File - Nellie`s E
advertisement

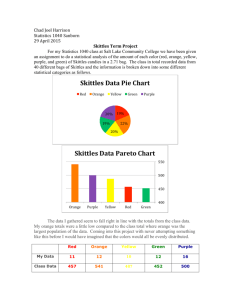
Math 1040 • Intro To Statistics • Professor: Zeph Allen Smith • Presented by: Nellie Sobhanian Introduction: • For this class, Math 1040, our term project consists of buying a bag of skittles and counting the number of skittles based on its color. Our class was to report these numbers for the instructor, who created a collective data that represents each respondent’s numbers. There are 38 respondents, or students in this class. The cumulative number of skittles came out to 2435. The colors represented a categorical data (colors) which corresponds to a quantitative data, or the number of skittles in each color. The entire data consisted of Red(500), Orange(446), Yellow(474), Green(503) and Purple (512). Next chart, is a pie chart and a Pareto chart that represents the collected data. Skittles Pie Chart Pareto Chart Name Value Relative frequency Cumulative frequency Purple Skittles 512 21.03 21.03 Green Skittles 503 20.66 41.68 Red Skittles 500 20.53 62.22 Yellow Skittles 474 19.47 81.68 Orange Skittles 446 18.32 100 SUM 2435 • By observing the pie chart versus each of the colors of the Pareto graph, it becomes evident that the pie chart is easier to get a holistic view of the data, at a glance. The Pareto chart, however, helps to get a more detailed look of the data, in an individual manner. The frequency represents the number of respondents who have had the same number of skittles. Summery of My bag of skittles • The table below, represents the numbers of skittles on my own personal bag, which can be used for compare and contrast purposes. Purple Skittles: 13 Red: 12 Orange:13 Green: 13 Yellow: 10 Total: 61 Skittles Summary Statistics Column Mean Std. dev. Median Min Max Q1 Q3 IQR Sum Red 84.707317 383.86015 13 0 2435 10 16 6 3473 Orange 22.871795 69.67752 11 3 446 9 14 5 892 Yellow 24.307692 74.049825 12 3 474 10 14 4 948 Purple 26.25641 79.903467 14 4 512 11 16 5 1024 Green 25.794872 78.50115 13 7 503 11 16 5 1006 Histogram Charts Box plot Recap • As presented above, each different chart has their unique way of portraying the same set of information. Some are easier to distinguish than others, but the sophisticated style of each chart allows for comparing and contrasting to figure out what chart ultimately works the best with the data. The box plot shows that the number of red skittles exceeds the number of any other skittles, and the numbers of other colors of skittles are approximately equal; the histogram verifies this observation. I only bought one bag of skittles, therefore the 38 other bags of skittles, one per respondent, provides for a better sample. Reflection • As previously explained in the introduction paragraph, categorical or qualitative data is measured based on characteristics of the data, such as color, name brand, taste, etc. as opposed to quantitative data which is basically anything that can be measured such as number, weight, distance, etc. The most helpful graph to measure qualitative data was the pie chart because it provides a visual of how one color such as red, is appears more frequently than other colors. The Pareto chart was the most helpful with quantitative data; it provided the number of frequency, the number of skittles in descending order, which in my opinion, is the best chart that provides the most quantitative information out of the other charts that are presented here. Confidence Interval Estimates • Confidence interval is essentially an estimated range of values which is likely to include an unknown population parameter or the estimated range being calculated from a given set of sample data. • Construct a 99% confidence interval estimate for the true proportion of yellow candies: using the confidence interval formula (see scanned sheet for work shown) the proportions of yellow candies were .179 < p <.221 thus they are between 18 and 22. (See Scanned sheet for work shown p.1) • Construct a 95% confidence interval estimate for the true mean number of candies per bag: I calculated the sample mean which is 64, and the standard deviation which is 13.2 of the 38 bags of skittles. The sample size is the grand total of the skittles which is 2435. I plugged in the numbers into the formula which calculated the true mean number of candies per bag to be between 60 (rounded up from 59.7) to 68. (See scanned sheet for work shown p.2) • .Construct a 98% confidence interval estimate for the standard deviation of the number of candies per bag: By using the estimating population parameter, specifically the standard deviation aspect, of 61, I plugged in the square root of 37, multiplying by the square root of the standard deviation (13.2) squared and dividing it by x2R which the calculator provided me with 49.588. The same process was used to figure out the left side. The answer resulted in 11.40 < α < 21.26. (See Scanned Sheet for work shown p.3) Hypothesis Test • A statistical hypothesis is an assumption about a population parameter. This assumption may or may not be true. Hypothesis testing refers to the formal procedures used by statisticians to accept or reject statistical hypotheses. • Use a 0.05 significance level to test the claim that 20% of all Skittles candies are red: Using the hypothesis proportion formula (see scanned sheet for work shown), We fail reject the null hypothesis because there is not sufficient evidence to support the alternative hypothesis. (See scanned sheet below p.1 for work shown) • Use a 0.01 significance level to test the claim that the mean number of candies in a bag of Skittles is 55. After using the hypothesis mean formula (see scanned work) We reject H0 if the t is less than or equal to -2.715 or if t is greater than or equal to 2.715. Comparing t (4.25) to 2.715 results in rejection of the null hypothesis due to enough evidence to support the alternative hypothesis. (See scanned sheet below p.2 for work shown) Recap • In order to construct the confidence interval and the hypothesis test, I used the holistic data of the entire class into the appropriate formula. My own sample of skittles met the 20% red skittle hypothesis test in a bag. However, the mean of my sample was 12 due to a smaller sample proportion. Some errors could have been caused due to outliers; there were 3 numbers that were unusually high. What could have been improved was to compare our data with other statistics classes to obtain a better sampling. Reflection What have I learned as a result of this project? • Discuss how the math skills that you applied in this project. • Identify specific parts of the project and your own process in completing the project that may have applications for other classes. • Discuss how the project helped to develop your problem solving skills. • Discuss how this project changed the way you think about real world math applications. If your thinking was not changed, then discuss how the project supported your views • Find examples that are applicable to your chosen field of study. Thank you! Fall Semester 2014