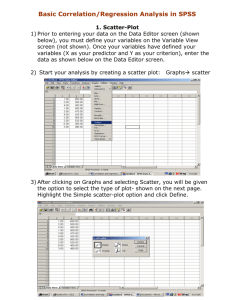
Simple Univariate and Bivariate Statistics The basics of any
advertisement

Simple Univariate and Bivariate Statistics The basics of any distribution usually entail some simple building blocks, such as: 𝑚𝑒𝑎𝑛 = 𝑋̅ = ∑𝑋 𝑛 𝑖 𝑆𝑢𝑚 𝑜𝑓 𝑆𝑞𝑢𝑎𝑟𝑒𝑠 = 𝑆𝑆𝑥 = ∑(𝑋𝑖 − 𝑋̅) 𝑛 2 𝑅𝑎𝑤 − 𝑆𝑐𝑜𝑟𝑒 𝑆𝑢𝑚 𝑜𝑓 𝑆𝑞𝑢𝑎𝑟𝑒𝑠 = 𝑆𝑆 = ∑ 𝑋 2 − 𝑠𝑎𝑚𝑝𝑙𝑒 𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒 = 𝑠𝑥2 = (∑ 𝑋) 𝑛 𝑆𝑆𝑥 𝑛−1 The square root of the sample variance is the standard deviation. When looking at the relationship of two variables, we are also going to utilize some building blocks: 𝑆𝑢𝑚 𝑜𝑓 𝑃𝑟𝑜𝑑𝑢𝑐𝑡𝑠 = 𝑆𝑃𝑋𝑌 = ∑(𝑋𝑖 − 𝑋̅)(𝑌𝑖 − 𝑌̅) 𝑅𝑎𝑤 − 𝑆𝑐𝑜𝑟𝑒 𝑆𝑢𝑚 𝑜𝑓 𝑃𝑟𝑜𝑑𝑢𝑐𝑡𝑠 = 𝑆𝑃𝑋𝑌 = ∑ 𝑋𝑌 − 𝑆𝑎𝑚𝑝𝑙𝑒 𝐶𝑜𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒 = 𝑐𝑜𝑣(𝑋, 𝑌) = 𝐶𝑜𝑟𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛 = 𝑟 = (∑ 𝑋)(∑ 𝑌) 𝑛 𝑆𝑃𝑋𝑌 𝑛−1 𝑆𝑃𝑋𝑌 √(𝑆𝑆𝑋 )(𝑆𝑆𝑌 ) It’s important to see that a correlation is merely a normalized covariance and a large covariance does not necessarily mean that there will be a large correlation. Correlation shows how strongly the variables change together in terms of how much variance they each individually express, whereas covariance shows how much the variable change together. We can also take another route to calculating correlations by looking at the average cross-product of z-scores: 𝑍𝑋𝑖 = 𝑋𝑖 − 𝑋̅ 𝑆𝐷𝑋 𝑐𝑜𝑟𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛 = 𝑟 = ∑(𝑍𝑋𝑖 𝑍𝑌𝑖 ) 𝑛−1 Adding new points to the samples whose relationship is in line with the previous data, even if it is extreme will not affect the relationship. There exist different types of correlations depending on the nature of your dataset. If both variables are continuous you will use a Pearson Correlations. If one variable is continuous and the other dichotomous you will use a Point-biserial correlation. This involves coding one group with a 1 and the other with a 0 and then running a pearson correlation. If both variables are dichotomous then you would use a phi-coefficient correlation. You would code both variables into 0/1 groups and run a pearson correlation to yield a phi-coefficient. You can also use a Spearman correlation to run a correlation of variables in the way in which they rank relative to the other points in the variable set. Furthermore there is Kendall’s tau which takes various observations in all possible pairs and looks to see if within each pair the observation with the higher A value also has the higher B value in an attempt to get a coordinate pair. Tau, then, is the ratio of coordinate and discoordinate pairs. Simple Linear Regression In Regression, the primary aim is to find the line that best summarizes the relation between a predictor X and an outcome Y. Formally, linear regression is given by the formulae: 𝑃𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 = 𝑌 = 𝛼 + 𝛽𝑋 + 𝜀 𝑆𝑎𝑚𝑝𝑙𝑒 = 𝑌 = 𝑎 + 𝑏𝑋 + 𝑒 a/alpha is the intercept or “the value of Y if X were equal to 0”. Technically, alpha will always be 0 because a regression line always passes through the mean of X and Y and if our variables our standardized, then the mean of each variable will be 0 and, thus, our intercept will be 0. b/beta is the slop of the regression line or “the expected change in Y with a 1-unit change in the X that the b is assigned to” In standardized variables, units would be SD for each variable. The e term is the residual or “that in Y which cannot be explained/accounted for by X” We want to use our regression formula to predict a Y value for each associated X value. This value is known as Y hat and is formally given by: 𝑌̂ = 𝑎 + 𝑏𝑋 A residual is the deviation of this Y-hat from the actual Y value for that associated X value. Thus: 𝑒 = 𝑌 − 𝑌̂ In order to get here in the first place, we need to determine what exactly the best fit line would be. The workflow for doing so is as follows: 1. State the function to be minimized a. We will use Ordinary Least Squares solution, so that what we want to minimize the sum of the squared residuals. That is, we want to minimize our error as much as possible. i. If 𝑌̂ = 𝑎 + 𝑏𝑋 and 𝑒 = 𝑌 − 𝑌̂, then 𝑒 = 𝑌 − 𝑎 − 𝑏𝑋 ii. Then what we want to minimize when we aim to minimize the squared residuals is: ∑ 𝑒 2 = ∑(𝑌 − 𝑎 − 𝑏𝑋)2 2. Differentiate the function with respect to the constants a. If we were to look at all the values of b or a, then we could plot the sum of squared residuals of the model using those parameters to estimate Yhat. What we want to do is find the minimum of that plot’s function. Specifically we want to identify the tangent of that function whose slope is 0. b. We want to expand the (𝑌 − 𝑎 − 𝑏𝑋)2 in its full fashion and tackle each term independently. i. We are looking to solve each constant (a/b) c. If the given constant (a/b) is not in the term then the derivative is 0. d. If the constant (a/b) is in the ther term then we must identify the coefficient and exponent and then use those in a calculus trick where: i. 𝑑𝑒𝑟𝑖𝑣𝑎𝑡𝑖𝑣𝑒(𝑛𝑎2 ) = 2𝑛𝑎1 1. The new coefficient is the previous coefficient (n) multiplied by the previous exponent (2). 2. The new exponent is the previous exponent -1 3. Set the derivatives(rate of change) equal to 0 to form normal equations 4. Evaluate normal equations to solve for the constants We can solve for a and b by first solving for b: 𝑏= 𝑆𝑃𝑋𝑌 = ∑(𝑋𝑖 − 𝑋̅)(𝑌𝑖 − 𝑌̅) 𝑆𝑆𝑥 = ∑𝑖𝑛(𝑋𝑖 − 𝑋̅) and then solving for a by substitution of b: 𝑎 = 𝑌̅ − 𝑏𝑋̅ Properties of regression equations include: 1. The sum of the residuals will be equal to 0 2. The sum of the squared residuals is at a minimum 3. The sum of the observed Y values equals the sum of the fitted values, and also the mean of Y is the mean of Y hat. 4. The regression line always goes through (𝑋̅, 𝑌̅) 5. Residuals are uncorrelated with the predictor such that 𝑟𝑒,𝑥 = 0 6. The fitted Y value (Yhat) are less extreme on Y than the associated X value is on X a. This phenomenon is known as “regression towards the mean” b. If you move up 1SD on X and then use that to predict Y, that predicted Y will not be 1SD up on Y. i. This is due to the fact that X does not explain everything about Y. So the more unrelated X and Y, the more we see a regression towards the mean. The Gauss-Markov Assumptions about variables and are listed below: 1. All predictors are quantitative or dichotomous, and the criterion is quantitative, continuous, and unbounded. Moreover, all variables are measured without error. 2. All predictors have nonzero variance 3. There is not perfect multicollinearity 4. 5. 6. 7. 8. At each value of the predictors, the expected value for the error term is 0. Each predictor is uncorrelated with the error term At each value of the predictor, the variance of the error term is constant (homoscedasticity) Error terms for different observations are uncorrelated. At each value of the IVs, the errors are normally distributed. It is important to meet the assumptions of Simple Linear Regression. OLS model, if these assumptions are met, would be the best (smallest sampling variance) linear unbiased estimator (BLUE) When we want to examine the significance of our regression coefficients, we must first use them as a predictor, form a regression model and then predict Yhats for all values and determine the standard error of our estimate, which is just the standardized residuals: 𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝑒𝑟𝑟𝑜𝑟 𝑜𝑓 𝑡ℎ𝑒 𝑒𝑠𝑡𝑖𝑚𝑎𝑡𝑒 = 𝑆𝑌∙𝑋 2 ∑(𝑌 − 𝑌̂) 𝑆𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 √ = =√ 𝑁−2 𝑑𝑓 We also want to know the standard error of our predictor: 𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝑒𝑟𝑟𝑜𝑟 𝑜𝑓 𝑏 = 𝑠𝑏 = 𝑆𝑌∙𝑋 √𝑆𝑆𝑋 Then we want to test our b with a t-test compared to the expected value (either under the null(B=0) or compared to an expectation in the population). 𝑡= 𝑏−𝛽 ; 𝑠𝑏 df=n-k-1 We can use the 𝑠𝑏 value to construct confidence intervals around b using the critical t-value for our alpha/2 and df 𝐶𝐼 = 𝑏 +/− 𝑡𝑐𝑣(𝑎,𝑛−𝑘−1) 𝑠𝑏 2 We also want to test our a using the same procedure, however its standard error is slightly different: 1 𝑋̅ 2 2 𝑠𝑎2 = 𝑆𝑌∙𝑋 [ + ] 𝑛 𝑆𝑆𝑋 This is relatively uncommon to test our intercept for significance and is rather non-interpretable. Simply included here for the sake of completeness. In order to recap a few terms before moving forward: 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 = ∑(𝑌 − 𝑌̅)2 ; 𝑆𝑆𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 = ∑(𝑌̂ − 𝑌̅)2 ; 𝑆𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 = ∑(𝑌̂ − 𝑌)2 It follows, then, that: 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 = 𝑆𝑆𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 + 𝑆𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 When we want to assess the significance of our regression, we would submit our SSregression to an ANOVA: Step 1: Get the Mean Square Residuals (this is the variance of the estimate): 𝑀𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 = 𝑆𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 𝑛−𝑘−1 Step 2: Get the Mean Square Regression: 𝑀𝑆𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 = 𝑆𝑆𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 𝑘 Step 3: Get the F ratio of MSregression and MSresidual: 𝐹= 𝑀𝑆𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 𝑀𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 Most importantly, to obtain a metric of how much of the total variance gets accounted for by your regression, you merely need to look at the amount of variance we see from the mean of Y and our predicted Ys (SSregression) over the amount of variance we see from the mean of Y and our actual Ys (SStotal): 𝑅2 = 𝑆𝑆𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 2 This can also be defined as a correlation between the actual Y values and Yhat values. (𝑟𝑌𝑌 ̂) It’s also clever to note that: 1 − 𝑅2 = 𝑆𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 If we want to test the significance of this 𝑅 2 we can submit it to an F-Test: 𝑅2 𝑘 𝐹= (1 − 𝑅 2 ) 𝑛−𝑘−1 This F value will be the same as our t-value for b.. squared. Note that an increase in n will always increase the F value if all other things are held constant. An increase in SSx will also increase any significance. Lastly, an increase in SSres will also decrease any significance. Increasing likelihood of significance is akin to increasing power. The standard error of our estimate has to incorporate the error and leverage associated with our predictor both for the mean and any new data that may come our way: 1 (𝑋 − 𝑋̅)2 𝑙𝑒𝑣𝑒𝑟𝑎𝑔𝑒 = ℎ𝑖𝑖 = [ + ] 𝑛 𝑆𝑆𝑋 𝑆𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝐸𝑟𝑟𝑜𝑟 𝑜𝑓 𝑡ℎ𝑒 𝑚𝑒𝑎𝑛 𝑟𝑒𝑠𝑝𝑜𝑛𝑠𝑒 = √𝑀𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 ℎ𝑖𝑖 𝑆𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝐸𝑟𝑟𝑜𝑟 𝑜𝑓 𝑡ℎ𝑒 𝑛𝑒𝑤 𝑟𝑒𝑠𝑝𝑜𝑛𝑠𝑒 = √𝑀𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 (1 + ℎ𝑖𝑖 ) We can use this standard error of Yhat to build confidence intervals around each Yhat: 𝐶𝐼 𝑓𝑜𝑟 𝑌̂ = 𝑌̂ + / −(𝑡𝑐𝑣 𝑎𝑡 𝑛−𝑘−1 )(𝑆𝐸) Notice that due to the inclusion of leverage, the confidence intervals will become wider at the extremities of X. When we add additional predictors into our model, we need to shift the interpretation of our coefficients. Particularly: a, the intercept, is the point at which the regression plane (since its multidimensional now) intersects the Y axis. So it is the expected value of Y when both X1 and X2 are equal to 0. B1 is the expected change in Y associated with a 1-unit increase in X1 over and above the effect of X2 (when X2=0). Adding new predictors does not necessitate any new calculations for our Sum of Squares. We must also take note in our interpretation of Rsquared in that it is a coefficient of multiple determination and the proportion of variance in outcome is accounted for by the set of the predictor variables. Partial correlations take out information from both X and Y. If we have X1 and X2 to predict Y, a partial correlation would first use X2 to predict X1(treating as a Y), then save X1’s residuals. Then, we’d use X2 to predict Y and save Y’s residuals. We’d then correlate these two residuals and say that we’ve correlated X1 and Y while controlling for X2. A partial correlation follows the notation: 𝑅01.23..𝑝 It would follow the form: 𝑟01.2 = 𝑟01 − 𝑟02 𝑟12 2 √1 2 √1 − 𝑟02 − 𝑟12 where the left of the dot is correlated variables and the right of the dot are the variables being partialed out.The square of a partial correlation tells us the percent of the variance in Y (that couldn’t be accounted for by X2) explained by X1 (that could not be explained by X2) Semi-Partial takes out all non-interest predictors from the predictor of interest only. So it would be the correlation between Y and X1’s residuals after regressing X2 on X1. We can say that this correlation is independent of X2. A semi partial correlation follows the notation: 𝑅0(1.2) It will follow the form: 𝑟0(1.2) = 𝑟0.1 − 𝑟02 𝑟12 2 √1 − 𝑟12 Where the left parentheses divide the two correlated variables and right of the period shows the variable that was regressed out of the variable to the left of the period. Semipartials allow us to make the claim “over and above”. If our b/Beta is significant, then our partial and semi-partial correlations are. When we want to get the standard error of our predictors, we must not take into account the correlation of each variable: 𝑀𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 𝑆𝑏𝑦1.2 = √ 2 𝑆𝑆𝑋1 (1 − 𝑟12 ) Previously, to achieve the standard error of just one predictor it was just MSresiduals over SSx In the case of standardizing both predictors and outcome (X1,X2,XN, Y): 𝑍𝑋𝑖 = 𝑋𝑖 − 𝑋̅ 𝑆𝐷𝑋 We then achieve Betas as our slope coefficients and no intercept (alpha). Technically, alpha will always be 0 because a regression line always passes through the mean of X and Y and if our variables our standardized, then the mean of each variable will be 0 and, thus, our intercept will be 0. We can use a shortcut to achieve our Betas since we want to examine the relationship between X1 and Y over and above the relationship between X2 and Y: 𝛽1 = 𝑟𝑌𝑋1 − 𝑟𝑌𝑋2 𝑟𝑋1𝑋2 2 1 − 𝑟𝑋1𝑋2 It’s important to not the conversion process for going from b to beta: 𝛽=𝑏 𝑆𝐷𝑋 𝑆𝐷𝑌 An important question we usually want to ask is “does adding another predictor increase the predictive quality of the model”. We can test the chance in Rsquared by including (full model) and not-including (reduced model) certain predictors of interest. In order to formally test this Rsquared change, we can submit it to an F-test: 𝐹(𝑑𝑓𝑟𝑒𝑔𝑓𝑢𝑙𝑙−𝑑𝑓𝑟𝑒𝑔𝑟𝑒𝑑𝑢𝑐𝑒𝑑),𝑑𝑓𝑟𝑒𝑠𝑓𝑢𝑙𝑙 = 2 2 (𝑅𝑓𝑢𝑙𝑙𝑚𝑜𝑑𝑒𝑙 − 𝑅𝑟𝑒𝑑𝑢𝑐𝑒𝑑𝑚𝑜𝑑𝑒𝑙 ) ⁄ 𝑑𝑓𝑟𝑒𝑔𝑓𝑢𝑙𝑙 − 𝑑𝑓𝑟𝑒𝑔𝑟𝑒𝑑𝑢𝑐𝑒𝑑 2 (1 − 𝑅𝑓𝑢𝑙𝑙𝑚𝑜𝑑𝑒𝑙 ) ⁄ 𝑑𝑓𝑓𝑟𝑒𝑠𝑓𝑢𝑙𝑙 df for regression is k (number of predictors) df for residuals is n-k-1 df for total is n-1 This F test for Rsquared change can potentially be used to compare the increase from no predictors (all coefficients set to 0) to all predictors. The F value will be exactly the same as the F value we obtain from an ANOVA using MSregression/MSresiduals from the full model. A major part of regression is determining which features to include and which to not include. We can do a simultaneous regression where all our predictors are entered in at once. We can also do a hierarchical regression where we add in predictors one (or sets) at a time depending on our theories. Its important to note that additional predictors will always either add nothing or increase the Rsquared value so we can calculate an adjusted R squared value that accounts for this and tells us whether an increase in df was worth it: (𝑛 − 1)(1 − 𝑅 2 ) 𝐴𝑑𝑗𝑅 = 1 − 𝑛−𝑘−1 2 We can also asses the predictability of our model by looking at PRESS which is the sum of all the deleted residuals. Where a deleted individual residual would be shown by: 𝑒−𝑖 = (𝑌𝑖 − 𝑌̂−𝑖 )2 Essentially, this is just saying what is the residual in predicting a Y value when that Y value was not included in the formation of the model? This is akin to a cross-validation. We would want to compare the PRESS to the standard residual and look for extraordinarily high values. This will tell us that “without this one individual in our model, we saw this difference in ability to account for that individual’s score on the dependent variable”. We can measure this in terms of predictive nature of our model by. This is how well we expect our model to perform on a new sample: 2 𝑅𝑃𝑅𝐸𝐷 =1− 𝑃𝑅𝐸𝑆𝑆 𝑃𝑅𝐸𝑆𝑆 =1− 2 ̅ 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 − 𝑌) ∑𝑁 𝑖=1(𝑌𝑖 We can also use Mallows Cp to assess the fitness of our model as compared to its expected fitness, which for mallows is: E(Cp)=k+1 Mallows Cp looks at the ratio of the residual sum of squares and the model in question over the mean square residuals when using all possible variables. This essentially tells us how much smaller our error is compared to when we use all the predictors. It is given by: 𝐶𝑝 = 𝑆𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠−𝑐𝑢𝑟𝑟𝑒𝑛𝑡−𝑚𝑜𝑑𝑒𝑙 − [𝑛 − 2(𝑘 + 1)] 𝑀𝑆𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠−𝑓𝑢𝑙𝑙−𝑚𝑜𝑑𝑒𝑙 k would be the number of predictors in the current model. Essentially, what we want to take-home from Mallows Cp is that if our model is performing below the expected value (number of predictors + 1), then we have a model of good fit and all models with a Cp (regardless of intensity) less than the expected are good. Thereby when looking for the best model you’d find the ones with a lower-than-expected Cp and then pick the one with the best adjusted R squared. We can also use selection algorithms to choose the best model for us by adhering to a set of rules: Forward model selection looks at the single predictor regression p-values for each variable and enters, starting with the predictor that has the smallest p-value (with an inclusion threshold of .05), one variable at a time until there are no non-included predictors with p-values less than .05. Stepwise model selection will follow the same logical flow as a forward model selection, but will, at first, insert two predictors at once (assuming there are two whose single predictor regression p-values are below .05), then remove a predictor that, when included in the multiple regression framework, has a pvalue greater than .1 and replace it with a predictor whose single predictor regression value is less than .05. One would repeat this process until no excluded predictor has a single predictor regression value less than .05 AND that predictor does not lose significance (greater than .1) when entered into the multiple regression framework. Backward deletion is like having all predictors in the model at once and removing the predictor with the highest p-value over a threshold of .1 and re-running without that predictor until all predictor p-values in the multiple regression framework are below .1. Keep in mind that the p value for a backward elimination will reflect the unique contribution of this variable that is not shared by any previous predictors. So, when pruning our model, we want to include the variables that are the most unique and can explain variance on their own, since the less variables in the model the better. The best way to really assess our model, though, is to apply it to a new population since sample based estimates tend to overestimate the R squared in the population. The decrease in Rsquared when applied to a new population is known as shrinkage. You can cross-validate your data in a split-sample in order to assess this or you can get a predicted R squared cross validation by use of the following formula: 𝑛−1 𝑛+𝑘+1 2 𝑅̂𝑐𝑣 =1−( )( )(1 − 𝑅 2 ) 𝑛 𝑛−𝑘−1 Always keep in mind that shared variance between X1 and X2 gets attributed to the first variable entered into the model in a hierarchical regression. So saying that X2 isn’t important if the R2 change doesn’t increase a lot means absolutely nothing if X1 and X2 are relatively highly correlated.