Statistical Inference & Normal Distribution
advertisement

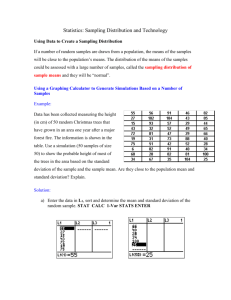
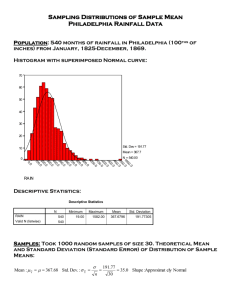
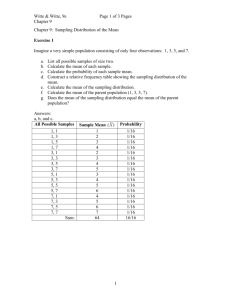
Need to know in order to do the normal dist problems • How to calculate Z • How to read a probability from the table, knowing Z **** how to convert table values to area that you need---you need to DRAW THE ND AND SHADE WHAT YOU NEED • How to go from a probability on the table to Z • How to convert Z to X Statistical Inference Samples & Populations Differs from the course so far Up till now, just “descriptive” statistics. Just reporting values that were directly measured or counted. Estimation Starting with some theory to set up a basis. We plan to use information from sample(s) to describe a population. Theory • Chapter 8, pp 196 – 198 and 204 - 208 Most Significant Parameters • Mean of the Population • Standard Deviation of the Population Sampling Distribution of the Mean • • • • Take many samples, each of size n Take the mean of each sample, X Take the mean of these means The mean of the sampling distribution of means follows a normal distribution If we … Take all possible samples of size n from a population The mean of the means of all samples equals the mean of the population And the Standard Deviation Of the population can be calculated from the distribution of sample means. Standard Deviation of the sampling distribution is called the standard error of the mean The dispersion of the sampling distribution is narrower than the values in the original population Dispersion of Means narrower than dispersion of values in the population For example • Serum cholesterol values for all 50-yr old men – the distribution would follow something like the low very dispersed ND shown in the previous slide. • Samples, 10 men in each – the distribution of the sample means would follow something like the high narrow ND. Standard Error of the Mean Compare it to the standard deviation of the population The standard deviation of the population is expressed as sigma, б The standard error = б / n Standard Error of the Mean • Its value depends on sigma of the population • And on n. The larger the sample, the smaller the value for S.E. • S.E. is written as sigma sub X bar. Too difficult for me to put in power pt. More about the Sampling Distribution of the Mean The mean of the sampling distribution of means follows a normal distribution. The basis for this is called The Central Limit Theorem Central Limit Theorem • Even if the values for the original population do not fit a normal curve, the distribution of the sample means does fit the normal distribution. • This is true if the size of the samples is large enough. • What is “large enough”? • N = 30 or larger. Each sample must have 30 or more observations. Is n ≥ 30 always necessary? • No • If the original population is itself a normal distribution, then the distribution of sample means will be normal even if the sample size is extremely small….even n = 1. The Original Population The distribution of sample means is a normal distribution even if • The values of the original population follow a skewed distribution • The values of the original population are discrete The Central Limit Theorem • How does the sampling distribution compare to the original population. • If we take ALL SAMPLES OF SIZE N FROM THE POPULATION • Mathematically, the mean of the population equals the mean of the sampling distribution of means. • Standard deviation of the distribution of means, “standard error of the mean” = sigma/ square root of n. But… • We are NOT going to be taking all possible samples • So…. • We use the mean of a sample as the best estimate we have of the mean of the population, And… We may be given the standard deviation of the population or We take the standard deviation of a sample as the best estimate of the standard deviation of the population, б. Estimating the Mean • The best estimate that we can get is the mean of the sample • But that isn’t good enough • It’s called a point estimate • And we have no idea of its probability of being the true mean Instead • We look for a range within which we can expect to find the true mean • We will also be able to express the probability that the mean is really within this range. An example • If we find the mean of a sample of insulin levels is 100 units • The true mean might be 101, 98, 101.2 or any number of values • But if we use a normal distribution, we can calculate a range for the mean, e.g. 95 – 105 and say that there is a 99% probability that the true mean falls within this range. (This example is only concocted numbers. Don’t try to confirm them.) The range and the probability are called Confidence Intervals Estimating the Mean • We are now using Chapter 9 Getting the Range & the Probability • Use the Normal Distribution • Use Z and the area under the ND curve Z (X μ) σ/ n Previously we used Z (X μσ Compare with Previous Examples • We did the normal distribution of values, X, around the mean of a population • The spread is the standard deviation of the population. • Here we are looking at the normal distribution of sample means, X, around the mean of the means.. • The spread is the standard error of the mean Values of Area and Z • These are the same as in any other standard normal distribution • e.g. 95% of the cases fall within 2 standard deviations of the mean Note: 2 standard deviations on both sides of the mean Approximation We used 2 standard deviations but when we looked in Table A.3, we found that 95% of the cases are actually within Z = 1.96, not 2.00 Let’s check it out. Look at 1.96, what is the area? Convert it to the two sides of the mean Table A.3 • Gives us the area under the “tail”. • Subtract that area from 0.5000 • Multiply it by two. • For Z = 1.96, A(under the tail) = 0.025 • 0.5000 – 0.025 = 0.475 • Times two = 0.950 that is, 95% Example • We are interested in finding the average level of enzyme, cut-em-up, in a population, e.g. patients in Pro-health Group Practice. • A sample of 10 patients has an average level of 22 units. • It is known from other information that the level of this enzyme is approximately normally distributed with a variance of 45. Find 95% Confidence Interval for To find 95% C.I., use Z = 1.96 Z (X μ) σ/ n Rearrange the equation to solve for Z * σ/ n X μ Form of Equation to use for Confidence Intervals Z * σ/ n X μ μ X Z * σ/ n But this would give us a point estimate of mu, so have to change this a little more. Just look at the part after the equal sign Mu is between the two values calculated by: X Z * σ/ n X Z * σ/ n Always draw the N.D. The shaded area can help us to see what we mean by X Z * σ/ n It is the border of the shaded area to the right of the mean . We are saying that the mean lies between that border and the corresponding left-side border Write the equation X Z * σ/ n μ X Z * σ/ n Mu lies between the two values within the parentheses Practical Statement of Result • With 95% confidence, we can say that u will be ≤ 1.96 *S.E. and • ≥ -1.96 * S.E. • We call 1.96 the reliability coefficient The Math • • • • • • • X = 22, n = 10, б2 = 45 Review what the symbols mean? Find the quantity Z * б / Γn б = Γ45 = 6.7 б / Γn = 6.7/ Γ10 = 6.7 / 3.16 = 2.12 1.96 * 2.12 = 4.16 Mu is between 22 – 4.16 and 22 + 4.16 • 17.84 ≤ µ ≤ 26.16 with 95% confidence Another Example • Page 230, #13 • • • • • Take out diskette from back of book Insert into computer Click on Install Check ASCII, excel, SPSS Install to hard drive Excel • • • • Go to “exercise” Find “lowbwt” Save to hard drive to work on File will probably be gone next time you return. Save the data set we want onto your own floppy Do Problem 13, just the males Separate male & female, how? Important Statements in the Problem 1. Large sample Applications • If we know a population mean & st. dev., we can calculate the probability that any sample will have a stated mean. • A certain large human pop’n has a cranial length that is approx’ly normally distributed with mean 185.6 mm and б of 12.7 mm. µ = 185.6 mm б = 12.7 mm • What is the probability that a random sample of size 10 from this population will have a mean greater than 190? • We can calculate this probability but why would we? Usefulness?? • Let’s say that it is accepted knowledge that the population has a certain mean. • I am working with a group of people. • I want to know if they fit into this population with regard to the particular parameter. If the probability of the mean of the sample is very low, perhaps it is not really from the same population Education Example • Third-graders in the U.S. have an average reading score of 124. • Third-graders in a particular school have a mean reading score of 120. What’s the probability that they are from the same population? Back to Cranial Length • µ = 185.6 mm б = 12.7 mm • random sample of size 10 from this population will have a mean greater than 190? • Have to find how far 190 is from 185.6 in units of standard error of the mean Z (190 185.6) 12.7/ 10 Probability of Mean of 190 Did you draw a normal dist??? Z = 4.4 / 12.7 / 3.16 Z = 1.09 0.138 Area = 0.138 185.6 190 The probability is 13.8% 0 1.09 The mean & st. dev. of serum iron values are 120 & 15 micrograms per 100 ml. What is the probability that a random sample of 50 normal men will yield a mean between 115 & 125 µg/100ml? µ = 120 б = 15 Z1 = (115-120) / 15 / sqrt of 50 Z2 = (125-120) / 15 / sqrt of 50 Z1 = (115-120) / 15 / sqrt of 50 Z2 = (125-120) / 15 / sqrt of 50 Draw the Normal Distribution