Asian option - Andrew.cmu.edu
advertisement

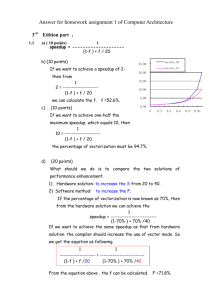
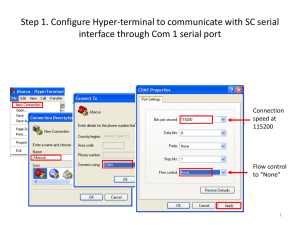
Da-Yoon Chung Daniel Lu Options An option is a contract that can be bought or sold, its value is a function of the value of the underlying stock An Asian option is an option whose terminal value is based on the average prices of stock at certain points in time. Pricing Options Recombinant Binomial Tree Problem with Asian Options: Non-recombinant (2^N) paths we have to consider (Serial) Algorithm Step 1: generate the average price tree for each (i,j), store 2*N out of iCj possible values of the running average up to that point Requires 2*N random paths of length O(N) consisting of up or down for each (i,j) (O(N^3) storage overhead) Step 2: generate the option prices tree Each level of the tree depends only on the next use backwards inductive approach starting at the leaves of the tree use linear interpolation to find an estimate of the option price at each node CUDA Algorithm (global memory) Step 1: generate the average price tree Compute all random paths required using Thrust For each (i,j), the 2*N average values are computed in parallel (one thread per node) Write all updates immediately to the global tree Step 2: generate the option price tree Compute each level of the tree in parallel Write all updates immediately to the global tree CUDA Algorithm (shared memory) Step 1: generate the average price tree Again, for each (i,j), the 2*N average values are computed in parallel (one thread per node) Store all intermediate values in shared memory to minimize global memory accesses Use a hash function to generate the random path within the kernel (reduce memory overhead) Step 2: generate the option price tree Divide the tree into subtrees at the same depth in the original tree which can be computed independently Compute one level of subtrees per kernel call Store all computations for subtrees in shared memory Limitations Size of shared memory N = 64, Tree occupies N * N * (2 * N) * sizeof(float) = 2^6 * 2^6 * (2 * 2^6) * 4 = 2^21 = 2m (48k shared memory) ○ Increasingly sequential as N increases Nature of the algorithm Step 2 of the algorithm is inherently sequential Results performance of Step 1 20 18 16 14 Speedup 12 10 8 6 Speedup (Shared to serial) 4 Speedup(Global to Serial) 2 0 0 50 100 150 Depth of Tree (N) 200 250 Results performance of Step 2 0.35 0.3 Speedup 0.25 0.2 0.15 0.1 Speedup (Global to Serial) 0.05 Speedup (Shared to Serial) 0 0 20 40 60 Depth of Tree (N) 80 100 120 Results performance of hybrid (CUDA shared step 1 + serial step 2) 4.5 4 3.5 Speedup 3 2.5 2 1.5 1 0.5 0 0 50 100 150 Depth of Tree (N) 200 250