SUPPORTING INFORMATION for Assessing Metabolomic and
advertisement

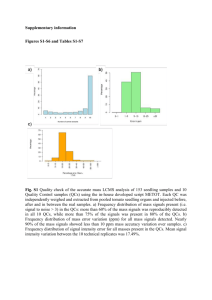
SUPPORTING INFORMATION for Assessing Metabolomic and Chemical Diversity of a Soybean Lineage Representing 35 Years of Breeding Miyako Kusano1, Ivan Baxter2,*, Atsushi Fukushima1, Akira Oikawa1, Yozo Okazaki1, Ryo Nakabayashi1, Denise J. Bouvrette2, Frederic Achard3, Andrew R. Jakubowski3, Joan M. Ballam3, Jonathan R. Philips3, Angela H. Culler3, Kazuki Saito1,4,*, George G. Harrigan3,* 1 RIKEN Center for Sustainable Resource Science, Tsunumi-ku, Yokohama 230-00405, Japan. 2 Agricultural Research Service Plant Genetics Research Unit, Donald Danforth Plant Science Center, United States Department of Agriculture, St. Louis, MO 63132, USA 3 Monsanto Company, 800 North Lindbergh Boulevard; St. Louis, MO 63167, USA. 4Graduate School of Pharmaceutical Science, Chiba University, Chuo-ku, Chiba 260-8675, Japan. . GENOTYPE DATA SUPPORTING TABLE 1. SIMILARITY MATRIX CX375 (A3733/ CX329) CX366 A3469 A3127 WILLIAMS AG3701 AG3705 A3555 AG3803 100% 86% 68% 87% 82% 68% 73% 70% 73% 86% 100% 75% 89% 90% 75% 80% 77% 79% A3469 68% 75% 100% 77% 71% 82% 83% 83% 81% A3127 87% 89% 77% 100% 80% 80% 80% 76% 78% WILLIAMS 82% 90% 71% 80% 100% 71% 77% 76% 77% AG3701 68% 75% 82% 80% 71% 100% 78% 75% 80% AG3705 73% 80% 83% 80% 77% 78% 100% 80% 80% A3555 70% 77% 83% 76% 76% 75% 80% 100% 88% AG3803 73% 79% 81% 78% 77% 80% 80% 88% 100% CX375 (A3733/ CX329) CX366 Genetic similarity of different soybean varieties based on genetic fingerprint data Supporting Figure A (Genotype Data) Supporting Figure A. PCA (principal components one and two) based on the genotypic data of 1,484 pre-commercial and commercial proprietary Monsanto lines. CX375 (A3733/CX329) was not included due to missing data. Principal component one (PC1) explained 8.9% of the variability, while principal component two (PC2) explained 7.4 %. Color coding refers to the maturity group for each line; Red: Maturity Group 2, Black: Maturity Group 3, Blue: Maturity Group 4. Method for Genetic Fingerprint Analysis: A total of 1,484 public, pre-commercial and commercial Monsanto proprietary lines were genotyped to place the germplasm sampled in this study in context of the scope of Monsanto and public soybean germplasm from the past 40 years. The genotyped lines included 387 samples from maturity group two, 853 lines from maturity group three, and 246 lines from maturity group four. Monsanto lines were genotyped at approximately 30K bi-allelic single nucleotide polymorphisms (SNPs) using the Illumina Infinium™ platform. The Infinium™ assay relies on direct hybridization of genomic targets to array-bound sequences. Each allele-specific single base extension is associated with a fluorescent dye for SNP allele detection. The markers were developed by Monsanto. Approximately 10,000 markers were dropped due to missing data in one of the included lines, leaving 20,156 markers for further analysis. Allelic scores were converted to -1, 0, and 1 for homozygous one, heterozygous, and homozygous two scores, respectively. A principal component analysis was performed using the base package in R 3.0.1. CX375 (A3733/CX329) was fingerprinted using the Golden Gate™ SNP platform at approximately 3,000 markers resulting in a significantly reduced overlap with the Infinium™ marker set. This variety was therefore excluded from this analysis due to missing data. METABOLOMICS AND IONOMICS DATA File S1. Full metabolomic and ionomic data: summonsoy2_ion.xlsx File S2. The 681 metabolite names: annotMets_v2.xlsx File S3. Supp_Table 1. Ionomics_DATA.xlsx File S4. Metadata: Metadatav2.docx File S5. Correlation data: ILJA_ILJE_Spearman_corr.xlsx SUPPORTING TABLES Supporting Table 2. Metabolite Coverage of Analytical Platforms Identified Annotated Annotated Platform Metabolite Class Metabolitesa Metabolitesb Peaksc CE-TOF-MS 134 139 228 Ionic compounds Low-molecular mass compounds including sugars, GC-TOF-MS 74 74 97 amino acids, and organic acids Heavier molecules with large polar surface area e.g. soyasaponins LC-TOF-MS 8 21 312 Lipid profiling 0 0 95 Di- and tri-glycerides, phospholipids TOTAL 216 234 732 1182 aIdentified metabolites refer to those confirmed by authentic standards and by database matching. metabolites refer to those identified by database matching but not confirmed by internal bAnnotated standards. cAnnotated peaks refers to peaks identified at the structure class level. SupportingTable 3. Summary of Statistically Significant Differences in Ionomic Profiles Conventional and Element Site Group A and B Transgenic Boron 2.90E-09 ns ns Sodium ns ns ns Magnesium ns 4.10E-09 ns Aluminum ns ns ns Phosphorus ns ns ns 4.50E-07 ns ns Sulfur ns ns ns Potassium ns ns ns Calcium 4.30E-15 1.60E-06 6.40E-06 Manganese 2.50E-05 7.00E-14 1.20E-10 Iron 2.70E-07 7.50E-08 ns Cobalt 6.50E-17 ns ns Nickel 2.40E-23 4.40E-05 5.70E-05 Copper Zinc 1.40E-42 2.80E-08 ns Arsenic ns ns ns Selenium 1.10E-50 ns ns Rubidium 3.80E-25 ns 7.50E-07 Strontium 9.40E-49 ns ns Molydenum 3.60E-51 ns ns 8.40E-05 ns ns Cadmium p-values are adjusted by Bonferroni correction. Ns= not significant at a=0.05 SUPPORTING FIGURES Color versions of Figure 3 of Main Text Supporting Fig. 1. Evaluation of the achieved coverage of metabolite profile data. PCA was performed on the predicted physicochemical properties of the detected metabolites and the metabolites in the SoyCyc database. (a) The score plots show that the distribution of the metabolites identified or annotated in our study occupies a similar space as the reference database metabolites. The inset barplot shows the ratio of variance among the reference metabolites covered by each of the individual platforms and the summarized data set. For instance, the 65% coverage of the LC-TOF-MS data implies that the seven annotated peaks having different physic-chemical properties from each other can occupy 65% of chemical space of the soybean metabolome. (b) The loading plots show that PC1 is dominated by size related- and PC2 by solubility-related properties. Coverage of chemical diversity was estimated by fetching all available predicted physicochemical properties from the ChemSpider database (http://www.chemspider.com) for identified metabolites and the metabolites listed in the SoyCyc database (ver. 3.0) (http://www.plantcyc.org/) (see ref. 19 in main text). All properties were scaled to unit variance (autoscaling). Chemical coverage was defined as the percentage of variance among the SoyCyc metabolites that could be predicted using a PCA model of the properties of a given subset of metabolites. Specifically, chemical coverage was defined as: 2 ∑[(𝑋𝑆𝑜𝑦𝐶𝑦𝑐 𝑃𝑠𝑢𝑏 )𝑃′𝑠𝑢𝑏 − 𝑋𝑆𝑜𝑦𝐶𝑦𝑐 ] Coverage = [1 − ] 2 ∑ 𝑋𝑆𝑜𝑦𝐶𝑦𝑐 where XSoyCyc are the unit-variance scaled physicochemical properties of metabolites in SoyCyc, and Psub the loadings matrix from the PCA model of the properties of a subset of metabolites (e.g. those from an individual platform). Missing value robust PCA was with the pcaMethods package (Stackles et al. 2007). Stackles W, Redestig H, Scholz M, Walther D, & Selbig J (2007) pcaMethods--a bioconductor package providing PCA methods for incomplete data. Bioinformatics 23(9):1164-1167. Supporting Fig. 2. Principal component analysis of the identified or annotated metabolites/ peaks. Number of observations, 106; number of variables, 681. PC1 (t[1]), 15%; PC2 (t[2]), 9.8%. Supporting Fig. 3. Principal component analysis of the identified or annotated metabolites/peaks and including the ionomics data. Number of observations, 106; number of variables, 701. PC1 (t[1]), 14.9%; PC2 (t[2]), 9.8%. Supporting Fig. 4. The score scatter plot of OPLS-DA using the identified or annotated metabolites/ peaks and including the ionomics data. The plot is color-and shape-coded by site (ILJA:blue, ILJE:green) (a) and by variety (b). A site location effect was observed for all varieties. We focused on the differences in predictive components 1 and 2 (t[1] and t[2]) according to the discriminant scores related to varietydependent differences. The number of each component in the score plots represents the sum of squares of all the annotated metabolites explained by the extracted components (t[1], 10.5%; t[2], 8.5%). The model was validated by analysis of variance testing of cross-validated predictive residuals (CV-ANOVA) pCV < 0.01). Number of observations, 106; number of variables, 719 (X = 701; Y = 18). Supporting Fig. 5. Graphic representation of nodes of the first neighbors in the yield-to-metabolite correlation networks of samples harvested at ILJA (above) and ILJE (below). We applied Spearman’s correlation analysis to generate the correlation networks. Solid and dot links represent a positive and a negative correlation (p < 0.01) To evaluate the correlation between the metabolite or ion level and yield at ILJA/ILJE from Table 1 (main text) we calculated the Spearman’s correlation coefficient (r). The statistical significance of the correlation coefficient was tested against the hypothesis of no correlation (r = 0) according to t-statistics; where n indicates the sample size. The significance level was set at p < 0.05. .