881 0.320658
0.999 pi(G) 0.081290 0.000043 0.067120 0.095940 0.080521
1.004 pi(T) 0.242695 0.000101 0.220020 0.261507 0.243742
1.030 alpha 0.608305 0.042592 0.370790 1.142317 0.546609
1.021 pinvar 0.135134 0.007374 0.008146 0.303390 0.126146
0.999
---------------------------------------------------------------------------------------
-- *
Convergence diagnostic (PSRF = Potential scale reduction factor [Gelman and Rubin, 1992], uncorrected) should approach 1 as runs converge. The values may be unreliable if you have a small number of samples. PSRF should only be used as a rough guide to convergence since all the assumptions that allow one to interpret it as a scale reduction factor are not met in the phylogenetic context.
For each parameter, the table lists the mean and variance of the sampled values, the lower and upper boundaries of the 95 % credibility interval, and the median of the sampled values. The parameters are the same as those listed in the .p files: the total tree length (TL), the six reversible substitution rates (r(A<->C), r(A<->G), etc), the four stationary state frequencies (pi(A), pi(C), etc), the shape of the gamma distribution of rate variation across sites (alpha), and the proportion of invariable sites (pinvar). Note that the six rate parameters of the GTR model are given as proportions of the rate sum (the Dirichlet parameterization). This parameterization has some advantages in the Bayesian context; in particular, it allows convenient formulation of priors. If you want to scale the rates relative to the G-T rate, just divide all rate proportions by the G-T rate proportion.
The last column in the table contains a convergence diagnostic, the Potential Scale Reduction
Factor (PSRF). If we have a good sample from the posterior probability distribution, these values
should be close to 1.0. If you have a small number of samples, there may be some spread in these values, indicating that you may need to sample the analysis more often or run it longer. In our case, we can probably easily obtain more accurate estimates of some parameters by running the analysis slightly longer.
Summarizing Samples of Trees and Branch Lengths
Trees and branch lengths are printed to the .t files. These files are Nexus-formatted tree files with a structure like this:
#NEXUS
[ID: 9409050143]
[Param: tree]
begin trees;
translate
1 Tarsius_syrichta,
2 Lemur_catta,
3 Homo_sapiens,
4 Pan,
5 Gorilla,
6 Pongo,
7 Hylobates,
8 Macaca_fuscata,
9 M_mulatta,
10 M_fascicularis,
11 M_sylvanus,
12 Saimiri_sciureus;
tree rep.1 =
((12:0.486148,(((((3:0.042011,4:0.065025):0.034344,5:0.051939):0.079843,6:0.154472):0.071622
,7:0.214803):0.140045,(11:0.047748,(10:0.062613,(8:0.011963,9:0.027989):0.039141):0.076611):
0.320446):0.054798):0.348505,2:0.407786,1:0.619434);
...
tree rep.10000 =
(((((10:0.087647,(8:0.013447,9:0.021186):0.030524):0.056885,11:0.058483):0.284214,(7:0.16214
5,(((4:0.074703,3:0.054709):0.038621,5:0.079920):0.092362,6:0.147502):0.042049):0.145813):0.
061064,12:0.550171):0.398401,2:0.386189,1:0.504229); end;
To summarize the tree and branch length information, type sumt burnin=250 . The sumt and sump commands each have separate burn-in settings so it is necessary to give the burn-in here again. Otherwise, many of the settings in MrBayes are persistent and need not be repeated every time a command is executed. To make sure the settings for a particular command are correct, you can always use help <command> before issuing the command.
The sumt command will output, among other things, summary statistics for the taxon bipartitions, a tree with clade credibility (posterior probability) values, and a phylogram (if branch lengths have been saved). The summary statistics (see below) describes each partition in the rmat (dots for the taxa that are on one side of the partition and stars for the taxa on the other side; for instance, the sixth partition (ID 6) is the terminal branch leading to taxon 2 since it has a star in the second position and a dot in all other positions). Then it gives the number of times the partition was sampled (#obs), the probability of the partition (Probab.), the standard deviation of the partition frequency (Stdev(s)), the mean (Mean(v)) and variance (Var(v)) of the branch length, the Potential
Scale Reduction Factor (PSRF), and finally the number of runs in which the partition was sampled
(Nruns). In our analysis, there is overwhelming support for a single tree, so all partitions have a posterior probability of 1.0.
Summary statistics for taxon bipartitions:
ID -- Partition #obs Probab. Stdev(s) Mean(v) Var(v) PSRF Nruns ------
------------------------------------------------------------------------
1 -- .......**... 1502 1.000000 0.000000 0.035937 0.000083 1.000 2
2 -- .........*.. 1502 1.000000 0.000000 0.056738 0.000148 1.006 2
3 -- ........*... 1502 1.000000 0.000000 0.022145 0.000037 1.077 2
4 -- ..........*. 1502 1.000000 0.000000 0.072380 0.000338 1.007 2
5 -- .......*.... 1502 1.000000 0.000000 0.017306 0.000037 1.036 2
6 -- .*.......... 1502 1.000000 0.000000 0.345552 0.003943 1.066 2
7 -- .*********** 1502 1.000000 0.000000 0.496361 0.006726 1.152 2
8 -- ..********** 1502 1.000000 0.000000 0.273113 0.003798 1.021 2
9 -- .......***.. 1502 1.000000 0.000000 0.045900 0.000315 1.002 2
10 -- .......****. 1502 1.000000 0.000000 0.258660 0.002329 1.041 2
11 -- ..*......... 1502 1.000000 0.000000 0.049774 0.000110 1.014 2
12 -- ...*........ 1502 1.000000 0.000000 0.062863 0.000147 1.000 2
13 -- .....*...... 1502 1.000000 0.000000 0.146137 0.000665 1.060 2
14 -- ...........* 1502 1.000000 0.000000 0.430463 0.004978 1.045 2
15 -- ......*..... 1502 1.000000 0.000000 0.173405 0.000940 1.053 2
16 -- ..***....... 1502 1.000000 0.000000 0.080733 0.000375 1.023 2
17 -- ..****...... 1502 1.000000 0.000000 0.055286 0.000409 1.064 2
18 -- ..*****..... 1502 1.000000 0.000000 0.116993 0.001254 1.046 2
19 -- ....*..
..... 1502 1.000000 0.000000 0.059082 0.000219 1.014 2 20 -- ..*********.
1501 0.999334 0.000942 0.124653 0.001793 1.141 2
21 -- ..**........ 1500 0.998668 0.000000 0.030905 0.000135 1.030 2 --------
----------------------------------------------------------------------
The clade credibility tree (upper tree, next page) gives the probability of each partition or clade in the tree, and the phylogram (lower tree, next page) gives the branch lengths measured in expected substitutions per site.
In the background, the sumt command creates three additional files. The first is a .parts file, which contains the list of taxon bipartitions, their posterior probability (the proportion of sampled trees containing them), and the branch lengths associated with them (if branch lengths have been saved). The branch length values are based only on those trees containing the relevant bipartition.
The second generated file has the suffix .con and includes two consensus trees. The first one has both the posterior probability of clades (as interior node labels) and the branch lengths (if they have been saved) in its description. A graphical representation of this tree can be generated in the program TreeView by Rod Page. The second tree only contains the branch lengths and it can be imported into a wide range of tree-drawing programs such as MacClade and Mesquite. The third file generated by the sumt command is the .trprobs file, which contains the trees that were found during the MCMC search, sorted by posterior probability.
VIEWING THE TREE
There are many different ways to look at the tree you have produced. There are many different software packages available, such as TreeView. Below are some plots made in Dendroscope, which illustrate different ways of showing the same tree. Which of these would you use? What do you think are appropriate uses for all the plots?
Cladogram
Phylogram
Circular cladogram
Radial phylogram
SUMMARY OF KEY POINTS
* Get help using help or help <command>
* Use execute to bring data in a Nexus file into MrBayes
* Set the model and priors using lset and prset
* Run the chain using mcmc
* Summarize the parameter samples using sump
* Summarize the tree samples using sumt
NEXUS FILES
Now that you are familiar with MrBayes, can you construct a nexus file and run a Baysian estimation of Maximum Likelihood?
There are a number of ways to do this. One is to take an existing Nexus file, and edit it (make changes) including replacing the data with your own. The other is to take a new word-processing file, write the necessary commands, import the sequence data, and save.
REMEMBER THAT YOU MUST “ SAVE A S” THE FILE USING THE “ TEXT ONLY ” FORMAT.
USE “
COURIER
” AS THE FONT FORMAT – THIS IS A NON-PROPORTIONAL FONT WHICH
GIVES THE FILE A CLEAN APPEARANCE THAT IS EASY TO PROOFREAD.
If you save the file as a Word document, there is a lot of extra hidden formatting that is not readable by MrBayes. The program will not run.
THE FILE FORMAT
The data are placed in a nexus file. This is the same file format used by PAUP* and other software.
The nexus file format is written in ASCII (plain text). Remember that the primate data you have already analysed came in a nexus file in the following format ( the following is repeated from above ):
#NEXUS begin data; dimensions ntax=12 nchar=898; format datatype=dna interleave=no gaps=-; matrix
Saimiri_sciureus AAGCT…CTT
Tarsius_syrichta AAGCT…CTT
Lemur_catta AAGCT…CTT
Macaca_fuscus AAGCT…CTT
M_mulatta AAGCT…CTT
M_fascicularis AAGCT…CTT
M_sylvanus AAGCT…CTT
Homo_sapiens AAGCT…CTT
Pan AAGCT…CTT
Gorilla AAGCT…CTT
Pongo AAGCT…CTT
Hylobates AAGCT…CTT
; end;
The nexus format permits many different blocks to be written – this example only has a DATA block. This starts with begin data;
The dimensions statement specifies the number of taxa ntax=12 , and the number of characters nchar=898 .
The format statement specifies the data type datatype=dna from the possible supported options (dna, rna, protein, standard, restriction), and if the sequences are written so that one complete sequence is found before the next interleave=no , or if the sequences are interleaved, interleave=yes . Sequences may contain gaps, and if so the symbol used for gaps needs to be specified gaps=. A standard way to type in sequences is to use a symbol that indicates when the sequence is the same (matches) as the one above. If a dot is used as the symbol, use match=.
This is followed by a matrix statement, then the DNA sequences. Each sequence starts with the name of the organism, separated by at least one space from the sequence. The data block is completed with an end; statement. Each statement ends with a semicolon.
THE DATA
Use the DNA sequence data for a number of lizard species in the genus Anolis . The sequence data are in the file lizard.txt
REMEMBER THAT YOU CAN ACCESS THE COMMAND HELP FOR MR BAYES AS YOU DID
PREVIOUSLY
The data in the file lizard.txt have the following parameters:
Number of taxa – 30
Number of characters – 1456
Data type
– DNA
The sequences are interleaved
Missing data are i ndicated by a “?”
Gaps in the data are indicated by a “-” (hyphen)
THE ANALYSIS
Use the following parameters in the mrbayes block in the nexus file: (See the details above if you can not remember).
A GTR model with a gamma-distributed rate variation and a proportion of invariant sites.
Use the default values for all the other programme settings
PRODUCING YOUR REPORT
Run MrBayes as you have been shown, ensuring that you can complete the report required. You can start writing the report while MrBayes is running. The last column in the output while the programme is running estimates the time required until the run is complete.
Prepare a brief report that is appropriately structured as a scientific article (including Introduction,
Material and Methods, Results, Discussion), and that contains the information and graphics requested below. All the numbered points below must be dealt with in your report. Use the spell and grammar checker. You are writing a paper concerning a number of lizards.
1) Determine an appropriate burn-in value
2) Run the chains for enough generations so that the number of generations at stationarity is at least three times the number for burn-in, and that the standard deviation of split frequencies is at or below 0.01
3) List the minimum and maximum acceptance rates for the cold chains.
4) Give the three values from the state exchange information table, that relate to the acceptance rates for the swaps between chains separated by a single heating step.
5) Give the graph of the generation vs the log probability of the data once stationarity has been reached.
6) Give as a result a table summarizing the samples of the parameter values, including TL (total tree length), the six rate parameters of the GTR model given as proportions of the sum, the stationary frequencies of the four bases, and alpha (the gamma distribution shape).
7) Produce a phylogram rooted on Diplolaemus
8) Give the credibility value of the clade containing Anolis stratulatus
9) Name the least credible clade
PRACTICAL 1b
Review of laboratory equipment and materials
You will be shown the following equipment, materials and approaches that will be used in the series of practicals. Read the accompanying information, or short discussions on each will be presented.
Make notes of the important points. It may help you later if you sketch the equipment (or photograph it).
1) Pipettes (Different sizes, different tips, correct way to use)
2) Tubes (Different sizes, tube boxes, autoclave)
3) Autoclave (Viewing only, you do not need to know how to use it)
3) Gel plates (Equipment for making agarose gels)
4) Power packs (Safety notes, voltage and heating)
5) Vortexer
6) Heating block or water bath (Stability, accuracy)
7) PCR machine (Care of, programming, use)
8) Gloves (Common mistakes, gloves as two-way barriers, sensitive skin)
9) Lab book (Permanent record) and photographs
10) Glassware (Flasks, measuring cylinders, beakers, washing)
11) pH meter (Use of, care of)
12) Centrifuge (Use of, balancing the load)
13) Reagents (Know them, cautions, cleaning)
14) Water still (Viewing only, you do not need to know how to use it)
15) Ice machine (Viewing only, you do not need to know how to use it)
16) The Budget
PRACTICAL 2
Reagent preparation, Basic spectrophotometry, Safety and Good
Laboratory Practice
Learner’s Objectives
1. Become familiar with the use of micro-pipettes and balances.
2. Learn to describe methods in a variety of formats.
3. Use a spectrophotometer to determine the concentration of a pigmented substance in solution.
4. Develop an awareness of Safety Issues and Good Laboratory Practice.
5. Become competent in the preparation of reagents for use in molecular biology.
2.1 Acquaintance with Micro-pipettes (Student task)
The Conservation Geneticist’s tool of the trade is the micro-pipette (often referred to as a Gilson – after one manufacturer). Gilson’s come in eight sizes: P2, P10, P20, P100, P200, P1000, P5000 and P10000. In this practical we will use three of these pipettes:
P1000 201
l – 1000 l P200 21
l - 200
l P20 1
l - 20
l
To use a Gilson Pipette follow the instructions provided in the handout, or explained to you.
1) Set the volume
2) Fit the tip
3) Aspirate
4) Dispense
5) Discard the tip
2.2 Using the fine balances (read instructions for use provided for each balance) (Student task)
1) Place a plastic tube onto the balance. Close the door
2) Tare and ensure the read-out is zero. Open the door. Take the tube.
3) Pipette 10
l of solution A into the tube, close the tube. Replace tube on balance. Close the door.
4) Write down the mass displayed on the read-out.
5) Repeat this procedure for all volumes in Table 2.1 for solutions A and B.
Table 2.1
VOLUME
10
l
15
l
25
l
100
l
WEIGHT OF
SOLUTION A
WEIGHT OF
SOLUTION B
2.3 Using the 1kg balance (read instructions for use provided for each balance) (Student task)
6) Place a plastic tube onto the balance.
7) Tare and ensure the read-out is zero. Remove the tube.
8) Pipette 1000 ul of solution A into the tube, close the tube. Replace the tube. Close the door.
9) Write down the mass displayed on the read-out.
10) Repeat this procedure for all volumes in Table 2.2 for solutions A and B.
Table 2.2
VOLUME
1000 ul
756 ul
432 ul
254 ul
WEIGHT OF
SOLUTION A
WEIGHT OF
SOLUTION B
Is there a difference in the mass of the two solutions? What does this tell you?
2.4 Prepare a Loading Buffer (Group task)
A loading buffer is a solution used in electrophoresis. The sample we prepare today will be used in several practicals throughout the course. It contains sucrose, which makes it dense in order to hold the sample in the loading well and a dye so we can track the movement of the sample. EDTA is a salt, which stabilises the pH and helps to prevent DNA degradation (by chelating salts needed by DNAse). Loading buffer preparation can be described in a number of formats depending on the purpose of the writing:
Paper format: Loading Buffer (Bromophenol Blue 0.25%; Sucrose 40%; EDTA 0.02 M)
Lab Book format: Loading Buffer
0.025 g Bromophenol Blue
4 g
400
l
Sucrose
EDTA (0.5 M, pH 8.0) to 10 ml with ddH
2
O
Step-by-step format:
1) Weigh 0.025 g of Bromophenol Blue in a weighing boat.
2) Weigh 4.0 g of sucrose into a second weighing boat.
3) Carefully transfer contents of weighing boats to a 50 ml bottle.
4) Measure 5 ml of ddH
2
O into a measuring cylinder and pour into bottle.
5) Pipette 400
l EDTA 0.5 M (pH 8) into the bottle.
6) Close bottle and shake to dissolve sucrose and Bromophenol Blue.
7) When fully dissolved pour contents of bottle into measuring cylinder.
8) Wash remains of bottle into cylinder with a further 1 ml ddH
2
O.
9) Top up cylinder to 10 ml with ddH
2
O using a pipette.
10) Transfer back to 50 ml bottle.
11) Label bottle clearly with your name, date and contents. Use clear tape to protect label.
12) Using a Gilson 1000 pipette transfer 1 ml of loading buffer to an eppendorf tube. Label the tube, include your initials. The loading buffer will be used later.
2.5 Describing Experiments in different formats (Individual task)
Write the following lab book recipe in “paper format” in your practical book.
5 ml Tris-HCl 1 M (pH 8.0)
1 ml EDTA 0.5 M (pH 8.0)
1 g NaCl
Water to 10 ml
Write a step-by-step guide and draw a flow diagram of how to make 100 ml of 10x TAE Running
Buffer (EDTA 0.01 M; Tris-HCl 0.4 M; Acetic acid 1.14 %). Write a list of the equipment that you will need to make it.
2.6 Use of a Spectrophotometer (Group task)
A spectrophotometer measures the light absorption capacity of chemicals. Coloured compounds absorb visible light. For example, Bromophenol blue loading buffer absorbs light of wavelength
580 nm. At 580 nm the amount of light absorbed is dependent on the concentration of
Bromophenol blue. In this task we will use a spectrophotometer to measure the concentration of
Bromophenol Blue in solution.
1. Make up the solutions in Table 2.3 in the supplied cuvettes.
2. Check that the spectrophotometer is set at 580 nm.
3. Fill a cuvette with water and place in holder (see demonstration)
4. Zero the spectrophotometer, by pressing the Set Ref button.
5. Replace the “blank” water cuvette with one of your solutions.
6. Read the absorbance of each of your solutions and write these down in Table 2.3.
7. Measure the absorbance of the Mystery Solution.
8. Plot the concentration of Bromophenol blue against absorbance at 580 nm. From your graph calculate the concentration of Bromophenol blue in the mystery solution.
Table 2.3
Loading Buffer
(
l)
Labelled 2.3
2
4
8
16
Water (
2998
2996
2992
2984
32 2868
Mystery solution
l) % Bromophenol blue
2.7 Health, Safety and Good Laboratory Practice
Absorbance at 580 nm
Write down a list of the safety precautions you took during this practical, and recommendations you would make for other students completing this practical. What do you understand by the term
“Good Laboratory Practice” – how would you change the way you conducted this practical to adhere to GLP?
NOTES FOR THE NEXT PRACTICAL: As the restriction digest takes 3 hours (for one of the groups), that group will be asked to come in to the laboratory during the morning to start the digestion. In that way we will be able to compare digestion times. In fact, all the groups would benefit from an early start.
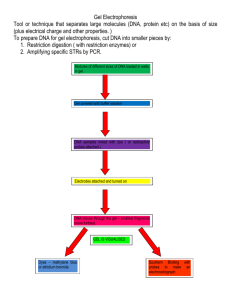
PRACTICAL 3
Restriction enzyme digestion
Learner’s Objectives
1. Understand the concept of restriction enzyme cleavage
2. Use restriction enzymes to make a molecular weight ladder
3. Learn how to choose restriction enzymes for use in phylogenetics
Type II restriction endonucleases are enzymes that cleave double-stranded DNA at particular recognition sequences. They are named after the organism from which they are produced. e.g.
Rsa1 is derived from Rhodopseudomonas sphaeroides
. It is a “four-base cutter”, that recognises
5’-GTAC-3’ and cuts between the T and A. Pst1 is derived from Providencia stuartii . It is a “sixbase cutter”, that recognises 5’-CTGCAG-3’ and cuts between the A and G. In this practical we are using the restriction enzyme Pst1 to cut DNA from the bacteriophage
(lambda). We already know the sequence of
, so we know precisely where the DNA will be cut when the digestion is completed. Table 3.2 is a list of the sizes of fragments produced from a complete digestion of
with Pst1. This digest will be used as a molecular size ladder in future practicals.
3.1 Digestion of
DNA with Pst1 (Group task)
1. Heat waterbath or heating block to 37
C.
2. Mix 4
l
DNA (
g/
l) with 2
l buffer (10x) and 14
l sterile water.
3. Add 2 units of Pst1 and mix gently, ensuring solution remains in bottom of tube.
4. Incubate at 37
C for the time specified in Table 3.1.
5. After the specified incubation add 4
l of Loading Dye (as prepared in a previous practical) and place on ice.
Table 3.1
GROUP NUMBER INCUBATION TIME
1
2
3
4*
15 mins
30 mins
1 hour
3 hours
*Group 4 will start this digestion in advance during the morning
Table 3.2
Fragment
No
1
2
3
4
5
6
7
8
9
10
Size (bp) Fragment
No
11497
5077
4749
4507
2838
2560
2459
2443
2140
1986
11
12
13
14
15
16
17
18
19
20
Size (bp) Fragment
No
1700
1159
21
22
1093
805
514
468
448
339
264
247
23
24
25
26
27
28
29
Size (bp)
216
211
200
164
150
94
87
72
15
3.2: Choosing Restriction Enzymes (Student task)
Manual (complete this during the first hour of the digestion)
You have been given a print out of a partial genome sequence from chicken. If we fully digested this sequence with Pst1 and then with Rsa 1 how many fragments would result and what size would they be? What have you learnt about the fragment frequency of four-base cutters and sixbase cutters?
Computer (Don’t forget your experiment!) This may be completed in Z29.
Open Word and open the Gallus Sequence File (see demonstrator for file directory)
Mouse over the sequence and press “Copy”
Open Webcutter2: http://www.firstmarket.com/cutter/cut2.html
Scroll down and paste the sequence into the sequence box.
Type Gallus into the Sequence Name box above.
Scroll down to select "Linear sequence analysis" and below c lick on the button that says “only the following enzymes”
Highlight Rsa1 and Pst1 (press control, whilst highlighting)
Click the “analyse sequence” box.
Scroll down to look at your results.
Did you find all of the sites that the computer found?
NC_001323.1 Gallus gallus mitochondrion, partial genome
AATTTTATTTTTTAACCTAACTCCCCTACTAAGTGTACCCCCCCTTTCCCCAGGGGGGGTATACTATGCATAATCG
TGCATACATTTATATACCACATATATTATGGTACCGGTAATATATACTATATATGTACTAAACCCATTATATGTATAC
GGGCATTAACCTATATTCCACATTTCTCCCAATGTCCATTCTATGCATGATCTAGGACATACTCATTTACCCTCCCC
ATAGACAGTTCCAAACCACTATCAAGCCACCTAACTATGAATGGTTACAGGACATAAATCTCACTCTCATGTTCTC
CCCCCAACAAGTCACCTAACTATGAATGGTTACAGGACATACATTTAACTACCATGTTCTAACCCATTTGGTTATG
CTCGCCGTATCAGATGGATTTATTGATCGTCCACCTCACGAGAGATCAGCAACCCCTGCCTGTAATGTACTTCAT
GACCAGTCTCAGGCCCATTCTTTCCCCCTACACCCCTCGCCCTACTTGCCTTCCACCGTACCTCTGGTTCCTCGG
TCAGGCACATCCCATGCATAACTCCTGAACTTTCTCACTTTTCACGAAGTCATCTGTGGATTATCTTCCCCTCTTTA
GTCCGTGATCGCGGCATCTTCTCTCTTCTATTGCTGTTGGTTCCTTCTCTTTTTGGGGCTTCTTCACAGGTTACCC
TTCACAGTGCGGGTGCGAGTGCTATTCAAGTGAAGCCTGGACTACACCTGCGTTGCGTCCTATCCTAGTCCTCTC
GTGTCCCTCGATGAGACGGTTTGCGTGTATGGGGAATCATCTTGACACTGATGCACTTTGGATCGCATTTGGTTA
TGGTTCTTCCACCCCCCCGGTAAATGGTGCTATTTAGTGAATGCTTGTCGGACATATTTTTATCAATTTTCACTTCC
TCTATTTTCTTCACAAAACTAGGAAATTCACCACAATTTTTTCTTTGTTATTTTTTAATTTTTTTTTTATTTTTTAAAAA
CATTTTTTAAAAAACTAAATTACATACAAACTACCGCATAAAATCCCTCAAACTATACAAACGTTTATCGTATAATAT
ATATACATTATTGTTTATTCTATCATTATTAGAGAAACTCCACTACCAAAACCATCATTAAAACAAAAATTTACATGC
CACTTAACTCCCCTCACAAACAATCGTTATTTATATTGTTAATTAGCAAACACAAAACCCGCCTTCTACCACTATAA
AGCCCCCATAGCTTAACCCACAAAGCATGGCACTGAAGATGCCAAGATGGTACCTACTATACCTGTGGGCAAAAG
ACTTAGTCCTAACCTTTCTATTGGTTTTTGCTAGACATATACATGCAAGTATCCGCATCCCAGTGAAAATGCCCCC
AAACCTTTCTTCCCAAGCAAAAGGAGCAGGTATCAGGCACACTCAGCAGTAGCCCAAGACGCCTTGCTTAAGCCA
CACCCCCACGGGTACTCAGCAGTAATTAACCTTAAGCAATAAGTGTAAACTTGACTTAGCCATAGCAACCCAGGG
TTGGTAAATCTTGTGCCAGCCACCGCGGTCATACAAGAAACCCAAATCAATAGCTACCCGGCGTAAAGAGTGGCC
ACATGTTATCTGCACCAGCTAAGATTAAAATGCAACCAAGCTGTCATAAGCCTAAGATCCACCTAAACCCAACCCA
AATCCATCTTAGCCTCAACGATTAATTTTAACCCACGAAAGCTAGGACCCAAACTGGGATTAGATACCCCACTATG
CCTAGCCCTAAATCTAGATACCTCCCATCACACATGTATCCGCCTGAGAACTACGAGCACAAACGCTTAAAACTCT
AAGGACTTGGCGGTGCCCCAAACCCACCTAGAGGAGCCTGTTCTATAATCGATAATCCACGATTCACCCAACCAC
CCCTTGCCAGCACAGCCTACATACCGCCGTCGCCAGCCCACCTCTAATGAAAGAACAACAGTGAGCTCAATAGC
CCCTCGCTAATAAGACAGGTCAAGGTATAGCCTATGGGGTGGGAGAAATGGGCTACATTTTCTAACATAGAACAA
ACGAAAAAGGATGTGAAACCCGCCCTTAGAAGGAGGATTTAGCAGTAAAGTGAGATCATACCCCCTAAGCTCACT
TTAAGACGGCTCTGAGGCACGTACATACCGCCCGTCACCCTCTTCACAAGCCATCAACATCAATAAATATATACTT
CCCCTCCCGGCTAAAGACGAGGCAAGTCGTAACAAGGTAAGTGTACCGGAAGGTGCACTTAGACTACCAAGGCG
TAGCTATAACTTCAAAGCATTCAGCTTACACCTGAAAGATACCCTCAACAGACAAGGTCGCCTTGACTTGCCCCC
CCTCTAGCCCGACAAACTCGTACCCTTAACATAAAAAACTTACCTCCCCCTCTTAACCAAAACATTATAAATTGTCC
CAGTATAGGCGATAGAAAAGACTACCCCGGCGCAATAGAGGCTAACTGTACCGCAAGGGAAAGATGAAATAGCA
ATGAAAACCATAAGCAAAAAACAGCAAAGACCAACCCTTGTACCTTTTGCATCATGATTTAGCAAGAACAACCAAG
CAAAGTGAGCTAAAGTTTGCCTTCCCGAAACCCAAGCGAGCTACTTGCGAGCAGCTAAAATTTGAGCGAACCCGT
CTCTGTTGCAAAAGAGCGGGATGACTTGCCAGTAGAGGTGAAAAGCCTACCGAGCTGGGTGATAGCTGGTTACC
TGTCAAACGAATCTAAGTTCCCCCTTAACCCACCCCCTAAAGACACCCACCTTTGTCAACCTTGAGAACGTTGGG
GTTAAGAGCAATTCGATGGGGGTACAGCTCCATCGAAAAAGAACACAACCTCCTCCAGCGGATAATAATCACCCC
TCCCCGCACTGTGGGCCTTCAAGCAGCCACCAACAAAAGAGTGCGTCAAAGCTCCCTCATTAAAAAATCTAAAAC
CCTATTTGACTCCCTCA
PRACTICAL 4
Electrophoresis
Learner’s Objectives
Learn to respect toxic chemicals and use them carefully
Understand the concept of agarose electrophoresis and relationship between Rf and Molecular
Weight.
Electrophoresis is a method for separating and visualising macro-molecules according to their size and/or charge. In today’s practical we are using Agarose Gel Electrophoresis of DNA. A matrix of agarose is made in a buffer that contains salts that a) carry electrical current and b) maintain the pH and integrity of the sample.
The gel is placed in a tank, containing buffer and an electric current is passed through it. Samples placed in wells at one end of the gel will travel through the gel at a rate proportional to their molecular weight. To ensure the sample stays in the well we use the loading buffer made in
Practical 2. The gel also contains ethidium bromide to visualise the position of DNA in the gel.
Ethidium bromide is a compound that interlinks between DNA strands causing them to fluoresce under UV light.
Ethidium bromide is EXTREMELY TOXIC – it will bind your DNA strands together and will lead to mutation of the foetus during pregnancy. Always wear gloves when in contact with gel and buffer and if you are/may be pregnant – do not touch the gel at all!
I have read and understood this warning Signed:
4.1 Checking a restriction digest and measuring size of fragments on a gel.
(Group task)
Watch the demonstration of gel preparation. Leave the gel to set for 15 minutes.
Whilst you are waiting, split into two teams. The first student must lift the test gel in the tanks filled with Bromophenol blue using a spatula/egg-lifter. Place it in a tray and carry it across the lab to the tupperware box. Slide the gel into the box. Then give the spatula to the next student who will take the gel back to the gel tank. Continue this until everyone in your team has carried the gel.
When the gel is set, gently remove the comb and place the gel face up in the tank. Pour 1x TBE over the gel until the gel is submerged 2 mm under the buffer.
Load 5
l of your digestion from Practical 3 into a well. (See Table 4.1 for where to load)
Pipette 1
l of loading buffer onto the plastic parafilm square. Then take 5
l of the mystery solution labelled X and pipette it on top of the loading buffer. Mix gently by pipetting up and down then pipette the mixed solution into the tip and load into the well (See Table 4.1).
Table 4.1
: Lanes of Agarose Gel. G = group number
1 2 3 4 5 6 7 8 9 10 11 12 LANE
Number
G1 dig
G1
X
G2 dig
G2
X
G3 dig
G3
X
G4 dig
G4
X est est est est
1. When everybody has loaded, put the lid on the tank so the black cable is at the top and red is at the bottom. (The bands run towards the red end) Plug in the cables to the power-pack and
switch ON. Check the voltage is 75 V. Watch to ensure that the blue band in the well is moving down the gel. Leave gel for 30 minutes. Do part 4.2 of the practical while the gel is running.
2. When the blue band has reached 1 cm from the bottom of the gel turn off the power. DO NOT open gel tank with power on! Remove gel from the tank using spatula and place in tray. Take the tray to the transilluminator with a Practical Assistant and get photographs of the gel (1 per group). Remember what you learnt about ethidium bromide!
What can you say about the digestion conditions used by the different groups? Which was the best condition for cutting the DNA?
Calculate the size of the mystery samples by plotting Rf against the size of fragments in your digest and then reading off the Rf of the mystery samples.
4.2 Estimating DNA fragment size (Student task)
1) Imagine that Figure 1 below is a diagram of your gel. The line R0 is where the samples were loaded. Lane 1 is the Pst 1 digestion and Lane 2 is a mystery sample of unknown size.
2) Measure the distance between R0 and each band using a ruler. This distance is the Rf. Plot
(on graph paper) Rf against the size of the fragment and draw a line through the points on the graph.
3) Then measure the Rf of sample X. Plot this on the graph and calculate the size of the fragment.
What size is X?
Figure 4.1: Exercise in calculating fragment length
R0
Size
X
PRACTICAL 5a
Introduction to Molecular Forensics
Modified from Nolan et al. 2000. Association for Biology Laboratory Education.
5.1 Background
Most museums of natural history have as one of their missions uncovering the relatedness among species. Traditionally, scientists have used measurements of physical characteristics, embryology, and the fossil record to help determine this relatedness. Many scientists are now using molecular biology tools in addition to these traditional approaches.
For example, molecular approaches have been used to assist in the construction of a “family tree” (phylogeny) of 25 sturgeon and paddlefish species (Order Acipenseriformes). These are the caviar-producing species.
The three species that produce the caviar that is most often found in shops are the beluga
( Huso huso ), the sevruga ( Acipenser stellatus ) and the osetra ( Acipenser gueldenstaedti ). All sturgeon species are suffering from over-fishing and many are trying to survive despite environmental degradation. The land-locked Caspian Sea commercially-fished species (the three mentioned above) have perhaps received the most publicity regarding their exploitation.
As caviar commands a high price in the marketplace, these fish are sometimes illegally caught. All sturgeon species were placed on the Convention for Trade in Endangered Species (CITES) list in
1998. What is worse, is that sometimes caviar from the more “commonly available” sturgeon are replaced by even rarer species. The rationale behin d being able to identify “unknown” or
“mistakenly labeled” caviar might lead to stricter laws against illegal sales of caviar from endangered species in the future.
When female sturgeons are caught, they are first stripped of their roe. The fish eggs are packed carefully in salt to add to the flavor and so that they will keep for several months in an unopened jar. After the salt is added, the roe is kneaded in a certain fashion —this is the “art” to packing caviar (Cullen, 1999). When the jars are opened, the eggs should keep for several weeks if tightly covered. DNA has been isolated from caviar that was several months old--if tightly covered and refrigerated, the eggs appear to keep their shape and integrity, which is necessary to isolate DNA from an intact egg.
Mitochondrial DNA genes have been sequenced for each of these species, and primers for amplifying these genes have been synthesized (Birstein and DeSalle 1998). Experiments have been conducted in which single caviar eggs obtained from jars purchased in stores have been tested for the three commercially available species of origin. It was ascertained through PCR analysis that a large percentage of these jars (23%) were “mislabeled” (DeSalle & Birstein
1996). In other words, the jars contained either:
(a) Species that should not have been fished for because they were endangered or
(b.) Caviar that should have been sold at a lower price.
“There is a lot of fake caviar out there.”
Species ID kits are being developed for use in conservation and wildlife forensics. It is thought that, since eggs from endangered species have been detected, illegal fishing of endangered species has occurred. The students who participate in this laboratory exercise are, in effect, conducting forensic science.
5.2 Background reading (Student task)
Read the accompanying papers, most available as pdf files, and any others you can find on the topic.
Birstein, V., P. Doukakis, B. Sorkin & R. de Salle. 1998. Population aggregation analysis of three caviar-producing species of sturgeons and implications for the species identification of black caviar. Conservation Biology 12: 766-775.
Birstein, V., R. de Salle & P. Doukakis. 2002. Letter to the editor. Reviews in Fish Biology and
Fisheries 12: 107-108.
Cullen, R. 1999. The rise and fall of the Caspian Sea. National Geographic 195: 2-35.
Ludwig, A. 2006. A sturgeon view of conservation genetics. European Journal of Wildlife Research
52: 3-8.
5.3 Make up the solution below (Group task)
10x TBE Buffer
To make one liter of 10X TBE buffer pH 8.0 add the following to 700 ml of distilled water in a 2-liter flask:
1 g of NaOH
108 g of Tris base
55 g of boric acid
7.4 g of EDTA
Stir to dissolve; then add distilled water to bring to 0.8 litre volume.
Check the pH. You can adjust the pH higher (more basic) by adding a few drops of NaOH and stirring. Check pH again.
If the pH is too high, add a few drops of Hydrochloric acid
CAUTION: Just add a few drops at a time, and allow the pH to settle before checking.
Once the pH is correct, add distilled water to bring the final volume to 1 litre.
PRACTICAL 5b
Extraction of DNA from caviar
Learner’s Objectives
1. Gain experience in DNA extraction methodologies.
2. Become aware of the quantities of material from which DNA can be extracted.
3. Extract DNA from fish eggs.
5.4: Sample Preparation (Per student)
IMPORTANT NOTICE: AVOID CONTAMINATION! ONLY USE A PIPETTE TIP ONCE!
Each student or group will receive one fish egg from each of two caviars. The first task is to wash the salt packing from the egg.
1. Pipette 0.5 ml of sterile STE into an eppendorf tube and label with your name.
2. Place one caviar egg into the tube and ensure it is covered with the buffer. Leave for 10 minutes. Label the tubes according to the egg type.
3. Once your samples have soaked in STE spin the tubes for 1 minute in a microfuge at full power.
Gently remove the STE with a 1 ml pipette, leaving your samples in the bottom of the tubes.
5.5: SDS-Phenol-Chloroform Extraction (Per student)
This method is the most widely used of all the extraction methods. The sample from which DNA will be extracted is incubated in a buffer (EDTA and Tris) containing SDS (a detergent to break down cell membranes) and Proteinase K to digest protein. The digest is mixed with phenolchloroform. The digested proteins dissolve in the phenol (lower phase) whilst the DNA stays in the upper aqueous phase. The aqueous phase is then washed with chloroform to remove any excess phenol and the DNA is precipitated with sodium acetate and ethanol. The precipitate is washed, dried and then re-suspended in buffer. This method is good for samples where there is a reasonable amount of starting material, but is not always good when there is only a small quantity of tissue because loss can occur during transfer between tubes.
1. Pipette 0.5 ml Extraction Buffer (SDS 0.5 %; 50 mM Tris; 0.4 M EDTA, pH 8.0) onto the egg sample in the eppendorf tube.
2. Open a sterile toothpick bag, and use the toothpick to gently squash the egg against the inside of the tube. Do not touch the end of the toothpick that will touch the egg.
3. Add 10
l Proteinase K (20 mg/ml). Vortex
4. Incubate at 55
C for 60 mins. Finger vortex. The egg should be completely digested (turned into "soup"). If not, incubate a little longer.
CAUTION: PHENOL IS VERY TOXIC & CORROSIVE
I have read and understood this warning. Signed:
5. Add 500
l phenol:chloroform:isoamyl alcohol (24:24:1). The PCI is below a layer of water in the container.
Finger vortex.
6. Centrifuge at low speed (5000 x g) for 10 mins.
7. Remove supernatant with a wide-bore 1 ml tip and place in a new tube. Mix with 500
l of chloroform:isoamyl alcohol (24:1). Finger vortex.
8. Centrifuge at low speed (5000 x g) for 10 mins.
9. Remove supernatant with a wide-bore 1 ml tip and place in a new tube. Add 0.1 volumes 3 M
Na acetate (pH 5.2). (ie about 45
l).
10. Add 650
l ice cold absolute ethanol.
11. You may see fine white wisps of DNA precipitate out, or a milky disc form between the alcohol and the supernatant. Shake gently.
12. Incubate in the deepfreeze until Practical 6, when you will continue with the instructions below
PRACTICAL 6
Control PCR of caviar DNA
For the control, we will use the general primers that are specific for all caviar species (B72 and
S2a) as we are sure that the eggs are real caviar. The purpose of this experiment is to check that everything is working. If you do not get a positive amplification, what might this mean?
6.1 Pelleting the DNA (Per student)
Remove your DNA precipitate tube from the deepfreeze.
1. Centrifuge for 10 mins at full speed (13,000 x g). You should see a small pellet (or flat blob) of white DNA at the bottom of the tube. Even if you can see nothing, there is still DNA present
2. Pour off the alcohol, watching to ensure that the blob of DNA does not move. Air-dry pellet for
20 mins, by placing the open tube flat on the bench on some paper towel.
5. Resuspend pellet in 30
l TE buffer, by adding the buffer to the tube.
6.2 PCR Amplification (Per student)
1.
You may warm the sample for a few minutes in a 55
°
C water bath, if the DNA appears to not have gone into solution.
2. Since you are not sure of the quantity of DNA that you have isolated, and the PCR reaction is
DNA concentration-dependent, it will be necessary for you to measure the DNA concentration using a fluorometer. This is a device which measures the amount of fluorescence, which is directly proportional to the amount of double-stranded DNA. There are other ways to proceed if you do not have a fluorometer (but we have one). You will be shown how to dilute 5
l of your sample into
195
l of fluorescent buffer. Allow to stand for two minutes before measuring. KEEP THE
SAMPLE AT ROOM TEMPERATURE, DO NOT HOLD IT IN YOUR WARM HANDS. The measurement is temperature-dependent. The fluorometer reads in
g/ml. Convert that to ng/
l, then multiply by 40 (you had only 5
l in 200
l = 1/40). This is the concentration of extracted
DNA.
3. Calculate the dilution necessary to produce about 20
l of your two DNA extractions, each at a concentration of 2 ng/
l. Dilute with TE buffer. This is the working concentration of the template for the PCR reaction. If the DNA concentration is too low, just use the extraction "as is", without diluting.
4. To set up the PCR mix:
You should have three PCR tubes: one for each egg DNA, and one for the negative control. Use water instead of template in the negative control. Keep all your tubes on ice. Label the tubes before you begin.
5. Add 23 µl of the PCR reaction mix that has been prepared by the instructor and is sitting on ice, to each of the three tubes.
The control reaction mix contains the following ratios of reactants:
Per 25
l reaction:
12.5
l Ready M ix (1 unit Taq polymerase, 2x buffer, 10 mM dNTPs)
1.5
l B72 primer (10 mM)
1.5
l S2a primer (10 mM)
7.5
l sterile water
6. Spin tubes briefly at top speed in the microfuge for a few seconds to mix the reactants .
7. Place the PCR tubes in the PCR machine. Run the PCR reaction under the following parameters: (This will take about 1 hour). We are using an engineered polymerase, made in Cape
Town, that is extremely fast. The enzyme is linked to an antibody, and does not start working until the antibody is separated by heating at 95 degrees.
STEP 1
Denature at 95
° for 1 minute
STEP 2
35 cycles of
95
° for 10 seconds;
53° for 10 seconds;
72° for 1 second.
STEP 3
Cool and hold at 10° C until needed
(Do 6.2 below while the PCR is running)
8. When the runs are finished, keep them at 4° C in the fridge until you have time to complete the electrophoresis.
PRACTICAL 7
Gel Electrophoresis
Prepare a fresh agarose gel
7.1 Agarose Gel Preparation (Per group)
1. Place 0.32 gram of agarose into a 125 ml Erlenmeyer flask. Add 45 ml of 1X TBE buffer.
2. Microwave the solution until it boils (about a minute and a half).
3. Let the gel cool at room temperature till hot but not burning to the touch. (Touch the flask to your cheek!)
4. At this point, add 2
l of a 1 mg/ml solution of ethidium bromide to the side of the flask above the agarose. Swirl to mix. (The instructor will handle the ethidium)
CAUTION!!
Since ethidium bromide intercalates between the bases of DNA, it is a potential carcinogen. Handle with care.
I have read and understood this warning . Signed:
5. Cast the gel according to the directions that come with your gel tray
—you can use masking tape to seal the ends, or some trays come with rubber “gaskets” that fit over the ends and effectively seal it. Place your tray on a level surface. Place a 8-12 well comb into the tray.
6. Pour the gel quickly. Push any bubbles to the side with a yellow micropipette tip. If necessary, use two combs.
7. The gel should be set after about 20 minutes
—it will turn opaque and you may see wavy lines running through it. Leave it until the PCR is complete.
8. Pull out the comb by wiggling it gently as you pull
—this takes a little practice. Take off the tape or the rubber gaskets.
7.2 Loading and running a gel (Per student)
1. Place the gel in an electrophoresis chamber. Cover the gel with 1X TBE. You should just barely cover the gel
—the less buffer, the less resistance to the current. As you increase the amount of buffer, you will notice that by switching to the "current" or "ampere" setting, the number of amperes increases, which is undesirable because this could create too much heat and cause your gel to melt.
2. Prepare to load the gel. Take a piece of parafilm about 10 cm long and place it down flat on the lab bench.
3. Add dots of 1
—one for each sample that you will load. (Don’t forget the control). The size ladder (digest) already has loading dye added.
4. Spin tubes briefly at top speed in the microfuge for a few seconds to ensure that nothing is stuck on the sides of the tubes.
5. Make a key of the order of your samples that you will be loading into your gel in your notebook.
Remember to include the control and the size ladder.
6. Loading dye:
(a) contains sucrose which is dense so that the samples do not float out of the gel and
(b) contains two dyes that will separate upon migration through the gel.
7. Add 2
l of each sample to the green loading dye dot and mix by pipetting up and down once.
8. Carefully add your samples to the wells under the liquid. Connect the electrodes. Then turn on the power supply and set the voltage at 90 volts.
9. You will notice that the loading dye will separate out into a dark blue and a yellow band.
The faster-moving band will co-migrate with a DNA fragment that is approximately 300 base pairs in length, and the slower-moving band will co-migrate with a DNA fragment that is approximately
9,000 base-pairs in length.
10. Turn off the power supply when the faster band is about 2 cm from the loading wells. Remove the gel tray, and carefully slide the gel into a glass carrying dish.
11. View the gel on the UV light box. Be sure to use the protective perspex box cover , and determine if bright clear bands are present.
12. Make a note of the results, and if possible, take a photograph
You should see nothing in your negative control lane and a nice, 150 base-pair band in your sample lanes. If you get this result, then you have successfully amplified and visualized a 150 bp fragment of a sturgeon cytochrome b mitochondrial gene!
13. Photograph the gel if you wish. Remember ethidium bromide is poisonous, and UV light is dangerous.
14. By repeating this process with different (specific) PCR primers, it is possible to identify each species of sturgeon
PRACTICAL 8
Species-specific PCR amplification
8.1 Setting up the PCR (Student task)
1. In this practical each student in a group will attempt to amplify the DNA from the two eggs, with a different set of primers. In this way the group will cover many of the species for which primers are available (Table 8.1)
Table 8.1
TO IDENTIFY
1. All sturgeons
2. Beluga
3. Beluga (alternate)
4. Sevruga
PRIMERS
B72 and S2a
B2 and B2a
B3 and B2a
S1 and S1a
NOTES
Tm = 53
Tm = --
Tm = --
Tm = --
5. Sevruga (alt)
6. Osetra
Both pairs must give positive results (two
S2 and S2a
G3 and S2a
G4 and S1a
Tm = --
Tm = --
Tm = -- separate reactions)
The Tm values will be checked in class. Make sure you have the correct temperatures before you start!
2. Repeat from Step 6.2.4 in Practical 6 “PCR Amplification”, adding the necessary primers.
Follow the protocol. Note that the primers and the PCR reaction conditions are different. Note your results. If you are unsure, follow the protocol below.
3. To set up the PCR mix:
Add 4
l of the appropriate template dilution to a 0.2 ml (PCR) tube. You should have three PCR tubes, including a negative control. Use water instead of DNA template in the negative control.
4. Next, add 21
µl of the PCR Master Mix that has been prepared by the instructor and is sitting on ice.
The Master Mix contains the following reactants:
RNAse free water
PCR buffer supplemented with 15 mM magnesium chloride
DNTP’s (10 mM each)
0.1 µl of 2G Fast Taq polymerase
5 . Now add 1.5 µl of each of the two primers, according to the plan of your group, to all three tubes. Be careful not to contaminate anything.
6. Spin tubes briefly at top speed in the microfuge for a few seconds.
7. Place the PCR tubes in the PCR machine. Run the PCR reaction under the parameters that will be given to you in class: (NOTE THESE CONDITIONS ARE DIFFERENT. Why?)
(Do 8.2 while the PCR is running)
8. When the runs are finished, keep them at 4° C in the fridge until you have time to complete the electrophoresis.
8.2 Agarose Gel Preparation
While the PCR is running, prepare an agarose gel.
1. Place 0.32 g of agarose into a 125 ml Erlenmeyer flask. Add 45 ml of 1X TBE buffer.
2. Microwave the solution until it boils (about a minute and a half).
3. Let the gel cool at room temperature till hot but not burning to the touch. (Touch the flask to your cheek!)
4. At this point, add 2
l of a 1 mg/ml solution of ethidium bromide to the side of the flask above the hot mixture of agarose. Swirl the flask to mix.
CAUTION!!
Since ethidium bromide intercalates between the bases of DNA, it is a potential carcinogen. Handle with care.
5. Cast the gel according to the directions that come with your gel tray —you can use masking tape to seal the ends, or some trays come with rubber “gaskets” that fit over the ends and effectively seal it. Place your tray on a level surface. Place a 8-12 well comb into the tray. Pour the gel quickly. Push any bubbles to the side with a yellow micropipette tip.
6. The gel should be set after about 20 minutes
—it will turn opaque and you may see wavy lines running through it. Leave it until the PCR is complete.
7. Pull out the comb by wiggling it gently as you pull —this takes a little practice. Take off the tape or the rubber gaskets.
8.3 Loading and running a gel
1. Place the gel in an electrophoresis chamber. Cover the gel with 1X TBE. The buffer should just barely cover the gel.
2. Prepare to load the gel. Take a small piece of parafilm and place it down flat on the lab bench.
3. Add dots of 1
—one for each sample that you will load. Include a positive control (PCR product from Practical 6 and 7), and a negative control.
The size ladder (digest) already has loading dye added, and so does not need any more. Load your two samples, the positive and negative controls, and a size ladder.
4. Spin tubes briefly at top speed in the microfuge for a few seconds.
5. Make a key of the order of your samples that you will be loading into your gel in your notebook.
6. Mix your samples with loading dye, which:
(a) contains sucrose which is dense so that the samples do not float out of the gel and
(b) contains two dyes that will separate upon migration through the gel.
Add 2
l of each sample to the green loading dye dot and mix by pipetting up and down once.
7. Carefully add your samples to the wells under the liquid. Then turn on the power supply and set the voltage at 90 volts.
8. You will notice that the loading dye will separate out into a dark blue and a yellow band.
9. Turn off the power supply when the faster yellow band reaches 2 cm from the loading wells.
10. Place the gel in a glass dish.
11. View the gel on the UV light box. Be sure to use a protective face shield or box cover , and determine if bright clear bands are present.
12.Identify the species (if any) represented on the gel according to Table 8.1.
13. Photograph the gel if you wish. Remember ethidium bromide is poisonous, and UV light is dangerous.
14. Combining the results from the whole group, which species of sturgeon are represented?
15. Write up the results of this mini-project as a brief scientific paper, following all the conventions you have been given.
DO EITHER PRACTICAL 8 OR PRACTICAL 9 AS YOUR
PRACTICAL TEST
PRACTICAL 9 (Maximum of 100 marks)
Epidemics in wild populations [Part D of evaluation]
This is a student-directed mini-project, that must be completed and submitted in your practical books before the end of the course.
9.1 Background
Amphibian populations are known to be in decline worldwide, with nearly one-third of all species under some level of threat and at risk of extinction. In the last few years there have been many reports of populations of frogs in Australia, South America, and elsewhere, suddenly going extinct.
Many of these species were in Natural Parks and other pristine areas. It has been discovered that a skin fungus is associated with most of the extinctions.
This chytrid fungus is called Batrachochytrium dendrobatidis , or just ‘chytrid’ for short. MAKE TIME
TO SEARCH THE WEB FOR BACKGROUND ON THIS PROBLEM. There are a large number of publications both on amphibian decline, and on the infectious agent, the chytrid.
The fungus is usually located in the skin of the foot of aquatic species. The original means of detection was to remove the last phalanx from a toe, and then make a series of thin sections, stain these, and examine them under a microscope. The fungus is visible as a series of vesicles sometimes containing zoospores. This method is time-consuming and requires a great deal of experience and patience, especially in a low-level infection.
The use of PCR to identify infections was developed in 2004 (Annis et al 2004), and this method can be used on shed skin, and on swabs taken from live animals. This molecular technique thus allows conservation geneticists to determine if the infection is present, and what proportion of the animals are infected. Wild populations can be quickly surveyed, without harming the animals.
The PCR amplifies part of the highly variable ITS region (Internally Transcribed Spacer) of the mitochondrion. The primer sequences are:
Bd1a: 5’-CAGTGTGCCATATGTCACG-3’
Bd2a:
5’-CATGGTTCATATCTGTCCAG-3’
In this practical, you will be working in small groups to
1) Keep a live frog Xenopus laevis , in clean water, and fed
2) Take a skin swab
3) Extract DNA and test for chytrid using PCR. (The primers Bd1a and Bd2a are available)
4) Use DNA extracted from a culture of chytrid as a positive control.
5) Determine an appropriate annealing temperature
6) Demonstrate that your frog does (or does not) have a chytrid infection.
Check with your instructor for the appropriate PCR conditions if you can not locate them. (be prepared to donate some marks!)
Hand in the report in the form of a scientific paper, using all the conventions that you have been given.
CONSERVATION BIOLOGY (4
th
Term)
PRACTICALS 1-2
Hunters, Gatherers and Agriculturalists
Before coming to the first Practical please view Video 1 & 2 of the series Stories from the Stone
Age produced by the Australian Broadcasting Corporation.
You will need to have prepared notes from your viewing. The class will be divided into four groups and each group will be given a topic to present at the end of the practical via the flip charts/white boards.
For the second practical you will explore BBC channel 4 History of the World in 100 objects.
You will note the each object it will have a place of manufacture, what it is manufactured of and when it was manufactured. There is a short description of the object that justifies its selection.
This is the structure for a group assignment “Impact of Humans on biodiversity through 80 objects”. http://www.bbc.co.uk/ahistoryoftheworld/
You are not expected to know material from this site, simply to see how information is presented in clear and logical structure.
Each student will be given FOUR objects from the following list:
Objects/Inventions that have impacted on Biodiversity Conservation
1. Aeroplanes 2. Iron
3. AK47 Machine Gun
5. Archimedes screw
7. Ballast (Boats)
9. Batteries
11. Bee Hives
13. Beer/Wine (Fermentation)
15. Bow and Arrow
17. Bronze
19. Cemeteries
21. Chain Saw
23. Chemical fertilizers
25. Chicken
27. Clay Bricks
29. Clay pots
31. Clovis point
33. Coal
35. Colt 45
37. Commercial Lending Banks
39. Concrete
41. Copper
4. Irrigation channels
6. Jet Engine
8. Land mines
10. Leather/Hides (Tanning)
12. Millstones (Grinding stones)
14. Model T Ford
16. Money (Coins and Paper)
18. Motorway/Freeways
20. Needle/Sowing
22. Olives
24. Paper
26. Patents/Royalties
28. Baskets/weaving
30. Petrol/Gasoline
32. Pigments and Paints
34. Plastics
36. Plough
38. Poisons/Insecticides/Herbicides
40. Potato
42. Printing Press
43. Cosmetics
45. Cotton
47. Dams
49. Diamonds
51. Electric light bulb
53. Electrical Motor
55. Electricity
57. Fishing hooks - long-line fishing
59. Fluorescent Light Bulb
61. Fruit trees/Orchards
63. Gin Traps and Snares
65. Glass
67. Glue
69. GMO Food
71. Granaries
73. Gun Powder
44. Radio/TV broadcasting
46. Rail Roads
48. Refrigeration
50. Rope
52. Sail (Sailing boats)
54. Saw Mill
56. Sickles
58. Slings and slingshots
60. Soaps/Detergents
62. Spices
64. Steel
66. Sugar
68. Tar/Bitumen
70. Throwing sticks
72. Vaccine
74. Water-wheel
75. Hamburger
77. Harpoon
76. Wheat fields
78. Wind Mills
79. Incandescent Light Bulb 80. Wool and Weaving
The objects may be very specific or very broad. If a broad object is selected, you may narrow it down to a specific object. For each object you will need to identify the following information
1) When it was first manufactured
2) Where it was manufactured
3) Picture of this object (no bigger than 800 resolution in length and width)
4) Significant variations on the basic design (could include up to four further images)
5) Why you think it has impacted on Biodiversity Conservation in at least 200 words (mostly negative but could be positive or both)
A Prezi presentation (http://prezi.com/ ) will be set up for the entire class to submit their material, with one object each week is to be submitted . A Prezi presentation is a mixture of a concept map and a Power Point Presentation and is viewable on-line. The form of a presentation will be a
Time-Line and you will use this as a template. More details and instructions will be provided during the practical (including the URL).
This will create a resource for all students to use for the rest of the course in assessing Human impact on biodiversity
This section will be included in your final report and will count 20%
Practicals 3 & 4: Populating the world through to the
Industrialists of the World. Introduction to the Portfolio
Projects
Before coming to the third Practical please view Videos 3 of the series Stories from the Stone Age produced by the Australian Broadcasting Corporation. You also need to review and The Story of
Science – Can we have unlimited power?
You will need to have prepared notes from your viewing. The class will be divided into four groups and each group will be given a topic to present at the end of the practical via the flip charts/white boards.
For the fourth practical a start will be made on the Portfolio Projects:
Setting the scene
Each student is given a continent and has to identify a country or region or state/county (defined as an "Area of Interest") and undertakes the following research during the course.
Review how humans arrived to this continent and/or “Area of Interest” to review the pre-history that could include hunter/gather and agrarian societies).
Review the Area of Interest's recent industrialisation and current economic land use including finding finding information on land use. The CIA - The World Factbook is good starting point together with Wikipedia.
This section should have a minimum 1000 words with at least 5 references.
Students will also need to review the following material as a guide to this section.
This section of the report will count 20%
Produced by the Discovery Channel in 2002. Please review what Wikipedia has to say about
Mitochondrial Eve as a background to this video. Karen Marais from last year summarized it.
“This documentary focuses on genetic lineages traced back through the analyses of mitochondrial DNA. Mitochondrial DNA is passed on by the mother to all her descendants, as it is only the egg cell (not sperm cells) that contains mitochondria.
This explains the reference to Eve, the proverbial mother of all people. DNA undergoes random mutations at a certain rate and by analyzing the DNA from distinct populations arou nd the world, one can establish the age of “tribes” and how they relate to each other. It is through this technology that the “Out of Africa” hypothesis has now been widely accepted by scientists.”
Produced by National Geographic in 2003. Please review what Wikipedia has to say about Ychromosomal Adam as a background to this video. Karen summarized this video.
“The sex chromosomes do not get chopped up and reshuffled as the other chromosomes do during sexual reproduction. That means that a father will pass on an exact replica of his Y chromosome to his son. Sometimes a mutation occurs during replication and this mutation is then passed on to all male descendants.
These tell-tale mutations are used as markers by geneticists to trace back specific lineages. Documenting specific markers allowed them to reconstruct the most likely routes taken by our ancestors to populate the globe. Dr. Spencer Wells is a geneticist, who was part of a team of scientists that analyzed the Y-chromosome, of isolated populations. In this documentary Spencer Wells takes the viewer on a scientific tour of the routes and extraordinary detours he believes humankind took during this epic journey.
According to Wells, it all started some 50 000 – 60 000 years ago in Africa. The most ancient Y chromosome marker was found in the San people of Botswana. Thus, it is here where his journey begins. The next stop in this incredible journey is Australia, as a marker found in the south of India links the Australian Aborigines to Africa. The journey continues to south-east and then to central Asia. It is here that a marker was found that links almost all Europeans, Asians and Native Americans, hence Spencer
Wells refers to central Asia as the “nursery of humankind”. In Siberia he meets up with nomadic reindeer herders; around 13 000 years ago a group of their forefathers crossed into the Americas, populating the New World.”
Both Mitochondrial Eva and Y Chromosome Adam support an “Out of Africa” hypothesis for the origin and populating of the people of the world. In contrast is the older multi-regional hypothesis which suggests that genetic variation between the various extant human races is the result of genetic inheritance from various hominid species, or subspecies distributed from Australia, Asia, and Europe. Consequently modern Homo sapiens interbred while populating the world. I think it is fair to say there are relatively few scientists supporting this hypothesis by some recent new evidence is changing the situation. Based on a sample of 12 000 people across Asia Spencer
Wells found no traces of any ancient non-African influence. It is a little less clear whether Homo sapiens when they invaded Europe some 35 000 years interbred with the resident Homo neanderthalensis populations. Genetic analyzes are interpreted as not being the case, but morphologically a couple of skeletons suggest it did occur. Certain genes occurring in modern
Europeans appear to trace back earlier than 35 000 years e.g. red-coloured hair and suggest that there could be interbreeding. Both videos have rather left the impression that Homo neanderthalensis was simply annihilated by Homo sapiens , but the reality is co-existence of at least 10 000 years occurred. I tend to believe in the minority opinion that some interbreeding occurred, and possibly even to suggest the present Basque/Celt people may actually be the descendants of interbreeding. Mechanism can still exist whereby most Neanderthal genes could have got “lost”. If Neanderthal had a high prevalence of rhesus negative (like modern day
Basques) where only the first born is likely to survive if they mated with a rhesus positive
(modern Homo sapiens ) their genes could certainly be lost over a 10 000 year period of contact.
Hypothesized populating of the world based on using mtDNA passed through maternal lines
Source: http://www.biocrawler.com/encyclopedia/Image:Human_mtDNA_migration.png
Hypothesized populating of the world based on using Y chromosome passed through paternal lines
Source: http://news.nationalgeographic.com/news/2002/12/photogalleries/journey_of_man/photo2.html
These two videos need to be compared with the lecture given by Michael Hammer, Research
Scientist, Division of Biotechnology and Department of Ecology and Evolutionary Biology discusses the latest discoveries about the origin of our species, including the intriguing possibility of interbreeding between our ancestors and Neandertals.
Link: http://www.youtube.com/watch?v=Ff0jwWaPlnU
Assignment Description
The really critical issue for is to contrast the different results (maps) for populating the world using
Mitochondrial DNA versus Chromosome Y. I suggest you examine how the data was collected to support each of these hypotheses. What should become evident is the role of fluctuating climate has on this process of migration, both making opportunities and marooning populations plus its impact on availability of the fossil record (consider that much evidence for past human migrations would be under sea now). Finally what habitats would they have found, and what animals would they would they have met? I will be giving access to three videos and transcripts of animals we met (Australia, North America and New Zealand) to help .
Depending on which continent is selected further information on early human impact on biodiversity can be found using the following video links (transcripts) for North America, Australia, and New Zealand. http://connected.uwc.ac.za/blog/index.php?/site/comments/transcript-bbc-monsters-north-america/ http://connected.uwc.ac.za/blog/index.php?/site/comments/transcript-bbc-monsters-we-meetaustralia1/ http://connected.uwc.ac.za/blog/index.php?/site/comments/transcript-monsters-new-zealand/
In Class we can Workshop the structure of this section in more detail.
Practicals 5-7: Time Series Analysis for analysis of recent change
(Understanding Landscape Changes, detecting changes in the environment, estimating environmental changes in the environment)
You will now have some background on possible human impact for your “Area of Interest”; you will now undertake an analysis of recent time-series change for the area. To do this there is a library of imagery from the SPOT data centre (http://free.veg.vito.be/ ) and you will need to make accounts to access the data. Students are then required to go through the article on Time Series
Change Analysis, review the Power Point presentation and to review the material in the IDRISI tutorial entitled “Time Series /Change Analysis” Chapter 19 pages 232-237 (at end of this handout).
This data is organised by continent so students can group themselves to download the data from
1989 to 2009.
The data and analysis needs to be done using the steps below.
1) Download all data for your continent for year 1998 to 2009 (all data). The data is organised into 10day periods (day 1, 11 and 21 for each month. In class the actual data will be explained.
2) Unzip the files which represent Normalised Difference Vegetation Index.
3) Convert the data from the native SPOT HDF format to Geo-Tiff (Using ENVI to Open using source as SPOT/Vegetation and then Save As Tiff/GeoTiff and ensuring you save only the Meta NDVI Pixel as the band [viz Band 1] to export and using the full scene as the export window).
4) When saving in ENVI I suggest you change the name to reflect the year, month and day e.g.
1989_april_1 and 1989_april_11 etc. This will help with labelling when you prepare your graphs.
5) Import GeoTiffs into IDRISI and you will need to ensure it is correctly spatially referenced. To do this you will need to make changes to the document file using the Metadata (this will require you to change from
“Lat/Long” to “Plate Carree” using Decimal Degrees units).
NOTE we will have added the Plate Carree projection specifications to IDRISI.
6) Using Window prepare a smaller “Area of Interest” (about 12 degrees each way – the resolution of the imagery is 1 km).
7) Check how big your image is – it should not be too big as this will make the analysis very slow.
8)
This has to be done for each “Period of Imagery” viz 36 images for each year 1999-2009 and 27 images for 1998 the year the satellite was commissioned. Your time series will therefore be for 423 periods. The easiest way to do this is to zoom to a suitable area and check using the measurement tool the extent of view. Then using the save (from composer menu) you make an
IDRISI file from which to cut the rest of the images to size. You will also need to prepare a Raster
Group File for your entire collection of images to do the windowing in one operation. This is done using using the Reformat then Window and specify the Group Layer File (viz Raster Group File) and then use your Cut image as the existing window image for the processing. It will then batch process all of your images.
9) You will need to prepare a Time Series Group file for all of your Windowed images and then run the
Time Series Module (TSA).
10) You will need to generate in Excel graphs that plot each of the most significant Component Loading against the dates (viz 1989_april_01) and ensure you adequately re-scale Y axis. For each component (see how the graphs were prepared in the Namaqualand Presentation but make sure you have some X-axis labels which are not included in these).
11) You can now interpret your results and prepare your results with very complete captions to each graph.
12) You will also need to prepare graphs showing the climatic data (which can be prepared from the
DIVA GIS and its Climate Data Envelops).
Your will use these results in your report (please look at the Power Point on Namaqualand to help you prepare your figures and to add to your reports). Your prepared data into figures will represent 10% of your project.
Change Detection Exercise:
Time Series Change Analysis using
Standardized Principal Components Analysis
INTRODUCTION
In the section covering image transformations, Principal Components Analysis was applied as a form of data compression technique. The principal aim was to identify which bands account for the largest amount of variance and thus can be selected for use in other analysis tasks like image classification or simply for purpose of image enhancement by combining information from various spectral bands. The variant of PCA used was termed unstandardized PCA because it uses the variance-covariance matrix in the calculation of eigenvalues and eigenvectors. The use of PCA in case was investigate variance patterns in the spectral domain . In this exercise we are going to apply another varianit of PCA known as the Standardized Principal Components Analysis to analyze remotely sensed data in the temporal domain . The implementation of Standardized PCA is based on the the use of a correlation matrix which is derived from the covariance matrix by dividing by the standard deviation to produce a matrix of standard scores. This procedure has been found to be very useful in the analysis of time series data sets where the interest is in the identification of phenomena or signals that propagate over time. Often it is applied to single band data (for example vegetation index maps) which map only one given phenomena over the land surface e.g. vegetation greenness. The standardization is intended to minimize the undue influence of other extraneous factors e.g. atmospheric interference (aerosols and water vapour), changes surface illumination conditions, e.t.c.. In this way the different time variance patterns of the phenomena of interest (in this case vegetation) can be extracted from the time series measurements effectively.
THE TIME SERIES DATA
The data set used for this exercise consists of 60 monthly NDVI images (which we can consider to be bands in a spectral sense) for Africa. The data set is part of USAID/FEWS time series archive stretching back to 1981. The data set is processed at NASA Goddard Space Flight Centre to support both FEWS and FAO's famine early warning activities. The time series that we will use in this exercise is covers the period January 1986 to December 1990. This period of special interest because it will enable us to investigate a number of patterns of variations related to various factors that influence vegetation reflectance patterns both bioclimatic and noise due to sensor instrument characteristics. Each image has 256 columns by 320 rows. The original data was registered to an 8km grid, we have contracted by averaging to 30km grid as a filter for high frequency noise related to topographic variability. This spatial averaging procedures enables us to identify a number of time signals of interest including those related to patterns of inter-annual variability from vegetation index data. The images are named JAN86GV.IMG .. DEC90.IMG. Each image file has a corresponding documentation file thus named JAN86GV.DOC..DEC90GV.DOC.doc. Ancillary information includes a series of vector files : COUNTRYH.VEC (country boundaries), COASTH.VEC (continental coastline),
LAKESH.VEC (lakes) and RIVERSH.VEC (major rivers).
PROCEDURE
NDVI Image exploration
P1.
Use the display system of your software to examine the images named JAN86GV and AUG86GV. These two images show the levels of NDVI over Africa for January 1986 and August 1986 respectively. As you can note the highest levels of NDVI are located in the southern hemisphere in January and in the northern hemisphere in August.
This show in a broad manner the variation in the pattern and location of maximum vegetation greenness that is related to the climatic growing seasons. In general desert areas (the Sahara in the north, and Namib - Kalahari in southwest)
show low levels of NDVI irrespective of the NDVI as they are largely devoid of vegetation. You can visually examine the images for the remaining months in 1986 using your display system.
Figure 1. Normalized Difference Vegetation Index maps for January 1986 (left) and August 1986 (right)
Standardized PCA Analysis of NDVI time series data
P2.
Now run your software's Principal Component Analysis routine. Specify the name of your time series file (that list the images to be used in this procedure) or select them from your list of data files. Make sure your images are input sequentially from January 1986 to December 1990. Elect to use the Standardized option. Indicate that you wish to output 8 component images and if required enter the names of the output images. This procedure should take you less 30 minutes depending on the speed of your computer. Note that we can output up to 60 components if we wanted to. You may be required to scale your output images, choose whatever default option is required by your software system.
When your software is finished analyzing the data you will have a number of outputs. For the purpose of this exercise, two forms of output are important : the component images and component loadings and per cent variance explained by each component (See Figure 1 below). The loadings are a measure of the degree of correlation between each original monthly input image and the new component patterns. The component loadings are very useful in interpreting the component patterns in this exercise.
In order to explore further our results we can plot the loadings statistics in any statistical analysis package or using your analysis system. Plot graphs for each of the components with the months on the x-axis and the loadings values on the y-axis. For example below is the type of loadings output you should get shown in Figure 2.
Figure 2. An example of component loadings output from Standardized PCA analysis
P3.
Use your software system to display Component 1 and also the component loadings chart for component
1 in your statistical analysis system.
Q1. What is the per cent variance accounted for Component 1.
Q2. Using the loading graph, what can you infer from the loadings pattern between the original input images and Component 1.
Figure 3. Component 1 spatial pattern (left) and loadings chart at right
P4.
Use your system to display Component 2 image. Also display the loadings chart for Component 2.
Q2. What is the percentage variance accounted from Component 2 ? Using the loadings chart, which months in the series have high positive loadings on Component ? and which ones have high negative loadings ?
Describe the spatial pattern shown by Component 2.
Figure 4. Component 1 spatial pattern (left) and loadings chart at right
P5.
Use your display systems to view Components 4 to 8 and their respective component loadings charts. As in T-PCQ2 above note the amount of variance accounted for by each component and describe the component spatial pattern using the respective loadings graph.
Figure 5. Component 3 spatial pattern (left) and loadings chart at right
Figure 6. Component 4 spatial pattern (left) and loadings chart at right
Figure 7. Component 5 spatial pattern (left) and loadings chart at right
Figure 8. Component 6 spatial pattern (left) and loadings chart at right
Figure 9. Component 7 spatial pattern (left) and loadings chart at right
Figure 10. Component 8 spatial pattern (left) and loadings chart at right
If you have finished examining the eight components you can take a look at any of the later components and compare the spatial and loadings patterns with the higher level components.
OBSERVATIONS
This exercise raises a number of issues regarding the application of standardized PCA in the temporal domain. Unlike in the spectral domain using unstandized PCA, in this case we are investigating variability of the given phenomena
(e.g. NDVI) overtime. PCA allows us to segregate the various patterns of variability embedded in time series data set into different components. We treat the time measurement maps as "spectral bands" thus taken as a time series each
pixel and thus each map contains information about the variance characteristics of the given phenomena. We can use the same technique to process a time series images of LANDSAT TM data used in the exercise on Principal
Components Analysis.
The are a number of important observations we can infer from this exercise. Component 1 shows a pattern that is similar to a typical continental vegetation map of Africa. The loadings indicate that all the months are highly correlated with this patterns, with loadings over 0.90. This component alone accounts for 96.7 per cent of the variance in the 60 months time series. However, in time series sense our interest is not really in examining the typical patterns but rather on the change patterns or the atypical components. Component 2 is such an atypical component. It is computed from the residuals after the variance accounted for by Component 1 are removed. Component 2 accounts for only 1.97 of the entire continental scale variance. It however contains very useful information on the seasonality patterns of vegetation. As can be seen in figure 4 it shows a strong positive NDVI anomaly pattern in band stretching from
Senegal to Ethiopia in the northern hemisphere (green areas) and negative anomaly in the southern hemisphere (red to deep blue). As illustrated by the component loadings, the positive anomaly in the northern hemisphere has peaks approximately in July - August and troughs from approximately November of one calendar year to April of the following year forming a sinusoidal temporal pattern. These months have positive and negative correlations with this positive spatial pattern respectively throughout the series. The reverse explanation applies to the southern hemisphere i.e. peaks in NDVI during December - March and negative anomalies in June - September. This pattern indicates the annual cycle in the flux of greenness in NDVI that is synchronized with the first mode of annual excursions of the ITCZ north and south of the equator. This mode essentially illustrates the annual cycle in greenness associated with summer and winter precipitation solstices.
Component 3 is a residual pattern from this pattern calculated after the variance accounted for by Components 1 and
2 has been removed. It accounts for only 0.28 per cent of the total variance. The spatial pattern for component three shows a positive anomaly across the Sahel and in south-eastern South Africa and a strong negative anomaly in a band immediately south of the Sahel (Figure 5). The loadings chart shows a slight bimodal time signal pattern. The positive anomalies are associated with greening in the Sahel between January and March (slight positive loadings) and between July and October. While the later period corresponds well with the peak timing of the Sahelian growing season when the ITCZ reaches its northern most position, the former seems to be an unexpected anomaly at this time of the year when there is no precipitation across the Sahel. Previous research (Eastman and Fulk, 1993), has suggested that this anomaly may be related to attenuation of the NDVI signal by preferential scattering of short-wave length radiation by aerosol dust particles that are common in the atmosphere over the region during this time of the year that is characterized by strong Harmattan winds from the Sahara in the north. This is therefore suggests a false greening that is not indicative of vegetation seasonality during the period January - March. There is also a drop in the component loadings to negative values between April and May prior to the beginning of the growing season. This anomaly is related to the increase in atmospheric water vapour content with the advance of the ITCZ into the Sahelian belt (Justice et al , 1991).
Component 4 shows positive NDVI anomalies in the Congo equatorial forest region and in parts of East Africa (Figure
6). As shown in the loadings chart, the months April, May, June and September, October, November are positively correlated with this pattern, while the rest of the months are negatively associated with this pattern. This temporal pattern illustrates the semi-annual cycle in vegetation greenness that is related to the annual cycle in precipitation associated with the equinoctial maxima of the ITCZ with peaks in April and October.
Component 5 shows a similar seasonality pattern to that of Component 4, with a strong bimodal pattern (Figure 7). In this case however, the peak in the loadings is mainly in May and November. These strongest negative anomalies occur over the desert regions and the strongest positive anomalies occur over the forested regions (e.g. the Congo
Forest). However, as can be seen in the loadings chart, the dominant trends is a progressive slight negative trend in the loadings over the 1986-1990 period that is negatively associated with the negative anomaly over the Sahara desert (thus an apparent increase in NDVI over the desert regions and decrease in NDVI over the forested regions).
This pattern of apparent greening over desert areas is attributed to anomalies in NDVI due to decay in the orbital cycle of the sensing platform. An aging NOAA-9 was in service during most this time series period, overtime its equatorial crossing time deteriorated from 16.10 hrs. to 14.20 hrs over a four year period. The effect of orbital decay is to attenuate calculated NDVI values over bare surfaces especially desert areas. Bright desert targets provide a higher reflectivity especially in the visible red wavelengths compared to the infrared at low sun angles because of differential degradation in the mapping channels since the pre-launch calibration (Teillet et al, 1990). As a consequence there is an apparent increase in calculated NDVI over desert areas (Price, 1991; Tateishi and Kajiwara, 1992). Similar anomalies have been found in analyses by Kaufaman and Holben, 1990; Eastman and Fulk (1993); Los et al (1994).
The changeover to a more stable NOAA-11, can be seen as the correlations drop to negative values in
November/December 1988 with a much more constant amplitude pattern in the loadings for the reminder of the series.
Component 6 shows a strong positive anomaly in East Africa (eastern Kenya and Ethiopia and Somalia), (Figure 8) with a pronounced bimodality indicating another double greening pattern associated with the ITCZ during its extreme northernmost position in July and another one associated with this discontinuity in December / January. There is a strong negative anomaly in the area of the Congo forest region, and slight positive anomalies in the Kalahari and along the Mediterranean coast of North Africa. The temporal pattern shows a decrease in the amplitude of the anomalies up to about November 1988 before the changeover to NOAA-11. This amplitude variation is related to the shift in the orbital cycle of the sensing and preferentially affects forested areas which appear as dark targets under low sun angle conditions and thus show and hence a decrease in the levels of NDVI over time as the sensor orbit decays..
The spatial pattern of Component 7 (Figure 9) shows a strong positive residual in NDVI across the Sahel, East Africa, and the south-eastern Africa coastal region. Examination of the loadings chart shown in figure 10.7 indicates that there were positive associations with this positive pattern in mid-1986, early to mid-1987, late 1988 to mid-1989 and early 1990, indicating anomalous high levels of NDVI in these regions at these times. Between each of these, periods of negative association can be found, indicating lower than usual levels of NDVI (e.g., early 1987, mid/late 1988, and mid to late. Thus the pattern is one which appears to oscillate with a wavelength of roughly 1.5 to 2 years and is largely inter-annual.
The image for Component 8 (Figure 10) shows a very strong and coherent positive residual over Southern Africa
(most particularly Botswana and South Africa). Positive residuals are also seen to occur in western Kenya, northeastern Uganda, southern Sudan, and Morocco. The loadings chart (Figure 10) shows negative loadings in early to mid 1987 (negative NDVI anomaly), followed by strongly positive loadings in 1988 reaching a peak in 1989 (positive
NDVI anomalies), followed by a progression back towards neutral to slightly negative association in late 1990. This pattern corresponds well with what is known as the El Niño - Southern Oscillation (ENSO) phenomena that is defines the pattern of inter-annual climate variability over the Southern Africa region by influencing the precipitation patterns and hence the patterns of vegetation greeness.
SUMMARY
In summary, the patterns shown in components 2-4 and their corresponding time correlation coefficients ( loadings ) are largely manifestations of the response of the land surface vegetation matrix to large scale seasonal changes in the precipitation fields associated with the general circulation of the atmosphere. These spatial patterns illustrate the zonal asymmetry about the equator in the NDVI variability that is related the seasonal precipitation patterns. Superimposed on these patterns, as illustrated in component 3, 5 and 6, are anomalies that are related to attenuation of the NDVI time signal that are related to atmospheric conditions and the instability in the cycle of imaging system over time.
Components 7 and 8 illustrate slowly varying patterns of variability that are associated with inter-annual phenomena.
Each of these components accounts for a smaller and smaller proportion of variance and the associated anomaly or residual spatial patterns are more regionalized or localized in space.
Figure 11. Eigenvector magnitudes as a function of principal component number. Each successive component accounts for a smaller portion of the total variance thus explaining only localized information. The magnitude of the eigenvectors decays exponentially as shown by the fitted least squares line. According to the rules of the log eigenvalue diagram (LEV) (Wilks, 1995), the ideal cut-off point could be component 9, as the bar graphs level out and approach the zero li ne.
Unlike applications of PCA as used traditionally remote sensing we cannot use the percent variance explained as a determinant for the important components to retain. We can use other measures like spatial autocorrelation or if we plotted the eigenvectors or eigenvalues on a logarithmic scale as shown in figure 11 above, we can get a sense of what is the cut-off point for the important components. Each case study however will require detailed examination of the components patterns and their associated loadings. The ability to disentangle different patterns of variability from a time series array like the one used in this study, illustrates the unique ability of principal components technique in the extraction of different types of time series phenomena from complex time series measurements in ways that may not be readily apparent from time profiles of NDVI and other change analysis methods.
CREDITS
This exercise was written by Assaf Anyamba at Clark University. The data were provided by USAID/FEWS Project.
REFERENCES
The use of Standard Principal Components Analysis in the analysis of land surface remotely sensed time series measurements has only happened in the last couple of years. The technique has been used widely in meteorology and climatology to identify propagating phenomena in geophysical data sets derived from remote sensing instruments.
For basic information on the implementation of Principal Components Analysis refer to the references in the section on Principal Components Analysis in the spectral domain. The references below will be useful for further reading on the applications and interpretation of component patterns derived from time series measurements.
Anyamba, A. and Eastman, J. R. (1996) Interannual Variability of NDVI over Africa and its relation to El Niño /
Southern Oscillation . International Journal of Remote Sensing 17(13) : 2533-2548.
Eastman, J. R.and Fulk, M .A. (1993a) Time Series Analysis of Remotely Sensed Data Using Standardized Principal
Components Analysis. Proceedings 25th International Symposium on Remote Sensing and Global Environmental
Change, Volume I.
April, 4-8, Graz - Austria. I485-I496.
Eastman, J. R. and Fulk, M. A. (1993b) Long Sequence Time Series Evaluation Using Standardized Principal
Components. Photogrammetric Engineering and Remote Sensing. 59(6): 991-996.
Eastman, J. R. and Fulk, M. A. (1992) Time Series Map Analysis Using Standardized Principal Component Analysis .
ASPRS/ACSM/RT'92 Technical Papers, Vol. 1: Global Change and Education, August 3-8, Washington, D. C. 195-
204.
Eklundh, L. and Singh, A. (1993) A comparative analysis of standardized and unstandardized Principal Components
Analysis in Remote Sensing. International Journal of Remote Sensing , 14(7): 1359-1370.
Richards, J. A. (1984) Thematic Mapping from Multitemporal Image Data Using Principal Components
Transformation. Remote Sensing of the Environment, 16: 35-46.
Singh, A. and Harrison, A. (1985) Standardized Principal Components. International Journal of Remote Sensing , 6(6):
883-896.
Tucker, C. J. and Townshend, J. R. G. and Goff, T. E. (1985) African Land-Cover Classification Using Satellite Data.
Science , 227(4685): 369-375.
Wilks, D. S., (1985) Statistical Methods in the Atmospheric Sciences.
New York: Academic Press, New York. 359-398.
Practicals 8-10: Developing Land Change Models
In class you will need to complete the following IDRISI Assignment (details at the back of the manual)
Analysing Vegetation cover as a Land use and land change indicator
(Exercise 5-7 pages 240-246)
Introduction to Land Change Modeling (LCM) and Change Analysis
(Exercise 6-1 pages 248-249)
LCM: Transitional Potential Modeling
(Exercise 6-2 pages 250-253)
LCM: Change Prediction
(Exercise 6-3) pages 254-256
LCM: Change Validation
(Exercise 6-4) pages 257-259
LCM: Dynamic Road Development
(Exercise 6-5 page 259)
LCM: Habitat Assessment, Change and Gap Analysis
(Exercise 6-6 Pages 260-262)
LCM: Species Range Polygon Refinement and Habitat Suitability
(Exercise 6-7 Pages 263-265)
LCM: Biodiversity Analysis
(Exercise 6-8 Pages 266-268)
You will need to write a report indicate what sort of data is needed and what would be suitable analyses for your Area of Interest. It is not necessary to actually get the data and to analyse it as this would take a little to be too long.
This will count 20% of your final report.
You also need to show that you have completed each of these exercises as a pre-requisite to being marked. In other words you will show that you have completed all of the above assignments. If you have say completed only two of the eight assignments you will get your report mark e.g. 6/20 * 2/8 (= .25) and therefore a final mark of 3/20.
Practicals 11-12: Analyse the Area of Interest's Conservation status
Using the World Database on Protected Areas as a starting point ( http://www.wdpa.org/ ) you will be able to build up a database and maps of a ll the Protected Areas within your “Area of Interest”.
You will need to create an account and then you can search for information using the Ais –Ais
Richtersveld as an example.
Site Name: Ais - Ais/Richtersveld
Country:
Longitude (DD):
Latitude (DD):
Designation:
South Africa
17.13668588
-28.29015205
National Park
Status:
Establishment Year:
IUCN Category:
Total Area (ha):
Site Governance:
Reference:
Brief Description:
Designated
1991
II
160962
Government Managed Protected Areas http://en.wikipedia.org/wiki/Richtersveld
Maximum 50 words (please not cut and paste – use your own words).
IUCN Protected Area Classification
Ia - Strict Nature Reserve
Strictly protected areas set aside to protect biodiversity and also possibly geological/ geomorphological features, where human visitation, use and impacts are strictly controlled and limited to ensure protection of the conservation values. Such protected areas can serve as indispensable reference areas for scientific research and monitoring.
Ib - Wilderness Area
Large unmodified or slightly modified areas, retaining their natural character and influence, without permanent or significant human habitation, which are protected and managed so as to preserve their natural condition.
II - National Park
Large natural or near natural areas set aside to protect large-scale ecological processes, along with the complement of species and ecosystems characteristic of the area, which also provide a foundation for environmentally and culturally compatible spiritual, scientific, educational, recreational and visitor opportunities.
III - Natural Monument or Feature
Areas are set aside to protect a specific natural monument, which can be a landform, sea mount, submarine cavern, geological feature such as a cave or even a living feature such as an ancient grove. They are generally quite small protected areas and often have high visitor value.
IV - Habitat/Species Management Area
An area of land or sea subject to active intervention for management purposes so as to ensure the maintenance of habitats and/or to meet the requirements of specific species.
V - Protected Landscape/Seascape
An area where the interaction of people and nature over time has produced an area of distinct character with significant ecological, biological, cultural and scenic value: and where safeguarding the integrity of this interaction is vital to protecting and sustaining the area and its associated nature conservation and other values.
VI - Protected Area with Sustainable Use of Natural Resources
Protected areas which are generally large, with much of the area in a more-or-less natural condition and where a proportion is under sustainable natural resource management and where low-level use of natural resources compatible with nature conservation is seen as one of the main aims of the area.
You will also need to locate and download an ESRI shp file which has all of the protected Areas of the World e.g.
( http://www.wdpa.org/AnnualRelDownloads.aspx
From this analysis prepare a Table summarising your identified Protected Areas based on the above information (with a complete and comprehensive caption).
Preparation of this summarizing Table for your will represent 10% of your overall project.
Practicals 13-14: Demonstrate how a systematic conservation plan can be prepared for an "Area of Interest"
You will now undertake a Systematic Conservation Plan
What is Systematic Conservation Planning?
Systematic conservation planning provides a guide for the process of selecting conservation areas to meet objectives of the representivity and persistence. Conservation planning therefore takes into account the location, size, connectivity and cost of future reserves. The principle of representation refers to the fact that reserves should represent the all or most of biodiversity features. Once reserves have been established, the processes that sustain species survival should be promoted. Reserves should also exclude any threats to biodiversity.
A framework for systematic conservation planning was first described by Margules & Pressey in
2000. From this framework it is apparent that throughout the planning process information is required on which areas are most vulnerable and the processes (mining, farming etc) which threatened its biodiversity. And since it is not possible to conserve everything this framework allows for the prioritization of areas that requires the most protection.
Systematic conservation planning provides a guide for the process of selecting conservation areas that meet the objectives of the principle of representation and persistence. Conservation planning therefore takes into account the location, size, connectivity and cost of future reserves.
The principle of representation refers to the fact that reserves should represent the all or most of biodiversity features. Once reserves have been established, the processes that sustain species survival should be promoted. Reserves should also exclude any threats to biodiversity.
A framework for systematic conservation planning was first described by Margules & Pressey in
2000. From this framework it is apparent that throughout the planning process information is required on which areas are most vulnerable and processes (mining, farming etc) which threatened its biodiversity. And since it is not possible to conserve everything this framework allows for the prioritization of areas that requires the most protection. The advantage of using this approach to select reserves is that it is based on the best available science, is data-driven, transparent, and defensible.
Framework for systematic conservation planning
Step 1: Identify and engage stakeholders
The needs of stakeholders often differ from person to person and from conservationists. Since the activities of certain stakeholders can represent a threat to conservation initiatives it is important that they are involved from the very beginning. Enough time and resources should be assigned to stakeholder participation.
Step 2: Determine the constraints and opportunities
Any activities that threatened biodiversity should be identified. These threats affect the opportunities and constraints for creating reserves or regions of conservation. 6
Step 3: Goals for planning process should be identified
Once threats have been identified and it has been determined how best to mitigate them through the creation of conservation areas, goals should be identified. The advantages of reserves or areas of conservation should be assessed in terms of how risks would be minimised. 6, 9
Step 4: Gather data for planning domain
The issue of biodiversity is extremely complex. It is for this reason that surrogates are often used.
Surrogates can be either habitat types, sub-sets of species or species assemblages. A continuous layer of surrogates is required for the entire planning domain to allow planners to estimate the differences between regions in the planning domain. If time allows, new data should be collected to improve or replace existing data sets. This is also the stage where planners decide on the type of planning units to be used in the planning domain. Planning units are basic units for assessment and planning. They can be either regular shaped (hexagons, squares, rectangles etc) or they can be irregular (catchments). The CAPE project used regular planning units. Regular planning units can be created in Esri’s ArcView using an extension called Repeating shapes. This extension is pretty intuitive to use and all the user has to do is input various parameters. The size of your planning units is affected by the size of your planning domain. It is also important to note that the software package CLUZ, which is often used in the systematic conservation planning, can only handle a maximum of 65 000 planning units.
CapeNature’s Fine-Scale Planning Unit is currently pioneering a new method of creating planning units using eCognition, a software programme that uses object based classification (this will be shown to you in class). The choice of planning units has huge implications on reserve design and the efficiency in which targets are met.
Step 5: Decide on targets for features
Targets are explicit quantitative goals that conservationists would like to meet in order to attain a living landscape e.g. 20% of a specific habitat type. It is imperative that targets meet the requirements of the principle of persistence and representation. Targets should also be based on the modeled spatial extent of a feature, before transformation occurred.
Step 6: Review the contribution of existing reserves in achieving target
In this stage conservation planners should identify the degree of conserved regions in each land class. The reserve network should be placed in a bioregional context. Once this is done it is possible to determine whether or not there are any geographical biases. Differentiating between reserve types i.e. statutory and non-statutory should occur. The degree to which targets are met in existing reserves can then be determined. The problem with this method is that it assumes that
100% of the biodiversity features occurring within reserves are being conserved.
Step 7: Selection of additional regions for conservation
This is the stage where conservation planning software (Marxan, CLUZ and C-Plan etc) are employed to assist in decision-making. These software programmes employ algorithms to select conservation areas.
Step 8: Implementation
Stakeholders should be consulted to ensure that any problems that might arise be minimized. The selected conservation areas with the greatest vulnerability should receive greater priority. If conservation areas selected are too degraded or prove difficult to preserve then it will be wise to return to step 7 and select other reserves. It is also imperative to look at whether there is enough resources to conserve a particular area. The most feasible management strategy should also be identified.
Step 9: Maintenance
To ensure that the biodiversity of an area persists for years to come it is important that threats be monitored. New data regarding the biodiversity of the reserve might result in the revision of goals.
Management strategies should therefore be adaptive.
Marxan
Marxan was developed in 1996. Marxan was developed to aid the design of reserve systems. The basic idea is that the reserve designer has a large number of potential sites or planning units from which to select a reserve system. Using Marxan it is possible to devise a reserve system that satisfies a number of ecological, social & economic criteria. Each planning unit is assigned a cost value based on its area, financial value, opportunity cost of it being protected (loss of income from farming) or any other relevant factor. Marxan calculates the combined cost of all the planning units in the portfolio. If a planning unit doesn’t contribute to your target then you get penalized. Marxan also allows one to give specific species (endangered species) a higher quality factor. After you have selected all your planning units Marxan also looks at the boundary length. The greater the boundary length (edges of planning unit) the greater the boundary costs – this maximizes connectivity. Marxan was basically designed to automate the design process so that a designer can try many different scenarios and see what the resulting reserve systems might look like.
CLUZ (Conservation Land-Use Zoning)
CLUZ was basically created to act as a user-friendly interface between Marxan. CLUZ and accompanying tutorial data can be downloaded from http://www.kent.ac.uk/anthropology/dice/cluz/
What is the Fine-Scale Planning (FSP) Project?
The FSP project is a four-year project is funded by GEF. CapeNature is leading the way to realizing this dream and are in collaboration with the South African National Biodiversity Institute
(SANBI). This project has two main objectives:
to undertake fine-scale analysis
to develop conservation plans and guidelines 8
To meet their first objective the unit has to come up with a product that can be used at a
1:10 000 to 1:50 000 scale. They also have to develop and incorporate new data e.g. landcover, and use the process of systematic conservation planning. 8. One of the revolutionary new approaches that the FSP unit has developed is their creation of planning units using the software programme, eCognition. eCognition segments the planning domain into units based on similar spectral and spatial patterns. 8
The FSP is also currently busy developing new rules that will allow for the improvement of landcover data.
References
Ball, I. & Possingham, H. (2000) Marxan (v1.8.2), Marine Reserve Design using Spatially Explicit
Annealing. The University of Queensland, Australia. Retrieved September 7, 2007. Available at: http://www.ecology.uq.edu.au/index.html?page=20882
Wikipedia contributors. (2007) Marxan. Wikipedia, The Free Encyclopedia. Retrieved September
7, 2007. Available at: http://en.wikipedia.org/wiki/Marxan
Wilson, K, Pressey, R.L., Newton, A., Burgman, M.A., Possingham, H., and Weston, C. (2005)
Measuring and incorporating vulnerability into conservation planning. Earth and Environmental
Science. Volume 35, Springer New York
Margules, C.R. & Pressey, R.L. (2000) Systematic conservation planning. Nature, Vol 405.
Macmillian Magazines Ltd. Retrieved September 7, 2007. Available at: www.sam.sdu.dk/fame/menu/pdfnov/margules.pdf
Systematic Conservation using Marxan and CLUZ (Extracted from DICE, University of Kent &
Darwin Initiative. (unknown). A tutorial for using CLUZ. DICE, University of Kent. Available at: http://www.kent.ac.uk/anthropology/dice/cluz/ )
Systematic conservation planning involves setting targets for a number of conservation features and identifying portfolios of planning units that, when combined, meet these targets. The real-world relevance of these portfolios can be further enhanced by including a range of political and socio-economic data into the planning process and by identifying patches of suitable units, which are more ecologically viable and easier to manage.
However, it is generally near-impossible to identify the best portfolio for meeting all these requirements because there are so many different potential combinations of planning units to investigate. For example, when dealing with 100 planning units there are 2 or
1,260,000,000,000,000,000,000,000,000,000 different combinations that would need to be assessed to identify the best portfolio. Fortunately, mathematicians have developed a way around this problem that identifies near-optimal portfolios by using a process called simulated annealing .
Moreover, simulated annealing is often more useful than optimisation techniques that have also been developed by mathematicians. This is because identifying a large number of near-optimal portfolios is often more useful than identifying one optimal solution, as this allows planners more flexibility when designing conservation networks.
Marxan is a conservation planning program that uses simulated annealing to identify efficient portfolios and CLUZ acts as a user-friendly interface for this process. The following web pages explain more about simulated annealing and the
Marxan outputs that can be produced using CLUZ:
An explanation of the outputs produced by MARXAN (section 1)
An introduction to simulated annealing
Simulated annealing is the process at the heart of the MARXAN conservation planning software and its results can be displayed and manipulated using CLUZ. Sections 2 and 3 of this explanation describe how MARXAN uses this technique but this page explains how simulated annealing works by using an analogy based on robot exploration.
Searching for life on Mars: a contrived analogy.
Imagine that the UK Government funded a project to look for life on Mars based on advice that it was most likely to be found in low-lying areas. The problem of finding the lowestlying area on Mars is similar to the problem of finding the most efficient planning portfolio, in that there are a huge number of alternatives to choose between. This is why the Chief
Scientist decided to develop robots that used a searching process based on simulated annealing. An example of the robot is shown on the left and it has four arms spaced equally around its diameter.
1) Iterative improvement
The first element of the simulated annealing process is based on iterative improvement. This means that the robot repeatedly follows the same set of rules to gradually locate low-lying areas. In this case the set of rules that the robots follows are:
1. Measure the elevation of the ground directly beneath the robot body.
2. Randomly choose an arm and measure the elevation of the ground beneath the arm.
3. If the ground beneath the arm is lower than the robot base then move to the point that was measured by the arm.
So if the robot was dropped by parachute onto the surface of Mars then it would move step-by-step downhill until it reached the valley bottom.
However, this strategy has a flaw, because it results in a process where the robot will never go uphill, and so won't locate lower areas on the other side of the valley in which it lands.
The result of the problem is illustrated here. The robot has moved to the bottom of the valley but there are deeper valleys elsewhere on the Mars surface.
The same problem occurs when choosing lowcost portfolios. By only accepting short term improvements, it is likely that more effective portfolios will be missed.
2) Random backward steps
One way to reduce this problem is to add a random element to the iterative process, so that the robot occasionally moves up a slope in the hope that it might move into neighbouring, lower-lying valleys. These backward steps are generally more effective just after the robot has landed, before it has moved far down the original valley slope, so the simulated annealing process ensures that they tend to occur at the beginning of the iterative improvement process.
The value of this process is illustrated here. The left figure shows the robot landing and, at random, moving uphill.
The right figure shows the iterative improvement process that follows, which allows the robot to find the bottom of the new valley that it has entered.
3) Repetition
The final way to increase the chances of finding the lowest-lying area is to repeat the process a number of times. This is illustrated below, where a number of robots are shown dropping to the surface of Mars.
This combination of 1) iterative improvement, 2) random backward steps towards the beginning of the process and 3) repetition, help ensure that the low-lying areas will be found. Increasing the number of iterations and increasing the number of repeats will also increase the likelihood of finding low-lying areas. However, increasing the number of iterations beyond a certain point will not increase the likelihood of finding low-lying areas. For example, it would be ineffective to increase the number of iterations so that the robot continued to search even when it was likely to have reached the valley bottom.
An explanation of the outputs produced by MARXAN (section 2)
How MARXAN works
Section 1 of this explanation illustrated the process of simulated annealing using an analogy based on designing a robot to find low-lying areas on the surface of Mars. Part of the iterative process that the robot used involved measuring its elevation, as it needed this information to calculate whether changing its location would result in moving to a lower-lying position.
MARXAN needs similar information to calculate whether a particular change to a portfolio would improve its effectiveness. It does this by calculating the cost of each portfolio, where effective portfolios have the lowest costs.
The portfolio cost consists of the following parts:
1) The combined planning unit cost
Each planning unit is assigned a cost value, based on its area, financial value, the opportunity cost of it being protected (e.g. lost income from farming) or any other relevant factor. MARXAN calculates the combined cost of all the planning units in the portfolio.
2) The boundary cost
The boundary cost measures the amount of edge that the planning units in a portfolio share with unprotected units. This means that a portfolio containing one connected patch of units will have a lower boundary cost than a number of scattered, unconnected units. The cost is quantified as the length of edge in metres, kilometres or any other measurement systems. MARXAN then multiplies this value by the Boundary Length
Modifier ( BLM ) constant, which is a user-defined number. Increasing this number increases the cost of having a fragmented portfolio.
3) Species penalty factor (or target penalty cost)
MARXAN calculates whether the target for each conservation feature is met by a portfolio and includes a cost for any target that has not been meet. A separate penalty value can be set for each conservation feature, although CLUZ aims to produce portfolios that meet all the targets by automatically setting a very high penalty for each target. The MARXAN literature refers to these penalty values as species penalty factors .
The total cost of a portfolio combines these three costs and is calculated as:
Combined planning unit cost + (boundary cost * BLM) + Combined species penalty factors
An example of calculating portfolio costs
This example uses a hypothetical planning exercise based on three vertebrate species (a mouse, a fish and a butterfly) and nine planning units. The distributions of the three species is shown below:
Each one of the planning units is 1 km x 1 km, so the planning unit (PU) cost of each unit is set as 1, the boundary is measured in kilometres and the boundary length modifier value is set as 1.5. The targets are that each species should be represented at least once in the portfolio and the species penalty factor for all three species is 10.
The diagrams below calculate the portfolio cost for two portfolios selected at random:
Portfolio A
Total PU cost = 4 Boundary cost = 12 * BLM SPF = 10
Portfolio B
Total PU cost = 4 Boundary cost = 8 * BLM SPF = 0
Portfolio A contains 4 units, has a boundary length (shown in red) of 12 and fails to represent the fish. Portfolio B contains 4 units, has a boundary length of 8 and meets all of the representation target. Therefore, the total cost for each portfolio is:
Portfolio A total cost = 4 + (12 * 1.5) + 10 = 32
Portfolio B total cost = 4 + (8 * 1.5) + 0 = 16
Incorporating viability into MARXAN costs
MARXAN can also incorporate population and ecological viability issues into the planning process. It does this by letting the user specify the minimum viable clump size for each conservation feature and only counting viable clumps when determining whether the conservation targets have been met. This feature can also be used to set targets for the number of clumps, so that a target for a particular species could be 20,000 ha of habitat made up of at least 3 clumps of a minimum size of 6,000 ha.
Extra features of MARXAN
The description above slightly simplifies the process that MARXAN uses to calculate the total portfolio cost, as it fails to mention the Cost Threshold Penalty (CPF). The CPF function allows the user to set the maximum total portfolio cost, so that an extra cost is added if the portfolio cost goes beyond the specified threshold. This means the user can ensure that MARXAN identifies portfolios that are less costly than a specified value, although these portfolios may be less effective at meeting the other specified targets.
The CPF feature is not included when CLUZ runs MARXAN (ie CLUZ sets the CPF value as 0). This is because the
CPF cost is based on the total planning portfolio cost, which combines the planning unit and boundary costs.
Beginners generally find it difficult to estimate the preferred total cost because it involves two separate elements which are measured in different ways. For example, the planning unit cost might be measured in dollars while the boundary cost is measured in kilometres. Advanced users who want to incorporate the CPF feature can run MARXAN independently and import the results into CLUZ.
An explanation of the outputs produced by MARXAN (section 3)
As described in section 1, MARXAN uses simulated annealing to identify efficient conservation portfolios and this process consist of three main elements described below:
1) Iterative improvement
MARXAN starts by creating a portfolio based on randomly selecting a number of planning units. It then improves on this random selection by using iterative improvement, ie one that is based on repeating the same simple set of rules a number of times to reduce the cost of the planning portfolio. In MARXAN's case the rules are:
1. Calculate the cost of the planning portfolio.
2. Choose a planning unit at random and change its portfolio status (ie change a protected unit to being unprotected or change an unprotected unit to being protected).
3. Calculate the new cost of the changed planning portfolio.
4. If the new portfolio has a lower cost than the original portfolio then make the change permanent. Otherwise, do not make the change.
This is one iteration and MARXAN can be used to repeat the process a number of times, so that the portfolio cost is gradually reduced. In general, a conservation planning exercise will use a large number of iterations (the CLUZ default is one million) but the illustration below shows the results of a process based on three iterations.
This illustration uses the planning example described in section 2of this explanation, which focussed on 9 planning units and 3 species. Each planning unit has a PU cost of 1, the BLM = 1.5 and the SPF cost = 10.
The random portfolio produced by MARXAN, which has a total cost of 32, is shown in iteration one and the following diagrams show each of the three iterations in turn:
Iteration 1:
Randomly selected unit
Iteration 2:
Total cost = 32 Total cost = 23
Randomly selected unit
Iteration 3:
Total cost = 23 Total cost = 26
Total cost = 23 Total cost = 22 Randomly selected unit
The three iterations produced two improvements to the portfolio and reduced the total portfolio cost from 32 to 22.
Increasing the number of iterations would probably have reduced the cost even further, although setting a very large number of iterations does not bring corresponding improvements in the cost of the final portfolio.
2) Random and occasional cost increase
The iterative improvement illustrated above is unlikely to identify the most effective portfolio. This is because it cannot make changes that increase the portfolio cost in the short term but would allow long term improvements.
MARXAN overcomes this problem by including a process that allows changes to the portfolio that increases the cost value. This is incorporated into the iterative process, so that when MARXAN checks whether the random change to the portfolio reduces the total cost it will occasionally allow changes that make the portfolio more costly. MARXAN is more likely to accept changes that will increase the portfolio cost at the beginning of the iterative process, as this is when these "backward steps" are most likely to produce long-term benefits. In addition, MARXAN is influenced by the size of the cost increase and is also more likely to accept large cost increases at the beginning of the process.
This feature of allowing backward steps in the iterative improvement process is illustrated below using the same set of
9 planning units containing three species. The distribution of these three species is shown again on the left.
The diagram shows two iterations, where the first increases the cost of the portfolio from 24 to 27 but is still accepted.
The second iteration is a standard example of iterative improvement, with the portfolio cost going from 27 to 14, but the previous backward step made this large improvement possible.
3) Repetition and irreplaceability scores
Finally, MARXAN can run the process described above a number of times, which also increases the chances of finding a low-cost portfolio. MARXAN then identifies the most efficient portfolio from the different runs but the information from each of the runs can also be used to provide important information. MARXAN does this by counting the number of times a planning unit appeared in the different portfolios produced by the different runs.
This is illustrated below, where MARXAN carried out five runs and identified five portfolios that are shown on the left.
All of these portfolios met the representation targets but the best one, that is the one with the lowest cost, is shown on the right. Also on the right is the "summed solution" output, which shows the number of times each unit appeared in those five portfolios. You can see that this "summed solution" output provides important information about each of the planning units, whereas the best result only shows whether each unit belongs to the best portfolio.
Best result Summed solution
This summed solution is useful in that it lets planners distinguish between units that are important for producing lowcost portfolios and those that could be swapped with other, similar units. For example, the figures below show the two types of MARXAN output that are displayed in CLUZ. The best result, ie the least-costly portfolio identified, shows a potential conservation plan for a region but the summed solution results show which parts of that plan are most important (in red) and which could be swapped with other units (in yellow).
The best result Summed solution (highest scores in red)
The summed solution scores are similar to the irreplaceability scores produced by the C-Plan conservation planning software. The main difference is that irreplaceability scores are based on determining the total number of different portfolios that would meet the representation targets. The irreplaceability score for a particular unit is then calculated as the number of possible portfolios that contain the unit divided by the total number of possible portfolios.
The summed solution in MARXAN is not based on the total possible number of portfolios but the number of runs specified by the user. In addition, each of these runs is designed to produce a low-cost portfolio.
Final details on the MARXAN parameters used by CLUZ
CLUZ has been designed to provide all of the important features of MARXAN in a way that can be understood by beginners. This means that it uses one mathematical approach to identifying low-cost portfolios, as this generally produces the best results. In addition, CLUZ does not allow the user to change several of the underlying parameters
but let MARXAN identify the best parameters instead. However, some experienced user may wish to experiment with changing these parameters and this can be done by running MARXAN independently and importing the results into
CLUZ.
Experienced users may also be interested in knowing the MARXAN settings that CLUZ uses, so that they can investigate other approaches. These settings are that CLUZ uses simulated annealing, with the adaptive annealing option, followed by the iterative improvement run and no cost threshold. Anyone interested in learning more about the extra features in MARXAN should read the MARXAN manual.
We also recommend that you try the reserve design game that has been developed by Wayne
Rochester and Hugh Possingham at The University of Queensland.
Once having read through the process of MARXAN you can now undertake the IDRISI Exercise 6-
9 Reserve Selection (pages 269-273). You will need to use the latest IDRISI TAIGA and will have
14 days in which to complete it from installation of the evaluation copy.
In the final section of the project report you will prepare a 1000 word conservation implication plan that also includes at least 5 references. This section will count 20% .
The combination of these reports will be compiled together and evaluated as one report and if improvements have been made based on feedback the total mark will be adjusted upwards.
Project Write-up summary (18% of Total Course)
Objects/Inventions that have impacted on Biodiversity Conservation (20%)
Review how humans arrived to this continent and/or “Area of Interest” to review the pre-history that could include hunter/gather and agrarian societies). (10%)
Review the Area of Interest's recent industrialisation and current economic land use including finding information on land use. (10%)
Results of recent change in your Area of Interest based on the time series analysis. Prepared as figures with complete captions. (10%)
Implementing Land Change Models for your Area of Interest (20%)
Preparing a Table summarising your identified Protected Areas for your Area of Interest (10%)
Implementing a Systematic Conservation plan for your Area of Interest (20%)