Solution - WordPress.com
advertisement

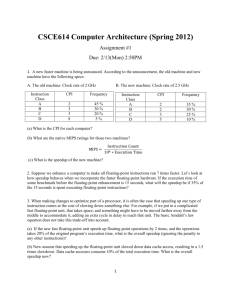
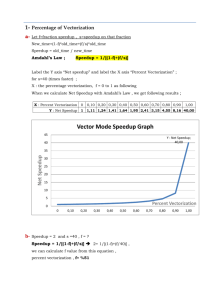
Assignment – 2 Amdahl’s law : The performance improvement to be gained from using some faster mode of execution is limited by the fraction of time the faster mode can be used. Speedup = Execution time for the program without using the enhancement Execution time for the program using the enhancement when possible Speedup (or enhancement) can be used for some fraction of the original program , which is referred as Fractionenhanced . Speedup achieved through this enhancement is applied as speedupenhanced . So, Execution timenew= Execution timenew x ((1 – Fractionenhanced) +( Fractionenhanced / Speedupenhanced) ) Q.1 A program consists of 25% floating-point operations and rest is integer operations. There are two design team propose optimization on this program. Team A proposes speed up of integer operations by 2 times. Team B proposes speed up of floating-point operations by 5 times. There is a budget for single design only. Which design you recommend considering Amdalh’s law speedup formula ? Why? Answer: Let us consider the second design proposal involving speeding up the floating-point operations and call it designB. Since we can speed up 25% of the code using this approach by 5 times, we can apply Amdahl's law to obtain the overall speedup SpeedupB = 1 . (1 – 0.25) + (0.25 / 5) = 1.25 Now, consider the first design proposal involving speeding up integer operations and call it designA. Since we can speed up 75% of the code using this approach by 2 times, the overall speedup is given by SpeedupA = 1 . (1 – 0.75) + (0.75 / 2) = 1.6 So, according to Amdahl's law, designA provides a bigger bang for the buck. Q.2 Write SIMD and MIMD non-recursive pseudo code to calculate sum of n elements stored in form of one dimensional array. Consider n is power of 2. Calculate run time complexity of these pseudo codes. (Hint : Use parallel reduction) Answer: Q.3 In a certain computation, 90% of the work is vectorizable. Of the remaining 10%, half is parallelizable for an MIMD machine. What are the speedups over sequential execution for a 10 PE SIMD machine and speedup over a 10 processor MIMD machine on this computation? ANSWER: Q.4 Counting floating point operations is a way of estimating execution time. Use it to analyze the following code fragment written in SIMD pseudo code for a true SIMD computer with N processing elements. s := (x y)/(x*x + y*y); v[i] := s*a[i] + b[i], (0 i < N); Where, the scalars x, y, and s and the vectors a, b, and v are all floating point. Scalar operations are done using only one of the PEs. Multiplication and Division operator takes 2 time unit. Addition and subtraction operator takes 1 time unit. (a) Give the speedup and efficiency obtained by executing the above code on the SIMD (vector) machine versus doing the same computation on a SISD (scalar) computer. (b) What is the largest integer value of N for which the processing element efficiency is still at least 50%? Answer: Scalar operations = 2 Mul + 1 Div + 1 Add + 1 SUB = (2+1) * 2 + (1*1) time unit = 8 time unit Vector operation = 1 Mul + 1 Add For SISD machine, we have 5 + 2N operations = scalar operation + vector operations * N = (3 Mul-div, 2 Add-sub) + (1 Mul +1 Add) * N = ( 3*2t + 2*1t) + (1*2t + 1*1t) * N = 8t + 3Nt For SIMD machine, we have 5 + 2 operations = scalar operation + vector operations (N PE) = (3 Mul-div, 2 Add-sub) + (1 Mul +1 Add) = ( 3*2t + 2*1t) + (1*2t + 1*1t) = 11t Speedup = 8t + 3Nt 11t Efficiency = Speedup / N (b) For efficiency > = 50% 8t + 3Nt >=1/2 11Nt 16+6N >= 11N 16 >= 5N 16/5 >=N N should be 3PE Q.5 A non-pipeline system takes 100ns to perform a task. The same task can be processed in a 5segment pipeline with the time delay of each segment in the pipeline is as follows 15ns, 25ns, 20ns, 30ns, and 30 ns. Determine the speedup ration of the pipeline for 100 tasks. What is the maximum speedup that can be achieved? Hint: Use Execution time for pipeline system given below. Execution time in pipeline system = (k + (n – 1) ) * t Where, k = number of Instruction stages n = number of Instructions in pipeline parallelization t = time required to execute each cycle Answer: Non-pipeline Sequential Execution Time = (15 + 25 + 20 + 30 + 30 ) ns * 100 tasks = 120 * 100 ns, (But here 100ns give n for non-pipe) = 100 * 100 = 10000ns Pipeline execution time = (5 + (100 – 1)) *30 (B’caz, in pipeline – each stage is of 30 ns) = 3120 ns Speedup = 10000 / 2975 = 4.2 Maximum speedup = 100 * N / ((5 + N – 1) *30 ) = 10/3 Q.6 Discusses Performance evaluation criteria for problem definition given in Q.4 following systems (a) SMP (b) Cluster of Workstation (c) Cluster of SMPs Q.7 In certain computation, a parallel system design is proposed. Simulation result shows that a 10 processors are used to perform computation of 45 elements. To keep constant speedup and proper scalability, How many processors are require to perform similar computation of 145 elements. Ans.: W = 45 N=19 W’=145 N’=? IF W/N=W’/N’ scalability = 1. For scalability =1, N’ = W’* N/W = 145 * 19/45