Economics 405
advertisement

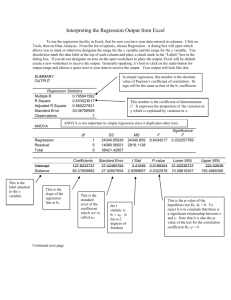
Economics 405 Due—November 18 at 6:30 pm. 1. Problem Set #3 A political scientist specified the following population regression model: voteA = 0 + 1 expendA + 2 expendB + 3 totexpen + u where voteA is the percentage of the vote captured by candidate A, expendA is campaign expenditures by candidate A, expendB is campaign expenditures by candidate B, and totexpen is the sum of campaign expenditures by both candidates. a. Which of the multiple linear regression (MLR) assumptions does this model violate? Explain why. The model violates MLR.3 (No Perfect Collinearity). There is an exact linear relationship between totexpen and expendA and expendB since totexpen = expendA + expendB. Intuitively, we’re asking the effect of a $1,000 increase in expenditure by candidate A on voteA, holding total expenditure and expenditure by candidate B constant. Increase in expenditure by A, with expenditure by B held constant, of course implies total expenditure does not stay constant. So there is no way for OLS to estimate 1 (or 2 and 3 for that matter). b. Use the Wooldridge data set Vote1 to attempt this regression (you’ll need to generate the totexpen variable yourself). Attach the regression output and comment on the outcome. STATA: . gen totexpen=expendA+expendB . regress voteA expendA expendB totexpen Source | SS df MS -------------+-----------------------------Model | 25679.8879 2 12839.944 Residual | 22777.3606 170 133.984474 -------------+-----------------------------Total | 48457.2486 172 281.728189 Number of obs F( 2, 170) Prob > F R-squared Adj R-squared Root MSE = = = = = = 173 95.83 0.0000 0.5299 0.5244 11.575 -----------------------------------------------------------------------------voteA | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------expendA | (dropped) expendB | -.0744583 .0053848 -13.83 0.000 -.0850879 -.0638287 totexpen | .0383308 .0033868 11.32 0.000 .0316452 .0450165 _cons | 49.619 1.426147 34.79 0.000 46.80376 52.43423 2 EXCEL: SUMMARY OUTPUT Regression Statistics Multiple R 0.733143139 R Square 0.537498862 Adjusted R Square 0.529288783 Standard Error 11.51575524 Observations 173 ANOVA df 3 169 172 SS MS F 26045.71597 8681.905 65.46817 22411.53258 132.6126 48457.24855 Coefficients 49.60647306 363.9483405 363.8757627 -363.9109519 Standard Error t Stat P-value 1.418846846 34.96253 2.82E-79 219.1117063 1.661017 0.098564 219.1128385 1.660678 0.098632 219.1122736 -1.66084 0.098599 Regression Residual Total Intercept expendA expendB totexpen Note that STATA won’t run the regression I asked it to run. Instead it arbitrarily drops expendA from the regression. Excel actually runs the regression, but note that the coefficients on expendA and expendB are virtually identical and that the coefficient on totexpen is also identical but of the opposite sign. Furthermore, interpretation of any of the Excel coefficients results in nonsense. For example, the estimated 1 implies that a $1,000 increase in expenditure by candidate A results in 363.9 percentage point increase in the share of votes for candidate A! c. Generate the variables expAsqr (equal to expendA squared) and expBsqr (equal to expendB squared). Regress voteA on expendA, expAsqr, expendB, and expBsqr. Write out the fitted model. (Use the fitted model format displayed on p. 127 of the text, i.e., include coefficient standard errors below estimated coefficients.) Attach your regression results. Explain why this model is estimable (i.e., explain why the MLR assumption violated in part b is not violated here). . gen expAsqr=expendA^2 . gen expBsqr=expendB^2 . regress voteA expendA expAsqr expendB expBsqr 3 Source | SS df MS -------------+-----------------------------Model | 36053.1139 4 9013.27847 Residual | 12404.1347 168 73.8341349 -------------+-----------------------------Total | 48457.2486 172 281.728189 Number of obs F( 4, 168) Prob > F R-squared Adj R-squared Root MSE = = = = = = 173 122.07 0.0000 0.7440 0.7379 8.5927 -----------------------------------------------------------------------------voteA | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------expendA | .081002 .005663 14.30 0.000 .0698222 .0921818 expAsqr | -.0000521 5.50e-06 -9.47 0.000 -.0000629 -.0000412 expendB | -.0787343 .0056362 -13.97 0.000 -.0898613 -.0676074 expBsqr | .0000494 5.34e-06 9.24 0.000 .0000388 .0000599 _cons | 49.26944 1.478249 33.33 0.000 46.3511 52.18778 ------------------------------------------------------------------------------ Writing the estimated model out in fitted model format: ^ voteA = 49.27 + .081expendA - .0000521expAsqr - .079expendB + .0000494expBsqr (1.478) (.0057) (.0000055) (.0056) (.0000053) 2 n = 173 R .744 The model is estimable since the quadratic terms, though exact functions of the expenditure variables, are not exact linear functions of the expenditure variables. d. What do the quadratic terms added to the model in part c allow for? Explain. Using the fitted model from part c, what is the impact on predicted voteA of a $1,000 increase in expenditure by candidate A? (In ^ voteA calculus terms, I’m asking for .) What is the impact on predicted voteA of expendA a $1,000 increase in expenditure by candidate B ^ voteA (i.e., )? expendB The quadratic terms allow for possible non-linear relationships between voteA and the expenditure variables. First note that expAsqr (expendA)2 and expBsqr (expendB)2 . Then ^ voteA ˆ1 2ˆ 2 expendA .081 (2 (.000052))expendA .081 .000104expendA expendA 4 The above statement implies that the partial effect of expenditure by candidate A is positive but diminishing as expenditure by A increases. Taking summary statistics for expendA: . summarize expendA Variable | Obs Mean Std. Dev. Min Max -------------+-------------------------------------------------------expendA | 173 310.611 280.9854 .302 1470.674 Plugging mean expenditure of 310.611 into the partial effect equation above, we get: ^ voteA .081 ((.000104) (310.611)) .049 . Hence, a candidate whose total expendA expenditure is at the mean level is predicted to gain almost .05 of a percentage point of votes cast by raising expenditure by $1,000. On the other hand, a candidate whose spending level is one standard deviation above the mean level (310.611 + 280.99 = 591.60) is predicted to gain only ^ voteA .081 ((.000104) (591.60)) .019 of a percentage point of votes expendA cast by spending another thousand dollars on the campaign. Thus the model predicts diminishing returns to campaign expenditures by a candidate. The partial effect of expendB is: ^ voteA ˆ3 2ˆ 4 expendB .079 (2 (.0000494))expendB .079 .0000998expendB expendB Interpreting, expenditure by candidate B has a negative impact on the percentage of votes cast for candidate A, but this impact becomes less negative the larger is expendB (by virtue of the second term). 2. Read the discussion titled “A Partialling Out Interpretation of Multiple Regression” on pp.78-79 of the text. a. Use the Wooldridge dataset Ceosal2 to estimate the following model: lsalary 0 1comten 2 ceoten 3lsales u where lsalary is the log of the CEO’s salary, comten is the total number of years the CEO has worked for the company in one capacity or 5 another, ceoten is the number of years the CEO has served as CEO of the company, and lsales is the log of company sales. Write out the fitted model (again, use the format from p. 127). Interpret each of the estimated slope coefficients. Attach the regression output as an appendix. . regress lsalary comten ceoten lsales Source | SS df MS -------------+-----------------------------Model | 21.614243 3 7.20474766 Residual | 43.0319701 173 .248739711 -------------+-----------------------------Total | 64.6462131 176 .367308029 Number of obs F( 3, 173) Prob > F R-squared Adj R-squared Root MSE = = = = = = 177 28.97 0.0000 0.3343 0.3228 .49874 -----------------------------------------------------------------------------lsalary | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------comten | -.0101184 .0033397 -3.03 0.003 -.0167102 -.0035266 ceoten | .0170786 .0055813 3.06 0.003 .0060624 .0280949 lsales | .2481522 .0272305 9.11 0.000 .1944054 .3018989 _cons | 4.880288 .1997791 24.43 0.000 4.48597 5.274606 ------------------------------------------------------------------------------ The fitted model is: ^ lsalary 4.880 .010comten .017ceoten .248lsales (.200) (.0033) (.0056) (.0272) 2 R .334 n = 177 The slope coefficient on comten implies that an additional year of tenure with a company reduces predicted CEO earnings by 1%, other things equal. In other words, given two CEOs with the same number of years on the job as CEO and whose firm sales are identical, the CEO with one year more in total tenure with her/his firm is predicted to earn 1% less than the CEO with one less year of total company tenure. (Hmmm, interesting result!) The slope coefficient on ceoten implies that an additional year of tenure as CEO, with total years of tenure at the company and log sales held constant, increases predicted CEO earnings by 1.7%. Finally, the coefficient on lsales is an elasticity and implies that a 1% increase in firm sales increases predicted CEO earnings by .248%, holding total tenure and tenure as CEO constant. b. Confirm the partialling out interpretation for ˆ1 . Do this by first regressing comten on ceoten and lsales. Attach these regression results. Save the residuals from this regression (call them r1hat). [Stata users, first run your regression. Your next command should then be “predict r1hat, residuals.” Excel users, check the residuals box in the regression dialog.] Now run the simple regression of lsalary on r1hat. Write out the fitted model. Interpret the estimated coefficient on r1hat. How does 6 the estimated coefficient of r1hat compare with the estimated coefficient on comten in part a? . regress comten ceoten lsales Source | SS df MS -------------+-----------------------------Model | 4302.91318 2 2151.45659 Residual | 22301.3354 174 128.168594 -------------+-----------------------------Total | 26604.2486 176 151.160503 Number of obs F( 2, 174) Prob > F R-squared Adj R-squared Root MSE = = = = = = 177 16.79 0.0000 0.1617 0.1521 11.321 -----------------------------------------------------------------------------comten | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------ceoten | .5580039 .1194227 4.67 0.000 .3223003 .7937074 lsales | 2.146732 .5963127 3.60 0.000 .9697944 3.323669 _cons | 2.540943 4.530812 0.56 0.576 -6.401482 11.48337 ------------------------------------------------------------------------------ Next: . predict r1hat, residuals . regress lsalary r1hat Source | SS df MS -------------+-----------------------------Model | 2.28323989 1 2.28323989 Residual | 62.3629732 175 .356359847 -------------+-----------------------------Total | 64.6462131 176 .367308029 Number of obs F( 1, 175) Prob > F R-squared Adj R-squared Root MSE = = = = = = 177 6.41 0.0122 0.0353 0.0298 .59696 -----------------------------------------------------------------------------lsalary | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------r1hat | -.0101184 .0039974 -2.53 0.012 -.0180077 -.002229 _cons | 6.582848 .0448702 146.71 0.000 6.494291 6.671404 ------------------------------------------------------------------------------ The fitted model is: ^ lsalary = 6.582 - .010r1hat (.0449) (.0040) R 2 .035 n = 177 The coefficients on r1hat and on comten are identical as the discussion in the Wooldridge text indicates they should be. The coefficient on comten in the original regression tells us the effect on predicted CEO log salary of a one year increase in total tenure with the company, holding tenure as CEO and firm log sales constant. r1hat is the component of comten that cannot be explained by variation in ceoten or lsales. In other words, r1hat is comten after 7 netting out the effects of ceoten and lsales. In essence, r1hat also holds comten and lsales constant and this explains why the coefficient is the same in the two regressions. 3. Use the data set Hprice2 from the textbook data files to do this problem. The data set contains information on median housing price in n = 506 communities. Suppose that the following equation is the true model for log median housing price in a community: log( price ) 0 1 log( nox) 2 rooms u where log(price) is the log of median housing price in the community; log(nox) measures the level of air pollution in the community and is the log of nitrous oxide concentration measured in parts per million; and rooms is the average number of rooms per house in the community. a. What are the probable signs of 1 and 2 ? Explain. 1 0 since a greater level of pollution should reduce home values. 2 0 since larger homes should be worth more. b. What is the interpretation of 1 ? What is the interpretation of 2 ? 1 is the percent change in expected home value due to a one percent increase in nitrous oxide concentration, holding the average number of rooms per house constant. 2 is the percent change in expected home value due to a one room increase in average number of rooms, holding log(nox) constant. c. Run a simple regression of rooms on log(nox). Write out the fitted model. Attach the regression output as an appendix to the problem set. Interpret the slope coefficient on log(nox). . regress rooms lnox Source | SS df MS -------------+-----------------------------Model | 23.1881055 1 23.1881055 Residual | 226.099087 504 .4486093 -------------+-----------------------------Total | 249.287193 505 .493638005 Number of obs F( 1, 504) Prob > F R-squared Adj R-squared Root MSE = = = = = = 506 51.69 0.0000 0.0930 0.0912 .66978 -----------------------------------------------------------------------------rooms | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------lnox | -1.063912 .1479814 -7.19 0.000 -1.354648 -.7731754 _cons | 8.085351 .2523091 32.05 0.000 7.589644 8.581058 8 The fitted model is: ~ rooms = 8.085 – 1.064lnox (.252) (.148) R 2 .093 n = 506 The estimated model here is a level-log model. As always the slope coefficient tells us the change in predicted dependent variable due to a 1-unit change in the regressor. Since the regressor is in logs, a 1-unit change is a “big” change (i.e., a 100 percent change). Usually, we’re interested in what happens given more marginal change in the regressor, for example, a 1 percent change (or a .01 change in proportional terms). To find this effect, take ˆ1 / 100 1.064 / 100 .01064 . Hence the interpretation of the slope coefficient on lnox is that a 1% increase in nitrous oxide concentration is associated with a decrease in predicted rooms of .01, a negative but relatively small effect. (See Wooldridge, p. 46, for interpretation of the regression coefficient in the level-log model.) d. Run the simple regression of log(price) on log(nox). Write out the fitted model. Interpret the model’s slope coefficient. Attach the regression output as an appendix. . regress lprice lnox Source | SS df MS -------------+-----------------------------Model | 22.2916542 1 22.2916542 Residual | 62.2905708 504 .123592402 -------------+-----------------------------Total | 84.582225 505 .167489554 Number of obs F( 1, 504) Prob > F R-squared Adj R-squared Root MSE = = = = = = 506 180.36 0.0000 0.2636 0.2621 .35156 -----------------------------------------------------------------------------lprice | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------lnox | -1.043144 .0776728 -13.43 0.000 -1.195746 -.8905413 _cons | 11.70719 .1324325 88.40 0.000 11.44701 11.96738 ------------------------------------------------------------------------------ ~ log(price) = 11.707 - 1.043lnox (.132) (.0777) R 2 .264 n = 506 Since both variables are in logarithms, the slope coefficient is an elasticity. Interpreting, the slope coefficient implies that a 1% increase in nitrous oxide concentration in a community is associated with a 1.043% reduction in predicted home value. Note, however, that the effect of home size, as measured by average number of rooms, is not controlled for in this model. 9 e. . regress Run the multiple regression of log(price) on log(nox) and rooms. Write out the fitted model. Interpret the slope coefficient of each regressor. Attach the regression output as an appendix. lprice lnox rooms Source | SS df MS -------------+-----------------------------Model | 43.4513652 2 21.7256826 Residual | 41.1308598 503 .081771093 -------------+-----------------------------Total | 84.582225 505 .167489554 Number of obs F( 2, 503) Prob > F R-squared Adj R-squared Root MSE = = = = = = 506 265.69 0.0000 0.5137 0.5118 .28596 -----------------------------------------------------------------------------lprice | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------lnox | -.7176736 .0663397 -10.82 0.000 -.8480106 -.5873366 rooms | .3059183 .0190174 16.09 0.000 .268555 .3432816 _cons | 9.233738 .1877406 49.18 0.000 8.864885 9.60259 The fitted model is: ^ log(price) = 9.234 - .718lnox + .306rooms (.188) (.0663) (.019) 2 R .514 n = 506 Since both log(price) and lnox are logarithmic, the coefficient of lnox is an elasticity. The coefficient on lnox implies that a 1% increase in nitrous oxide concentration reduces home value by .718%, with average number of rooms held constant. Note that once we control for number of rooms, the estimated impact of pollution becomes considerably smaller. The omission of number of rooms from the regression of part d resulted in downward bias away from zero. The coefficient on rooms implies that a one room increase in the average number of rooms raises predicted home value by 30.6%, with pollution level held constant. f. ~ ~ Verify mathematically that 1 ˆ1 ˆ 2 1 . ~ From part d, 1 1.043 . From part e, ˆ1 .718 and ˆ 2 .306 . From part c, ~ 1 1.064 . Plugging these values into the statement, -1.043 = -.718 + [(.306)(-1.064)] = -1.043. The statement is verified. Intuitively, the negative impact of pollution is over-estimated in part d because more polluted communities also tend to have smaller homes. Smaller homes are worth less in the real estate market. Ignoring house size in the log(price) regression means we are not holding home size constant in evaluating the impact of pollution on home value. Since more polluted communities also tend to have smaller homes, some of the adverse impact of pollution on home price found in the simple regression will in 10 actuality be the result of smaller homes being found in those communities. To see the true impact of pollution on home price, we need to hold home size constant. 4. Suppose we want to estimate the ceteris paribus effect of x1 on y. Data for two additional ~ control variables, x2 and x3, are collected. Let 1 be the simple regression estimate from y on x1 and let ˆ be the multiple regression estimate of y on x1, x2, and x3. 1 a. If x1 is highly correlated with x2 and x3 in the sample, and x2 and x3 have large partial ~ effects on y, would you expect 1 and ˆ1 to be similar or very different? Explain. Because x1 is highly correlated with x2 and x3 , and these latter variables have large partial effects on y, the simple and multiple regression coefficients on x1 can differ by large amounts. Intuitively, think in terms of equation (3.45) from the book, i.e., ~ ~ E ( 1 ) 1 2 1 , where the betas are the true partial effects of the relevant variables and the delta term is the regression coefficient on x1 in a regression of the omitted variable on the other explanatory variables in the model. In the case at hand, 2 and 3 will both be large (“x2 and x3 have large partial effects on y”) and ~ 1 terms will also be large (“x1 is highly correlated with x2 and x3”). b. If x1 is almost uncorrelated with x2 and x3, but x2 and x3 are highly correlated with ~ each other, would you expect 1 and ˆ1 to be similar or very different? Explain. Here we would expect 1 and ̂1 to be similar. The amount of correlation between x2 and x3 does not directly affect the multiple regression ~ estimate on x1 if x1 is essentially uncorrelated with x2 and x3 (i.e., the 1 terms are approximately equal to 0). c. If x1 is highly correlated with x2 and x3, but x2 and x3 have small partial effects on y, ~ would you expect se( 1 ) or se( ˆ1 ) to be smaller? Explain. In this case we are (unnecessarily) introducing multicollinearity into the regression: x2 and x3 have small partial effects on y and yet x2 and x3 are highly correlated with x1 . Adding x2 and x3 likely increases the standard error of the coefficient on x1 substantially, so se( ̂1 ) is likely to be much larger than se( 1 ). d. If x1 is almost uncorrelated with x2 and x3, x2 and x3 have large partial effects on y, ~ and x2 and x3 are highly correlated, would you expect se( 1 ) or se( ˆ1 ) to be smaller? Explain. 11 In this case, adding x2 and x3 will decrease the residual variance without causing much collinearity (because x1 is almost uncorrelated with x2 and x3 ), so we should see se( ̂1 ) smaller than se( 1 ). The amount of correlation between x2 and x3 does not directly affect se( ̂1 ). 5. a. b. What is the Gauss-Markov Theorem? Discuss the importance/relevance of the Gauss-Markov Theorem. Read pp. 102-104 of Wooldridge for answers to both a and b. 6. Assume that MLR.1-MLR.6 are valid for a k regressor model: a. Draw the sampling distribution for ˆ j . f ( ˆ j ) j b. ˆ j Explain why the graph looks as you have drawn it. By Theorem 4.1, when MLR.1 – MLR.6 are valid for the k regressor model, the sampling distribution of ˆ j is ˆ j ~ N ( j ,Var ( ˆ j )) . The distribution 12 characterized in the graph of part a is normal and centered at j per the distribution statement. c. If the sample size were to double, how (if at all) would that affect your drawing? Illustrate and explain. Var ( ˆ j ) 2 . As n increases, SSTj increases, hence Var ( ˆ j ) decreases. SST j [1 R ] The implication for the sampling distribution is that it becomes less dispersed about j as in the graph below. f ( ˆ ) 2 j j Distribution becomes less dispersed as n increases j ˆ j 13 7. Use the textbook data file Lawsch85 to estimate: log( salary ) 0 1 LSAT 2 GPA 3 log( libvol ) 4 log( cost ) 5 rank u where log(salary) is the log of median starting salary for a law school’s graduates; LSAT is the median LSAT score for the law school’s admits; GPA is the median undergraduate GPA of the law school’s admits; libvol is the number of volumes in the school’s library (in thousands); cost is the school’s tuition cost; and rank is the law school’s ranking (where 1 is the best and 175 is the worst). a. . regress Attach your regression output as an appendix. lsalary LSAT GPA llibvol lcost rank Source | SS df MS -------------+-----------------------------Model | 8.73362207 5 1.74672441 Residual | 1.64272974 130 .012636383 -------------+-----------------------------Total | 10.3763518 135 .076861865 Number of obs F( 5, 130) Prob > F R-squared Adj R-squared Root MSE = = = = = = 136 138.23 0.0000 0.8417 0.8356 .11241 -----------------------------------------------------------------------------lsalary | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------LSAT | .0046965 .0040105 1.17 0.244 -.0032378 .0126308 GPA | .2475239 .090037 2.75 0.007 .0693964 .4256514 llibvol | .0949932 .0332543 2.86 0.005 .0292035 .160783 lcost | .0375538 .0321061 1.17 0.244 -.0259642 .1010718 rank | -.0033246 .0003485 -9.54 0.000 -.004014 -.0026352 _cons | 8.343226 .5325192 15.67 0.000 7.2897 9.396752 ------------------------------------------------------------------------------ b. What is the estimated ceteris paribus effect of a 1-point increase in GPA on salary? What has truly been “held constant” when you make this statement? The model predicts that a 1-point increase in GPA increases predicted earnings by 24.8%. LSAT scores, library size (measured by books), law school cost, and law school rank have been controlled for in the model. That is, given two law schools with the same median LSAT score for admits, the same library size, the same tuition cost, and the same rank, predicted earnings are 24.8% higher for the school for which undergraduate GPA is 1 point higher. c. Use Stata or Excel to calculate the standard deviation of GPA (attach the results). Is a 1 point change in GPA from part b a relatively “big” change in GPA or a relatively “small” change in GPA? Explain. The Lawsch85 data set has 156 observations in total, but there are missing values in both the dependent variable and in some of the regressors. As a consequence, there are only 136 observations that can be used in the log(salary) regression (see part a). 14 In doing the summary statistics, I first restricted the calculations to observations in the regression sample. The command to do this in Stata is: . keep if e(sample) This command retains only observations that were in the regression sample. . summarize GPA Variable | Obs Mean Std. Dev. Min Max -------------+-------------------------------------------------------GPA | 136 3.309632 .1972305 2.8 3.82 Given that the standard deviation of GPA is only .197, we can conclude that a 1point change in GPA across these law schools represents a huge (unrealistically large) change in GPA. So a more interesting question to ask might be what is the ceteris paribus effect of a one standard deviation change in GPA on salary? d. What is the estimated ceteris paribus effect of a one standard deviation change in GPA on salary? Show your work. ^ Recall yˆ ̂ j x j . Therefore: log( salary ) (.248) (.197) .049 Hence, the predicted median salary, other factors held constant, is about 5% higher for a school for which the undergrad GPA of its students is a standard deviation higher. e. State and interpret the value of the regression’s ̂ . The standard error of the regression is .112. Therefore, the typical amount of unexplained difference between the actual value of log(salary) and its predicted value is .112 log points. Since the dependent variable here is measured in logs, we can easily convert to percentages by multiplying by 100. Therefore, the typical amount of unexplained difference between actual and predicted salary is 11.2%. f. Determine SSTGPA (you should be able to figure this out based on your work for part 2 2 c) and RGPA (where RGPA is the R2 from a regression of GPA on the other explanatory 2 variables in the model). Attach your results. Using ̂ , SSTGPA , and RGPA , verify the computer’s calculation of se(ˆ ) from part a. Show your work. Evaluate and GPA discuss the degree of multicollinearity in ̂ GPA . 15 2 .0388998 . From part c, sGPA .1972305 sGPA 2 sGPA . regress SSTGPA SSTGPA .0388998 SSTGPA 135 .0388998 5.251473 . n 1 136 1 GPA LSAT llibvol lcost rank Source | SS df MS -------------+-----------------------------Model | 3.69271787 4 .923179469 Residual | 1.55876379 131 .01189896 -------------+-----------------------------Total | 5.25148166 135 .038899864 Number of obs F( 4, 131) Prob > F R-squared Adj R-squared Root MSE = = = = = = 136 77.58 0.0000 0.7032 0.6941 .10908 -----------------------------------------------------------------------------GPA | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------LSAT | .0266461 .0031186 8.54 0.000 .0204768 .0328154 llibvol | .0151729 .0322422 0.47 0.639 -.0486099 .0789556 lcost | -.1460243 .0284231 -5.14 0.000 -.2022521 -.0897966 rank | -.0014423 .0003138 -4.60 0.000 -.002063 -.0008215 _cons | .4847979 .5150086 0.94 0.348 -.534012 1.503608 -----------------------------------------------------------------------------2 .7032 , i.e., only From the regression results table above, we observe that RGPA about 30% of the variation in GPA is independent of the other explanatory variables. ˆ .11241 Estimated se( ˆ j ) .090039 , which 2 ( 5 . 251473 ) * ( 1 . 7032 ) SST j [1 R j ] is the same as the standard error value reported for GPA’s coefficient in the regression results table of part a. 2 The high RGPA suggests a considerable degree of collinearity between GPA and the other regressors. Perhaps this is not too surprising. For example, one would expect average LSAT and average undergraduate GPA to be highly correlated. The effect that collinearity has on the variance of the estimated regression coefficient can be seen by re-writing the estimated variance as 1 ˆ 2 ˆ 2 Var ( ˆ j ) SST j [1 R 2j ] 1 R 2j SST j The second term to the right of the last equality is like estimated coefficient variance in simple regression. The first term to the right of the last equality is > 1 and measures the degree by which the coefficient variance is inflated as a result of correlation between the regressor in question and the other regressors in the model. If the regressor in question is uncorrelated with the other variables in the model, then R 2j 0 and no inflation of the variance occurs. The larger is R 2j , however, the larger is 1 1 3.369 , . In GPA’s case, its variance inflation factor is 2 1 .7032 1 Rj 16 hence the variance of GPA’s coefficient is much larger than would be the case in the absence of collinearity. With all of this said, however, the large variance inflation factor hasn’t rendered GPA statistically insignificant (its t-ratio is 2.75). What has saved the day? Probably the large sample size as this makes SSTj large, counteracting the effect of the collinearity.