Solution to first HW
advertisement

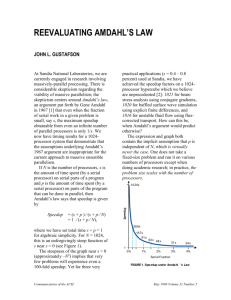
1- Percentage of Vectorization a- Let f=fraction speedup , s=speedup on that fraction New_time=(1-f)*old_time+(f/s)*old_time Speedup = old_time / new_time Amdahl’s Law ; Speedup = 1/[(1-f)+(f/s)] Label the Y axis “Net speedup” and label the X axis “Percent Vectorization” ; for s=40 (times faster) ; X : the percentage vectorization, f = 0 to 1 as following When we calculate Net Speedup with Amdahl’s Law , we get following results ; X : Percent Vectorization 0 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 1,00 Y : Net Speedup 1 1,11 1,24 1,41 1,64 1,95 2,41 3,15 4,55 8,16 40,00 Vector Mode Speedup Graph 45 Y : Net Speedup; 40,00 40 Net Speedup 35 30 25 20 15 10 5 Percent Vectorization 0 0 b- 0,10 0,20 0,30 0,40 0,50 Speedup = 2 and s =40 , f = ? Speedup = 1/[(1-f)+(f/s)] 2= 1/[(1-f)+(f/40)] , we can calculate f value from this equation , percent vectorization , f= %51 0,60 0,70 0,80 0,90 1,00 c- Since the maximum speedup attainable would be 40, one-half of this value would be Speedup =20 and s =40 , f= ? Speedup = 1/[(1-f)+(f/s)] 20= 1/[(1-f)+(f/40)] , we can also calculate f value from this equation , percent vectorization , f= %97 The percentage vectorization needed to gain one-half of the maximum speedup attainable is %97. d- Using the hardware doubling the following equation can be generated: f=%55 and s =80 , Speedup = ? Speedup = 1/[(1-f)+(f/s)] = 1/[(1-0,55)+(0,55/80)] , Speedup = 2,189 To find what percentage of vectorization would need to be achieved to match the hardware doubling ; Speedup =2,189 and s =40 , f= ? Speedup = 1/[(1-f)+(f/s)] 2,189= 1/[(1-f)+(f/40)] , we can also calculate f value from this equation , percent vectorization , f= %55,72 2- Iron Law Assume code size is 100. CPI can be calculated as Assume cycle time is 1 for initial case. Then performance will be If ALU instructions are removed from branch instructions, then 20% of ALU instructions will be removed. We assumed code size is 100 for simplicity. Then 20 ALU should be removed. New code size is reduced to 80 with 30 ALU, 30 Memory and 20 branch instructions. New CPI can be calculated as Then performance can be calculated as Even though ALU instructions are removed, performance of the new design is worse.
![1.14 [20/10/10/10/15] In this exercise, assume that we are](http://s3.studylib.net/store/data/008107156_1-4c2ce11e19e69484e2906286b2787a3a-300x300.png)