CS 332: Algorithms
advertisement

CS30003: Compilers
Lexical Analysis
Lecture Date: 05/08/13
Submission By:
DHANJIT DAS,
11CS10012
What are Lexemes?
Before understanding “lexical analysis” let's
understand what is a Lexeme in brief
■ Lexemes are a stream of characters which can be
grouped together based on a specific pattern.
■ Patterns are the description that lexemes can
represent or can take.
■ Example: if var < tmp*6
What are the lexemes here??
Find lexemes: If var < tmp*6
If
← keyword
var ← identifier
< ← operator (logical)
tmp ← identifier
6
← constant
● Note: Space is discarded. In most compilers,
spaces are stripped out.
Token, Patterns... and Lexemes
● Generally, there are a set of string in input for
which same token is produced as output.
● Patterns is a rule that matches each string of
this set.
● Lexeme is a sequence of characters in source
program that is matched by pattern for a token.
● So, 'if' ← lexeme ; 'keyword' ← token ;
'i-f- ' ← pattern
Tokens
Sample Lexemes Patterns (informal
description)
enum
enum
enum
for
for
for
identifier
count, flag, var
letter followed by letters and digits
num
3.1416, 2, 0
a numeric constant
literal
“segmentation fault”
any characters between two
qoutation marks.
Source code is a collection of lexemes
The collection/pattern of lexemes is defined by the
programming language.
Token Tuple
● From lexemes we construct tokens.
● Token is a tuple of two elements, but may be
of only one element.
{token_name, attribute}
symbolic representation
optional
of a specific lexeme
● Example: 'if' ← when identified, set
'token_name' as 'if' and no attribute for
keywords.
● When lexical analyser encounters lexeme, it
generates the token_name and fills up the
attribute with the name, type, etc.. from the
symbol table.
● Attribute will point to the entry in the symbol
table, or memory.
● Numeric Constants: token can be
represented in three ways →
■ <2>
■ <number,2>
■ <number, ptr> ← where “ptr” is pointer to
the number stored in memory
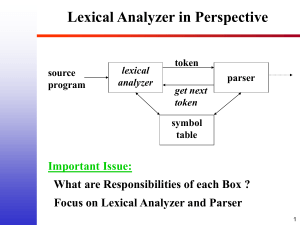
Lexical Anyalyser – Parser
relationship.
● Lexical Analyser does not read the source code
in entire go.
Source Code
Lexical
Analyser
Parser
● Produced tokens are held in a buffer until they
are consumed by parser.
● LA cannot proceed when buffer is full and
parser cannot proceed when buffer is empty.
token
Parser
Lexical Analyser
get next token
Symbol Table
● The schematic diagram is commonly implemented by
making the lexical analyser a subroutine of the parser.
● Upon receiving a “get next token” command from the
parser, the lexical analyser reads input characters until it
can identify next token.
If var < temp*6
Lexical Analyser will first read “if”.
match keyword
generate token
● NOTE: Read next character also.
Example: ifex = 5 ← ifex not a keyword
and lack of space is a error!! So, should
scan next character also.
● Lexical Analyser reads one data block
In one go, lexical analyser will read one
data block from source code.
● What is data block?
A block is a sequence of bytes or bits,
having a nominal length (a block size).
Data thus structured are said to be
blocked.
● Blocking is used to facilitate the handling
of the data-stream by the computer
program receiving the data, in this case
the lexical analyser.
Forward and Begin Pointer
● Two pointers to the input buffer are maintained.
● The string of characters between the two pointers
is the current lexeme.
● Forward pointer: Scans ahead until a match for a
pattern is found. If lexeme found, 'forward
pointer' set to next character to its right.
● Begin pointer: marks the beginning of the current
lexeme being searched for a match.
Next character also needs to be scanned
w
h
i
l
e
forward pointer
begin pointer
“while” is the string between the forward and
begin pointer. Once “while” is matched to
symbol table, token can be generated.
END OF THIS LECTURE
Date: 05/08/13