Programming Languages: Syntax, Semantics, and VPLs
advertisement

Programming language
A programming language is an artificial language designed to communicate instructions to a machine,
particularly a computer. Programming languages can be used to create programs that control the
behavior of a machine and/or to express algorithms precisely.
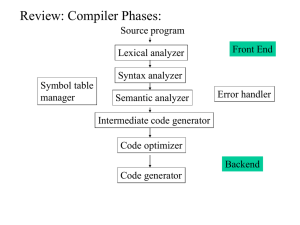
The description of a programming language is usually split into the two components of syntax (form)
and semantics (meaning). Some languages are defined by a specification document (for example, the C
programming language is specified by an ISO Standard), while other languages, such as Perl 5 and
earlier, have a dominant implementation that is used as a reference.
In computing, a visual programming language (VPL) is any programming language that lets users create
programs by manipulating program elements graphically rather than by specifying them textually
Example:
Mama (software) - a programming language and IDE for building 3D animations and games
Max (software), visual programming environment for building interactive, real-time music
and multimedia applications
Syntax
A programming language's surface form is known as its syntax. Most programming languages
are purely textual; they use sequences of text including words, numbers, and punctuation, much
like written natural languages. On the other hand, there are some programming languages which
are more graphical in nature, using visual relationships between symbols to specify a program.
The syntax of a language describes the possible combinations of symbols that form a
syntactically correct program. The meaning given to a combination of symbols is handled by
semantics (either formal or hard-coded in a reference implementation).
Syntax definition
Parse tree of Python code with inset tokenization
The syntax of textual programming languages is usually defined using a combination of regular
expressions (for lexical structure) and Backus-Naur Form (for grammatical structure) to
inductively specify syntactic categories (nonterminals) and terminal symbols. Syntactic
categories are defined by rules called productions, which specify the values that belong to a
particular syntactic category.[1] Terminal symbols are the concrete characters or strings of
characters (for example keywords such as define, if, let, or void) from which syntactically valid
programs are constructed.
Below is a simple grammar, based on Lisp, which defines productions for the syntactic
categories expression, atom, number, symbol, and list:
expression ::= atom | list
atom ::= number | symbol
number ::= [+-]?['0'-'9']+
symbol ::= ['A'-'Z''a'-'z'].*
list ::= '(' expression* ')'
This grammar specifies the following:
an expression is either an atom or a list;
an atom is either a number or a symbol;
a number is an unbroken sequence of one or more decimal digits, optionally preceded by a
plus or minus sign;
a symbol is a letter followed by zero or more of any characters (excluding whitespace); and
a list is a matched pair of parentheses, with zero or more expressions inside it.
Here the decimal digits, upper- and lower-case characters, and parentheses are terminal symbols.
The following are examples of well-formed token sequences in this grammar: '12345', '()', '(a b
c232 (1))'
Token
A token is a string of characters, categorized according to the rules as a symbol (e.g.,
IDENTIFIER, NUMBER, COMMA). The process of forming tokens from an input stream of
characters is called tokenization, and the lexer categorizes them according to a symbol type. A
token can look like anything that is useful for processing an input text stream or text file.
A lexical analyzer generally does nothing with combinations of tokens, a task left for a parser.
For example, a typical lexical analyzer recognizes parentheses as tokens, but does nothing to
ensure that each "(" is matched with a ")".
Consider this expression in the C programming language:
sum=3+2;
Tokenized in the following table:
Lexeme
Token type
sum
Identifier
=
Assignment operator
3
Number
+
Addition operator
2
Number
;
End of statement
Tokens are frequently defined by regular expressions, which are understood by a lexical
analyzer generator such as lex. The lexical analyzer (either generated automatically by a tool
like lex, or hand-crafted) reads in a stream of characters, identifies the lexemes in the stream,
and categorizes them into tokens. This is called "tokenizing." If the lexer finds an invalid
token, it will report an error.