Chapter 10 Vocabulary & Questions
advertisement

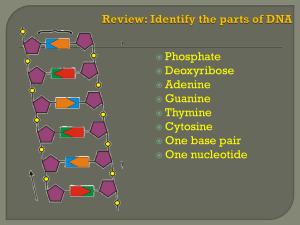
Chapter 10: From DNA to Protein – Gene Expression Vocabulary: mRNA- serves as a template for protein synthesis; messenger DNA rRNA- a molecular component of a ribosome, the cell's essential protein factory. Strictly speaking, ribosomal RNA (rRNA) does not make proteins. It makes polypeptides (assemblies of amino acids) that go to make up proteins. tRNA- transfer RNA. Small RNA molecules that carry amino acids to the ribosome for polymerization into a polypeptide codon- a sequence of three nucleotides that together form a unit of genetic code in a DNA or RNA molecule. Anticodon- a sequence of three nucleotides forming a unit of genetic code in a transfer RNA molecule, corresponding to a complementary codon in messenger RNA microRNA- a cellular RNA fragment that prevents the production of a particular protein by binding to and destroying the messenger RNA that would have produced the protein. Polysome- a cluster of ribosomes held together by a strand of messenger RNA that each ribosome is translating Transcription- the process by which genetic information represented by a sequence of DNA nucleotides is copied into newly synthesized molecules of RNA, with the DNA serving as a template Translation- the process by which a sequence of nucleotide triplets in a messenger RNA molecule gives rise to a specific sequence of amino acids during synthesis of a polypeptide or protein Initiation- involves the small subunit of the ribosome binding to the 5' end of mRNA with the help of initiation factors Elongation- The tRNA transfers an amino acid to the tRNA corresponding to the next codon. Termination- a specific sequence in DNA at which the RNA polymerase and the newly made RNA transcript are released from their DNA association Point mutation- a mutation affecting only one or very few nucleotides in a gene sequence 1. 2. mRNA: When a particular gene is expressed, one of the two DNA strands in the gene is transcribed to guide the synthesis of a complementary RNA strand, which is then cut up and reassembled: introns stay “in” the nucleus, exons “exit” the nucleus, after being spliced together to produce an mRNA. The mRNA exits the nucleus to the cytoplasm, where it serves a guide that is translated to guide the synthesis of a polypeptide: the nucleotide sequence of the mRNA determines the ordered sequence of amino acids on the polypeptide chain which is built by a ribosome. rRNA: Ribosomes are often called “protein synthesis factories.” They are made up of multiple proteins and several ribosomal RNAs. One of the rRNAs in the ribosome catalyzes the formation of the peptide bond linking a newly delivered amino acid to the “growing” protein as it is synthesized. MicroRNA: MicroRNA is a small, noncoding RNA molecule, typically about 21 bases long. When a microRNA bind to an mRNA, the mRNA-microRNA complex that is formed cannot be translated. MicroRNAs thus exert regulation of gene expression in this manner. tRNA: Each specific tRNA molecule transports a specific amino acid to the ribosome. Each specific tRNA molecule also has triplet of nucleotides (the anticodon) that binds to a specific triplet of nucleotides (the codon) in mRNA. Thus the codon in mRNA specifies the tRNA molecule that associates with mRNA in the ribosome, and thus determines which amino acid is peptide-bonded to the growing polypeptide chain. In this manner, the sequence of codons in mRNA determines the sequence of amino acids in proteins. 3. This characterization is inaccurate, because genes code for proteins, and these proteins then determine phenotypes. In other words, genes provide the roadmap for the synthesis of proteins, including enzymes, which influence many metabolic processes, including the production of hormones. Low levels of cortisol could result from a mutation in a gene that codes for an enzyme essential for the synthesis of cortisol. 4. Sickle-cell anemia is a heritable blood disorder caused by a point mutation that occurs in people who carry two copies of the sickle allele of the gene for human β-globin (a subunit of hemoglobin, the blood protein in humans that carries oxygen). The sickle allele differs from the normal allele by just one base pair, resulting in a polypeptide that differs by just one amino acid from the normal protein. People who are homozygous for this recessive allele have defective, sickle-shaped red blood cells, especially when oxygen levels are reduced in the blood. These deformed blood cells can block narrow capillaries, which result in extremely painful tissue damage. Heterozygous individuals are usually asymptomatic, with the only significant manifestation being urinary tract issues. Surprisingly, heterozygous individuals are also resistant to malaria, given an advantage to having one copy of the mutated β-globin gene. 5. A mutation in the stop codon of a gene could result in the transcription process continuing past the original gene, and it could also prevent the release of the completed polypeptide from the translation complex. Assuming the DNA eventually included another stop codon, the results of the mutation could include much longer than normal RNA and a much longer than normal protein. 6. A eukaryotic gene may contain noncoding sequences called introns (intervening regions) that interrupt the coding region. These regions are called exons (expressed regions). Both introns and exons appear in the primary mRNA (pre-mRNA) transcript, but the introns are removed by the time the mature mRNA exits the nucleus. Pre-mRNA processing involves cutting introns out of the transcript and splicing together the exon transcripts. Introns stay “in” the nucleus, exons “exit” the nucleus. 7. While pre-mRNA is still in the nucleus it undergoes two processing steps, one at each end of the molecule. First the 5’ cap (or G cap) is added to the 5’ end of the pre-mRNA as it is transcribed. The cap is a chemically modified GTP molecule that helps bind the mRNA to the ribosome for translation and protects it from being digested by ribonucleases. The poly-A tail is added to the 3’ end of the pre-mRNA at the end of transcription aids in export of mRNA from the nucleus. The poly-A tail also enhances stability. 8. The polypeptide product’s start codon is methionine, followed by phenylalanine, glutamine, arginine, glycine, and ending with a stop codon. 9. UUG is leucine, so the second codon would replace phenylalanine with leucine. 10. The fragment shown above only has 18 bases, so a 19th base would be an addition, not a substitution. Since a codon is composed of three nucleotides that direct the placement of amino acids into a polypeptide chain, a single “A” at the end of this sequence would not provide sufficient information for translation process to continue. Furthermore, the addition this particular 19th base follows a stop codon, so translation of this particular amino acid sequence would have already been completed. 11. The code for serine can be specified by six difference sequences that are redundant but not ambiguous. Serine can be produced in response to any of these six codons, but each of these codons only encodes one amino acid. An ambiguous codon would be one that specified two or more different amino acids. 12. The genetic code is considered to be universal because it is used by all species on our planet. This provides strong evidence that the code is an ancient one that has been maintained intact throughout the evolution of living organisms. “Nearly” implies life forms not yet discovered might use a different code. 13. The E. coli bacterium can be manipulated to produce human insulin by introducing the human gene for insulin into the bacteria through the use of plasmids. The process by which this takes place is called recombinant DNA technology. The “universal genetic code” for all species is the underlying reason why a process like this is possible. The actual details for the two peptides needed for this hormone is beyond the scope of the course. 14. Silent mutations can occur because of the redundancy of the genetic code. Even though a mutation may change the code, this change may also translate to the production of the same amino acid, and there would be no phenotypic difference. Nonsense mutations could result in a premature stop codon. In this case, the polypeptide chain would be shorter than the original protein. 15. At about the midpoint on the tRNA polynucleotide chain, there is a triplet of bases called the anticodon. This region binds to its complementary codon in mRNA. Like the two strands of DNA, the codon and anticodon bind together via hydrogen bonds; this binding is associated with the “delivery” of the amino-acid “cargo” on the tRNA molecule. In this way, mRNA determines which amino acid is at which location on a new protein. The codons on mRNA are, of course, determined by the DNA sequence. 16. The ribosome is the molecular workbench where the translation of mRNA occurs. Like transcription, translation is a three step process involving initiation, elongation, and termination. The ribosome contains a large subunit where interactions with tRNA anticodons take place. At the A site, the charged tRNA anticodon binds to the mRNA codon. The P site is where the tRNA adds its amino acid to the growing polypeptide chain. Finally, the tRNA is released at the E site. Polyribosomes allow more than one ribosome to move along a strand of mRNA at one time. 17. The next anticodon will be UAC, which is the amino acid tyrosine. 18. RNA polymerase is an enzyme that catalyzes the formation of RNA from a DNA template. This enzyme is necessary for the creation of RNA chains using the DNA genetic code as a template in the process of transcription. RNA carries the genetic code or “instructions” from the nucleus of the cell to the ribosomes and the ribosomes then carry out the actual synthesis of amino acids, in accordance with these instructions through the process of translation. RNA functions, e.g., rRNA, mRNA, tRNA, µRNA, etc. have been discussed earlier. 19. Secreted proteins, including hormones, interact with rough endoplasmic reticulum (RER) and Golgi apparatus (or lysosome or plasma membrane). If a newly formed polypeptide contains a signal sequence, a short stretch of amino acids with instructions for its destination in the organism, it will bind to a signal recognition particle. Then both bind to a receptor protein in the membrane of the RER, and translation proceeds. The signal sequence is removed by an enzyme in the lumen of RER. The polypeptide continues to elongate until translation terminates. The ribosome is then released, and the protein folds inside the RER. Next the protein may move elsewhere within the endomembrane system, such as the Golgi apparatus, lysosome, or plasma membrane. If it lacks specific signals for destination within the endomembrane system, it will usually be secreted from the vesicles that fuse with the plasma membrane. 20. A gene contains the entire nucleic acid sequence necessary for the synthesis of any given protein, such as insulin in this case. Therefore, the gene likely includes more than just the nucleotides necessary to encode the amino acid sequence, or the coding region. The gene must also include all the DNA sequences needed for the transcription process, including non-coding regions such as enhancers, cleavage specifications, poly A sites, splicing instructions, and all other non-coding instructions necessary for insulin to be produced, packaged, and delivered for suitable functioning in the cell. Directly relevant to the size of the insulin protein is the fact that it is synthesized as a much larger protein called prepro-insulin, which is cleaved to yield the active 51-amino-acid active hormone. 21. 22. A. 5’-CCU-CCU-AAA-AAA-AAA-CGU-AAA-GUU-3’ B. 24 C. Methionine has the codon AUG, which is the “start” codon or message for a ribosome that signals the initiation of protein translation from mRNA. D. 3’-AAC-TTT-ACG-TTT-TTT-TTT-AGG-AGG-5’ E. No, the codons in this peptide chain have between two and four redundant codons that would produce the same amino acids. 23. A. A cytosolic protein bound to NLS peptide will be found in the nucleus. This is because the nuclear localization signal involves a localization signal or tag, which is a specific amino acid sequence that interacts with a receptor protein on the surface of the organelle, in this case the nucleus, that is the correct “destination.” B. The nuclear protein will remain in the cytoplasm, because the codon for the NLS is incomplete. The correct signal sequence is necessary for it to bind to the receptor protein at the surface of the nucleus. Without the proper signal sequence, a channel will not form, and the targeted protein is unable to move into the nucleus. C. This DNA sequence contains two “start” codons, one at the beginning of the sequence and another two codons before “stop.” This mutation renders the NLS ineffective because it lacks the proper sequence or specificity to provide a signal for it to bind to the receptor protein on the surface of the nucleus. Therefore, this protein will remain in the cytoplasm.