Statistics – used to describe characteristics of a large population
advertisement

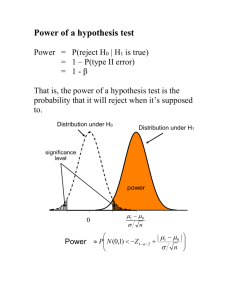
Biostatistics in Dentistry Instructor: Chuck Spiekerman Statistics – used to describe characteristics of a large population using small subset (sample). Example: U.S. presidential election poll CNN/ORC Poll. May 29-31, 2012. N=895 registered voters nationwide. Margin of error ± 3.5. "Suppose that the presidential election were being held today and you had to choose between Barack Obama as the Democratic Party's candidate, and Mitt Romney as the Republican Party's candidate. Who would you be more likely to vote for: Barack Obama, the Democrat, or Mitt Romney, the Republican?" 5/29-31/12 Barack Obama % 49 Mitt Romney % 46 Neither (vol.) % 4 Other (vol.) % 1 From www.pollingreport.com With careful random sampling, there’s a good chance that the %’s in the sample will be close to the %’s in the population of interest. But the “answers” we get are random (because of the random sampling). Each different sample is going to give a different answer. In Statistics we use what we know about the random sampling, and combine that with probability theory to make more precise statements about how accurate our sample statistics are in terms of describing the actual population parameters of interest. Biostatistics in Dentistry Biostatistics ≈ statistical methods for applications in medical/dental research Medical/Dental Research often involves human subjects, study of complex mechanisms. This leads to highly variable outcomes. Statistical methods are used in an attempt to separate the effects of interest from random “noise” in the data. Once understood, statistical methods give a good basis for understanding what can and what can’t be inferred from the data that are produced in medical/dental studies. Example: Chewing Gum Study Fourth grade students (ten year olds) recruited. Students assessed for DMFS at study entry. Students randomly assigned to various chewing-gum regimens: no gum, sucrose gum, xylitol gum, sorbitol gum or xylitol/sorbitol gum. Students assessed again for DMFS 2 years after study entry. We will focus on two groups, those randomized to gum “B” and to gum “C”. We wish to evaluate whether the two groups of children differ with respect to caries progression. Chewing Gum Data Group B id # 420 830 835 847 853 855 856 858 859 867 868 873 876 879 881 886 888 890 896 897 903 908 913 915 919 920 946 950 951 952 958 959 966 967 1,002 before 3 12 0 2 7 0 1 0 1 3 0 7 3 3 7 5 0 7 11 3 0 5 8 6 6 3 2 2 3 7 4 0 2 1 8 DMFS after 3 0 0 1 8 0 6 0 0 4 6 2 7 0 6 0 3 1 5 3 0 7 6 10 0 4 0 0 1 10 2 0 0 0 8 Group C change 0 -12 0 -1 1 0 5 0 -1 1 6 -5 4 -3 -1 -5 3 -6 -6 0 0 2 -2 4 -6 1 -2 -2 -2 3 -2 0 -2 -1 0 id # 331 335 336 340 342 344 345 346 348 352 353 354 355 356 364 366 374 380 385 389 392 396 401 402 403 404 405 408 415 416 417 422 423 428 430 434 455 456 457 460 before 2 8 0 0 0 1 0 3 5 1 1 8 5 1 2 5 6 5 0 3 0 0 2 8 7 0 3 3 5 12 4 6 16 2 7 4 7 0 4 1 DMFS after 8 9 1 0 0 1 5 2 5 2 6 10 6 8 2 8 11 19 2 2 0 3 1 15 18 1 8 4 8 15 12 0 18 7 5 10 8 0 12 0 change 6 1 1 0 0 0 5 -1 0 1 5 2 1 7 0 3 5 14 2 -1 0 3 -1 7 11 1 5 1 3 3 8 -6 2 5 -2 6 1 0 8 -1 We can get a better understanding of the data using histograms. Gum B Gum C -15 -10 -5 0 5 10 15 5 10 15 5 10 15 change in DMFS Gum B -15 -10 -5 0 Change in DMFS Gum C -15 -10 -5 0 Change in DMFS Is it obvious that the two gums have different effects? Another common method used to compare groups. Boxplot 20 18 change in DMFS 10 51 0 -10 42 -20 N= 35 40 B C gum type The lines inside the boxes are medians (50th percentiles) The top of boxes are the 75th percentiles The bottom of the boxes are the 25th percentiles The “whiskers” extend to the furthest observations within 1.5 interquartile ranges (distance between 25th and 75th percentiles) from the boxes The dots represent further outlying observations To objectively compare two sets of continuous data, we often focus on the sample means within the groups. change in DMFS N gum typ e Mean Std Dev iation B 35 -.8 3 3.5 7 C 40 2.6 3 3.8 0 The sample mean is the average of the values. It is a measure of the “center” of the data. sample mean (group B) = 0 12 ... 1 0 .83 35 The standard deviation is a measure of variability of the data; or, how spread out they are. The standard deviation can be loosely interpreted as the average distance of the observations from the sample mean. change in DMFS N gum typ e Mean Std Dev iation B 35 -.8 3 3.5 7 C 40 2.6 3 3.8 0 mean Gum B < 1 SD 1 SD > >< mean Gum C < -15 -10 -5 1 SD >< 0 1 SD 5 > 10 15 change in DMFS Non-standard graphical representation of means and standard deviations Summation Notation We will use summation notation often. n x i 1 i x1 x 2 x n Example: Suppose x1 = 5, x2 = -4, and x3 = 7, then 3 x i 1 i x1 x2 x3 5 4 7 8 . In summation notation, the sample mean, X , is written X n 1 n x i 1 i . The sample variance, s2, is written s 2 x n 1 n 1 i 1 i X 2 , 2 s s and the sample standard deviation is . Back to the Data: Which are we seeing? A. The two groups are systematically different. The difference is reflected in the observed mean changes in DMFS. -- or -B. The two groups are basically the same. The difference we observed in sample means is due to the random sampling. In Hypothesis Testing, we go about answering this question by assuming that the second of these alternatives is the truth. In this example we assume that option B is correct. We assume that the two gums are basically the same. Then we use probability theory to calculate how likely it would be for the sample means to be as different as observed in a trial where everybody was chewing the same gum. “Behavior” of the sample statistics We can predict what values are likely and unlikely to be seen when sampling one observation from the population using a very large sample to compute a histogram. With respect to sample statistics, like the sample mean, we usually only see one observation. Luckily, probability theory gives us the Central Limit Theorem, which basically says that averages (like the sample mean) all behave in a specific way. Knowing how the sample means should behave will let us make informed judgments on whether the observed statistics are more consistent with coming from o two different groups, or o the same group with two different labels Deciding whether there are really two different gum groups First, we assume/pretend that the two gums have equivalent effects on DMFS. Then, we use probability theory to estimate how likely different outcomes with respect to different mean DMFS would be. Probability distribution of possible differences in mean DMFS if gums are equivalent -4 -3 -2 -1 0 1 2 3 4 Mean difference of DMFS change Probability is represented by area under the curve. Finally, we look at the actual observed data and see whether they are consistent with our assumed distribution. Output from the statistical computer package SPSS Independent Samples Tes t t-test fo r Equality of Means t change in DMFS df Sig. (2-tailed) Mean Differen ce Std. Erro r Differen ce Equal variances assumed -4.04 73 .00 013 -3.45 .86 Equal variances not assumed -4.06 72.6 .00 013 -3.45 .85 The circled value is the p-value of the t-test for equality of means. The p-value is the estimate of the probability that a difference of –3.45 DMFS would be seen between groups if, in fact, the two gums were equivalent. Since the probability (.00013, about 1 in 8000) is very low, this leads us to doubt our initial assumption that the two groups could actually be equivalent. This is the basic procedure for a hypothesis test. Estimating the difference Using the sample means we estimated that one gum was associated with 3.45 less DMFS, on average. This estimate would differ depending on which 75 children we happened to pick. Our hypothesis test convinced us that the two gums were not the same; that is, the difference was not 0. We can use similar methodology find all other possible differences that our data would not contradict. A 95% confidence interval for the mean difference in DMFS between group B and group C is (1.75 to 5.16). This contains all possible true differences between groups that would have at least a 95% chance of producing our observed data. This class will concentrate mostly on - developing a “toolbox” of necessary probability and statistical theory (Days 1-4) - introducing methods of inference for various types of data o develop a useful statistic o figure out distribution of statistic (almost always related to Normal distribution) o use distribution to estimate precision of statistic and perform hypothesis tests