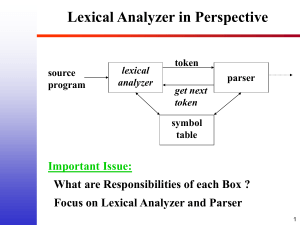
Role of Lexical Analyser:
advertisement

Role of Lexical Analyser: First phase of a compiler. Main task is to read the input characters and produce the sequence of tokens that the parser uses for syntax analysis. It does dual tasks: one stripping out the various tokens from the input and also associating error messages. Sometimes they are divided into scanners and lexical analysis. Issues with Lexical Analysis: If parser does the work of reading the tokens, identifying the tokens and also parsing them , than parser’s task would be complex. Hence before paring a phase of lexical analysis is associated for doing these works. Compiler’s efficiency would increase Compiler’s protability would increase: input related problems would be delt by lexical analyzer would be solved by it. Tokens, Patterns, Lexemes Token A lexical token is a sequence of characters that can be treated as a unit in the grammar of the programming languages. Example of tokens: Type token (id, num, real, . . . ) Punctuation tokens (IF, void, return, . . . ) Alphabetic tokens (keywords) Example of non-tokens: Comments, preprocessor directive, macros, blanks, tabs, newline, . . . Patterns There is a set of strings in the input for which the same token is produced as output. This set of strings is described by a rule called a pattern associated with the token. Regular expressions are an important notation for specifying patterns. For example, the pattern for the Pascal identifier token, id, is: id → letter (letter | digit)*. Lexeme A lexeme is a sequence of characters in the source program that is matched by the pattern for a token. For example, the pattern for the RELOP token contains six lexemes ( =, < >, <, < =, >, >=) so the lexical analyzer should return a RELOP token to parser whenever it sees any one of the six. Consider the following line of Pascal text: 1:if a=0 then a:=b; (* entry := default *) It contains 12 lexemes: 1, :, if, a, =, 0, then, a, :=, b, ;, and (* entry := default *). The last lexeme matches the pattern for comments and does not have a corresponding token. The tokens for the other lexemes might be as follows: label, colon, keyword, id, equal, integer, keyword, id, assign, id, and semicolon. We divide the task of the lexer into two subtasks: scanning and conversion. Scanning refers to the act of identifying a source character sequence as an instance of a class of tokens, i.e., finding a lexeme. Conversion refers to the act of obtaining the representation and attributes of the particular lexeme that has been identified. Tokens are terminal symbols in CFG. So when in the above example pi is identified by the lexer as token, then it will be sent to the parser in the form of a number named id Attributes of the Tokens: If a situation is such where one lexemes belongs more than one pattern than what token should we associate with it. For example if in the source programme there are many constatant numbers falling under the category of pattern num than we have to associate values of the number pattern to identify them separately. Lexical Errors: Input buffering: