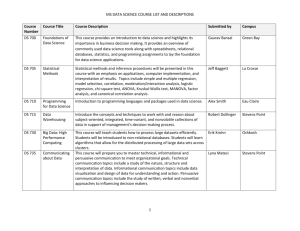
Course Outline – Big Data Management
advertisement

WORKSHOP ON BIG DATA MANAGEMENT: CHALLENGES AND OPPORTUNITIES By Dr. Sumeet Dua, Louisiana Tech University July 2-4, 2013 Madanapalle Institute of Technology & Science In today’s data rich but information poor technological age, automated data collection instrumentation and processes have led to the tsunami of data stored in data marts and storage structures, but majority of this data goes underutilized for information discovery. Data analytics in such large data spaces has become increasingly challenging owing to the growing volume, dimensionality, distribution, complexity and heterogeneity of the underlying data elements. These data characteristics are broadening the lag between in the data generation and its analytics, and eventual intelligence discovery. Owing to the increasing number of services that adapt a data-centric view to information processing, data-driven decision-making spurred by this access to large volumes of data has given rise to the latest trend known as “Big Data.” With silos of exabytes of data being now available for decision making - in the form of social media, network data, enterprise operation and legacy databases etc., organizations are gearing to exploit the benefits of data analytics on a large scale and tread using unconventional learning approaches. To make this realization a reality, organizations are just not trying to scale up to much larger datasets, but are focusing on design, development and implementation for techniques or tools to manage and analyze this data, and perform predictive analytics faster than ever before. Big Data analytics is a multi step process that entails the systematic analysis of data and its underlying at every step of the process – commonly referred to as the “Big Data life cycle.” The Big Data life cycle is a derivative of the knowledge discovery in databases (KDD) process with subtle but important enhancements. Data mining and fusion has rapidly emerged as an enabling, robust, and scalable technique to analyze data for novel patterns, trends, anomalies, structures, and features that can be discovered from Big Data. The focus of this workshop is two fold, namely, to highlight the challenges while transcending towards Big Data, and the opportunities for training, design and development of techniques and technologies that can used to overcome these challenges. The workshop will discuss key data mining techniques, frameworks, algorithms, and strategies as they are employed to analyze large volumes of data and its application to intelligence discovery. Topics: The topics covered in the workshop will include the following. Big Data Management: Opportunities and Challenges; Science of data analytics; Data growth and associated computational complexity; Algorithmic techniques of data mining; The MapReduce framework and HADOOP; Conventional Extract Transform Load (ETL) and Extract Load Transform (ELT) for large data preprocessing; Data preprocessing and transformation; Dimensionality reduction methods; Feature selection, distance metrics, algorithm design and analysis; Data analytics using clustering, algorithms and frameworks; Categories of clustering algorithms; Data analytics using supervised learning and classification; Multi-class classification; Differences and shared challenges between classification and clustering; Classification based models for clustering; Spatio-temporal data structures for range queries for data mining applications; Intricacies of image feature extraction for content-Based image retrieval; Advanced techniques in indexing and querying large time-series; Text mining for sentiment analysis; Hands-on experience with data analytics.