Supplementary Data
advertisement

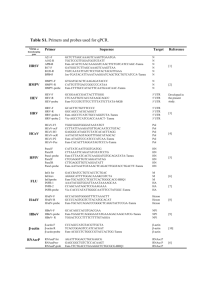
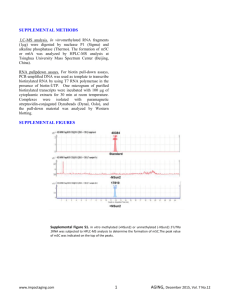
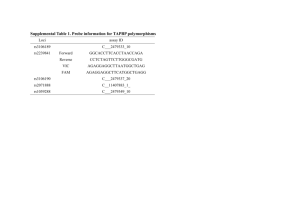
Supplementary Data Whole exome sequencing in an Indian family links cerebroretinal microangiopathy with calcifications and cysts(CRMCC) and dextrocardia with a homozygous novel CTC1 and a rare HES7 variation Manjunath Netravathi1, Saketh Kapoor2, Renu Kumari3, Pushkar Dakle3, Manish Kumar Dwivedi3, Sumit Deb Roy4, Paritosh Pandey5, Jitender Saini6, Anil Ramakrishna1 , Devaraddi Navalli1, Parthasarathy Satishchandra1, Pramod Kumar Pal1* , Mohammed Faruq3* and Arun Kumar2* 1 Department of Neurology, National Institute of Mental Health and Neuro Sciences, Bangalore, India. 2 Department of Molecular Reproduction, Development and Genetics, Indian Institute of Science, Bangalore, India. 3 Genomics and Molecular Medicine, CSIR-Institute of Genomics and Integrative Biology, Mall Road, New Delhi, India. 4 Proteomics and Structural Biology Unit, CSIR-Institute of Genomics and Integrative Biology, Mall Road, New Delhi, India. 5 Department of Neurosurgery, National Institute of Mental Health and Neuro Sciences, Bangalore, India. 6 Department of Neuroimaging and Interventional Radiology, National Institute of Mental Health and Neuro Sciences, Bangalore, India. Supplementary materials and methods Genetic analysis of the family Following informed consent, 3-5 ml of the peripheral blood sample was collected from proband(case:II-1) and both the parents in a Vacutainer EDTA™ tube (Beckton-Dickinson, Franklin Lakes, NJ) for genomic DNA isolation using a Wizard™ Genomic DNA Purification Kit (Promega, Madison, WI). This research followed the tenets of the Declaration of Helsinki and the guidelines of the Indian Council of Medical Research, New Delhi. Targeted resequencing of CTC1 For mutation screening, the entire coding region and intron-exon junctions of the CTC1 gene (GenBank NM_025099.5) were amplified by polymerase chain reaction with appropriate primer pairs (Table S1). The amplified PCR products were subjected to Sanger sequencing followed by analysis on an ABIprism A370-automated sequencer (PE Biosystems, Foster City, CA). Once the mutation was identified, both parents were also examined for the presence of the mutation by sequencing. A total of 50 normal controls were examined for the presence of the mutation by DNA sequencing. Whole exome sequencing Whole exome sequencing was carried out in 3 individuals of this family comprising the proband and both the parents. For exome sequencing, 2 μg of DNA was used for fragmentation, and DNA library preparation was carried out according to Illumina DNA sample prep protocol.v2. Exonic regions were captured and enriched using Truseq Illumina exome capture kit.v2 protocol. Cluster generation using cBOT was carried out for exome enriched libraries on Illumina flow cell.v3 followed by 100bp paired end sequencing on Hiseq2000 using Illumina SBS kit.v3 protocol. Nearly 12 Gb raw data was generated for each sample. The base calls for all the sample reads were analyzed on CASAVA and subsequent pipeline for data processing is described in the following section. The validation of selected candidate variation for dextrocardia (HES7, rs182882481) from exome analysis was carried out by Sanger sequencing using Big-Dye terminator sequencing kit on 3130xl sequencer (ABI, Foster City). Exome sequence analysis Paired-end raw sequencing reads of length 101 bp were trimmed to 96 bp using Trimmomatic1 based on the quality score assessment by FastQC [http://www.bioinformatics.babraham.ac.uk/projects/fastqc/]. These reads were further trimmed if the phred quality score dropped below 20 for a window of 25 bases. For subject, I-2(pedigree chart, Fig. 1, i), the raw reads were trimmed with a more stringent cutoff of phred score dropping below 30 in a window of 10 bases. Finally, the reads which were of length greater than 50bp were taken forward. The filtered reads were then aligned against human genome reference (human.g1k.v37.fasta) using Stampy2. PCR duplicates were labeled in aligned reads using Picard Markduplicates (http://picard.sourceforge.net/). Genome Analysis toolkit (GATK) from http://www.broadinstitute.org/gatk was used to realign BAM file around indels and further scores were re-calibrated to obtain final processed BAM file. Variant calls were made jointly for all the samples using Unified Genotyper module of GATK3. Raw calls were labeled using GATK's VariantAnnotator based on filter expressions. SeattleSeqAnnotation138 server was used to further annotate the calls based on their genomic location– genic/non-genic and their effect(http://snp.gs.washington.edu/SeattleSeqAnnotation138/). Analysis of variations in the known candidate genes from WES data The variation data was obtained for 15 genes involved in telomere length maintenance activity(TERF2IP,POT1,TERF1,OBFC1/STN1,CTC1,TERT,DKC1,WRAP53,TINF2,TPP1,T ERF2,TEN1,TERC,NHP2 and NOP10). All the known and novel variations passing quality filter criterias of GATK were considered for the further analysis(n=23 variations) of direct or indirect association. For Dextrocardia phenotype, a total of 111 variations were obtained from 28 known candidate genes; ACVR2B, CCDC103, CRELD1, DNAH11, GATA4, HES7, MEGF8, NODAL, PKD2, PRKAR1A, SMAD2, CCDC11, INVS, NPHP3, DNAI1, DNAAF1, CCDC114, DYX1C1, CLMP, UBR1, SCN5A, B9D1, CFC1, DNAAF3, ZIC3, MBS1, GDF1, ZMYND10 (supplementary TableS4). All dextrocardia genes related variations were also analyzed with autosomal recessive inheritance pattern to document their potential association with the phenotype (supplementary Table S5). Whole exome variants analysis and variant filtering For a stringent and unbiased approach to analyze the whole exome variations in this family, we filtered variations in the following manner. All calls that were reported in dbsnp138 (http://www.ncbi.nlm.nih.gov/projects/SNP/index.html) were removed. Only protein damaging variations, such as non-synonymous, stop-gain or loss, splice site and indels, were further used to locate variations/gene that fit the model of recessive inheritance i.e genes with homozygous or compound heterozygous mutations in same gene. Finally, these calls were predicted for their role in pathogenicity using SIFT (http://sift.jcvi.org), Polyphen-2 algorithm (http://genetics.bwh.harvard.edu/pph2/) and Mutation Taster (www.mutationtaster.org/). To find the functional significance of the mutated amino acid residue, CTC1 protein sequences from different species were aligned by the ClustalW2 program (http://www.ebi.ac.uk/Tools/msa/clustalw2/). To predict the effect of the mutation on CTC1 function, we used two bioinformatics programs: Mutation Taster (http://www.mutationtaster.org) and PolyPhen-2 (http://genetics.bwh.harvard.edu/pph2/). The output from the Mutation Taster program is a p (probability) value. A p value close to 1 indicates a high 'security' of prediction function. The output score from the PolyPhen-2 program ranges from 0 to a positive number, where 0 is neutral, and a high positive number is damaging to protein function. Supplementary Table S1: Details of PCR primers used in the mutation analysis of CTC1. Exon Primer Sequence (5’ to 3’) Tm (°C) 1 F:CCTCGCGGAGTCTCTAGGAAGCGAG R:ACAACCCCCTCACCCATGGGCCGGA F:CCGGCCCGGATATTTTTTTCTAGTC R:AGACTACCTTGTCCTCCGCTCAC F:ATGTTCCCTGCAACCTTTCCCTG R:ACCTCCCCGTTTGTTTCCTCAG F:CAAGAATGGTGTCCAAGGATCAAGGCA R:TCAAAGCCCACCATTCCCTTGATTTGGA F:TGAGACGTAGTTTCACTCCTGCTGC R:TCCTACATGGCTCCTCCTATGATGC F:GTCTCTGAGTTCAAATCGTGAGG R:ATTTCTATATAACCACCCTGCTGC F:GGCAGTGGCAAAGTGCGGTTAACTC R:GAGCCTGCCTCTTCAAGAATCCTGC F:CAGTGGGAGTAGCACACTTCCTTGG R:ATGACGAAGAAAGATAGTAACCGAGAC F:AGCTTTACCATGTAATACAGCATCTGG R:TCTGCATCTCTAGTAAATCCCAGCAG F:GTGAGGCCGGTAGGATGGTTTGC R:ACTGGACATAGACTCTGTTGGGAG F:TCCTTGGGGTCATGGTTGTCTTGAG R:AGGCCTAGAGAATGACCAGGCACTG F:CAGTGCCTGGTCATTCTCTAGGCCTC R:CTTCACCAAACCCAGCTAGCTTGGGA F:TGAAGTTCTAGCAGATACTTTAGCTCCA R:TATGAAAGAGAAGGGGTCGCTGCAG F:CCATGGCTAGGATATGTCCCTCAG R:GGATTGGAGAAGACTGTAATGATGG F:CTCTAAGTCCTTCTAGACCCAC R:TTCTCATGAGCCAGGAATTATGC F:GTGAGCCAAAGACTGCAGACAGC R:GAAATTCCCCATCAGTCCCTCATC F:GATGAGGGACTGATGGGGAATTTC R:CTGGAGTCCTTGGTTCAATCACAGA F: GTAGGAGCCAGGAGTTGCA R: TTGGCAAGGAGAGCAGGATT IP: GCTCCCAGGAGAGGAATGTT 62 Amplicon size (bp) 321 62 381 62 443 62 460 62 384 62 700 62 410 62 659 62 322 62 346 62 724 62 453 59 567 62 306 62 495 62 595 62 349 60 164 2 3 4 5 6+7 8 9+10 11 12 13+14 15 16+17 18 19+20 21+22 23 Genotyping primer* for p.H484P variation *Genotyping was done by SNaPshot reaction kit (ABI) which is based on single base extension chemistry. F, forward primer; R, reverse primer; IP, Internal primer targeted penultimate to the variation of interest. Supplementary Table S2: Details of Exome sequencing with respect to read counts, depth of coverage and mapping statistics for each DNA sample sequenced. Sample ID Raw Reads Filtered Reads II-1(Proband) I-1(Father) I-2(Mother) 71486240 63329178 67592800 66121038 57945272 29144024 Alignment (Properly Paired) 99.64% 99.21% 99.50% mean depth 59.56 50.60 22.12 Percentage of Exome with non zero coverage (per base) 95.05 94.93 93.48 Supplementary Table S3: Variation analysis of known telomere associated genes. Genomic coordinates chr17:g.8138233T>G chr17:g.8129160A>G chr17:g.8132763T>C chr17:g.8135061T>C chr17:g.7606723GC>G chr15:g.34634033A>G chr15:g.34634124C>G chr15:g.34634138G>A chr15:g.34634139T>C chr10:g.105638232T>C chr10:g.105640978C>T chr10:g.105641935G>GCAAGTGA chr10:g.105657316G>C chr10:g.105659826T>C chr7:g.124462655T>C chr7:g.124462661C>T chr8:g.73958718G>A chr16:g.75681743C>G chr16:g.75691252A>G chr5:g.1268721C>T chr5:g.1294086C>T chrX:g.153994596G>T chrX:g.154005148G>A Variation status Novel rs8078338 rs3826543 rs3027238 rs373064567 rs3063 rs1045238 rs1045204 rs1045194 rs4917405 rs7100920 rs147944736 rs10786775 rs2487999 rs76436625 rs17246404 rs10112752 rs1865493 Novel Novel rs2736098 rs2728532 rs1800533 GL CTC1 CTC1 CTC1 CTC1 WRAP53 NOP10 NOP10 NOP10 NOP10 OBFC1 OBFC1 OBFC1 OBFC1 OBFC1 POT1 POT1 TERF1 TERF2IP TERF2IP TERT TERT DKC1 DKC1 FG II-1 missense 1/1 3'UTR 0/0 missense 0/0 missense 1/1 frameshift 0/0 3'UTR 0/1 3'UTR 0/1 3'UTR 0/1 3'UTR 0/1 3'UTR 1/1 3'UTR 0/1 3'UTR 0/1 missense 1/1 missense 1/1 3'UTR 0/0 3'UTR 0/1 3'UTR 0/0 5'UTR 0/1 3'UTR 0/0 synonymous 0/1 synonymous 0/1 synonymous 1/3'UTR 1/- I-1 0/1 0/0 0/0 1/1 0/0 0/1 0/1 0/1 0/1 1/1 0/1 0/1 1/1 1/1 0/0 0/0 0/0 0/1 0/1 0/1 1/1 1/0/- I-2 0/1 0/1 0/1 1/1 0/1 0/0 0/0 0/0 0/0 1/1 1/1 1/1 1/1 1/1 0/1 0/1 0/1 0/1 0/0 0/0 0/0 1/1 0/1 Supplementary Table S4: WES variations from known Dextrocardia/situs-inversus associated genes. Coordinates chr3:38519424 A>G chr3:38524742 C>T chr3:38525567 T>C chr3:38525734 C>T chr3:38525864 A>C chr3:38526166 CAA>C chr3:38527215 T>C chr3:38527913 C>T chr3:38528537 G>T chr3:38529440 C>G chr3:38529818 C>T chr3:38529825 C>T chr3:38531211 T>G chr3:38532511 G>A chr3:38533335 A>C chr3:38534133 T>TA chr17:42980189 G>A chr18:47777323 T>C chr19:48799716 A>G chr11:122943495 T>C chr11:122944081 C>CCT chr11:123065902 A>G chr3:9976159 A>G chr3:9987049 A>G chr16:84203612 A>G chr16:84203730 G>C chr16:84203939 C>T chr16:84209634 C>G chr16:84209738 T>C chr16:84209816 T>C chr16:84209864 G>C chr7:21582963 G>T chr7:21582964 A>T chr7:21598500 A>G chr7:21599233 C>T chr7:21603886 A>G chr7:21628197 A>G chr7:21628237 C>T chr7:21628242 C>G dbSNP rs2070489 rs1046048 rs7642472 rs6599204 rs7640050 rs56291663 rs11914389 rs11926767 rs928813 rs6599205 rs7433277 rs2370840 rs7374458 rs1058945 rs13072731 rs34717882 rs8079308 Novel rs2292112 rs7949414 rs149599709 rs3132824 rs279552 rs73118375 rs17856705 rs9972733 rs11644164 rs2288019 rs2288020 rs2288022 rs2288023 rs2285943 rs2285944 rs72655972 rs10950854 rs4392792 rs12670130 rs6963535 rs62441683 Gene ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B ACVR2B CCDC103 CCDC11 CCDC114 CLMP CLMP CLMP CRELD1 CRELD1 DNAAF1 DNAAF1 DNAAF1 DNAAF1 DNAAF1 DNAAF1 DNAAF1 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 II-1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 0/1 0/0 0/1 0/0 0/0 1/1 1/1 1/1 0/1 0/0 0/1 0/1 0/1 0/1 0/1 0/0 0/0 0/0 0/1 0/1 0/0 1/1 0/0 I-1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 0/0 0/1 0/0 0/1 0/1 1/1 1/1 1/1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/0 0/0 0/0 1/1 0/1 0/1 1/1 0/1 I-2 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 0/0 0/1 0/0 0/0 1/1 1/1 -/0/1 0/0 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/0 0/0 1/1 0/0 chr7:21630982 A>G chr7:21640361 T>C chr7:21640405 A>G chr7:21641218 G>A chr7:21659645 T>C chr7:21765452 C>T chr7:21775443 G>A chr7:21778449 C>T chr7:21779278 A>G chr7:21824058 A>G chr7:21893993 G>T chr7:21901566 T>C chr7:21924014 A>G chr7:21932044 C>T chr9:34500821 G>A chr8:11614575 A>G chr8:11616338 A>C chr8:11616410 C>T chr8:11616501 T>C chr8:11616516 T>C chr8:11616547 C>G chr8:11616571 A>G chr8:11616836 G>A chr8:11617240 A>T chr17:8024121 C>T chr17:8024204 T>C chr17:8024237 T>C chr17:8024333 T>C chr17:8024758 C>A chr9:102861613 T>G chr9:103063253 A>G chr19:42882829 TA>T chr10:72191952 A>G chr10:72191970 C>G chr10:72195439 T>C chr10:72195576 G>A chr10:72201294 T>G chr4:88997021 A>AT chr4:88997102 C>T chr17:66527262 T>C chr17:66527402 A>C chr17:66527834 T>C chr17:66528367 C>T chr17:66528778 C>G chr3:38589666 T>TCCCTCCTTTTTCCTA rs4615458 rs10269582 rs10224537 rs3827657 rs56029521 rs12536928 rs2072221 rs1109806 rs9639393 Novel rs4722064 rs4722067 rs6461613 rs12537531 rs11793196 rs3729856 rs867858 rs1062219 rs884662 rs904018 rs12825 rs804291 rs804290 rs12458 rs1442849 rs75711247 rs1442850 rs182882481 rs114049508 rs7024375 rs190277417 rs3214618 rs2279253 rs2279254 rs1904589 rs77151171 Novel Novel rs2728121 Novel rs116996069 rs9925 rs7977 rs6958 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAH11 DNAI1 GATA4 GATA4 GATA4 GATA4 GATA4 GATA4 GATA4 GATA4 GATA4 HES7 HES7 HES7 HES7 HES7 INVS INVS MEGF8 NODAL NODAL NODAL NODAL NODAL PKD2 PKD2 PRKAR1A PRKAR1A PRKAR1A PRKAR1A PRKAR1A 0/0 0/1 0/1 0/1 0/1 1/1 1/1 0/1 0/1 0/0 0/1 0/1 1/1 1/1 0/1 0/1 1/1 0/0 0/0 1/1 1/1 1/1 0/0 1/1 1/1 0/0 1/1 1/1 0/0 0/1 0/0 0/1 0/1 0/1 1/1 0/0 0/0 0/1 0/1 0/1 0/0 0/1 0/1 0/1 0/1 0/0 0/1 0/1 0/1 1/1 0/1 0/0 0/0 0/1 0/0 0/1 1/1 1/1 0/0 0/0 0/1 0/1 0/1 1/1 0/1 1/1 0/1 0/1 1/1 0/1 1/1 0/1 0/0 0/1 0/1 1/1 0/1 0/1 1/1 0/0 0/0 0/0 0/0 0/0 0/0 0/0 0/0 1/1 0/1 0/1 1/1 1/1 0/1 0/1 1/1 1/1 1/1 0/0 0/1 1/1 1/1 1/1 0/1 0/1 0/1 0/1 0/1 1/1 0/1 1/1 0/1 0/1 0/1 0/0 1/1 0/1 0/1 0/1 0/0 0/0 0/0 0/0 0/1 0/1 0/1 1/1 1/1 0/1 0/1 1/1 0/1 0/1 rs45592631 SCN5A 1/1 1/1 1/1 CTCTCTTCTC chr3:38590358 C>CT chr3:38590470 A>G chr3:38590849 G>A chr3:38590850 A>T chr3:38591059 G>A chr3:38591689 T>C chr3:38592406 A>G chr3:38622467 T>C chr3:38645420 T>C chr3:38674712 T>C chr18:45359664 T>A chr18:45360991 A>G chr18:45361016 C>CTTAT chr18:45362150 C>A chr18:45362194 T>C chr18:45363214 A>T chr18:45365396 CA>C chr18:45367484 A>G chr15:43236612 C>T chr15:43237203 T>C chr15:43237572 T>C chr19:55671337 C>T chr19:55671374 C>T chr19:55672055 A>G chr19:55673145 C>T chr19:55673164 T>C chr19:55673654 T>C rs11414422 Novel rs4073796 rs4073797 rs41310757 rs7429945 rs1805126 rs7430407 rs1805124 rs6599230 rs8671 rs1981 rs111850625 Novel rs1792671 rs1792666 rs5824709 rs1787187 rs7178567 rs3803341 rs16957277 rs890872 rs891187 rs890871 rs58824375 rs56726774 rs3848618 SCN5A SCN5A SCN5A SCN5A SCN5A SCN5A SCN5A SCN5A SCN5A SCN5A SMAD2 SMAD2 SMAD2 SMAD2 SMAD2 SMAD2 SMAD2 SMAD2 UBR1 UBR1 UBR1 DNAAF3 DNAAF3 DNAAF3 DNAAF3 DNAAF3 DNAAF3 0/1 0/1 0/1 0/1 0/1 0/1 0/1 1/1 0/1 0/1 1/1 1/1 1/1 0/0 1/1 1/1 1/1 1/1 1/1 1/1 0/1 1/1 0/1 0/1 0/1 0/1 0/1 0/0 0/1 0/0 0/0 0/0 0/0 0/0 1/1 0/1 1/1 0/1 0/1 1/1 0/1 0/1 0/1 0/1 1/1 1/1 1/1 0/1 1/1 0/0 0/1 0/1 0/1 1/1 0/1 0/0 0/1 0/1 0/1 0/1 0/1 1/1 0/0 0/1 0/1 0/1 1/1 0/0 0/1 0/1 0/1 1/1 1/1 1/1 1/1 1/1 0/1 0/0 0/0 0/0 0/0 Supplementary Table S5: Variation analysis of known candidate of dextrocardia phenotype with homozygous disease model. Genomic coordinates chr17:g.8024333T>C chr8:g.11616338A>C chr8:g.11616547C>G chr8:g.11617240A>T chr18:g.45359664T>A chr18:g.45360991A>G chr18:g.45362194T>C chr18:g.45363214A>T chr18:g.45365396CA>C variation status rs182882481 rs867858 rs12825 rs12458 rs8671 rs1981 rs1792671 rs1792666 rs5824709 Gene HES7 GATA4 GATA4 GATA4 SMAD2 SMAD2 SMAD2 SMAD2 SMAD2 Location 3'UTR 3'UTR 3'UTR 3'UTR 3'UTR 3'UTR 3'UTR 3'UTR 3'UTR II-1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 I-1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 I-2 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/1 TGP MAF 0.001 0.358 0.453 0.392 0.423 0.385 0.384 0.423 0.66 Supplementary Table S6: Compound heterozygous model WES data. Genomic coordinate chr11: g.6540998 G>T chr11: g.6585264 C>CCT chr14: g.105223033 G>A chr14: g.105223055 G>T chr7: g.151896438 T>A chr7: g.151917753 G>T Gene Effect DNHD1 missense II-1 0/1 I-1 0/0 I-2 0/1 DNHD1 SIVA1 SIVA1 KMT2C KMT2C 0/1 0/1 0/1 0/1 0/1 0/1 0/1 0/0 0/1 0/0 0/0 0/0 0/1 0/0 0/1 frameshift missense missense missense missense Supplementary Table S7: The variation found in the homozygous stretch on chr17. Genomic coordinates chr17:g.6942111 G>T chr17:g.7224921 C>G chr17:g.7257185 C>T chr17:g.7257669 C>A chr17:g.7257847 GGT>G chr17:g.7360110 T>C chr17:g.7363055 A>G chr17:g.7369541 C>T chr17:g.7460517 G>C chr17:g.7554536 T>C,G chr17:g.7554772 C>T chr17:g.7560294 C>T chr17:g.7836105 G>A chr17:g.7942434 A>G chr17:g.8024333 T>C chr17:g.8048216 C>T chr17:g.8062993 G>A chr17:g.8138233 T>G chr17:g.8222870 C>T chr17:g.8224276 T>C chr17:g.8224670 G>C chr17:g.8225768 A>G chr17:g.8225787 C>T chr17:g.8243661 G>A chr17:g.8243785 A>G chr17:g.8272767 G>A chr17:g.8701116 G>A chr17:g.8702205 C>T chr17:g.9674901 C>T chr17:g.9674922 A>G chr17:g.9674976 T>C ID rs33979567 rs3809813 rs3809830 rs3809831 Gene SLC16A13 NEURL4 KCTD11 KCTD11 effect synonymous missense 3'UTR 3'UTR rs3840878 rs2302764 rs371972614 Novel rs3803798 rs1050528 rs1642762 rs1050533 rs72841443 rs73972649 rs182882481 Novel rs75056600 Novel rs79993581 rs3744647 rs1045161 rs1045172 rs2430 rs12601097 rs12936935 rs2430949 rs2242374 Novel rs114469918 rs11654889 rs11655932 KCTD11 CHRNB1 ZBTB4 ZBTB4 TNFSF12/TNFSF12-TNFSF13 ATP1B2 ATP1B2 ATP1B2 CNTROB ALOX15B HES7 PER1 VAMP2 CTC1 ARHGEF15 ARHGEF15 ARHGEF15 ARHGEF15 ARHGEF15 ODF4 ODF4 KRBA2 MFSD6L MFSD6L DHRS7C DHRS7C DHRS7C 3'UTR 3'UTR 3'UTR missense synonymous 5'UTR 5'UTR 3'UTR 5'UTR 5'UTR 3'UTR missense 3'UTR missense missense missense 3'UTR 3'UTR 3'UTR missense missense synonymous synonymous synonymous synonymous synonymous synonymous References 1. Bolger, A., Lohse, M. and Usadel, B. Trimmomatic: a flexible trimmer for Illumina sequence data. Bioinformatics, 2014 p.170 2. Lunter G, Goodson M. Stampy: a statistical algorithm for sensitive and fast mapping of Illumina sequence reads. Genome Res 2011;21:936-9 3. McKenna A, Hanna M, Banks E, et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res 2010;20:1297-303.