Statistics handout
advertisement

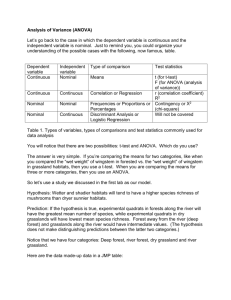
Please bring this handout with you every time you do data analysis in the computer lab. This handout is also available on my website. JMP Instructions A worked example Your biology instructor has encouraged you to investigate some aspects of a flowering plant wingstem. You have decided to investigate whether wingstem grows better in forested areas than in grasslands. You randomly choose wingstem from each of these two habitats for laboratory analysis, ending up with 22 plants - 12 from forest and 10 from grassland. In an attempt to impress your instructor you also note whether there is a trillium plant within 1 meter of the wingstem plant - there seemed to be quite a few trillium plants near wingstem plants in the forested habitat. Entering data in the table Each column must be one variable. For the purposes of this example, you have decided to weigh each plant (“wet weight” means it hasn’t had a chance to dry out), and to measure the length of its stem. If you are comparing forests and grasslands, then one column will be for “habitat” (forest or grassland), the 2nd column will be “wet weight”, the 3rd column will be “stem length”, and your final column will be “trillium nearby?”. You can enter these in any order you’d like. Make sure each column is assigned an appropriate “modeling type” (continuous, nominal, or ordinal data) as follows: In the Columns box, you should see each of your heading names with a symbol (button). Click on the button to get a pop-up menu and change the variable type. Most of the variables you use for analysis should be classified as either continuous (data that you measure in some manner) or nominal (data that you apply a name or category-type to). We may discuss ordinal data at a later time. Thus make sure that the “habitat” and “trillium nearby” columns have an “N” button (for nominal), and the “wet weight” and “stem length” columns have a “C” button (for continuous). The most recent version of jmp replaces the “N” with a bar graph, and the “C” with a line graph. Your data file will look something like this: 1 Which test to use? The answer to this question depends on (1) which questions you ask and on (2) the types of variables you are considering for asking your questions. Let’s consider a few examples. Example I. Do wingstem plants from grasslands tend to weigh more than wingstem plants from forested regions? To answer this question you would ask whether the mean “wet weight” of wingstem plants from grasslands is significantly greater than the mean “wet weight” of wingstem from forested regions. 2 There are two steps to this process: a. Identify your dependent and independent variables dependent variable - the variable you believe might be influenced or modified by some treatment or exposure independent variable - the variable you believe may be influencing or affecting the dependent variable In this case we believe that habitat (the independent variable) may be influencing “wet weight” (the dependent variable). Note that it doesn’t make sense to look at it the other way around! b. Decide whether each of your variables is nominal or continuous. If the dependent variable is continuous, and the independent variable is nominal, you will use a t-test for cases when your independent variable has two categories (such as this case where we have either forest or grassland for our “habitat” variable), or an analysis of variance (ANOVA) in cases where your independent variable has three or more categories. The table below summarizes all of the possible combinations. At this point we are confining the discussion to the first row of the table. Dependent variable Continuous Independent variable Nominal Type of comparison Test statistics Means Continuous Continuous Correlation or Regression Nominal Nominal Nominal Continuous Frequencies or Proportions or Percentages Discriminant Analysis or Logistic Regression t (for t-test) F (for ANOVA (analysis of variance)) r (correlation coefficient) R2 Contingency or X2 (chi-square) Will not be covered Table 1. Types of variables, types of comparisons and test statistics commonly used for data analysis You already knew that you were comparing means - now you know you will do a t-test. t-tests Please do the following: 1. Open or create your data file 2. .Analyze menu Fit Y by X 3. You should see a window as follows: 3 Remember that in this case, our dependent variable is “wet weight”, and we are hypothesizing that it is being influenced by the independent variable - “habitat”. Also make sure you understand that “wet weight” is continuous and “habitat” is nominal (you can confirm by looking at the little buttons in the select columns window). If you check out table 1, you will confirm that you will be comparing the “wet weight” mean for the forested habitat with the “wet weight” mean for the “grassland” habitat, and using a t-test to test for whether the means are statistically significantly different from each other. 4. Highlight “wet weight” and click on “y,response” in the “fit y by x” window. (In JMP language, “y, response” is the same as dependent variable) 5. Highlight “habitat” and click on “x-factor” in the “fit y by x” window. (In JMP language, xfactor is the same as independent variable). 6. Click OK. The following will come up on your screen (hopefully) 4 Oneway Analysis of “wet weight” in grams By habitat 8 wet weight in grams 7 6 5 4 3 2 1 0 forest grassland habitat 7. Click on the red triangle in the title bar to get a pop-up menu. Select “Means and Std Dev”. Below the graph you will see calculations of the means, Standard deviations, Standard Error of the Mean and confidence intervals for each of your independent variables. In the graph some blue lines have been added among your black data points. The center blue line is the mean. It is connected by a vertical blue line to a pair of short blue horizontal lines that represent the mean-plus-one-standard-error and the mean-minus-one-standard-error. Further away from the mean are two longer horizontal blue lines that represent the mean-plus-one-standarddeviation and the mean-minus-one-standard-deviation. 5 8. Click the red triangle again and select “ t test”. You will see the addition of another graph and other calculations. Don’t worry about the graph for now. There are two important numbers in this output. T Ratio = t = -1.81115. The negative sign doesn’t matter, and you should usually report t-vales down to two decimal points, so in your report you would state that t = 1.81 Prob > |t| = p value = 0.0866. Please refer to the end of this handout for information on interpreting p-values. Example II - Linear Correlation Do taller plants tend to weigh more than shorter plants. A more formal way of stating this in hypothesis form is as follows: Hypothesis: There is a positive correlation between “stem length” and “wet weight”. In this case we believe that “stem length” (the independent variable) may be influencing “wet weight” (the dependent variable). In this case you need to do some serious thinking to convince yourself that “stem length” is the factor that would influence “wet weight”, and not the other way around. Because we hypothesize that “stem length” is influencing “wet weight”, “stem length” is the independent variable and “wet weight” is the dependent variable. Both of the variables are continuous. If both variables are continuous, refer to Table 1 and note that the correct analysis is correlation or linear regression (these two analyses are functionally equivalent). JMP Steps 1. Analyze menu Fit Y by X 2. Click on your dependent variable - ““wet weight” in grams” (which should have a C beside it). then on “Y, Response”. Click on the independent variable - “stem length” (cm) - (which should also have a C beside it) and then on “X, Factor.” Click OK. You will see a scatter plot of the data. 6 3. Click on the red triangle in the title bar and select “ Fit Line.” You will see a red line appear through your data points. That is the best straight line that fits your data (it minimizes the sum of the distances from each data point to the line). A bunch of output will also appear below the graph. 7 For now I am concerned with two parts of this output. A. Under “summary of fit” you will note the RSquare = 0.880328. If you were reporting your results you would report that R2 = 0.88. In general, the closer R2 is to 1, the stronger is your correlation. The graph looks impressively linear, so it is no surprise to have a high R 2 value. B. Under “Parameter Estimates” you will note that if you go across from “stem length” and down from Prob > |t| you will find a value of <.0001. That tells us that the correlation between “stem length” and “wet weight” is very strong. Finally to determine if the correlation is positive or negative, you will need to look at the graph and see if the slope of the line is positive or negative. Example III - Contingency or Chi-square (X2) analysis - for this problem, use the made-up data table from the previous lab (the wingstem data table with 22 cases) Table 1. Wingstem data table from previous lab. Is trillium more likely to be associated with wingstem in forested regions than in grasslands? Again you could state this more formally: Hypothesis: There is a higher frequency of trillium near wingstem in forested regions than in grassland regions. 8 You are asking whether habitat type (forest or grassland) influences whether trillium is likely to be nearby (yes or no). Thus both variables are nominal. The dependent variable is “trillium nearby?” and the independent variable is “habitat type”. Refer to Table 2 and note that in cases in which both variables are nominal, you will compare frequencies or percentages using a contingency or chi-square test. Dependent variable Continuous Independent variable Nominal Type of comparison Test statistics Means Continuous Continuous Correlation or Regression Nominal Nominal Nominal Continuous Frequencies or Proportions or Percentages Discriminant Analysis or Logistic Regression t (for t-test) F (for ANOVA (analysis of variance)) r (correlation coefficient) R2 Contingency or X2 (chi-square) Will not be covered Table 2. Types of variables, types of comparisons and test statistics commonly used for data analysis JMP steps 1. Analyze menu Fit Y by X 2. Click on your dependent variable - “trillium nearby?’ (which should have an N beside it) then on “Y, Response.” Click on the independent variable (which should have an N beside it), and then on “X, Factor”. Click OK. This is what you will see if you are a lucky person. 9 3. You will see a “Mosaic Plot,” which shows, for each independent variable, the percentage of total observations in each category of the Y axis. 4. Below the mosaic plot you will see a “Contingency table.” The upper left square in the table explains to you what each % of the table refers to (check with me to get a more complete explanation). 5. Below the contingency table are the test statistics. For our purposes there are three numbers which are relevant. 10 A. DF stands for degrees of freedom: In the “source” table you should note that the model DF = 1. Your instructor may elect to explain degrees of freedom to you. B. In the “Test” table, note that the Likelihood Ratio ChiSquare value =- 3.005, and the Prob>ChiSq = 0.083. OK, how might you go about reporting this? I would recommend something like the following: Eight out of 12 (66.67%) of the wingstem from the forested region had trillium nearby, while 3 out of 10 (30%) of the wingstem from the grassland had trillium nearby. These differences in frequency are not statistically significantly different (X2 = 3.005, df = 1, p = 0.083). CHI-Square (contingency table) analysis - the easy way The data table you made allowed you to test the hypothesis that there is a higher frequency of trillium near wingstem in forested regions than in grassland regions. The data lean in that direction, as follows: 66.67% of the wingstem had trillium nearby in the forested region 30% of the wingstem had trillium nearby in the grassland Please check the contingency table output to make sure you see where these percentages came from. Based on these data, your conclusion should be that the p value of 0.083 is not low enough to support your research hypothesis. I am also hoping that your conclusion will also be that you need more data to adequately test the hypothesis. Unfortunately for you, your instructor felt the same way, and sent you back out to collect more data. The new data look like this: Forested habitat Grassland habitat Trillium nearby? Yes no 21 41 37 18 One problem with your previous data table was that it was very cumbersome. You had to type in yes or no for each case, which was OK when it was 22 times, but would be a real drag when you had to do it for these data (58 yeses and 59 nos) Rejoice - there is an easy way. Just enter the table that looks like this: 11 Then do the following steps: 1. Analyze menu Fit Y by X 2. Click on your dependent variable - “trillium nearby?’ (which should have an N beside it) then on “Y, Response.” Click on the independent variable - habitat (which should have an N beside it), and then on “X, Factor”. Click on “how often”, which is your weighting variable, and click on “weight”. Click OK. The output will be exactly the same format as before, but the actual numbers will change as a result of your valiant data collection. You will get a graph that looks like this: and some data that look like this: 12 How would you report these findings. Do the results support or fail to support your hypothesis? Example IV. Analysis of Variance (ANOVA) Let’s go back to the case in which the dependent variable is continuous and the independent variable is nominal. Just to remind you, you could organize your understanding of the possible cases with the following, now famous, table 1. Dependent variable Continuous Independent variable Nominal Type of comparison Test statistics Means Continuous Continuous Correlation or Regression Nominal Nominal Nominal Continuous Frequencies or Proportions or Percentages Discriminant Analysis or Logistic Regression 13 t (for t-test) F (for ANOVA (analysis of variance)) r (correlation coefficient) R2 Contingency or X2 (chi-square) Will not be covered Table 1. Types of variables, types of comparisons and test statistics commonly used for data analysis You will notice that there are two possibilities: t-test and ANOVA. Which do you use? The answer is very simple. If you’re comparing the means for two categories, like when you compared the “wet weight” of wingstem in forested vs. the “wet weight” of wingstem in grassland habitats, then you use a t-test. When you are comparing the means for three or more categories, then you use an ANOVA. From what we know about mushrooms, we could propose the following: Hypothesis: Wetter and shadier habitats will tend to have a higher species richness of mushrooms than dryer sunnier habitats. Prediction: If the hypothesis is true, experimental quadrats in forests along the river will have the greatest mean number of species, while experimental quadrats in dry grasslands will have lowest mean species richness. Forest away from the river (deep forest) and grasslands along the river would have intermediate values. (The hypothesis does not make distinguishing predictions between the latter two categories.) Notice that we have four categories: Deep forest, river forest, dry grassland and river grassland. Here are the made-up data in a JMP table: 14 Table 2. Made-up data of number of different species of mushrooms collected from five 10 X 10 M quadrats in each of four habitats. Notice that I have a column called “replicate”. Each replicate (or replication) is a sample of the category. Because we set up five quadrats in each habitat, we have five replicates for each of the four habitats. I put the replicate numbers in the data table because it facilitates discussion. For example I could say “replicate 3 of river forest”, and you would know I’m referring to the quadrat with 12 different species of mushrooms. Numbering your replicates is very useful for complex data tables. But for simple data tables you probably don’t need to worry about it. OK. So we want to test our Prediction that experimental quadrats in river forest will have the greatest mean number of species, while experimental quadrats in dry grasslands will have lowest mean species richness. Deep forest and river grasslands will have intermediate values. Please do the following: 1. Open or create your data file 2. .Analyze menu Fit Y by X 3. Select “species richness” as your Y,response, and “habitat” as your X, factor. Click OK. 4. You will get a graph that shows the data points for each category. 15 Figure 1. Data points for each of four habitat categories. 5. Then click on the red triangle to the left of “oneway”, drag down to means/anova, and you should see a new window with a great deal of data on it. You will also that the graph has been redrawn, with the gray horizontal bar representing the mean number of species overall, the longer green horizontal bar representing the mean for each category, and the top and bottom of the diamond shape representing the 95% confidence intervals. Based on these samples we are 95% confident that the true mean for that category falls between the top tip and bottom tip of the diamond. We won’t worry about the meaning of the two shorter green horizontal bars for now. 16 Here are the essential data from this table: A. In the “Summary of Fit” table, the overall mean of response = 3.8. You won’t report that, but it’s nice to know. B. In the Analysis of Variance (ANOVA) table, you will note the DF (degrees of freedom) for habitat = 3, and DF for error = 16. The F-ratio is 11.90, and P = 0.0002. You would report that as follows: “F3,16 = 11.90, P = 0.0002.” 17 So what does this mean? Because the P-value is so low (much less than 0.05), we can support our hypothesis that species richness is significantly different for different habitats. C. In the “Means for Oneway Anova” table, you will see the means and standard errors reported for each category. Beware! Those standard errors are for the entire sample, not for the individual categories. To get the standard error for each category, click on the red triangle and drag to “Means and Std Dev.” You’ll get the following: These are the correct values for means, standard deviations, and standard errors. Your report should include (either in the text of the paper, in a figure, or in a table) the means for each category, and either the standard error of the mean, or the standard deviation. The frustrating thing is that while we now know that habitat influences mushroom species richness, we still don’t know which category is significantly different from which. In other words we still haven’t fully tested the predictions of our hypothesis. There’s only one more step. 6. Go back to that little red triangle, drag to “compare means”, then drag to all “pairs Tukey HSD”. You will get the box below: 18 The bottom portion of this output is of relevance. You will notice that “Levels not connected by same letter are significantly different.” (for our purpose levels = categories). For example the mean (7.6) for River forest has an A next to it. Thus its mean is significantly greater than the 2 categories that don’t have an A next to them (both grassland categories), but it isn’t significantly greater than Deep forest (which also has an A next to it). Similarly Deep forest’s mean is significantly greater than Dry grassland’s mean, but not River grassland (Because Deep forest and River grassland both share the letter B). So that’s how we will be comparing means in this class when there are more than two categories for a nominal independent variable. Notice that I used the term significantly greater rather than significantly different - if the means are different I want to know which is greater than which. Appendix - HYPOTHESIS TESTING We used a t-test to address the question of whether the mean “wet weight” of wingstem plants from grasslands is significantly greater than the mean “wet weight” of wingstem from forested regions. The t-test, and all of the statistics we have been discussing, allow you to ascribe a confidence value to the conclusions you will draw based on the analysis. In this case we are formally testing the hypothesis that wingstem from grasslands on average weigh more than wingstem from forested regions. We can (and should!) compare the means and say that the answer is “yes”, based on the sample we collected. But we’re still not sure whether the same conclusion can be drawn for the entire population of wingstem plants, in part because we haven’t weighed very many plants. Are we justified in concluding that there is truly a significant difference in ‘“wet weight”” based on our sample? If so, how comfortable do we feel about this conclusion? The answer to this question is that we will never be able to say for sure wingstem in grasslands weigh more on average than wingstem in forested regions unless we test the entire population. Fortunately for us, statisticians have developed techniques that allow us to make inferences from relatively small samples to much larger populations. The hypothesis we wish to test is called the research hypothesis (HA). In this case HA is that there truly is a difference in mean wingstem “wet weight” between the two habitats . To establish some credibility for the research hypothesis, we first define a null hypothesis (Ho) that directly opposes HA. In this case Ho is that in reality, there is no difference in mean wingstem “wet weight” weight between the two habitats. To support HA, we attempt to show that the sample provides evidence that Ho is unlikely. How unlikely? It is up to the researcher to decide how unlikely Ho must be before it can be rejected. This is known as the critical value (). The most common is .05. This means that if Ho is true, we would expect to see such a difference between the mean wingstem ““wet weight”s” in the two habitats in only one of every 20 samples. Do the data allow us to reject Ho? The t- test allows us to compute the probability of how often we would expect to have a difference as great as we observe for two habitats by chance 19 alone (i.e. if Ho were true). The calculation of the frequency with which we would expect to see such a difference if Ho is true is the p-value. If p =.01, we will expect to see the observed difference between the two groups (in other words between the ““wet weight”s” of wingstems in forest vs. grassland) due to chance alone, only one out of 100 times. That’s very unlikely, so as scientists, we can feel pretty good claiming that the Ho is probably wrong, and therefore that the HA is supported. In a formal sense, we can then compare the p-value to ; if p < as it is when p = .01), then we can reject the Ho. This provides support for HA, but does not prove it (recall we can prove our research hypothesis only by measuring the entire population). Also beware! If we cannot reject Ho, that does not mean that Ho is correct. It is possible that we would be able to reject Ho if we had a larger sample size. The key realization for you to make is that the higher the value of t, the lower your p-value. The lower your p-value, the more confident you are about rejecting Ho and supporting HA. In the case presented at the beginning of this handout, the p value = 0.0866. This is greater than our critical value of 0.05. Thus we are unable to reject H0, and fail to support the research hypothesis. However, it is still possible that in the natural world, wingstem on average have higher mean “wet weight” in grasslands than in forested regions. Our data are not sufficient to support this hypothesis. A big however is that we really were much too lazy and should have collected many more plants (in other words, our sample size was pretty pitiful). One wonderful aspect of this approach to hypothesis testing is that all of the tests you use will generate a p-value. The p-value will be interpreted in the same manner regardless of whether you are using a t-test, ANOVA, linear regression, or chi-square test. If p << 0.05, you have supported your research hypothesis If P >> 0.05, you have failed to support your research hypothesis. But if P is in the neighborhood of 0.05, you are in the uncomfortable zone, in that it is not clear whether you have support for your research hypothesis. The reality is that there really is nothing magical about a critical value of 0.05, so maybe we should say that between 0.04 and 0.08 we have some weak support for our research hypothesis. We’ll talk about this later in the year. 20