hpc_at_sheffield2013.. - The University of Sheffield High

Getting Started with HPC
On Iceberg
Michael Griffiths and Deniz Savas
Corporate Information and Computing Services
The University of Sheffield www.sheffield.ac.uk/wrgrid
Outline
• Review of hardware and software
• Accessing
• Managing Jobs
• Building Applications
• Resources
• Getting Help
Types of Grids
•Cluster Grid
•Computing clusters ( e.g.
iceberg )
•Enterprise Grid, Campus Grid,
Intra-Grid
•Departmental clusters, servers and PC network
•Cloud, Utility Grid
•Access resources over internet on demand
•Global Grid, Inter-grid
•White Rose Grid, National Grid Service,
Particle Physics Data Grid
Iceberg Cluster
There are two head-nodes for the iceberg cluster login
HEAD
NODE1
Iceberg(1) qsh,qsub,qrsh
Worker node
Worker node
Worker node
There are 232 worker machines in the cluster
HEAD
NODE2
Iceberg(2) qsh,qsub,qrsh
Worker node
Worker node
All workers share the same user filestore
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
iceberg cluster specifications
AMD-based nodes containing;
•
96 nodes each with 4 cores and 16 GB of memory
•
31 nodes each with 8 cores and 32 GB of memory
•
TOTAL AMD CORES = 632, TOTAL MEMORY = 2528 GB
The 8-core nodes are connected to each other via 16 GBits/sec infiniband for MPI jobs
The 4-core nodes are connected via the much slower "1 Gbits/sec" ethernet connections for MPI jobs. Scratch space on each node is 400 GBytes
Intel Westmere based nodes all infiniband connected, containing;
•
103 nodes each with 12 cores and 24 GB of memory ( i.e. 2 * 6-core Intel X5650 )
•
4 nodes each with 12 cores and 48 GB of memory
•
8 Nvidia Tesla Fermi M2070s GPU units for GPU programming
•
TOTAL INTEL CPU CORES = 1152 , TOTAL MEMORY = 2400 GB
Scratch space on each node is 400 GB
Total GPU memory = 48 GB
Each GPU unit is capable of about 1TFlop of single precision floating point performance, or 0.5TFlops at double precision. Hence yielding maximum GPU processing power of upto
8 TFlops in total.
Getting an account
All staff and research students are entitled to use iceberg
For Registration See: http://www.shef.ac.uk/wrgrid/register
Staff can have an account by simply emailing ucards-reg@sheffield.ac.uk
Access iceberg
Remote logging in
Terminal access is described at: http://www.shef.ac.uk/wrgrid/using/access
Recommended access is via any browser at: www.shef.ac.uk/wrgrid
This uses Sun Global Desktop ( All platforms, Graphics-capable )
Also possible:
•
Using an X-Windows client ( MS Windows, Graphics-capable )
▬ Exceed 3D
▬ Cygwin
•
Various ssh clients (MS Windows, Terminal-only )
▬ putty, SSH
Note: ssh clients can also be used in combination with Exceed or Cygwin to enable graphics capability. Above web page describes how this can be achieved.
Access iceberg from MAC or Linux platforms
•
The web browser method of access ( as for Windows platforms) also works on these platforms.
•
More customary and efficient method of access is by using the ssh command from a command-shell.
Example: ssh –X iceberg_username@iceberg.shef.ac.uk
Note1: -X parameter is needed to make sure that you can use the graphics or gui capabilities of the software on iceberg.
Note2: Depending on the configuration of your workstation you may also have to issue the command : xhost + before the ssh command.
Web browser method of access: Sun Global Desktop
Start session on headnode
Start an interactive session on a worker
Start Application on a Worker
Help
Transferring files to/from iceberg
Summary of file transfer methods as well as links to downloadable tools for file transfers to iceberg are published at: http://www.sheffield.ac.uk/wrgrid/using/access
• Command line tools such as scp , sftp and gftp are available on most platforms.
• Can not use ftp ( non-secure ) to iceberg.
• Graphical tools that transfer files by dragging and dropping files between windows are available winscp, coreftp, filezilla, cyberduck
Pitfalls when transferring files
• ftp is not allowed to by iceberg. Only sftp is accepted.
•
Do not use spaces ‘ ’ in filenames. Linux do not like it.
•
Secure file transfer programs ‘sftp’ classify all files to be transferred as either ASCII_TEXT or BINARY.
•
All SFTP clients attempt to detect the type of a file automatically before a transfer starts but also provide advanced options to manually declare the type of the file to be transferred.
•
Wrong classification can cause problems particularly when transfers take place between different operating systems such as between Linux and Windows.
•
If you are transferring ASCII_TEXT files to/from windows/Linux, to check that transfers worked correctly while on iceberg, type; cat –v journal_file
If you see a ^M at the end of each line you are in trouble !!!
CURE: dos2unix wrong _file on iceberg
Working with files
To copy a file: cp my_file my_new_file
To move ( or rename ) a file : mv my_file my_new_file
To delete a file : rm my_file
To list the contents of a file : less file_name
To make a new directory( i.e. folder) : mkdir new_directory
To copy a file into another directory: cp my_file other_directory
To move a file into another directory: mv my_file other_directory
To copy a directory to another location: cp –R directory other_directory
To remove a directory and all its contents!!!: rm –R directory
( use with care )
Wildcards : * means matching any sequence of characters.
For example: cp *.dat my_directory
•
Your filestore
Three areas of filestore always available on iceberg
•
These areas are available from all headnode and worker nodes.
1.
home directory:
•
/home/username
•
5 GBytes allocations
•
Permanent, secure, backed up area ( deleted files can be recovered )
2.
3.
data directory
•
/data/username
•
50 GBytes of ollocation
•
Not backed but mirrored on another server
/fastdata area
•
/fastdata
•
Much faster access from MPI jobs
•
No storage limits but no backup, or mirroring
•
Files older than 90 days gets deleted automatically
•
Always make a directory under /fastdata and work there.
Scratch area ( only available during a job)
•
Located at /scratch
•
Used as temporary data storage on the current compute node alone.
•
File I/O to /scratch is faster than to NFS mounted /home and /data areas
•
File I/O to small files is faster than to /fastdata but … for large files /fastdata is faster than /scratch
•
Data not visible to other worker nodes and expected to exist only during the duration of the job.
HOW TO USE SCRATCH:
•
Create a directory using your username under /scratch on a worker and work from that directory
Example: mkdir /scratch/$USER cp mydata /scratch/$USER cd /scratch/$USER
( then run your program )
Storage allocations
• Storage allocations for each area are as follows:
– On /home 5 GBytes
– On /data 50 GBytes
– No limits on /fastdata
• Check your usage and allocation often to avoid exceeding the quota by typing quota
• If you exceed your quota, you get frozen and the only way out of it is by reducing your filestorage usage by deleting unwanted files via the RM command ( note this is in CAPITALS ).
• Requesting more storage:
Email iceberg-admins@sheffield.ac.uk
to request for more storage.
• Excepting the /scratch areas on worker nodes, the view of the filestore is the same on every worker.
Running tasks on iceberg
•
Two iceberg headnodes are gateways to the cluster of worker nodes.
•
Headnodes ’ main purpose is to allow access to the worker nodes but NOT to run cpu intensive programs.
•
All cpu intensive computations must be performed on the worker nodes. This is achieved by;
▬ qsh command for interactive jobs and
▬ qsub command for batch jobs.
•
Once you log into iceberg, taking advantage of the power of a worker-node for interactive work is done simply by typing qsh and working in the new shell window that is opened. The next set of slides assume that you are already working on one of the worker nodes (qsh session).
Where on the cluster ?
•
Most of the application packages, compilers and software libraries are only available on the worker_nodes .
•
Iceberg headnodes are suitable for only light-weight jobs such as editing files.
•
If you are on one of the headnodes, you will need to type qsh to get an interactive session to the worker nodes.
•
How do you know where you are ?
The command prompt will contain your userid@hostname
Example: ch1abc@node-056 $
▬ If you are on one of the headnodes, hostname will be iceberg1 or iceberg2
▬
▬
If you are on an amd-based worker-node, it will be amd-nodenn where nn is the number of the amd-node.
If you are on an intel-based worker-node it will be node-nnn where nnn is the number of the intel node .
You can always type echo $HOSTNAME to find out the name of the machine you are currently using.
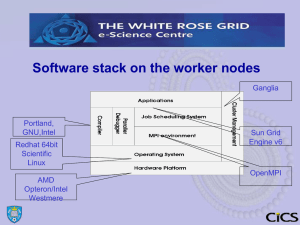
Software stack on the worker nodes
Ganglia
Portland,
GNU,Intel
Redhat 64bit
Scientific
Linux
AMD
Opteron/Intel
Westmere
Sun Grid
Engine v6
OpenMPI
Operating system and utilities
•
Linux Operating System version is-
Scientific Linux, which is RedHat Enterprise 5 based
•
Default Shell isbash
•
Available editors-
Graphical Editors:
▬ gedit ( not available on headnode)
▬ emacs
▬ nedit
Text editors:
▬ vi
▬ pico ( not available on headnode)
▬ nano
Login Environment
• Default shell is bash ( you can request to change your default shell ).
• On login into iceberg many environment variables are setup automatically to provide a consistent interface and access to software.
• Each user has a .bashrc
file in their directory to help setup the user environment.
• Type set to get a list of all the environment variables.
• Change all variables that are in CAPITALS with extreme care.
• Modify/enhance your environment by adding commands to the end of your .bashrc
file , such as alias commands. (Again do this with care! )
Application packages
•
Following application packages are available on the worker nodes via the name of the package.
▬
▬
▬
▬
▬
▬
▬
▬
▬
▬
▬
▬ maple , xmaple matlab
R abaquscae abaqus ansys fluent fidap dyna idl comsol paraview
Keeping up-to-date with application packages
From time to time the application packages get updated. When this happens;
– news articles inform us of the changes via iceberg news. To read the news- type news on iceberg or check the URL: http://www.wrgrid.group.shef.ac.uk/icebergdocs/news.dat
– The previous versions or the new test versions of software are normally accessed via the version number. For example; abaqus69 , nagexample23 , matlab2011a
Running application packages in batch queues
icberg have locally provided commands for running some of the popular applications in batch mode.
These are; runfluent , runansys , runmatlab , runabaqus
To find out more just type the name of the command on its own while on iceberg.
Setting up your software development environment
•
Excepting the scratch areas on worker nodes, the view of the filestore is identical on every worker.
•
You can setup your software environment for each job by means of the module commands.
•
All the available software environments can be listed by using the module avail command.
•
Having discovered what software is available on iceberg, you can then select the ones you wish to use by usingmodule add or module load commands
•
You can load as many non-clashing modules as you need by consecutive module add commands.
•
You can use the module list command to check the list of currently loaded modules.
Software development environment
• Compilers
– PGI compilers
– Intel Compilers
– GNU compilers
• Libraries
– NAG Fortran libraries ( MK22 , MK23 )
– NAG C libraries ( MK 8 )
• Parallel programming related
– OpenMP
– MPI ( OpenMPI , mpich2 , mvapich )
Managing Your Jobs
Sun Grid Engine Overview
SGE is the resource management system, job scheduling and batch control system.
Platform LSF )
(
Others available such as PBS, Torque/Maui,
• Starts up interactive jobs on available workers
• Schedules all batch orientated ‘i.e. non-interactive’ jobs
• Attempts to create a fair-share environment
• Optimizes resource utilization
SGE worker node
SGE worker node
SGE worker node
SGE worker node
SGE worker node
SGE MASTER node
Queue-A Queue-B Queue-C
JOB X
JOB U
JOB Y
JOB N
JOB Z
JOB O
Job scheduling on the cluster
Queues
Policies
Priorities
Share/Tickets
Resources
Users/Projects
Submitting your job
There are two SGE commands submitting jobs;
– qsh or qrsh : To start an interactive job
– qsub : To submit a batch job
There are also a list of home produced commands for submitting some of the popular applications to the batch system. They all make use of the qsub command.
These are; runfluent , runansys , runmatlab , runabaqus
Managing Jobs monitoring and controlling your jobs
• There are a number of commands for querying and modifying the status of a job running or waiting to run. These are;
– qstat or Qstat (query job status)
– qdel (delete a job)
– qmon ( a GUI interface for SGE )
Running Jobs
Example: Submitting a serial batch job
Use editor to create a job script in a file (e.g. example.sh):
#!/bin/bash
# Scalar benchmark echo ‘This code is running on’ `hostname` date
./linpack
Submit the job: qsub example.sh
Running Jobs qsub and qsh options
-l h_rt=hh:mm:ss The wall clock time. This parameter must be specified, failure to include this parameter will result in the error message:
“Error: no suitable queues”.
Current default is 8 hours .
-l arch=intel*
-l arch=amd*
-l mem=memory
Force SGE to select either Intel or AMD architecture nodes. need to use this parameter unless the code has processor dependency .
sets the virtual-memory limit e.g.
–l mem=10G
(for parallel jobs this is per processor and not total).
Current default if not specified is 6 GB .
No
-l rmem=memory Sets the limit of real-memory required
Current default is 2 GB.
Note: rmem parameter must always be less than mem .
-help Prints a list of options
-pe ompigige np
-pe openmpi-ib np
-pe openmp np
Specifies the parallel environment to be used. np is the number of processors required for the parallel job.
-N jobname
-o output_file
-j y
-m [bea]
-M email-address
Running Jobs qsub and qsh options ( continued)
By default a job
’s name is constructed from the job-script-filename and the job-id that is allocated to the job by SGE.
This options defines the jobname. Make sure it is unique because
the job output files are constructed from the jobname.
Output is directed to a named file. Make sure not to overwrite important files by accident.
Join the standard output and standard error output streams recommended
Sends emails about the progress of the job to the specified email address. If used, both
–m and –M must be specified. Select any or all of the b,e and a to imply emailing when the job begins , ends or aborts .
Runs a job using the specified projects allocation of resources. -P project_name
-S shell
-V
Use the specified shell to interpret the script rather than the default bash shell. Use with care.
A better option is to specify the shell in the first line of the job script. E.g. #!/bin/bash
Export all environment variables currently in effect to the job.
Running Jobs batch job example
qsub example: qsub –l h_rt=10:00:00 –o myoutputfile –j y myjob
OR alternatively … the first few lines of the submit script myjob contains -
$!/bin/bash
$# -l h_rt=10:00:00
$# -o myoutputfile
$# -j y and you simply type; qsub myjob
Running Jobs
Interactive jobs
qsh , qrsh
• These two commands, find a free worker-node and start an interactive session for you on that worker-node.
• This ensures good response as the worker node will be dedicated to your job.
• The only difference between qsh and qrsh is that ; qsh starts a session in a new command window where as qrsh uses the existing window.
Therefore, if your terminal connection does not support graphics ( i.e. XWindows) than qrsh will continue to work where as qsh will fail to start.
Running Jobs
A note on interactive jobs
•
Software that requires intensive computing should be run on the worker nodes and not the head node.
•
You should run compute intensive interactive jobs on the worker nodes by using the qsh or qrsh command.
•
Maximum ( and also default) time limit for interactive jobs is 8 hours.
Managing Jobs
Monitoring your jobs by qstat or Qstat
Most of the time you will be interested only in the progress of your own jobs thro
’ the system.
•
Qstat command gives a list of all your jobs ‘interactive & batch’ that are known to the job scheduler. As you are in direct control of your interactive jobs, this command is useful mainly to find out about your batch jobs ( i.e. qsub ’ed jobs).
• qstat command ‘note lower-case q’ gives a list of all the executing and waiting jobs by everyone.
•
Having obtained the job-id of your job by using Qstat, you can get further information about a particular job by typing ; qstat –f -j job_id
You may find that the information produced by this command is far more than you care for, in that case the following command can be used to find out about memory usage for example; qstat –f -job_id | grep usage
Managing Jobs qstat example output
State can be: r=running , qw=waiting in the queue, E=error state. t=transfering’just before starting to run’ h=hold waiting for other jobs to finish. job-ID prior name user state submit/start at queue slots ja-task-ID
-------------------------------------------------------------------------------------------------------------------------------------------------
206951 0.51000 INTERACTIV bo1mrl r 07/05/2005 09:30:20 bigmem.q@comp58.iceberg.shef.a 1
206933 0.51000 do_batch4 pc1mdh r 07/04/2005 16:28:20 long.q@comp04.iceberg.shef.ac. 1
206700 0.51000 l100-100.m mb1nam r 07/04/2005 13:30:14 long.q@comp05.iceberg.shef.ac. 1
206698 0.51000 l50-100.ma mb1nam r 07/04/2005 13:29:44 long.q@comp12.iceberg.shef.ac. 1
206697 0.51000 l24-200.ma mb1nam r 07/04/2005 13:29:29 long.q@comp17.iceberg.shef.ac. 1
206943 0.51000 do_batch1 pc1mdh r 07/04/2005 17:49:45 long.q@comp20.iceberg.shef.ac. 1
206701 0.51000 l100-200.m mb1nam r 07/04/2005 13:30:44 long.q@comp22.iceberg.shef.ac. 1
206705 0.51000 l100-100sp mb1nam r 07/04/2005 13:42:07 long.q@comp28.iceberg.shef.ac. 1
206699 0.51000 l50-200.ma mb1nam r 07/04/2005 13:29:59 long.q@comp30.iceberg.shef.ac. 1
206632 0.56764 job_optim2 mep02wsw r 07/03/2005 22:55:30 parallel.q@comp43.iceberg.shef 18
206600 0.61000 mrbayes.sh bo1nsh qw 07/02/2005 11:22:19 parallel.q@comp51.iceberg.shef 24
206911 0.51918 fluent cpp02cg qw 07/04/2005 14:19:06 parallel.q@comp52.iceberg.shef 4
Managing Jobs
Deleting/cancelling jobs
qdel command can be used to cancel running jobs or remove from the queue the waiting jobs.
• To cancel an individual Job; qdel job_id
Example: qdel 123456
• To cancel a list of jobs qdel job_id1 , job_id2 , so on …
• To cancel all jobs belonging to a given username qdel –u username
Managing Jobs
Job output files
•
When a job is queued it is allocated a jobid ( an integer ).
•
Once the job starts to run normal output is sent to the output (.o) file and the error o/p is sent to the error (.e) file.
▬ The default output file name is: <script>.o<jobid>
▬ The default error o/p filename is: <script>.e<jobid>
•
If -N parameter to qsub is specified the respective output files become <name>.o<jobid> and <name>.e<jobid>
•
–o or –e parameters can be used to define the output files to use.
•
-j y parameter forces the job to send both error and normal output into the same (output) file (RECOMMENDED )
Monitoring the job output files
• The following is an example of submitting a SGE job and checking the output produced qsub myjob.sh
job <123456> submitted qstat –f –j 123456 (is the job running ?)
When the job starts to run, type ; tail –f myjob.sh.o123456
Managing Jobs
Reasons for job failures
– SGE cannot find the binary file specified in the job script
– You ran out of file storage. It is possible to exceed your filestore allocation limits during a job that is producing large output files. Use the quota command to check this.
– Required input files are missing from the startup directory
– Environment variable is not set correctly
(LM_LICENSE_FILE etc)
– Hardware failure (eg. mpi ch_p4 or ch_gm errors)
Finding out the memory requirements of a job
•
Virtual Memory Limits:
▬ Default virtual memory limits for each job is 6 GBytes
▬ Jobs will be killed if virtual memory used by the job exceeds the amount requested via the –l mem= parameter.
•
Real Memory Limits:
▬
▬
Default real memory allocation is 2 GBytes
Real memory resource can be requested by using –l rmem=
▬
▬
Jobs exceeding the real memory allocation will not be deleted but will run with reduced efficiency and the user will be emailed about the memory deficiency.
When you get warnings of that kind, increase the real memory allocation for your job by using the –l rmem= parameter.
▬ rmem must always be less than mem
Determining the virtual memory requirements for a job;
▬ qstat
–f –j jobid | grep mem
▬
▬
The reported figures will indicate
- the currently used memory ( vmem )
- Maximum memory needed since startup ( maxvmem)
- cumulative memory_usage*seconds ( mem )
When you run the job next you need to use the reported value of vmem to specify the memory requirement
Managing Jobs
Running arrays of jobs
• Add the –t parameter to the qsub command or script file (with #$ at beginning of the line)
– Example: –t 1-10
• This will create 10 tasks from one job
• Each task will have its environment variable
$SGE_TASK_ID set to a single unique value ranging from 1 to 10.
• There is no guarantee that task number m will start before task number n , where m<n .
Managing Jobs
Running cpu-parallel jobs
•
Parallel environment needed for a job can be specified by the:
-pe <env> nn parameter of qsub command, where <env> is..
▬ openmp : These are shared memory OpenMP jobs and therefore must run on a single node using its multiple processors.
▬ ompigige : OpenMPI library- Gigabit Ethernet. These are MPI jobs running on multiple hosts using the ethernet fabric ( 1Gbit/sec)
▬ openmpi-ib : OpenMPI library-Infiniband. These are MPI jobs running on multiple hosts using the Infiniband Connection (
32GBits/sec )
▬ mvapich2-ib : Mvapich-library-Infiniband. As above but using the
MVAPICH MPI library.
•
Compilers that support MPI.
▬ PGI
▬
▬
Intel
GNU
Setting up the parallel environment in the job script.
• Having selected the parallel environment to use via the qsub – pe parameter, the job script can define a corresponding environment/compiler combination to be used for MPI tasks.
• MODULE commands help setup the correct compiler and MPI transport environment combination needed.
List of currently available MPI modules are; mpi/pgi/openmpi mpi/pgi/mvapich2 mpi/intel/openmpi mpi/intel/mvapich2 mpi/gcc/openmpi mpi/gcc/mvapich2
• For GPU programming with CUDA libs/cuda
• Example: module load mpi/pgi/openmpi
Summary of module load parameters for parallel
MPI environments
-pe mvapich2-ib TRANSPORT qsub parameter
-------------------------
COMPILER to use
-pe openmpi-ib
-pe ompigige
PGI mpi/pgi/openmpi mpi/pgi/mvapich2
Intel
GNU mpi/intel/openmpi mpi/intel/mvapich2 mpi/gcc/openmpi mpi/gcc/mvapich2
Running GPU parallel jobs
GPU parallel processing is supported on 8 Nvidia Tesla Fermi
M2070s GPU units attached to iceberg.
• In order to use the GPU hardware you will need to join the
GPU project by emailing iceberg-admins@sheffield.ac.uk
• You can then submit jobs that use the GPU facilities by using the following three parameters to the qsub command;
P gpu
-l arch=intel*
-l gpu=nn where 1<= nn <= 8 is the number of gpu-modules to be used by the job.
P stands for project that you belong to. See next slide.
Special projects and resource management
•
Bulk of the iceberg cluster is shared equally amongst the users.
I.e. each user has the same privileges for running jobs as another user.
•
However, there are extra nodes connected to the iceberg cluster that are owned by individual research groups.
•
It is possible for new research project groups to purchase their own compute nodes/clusters and make it part of the iceberg cluster.
•
We define such groups as special project groups in SGE parlance and give priority to their jobs on the machines that they have purchased.
•
This scheme allows such research groups to use iceberg as ordinary users “with equal share to other users” or to use their privileges ( via the –P parameter) to run jobs on their own part of the cluster without having to compete with other users.
•
This way, everybody benefits as the machines currently unused by a project group can be utilised to run normal users ’ short jobs.
Queue name short.q
long.q
parallel.q
openmp.q
gpu.q
Job queues on iceberg
Time Limit
(Hours)
8
168
168
168
168
System specification
Long running serial jobs
Jobs requiring multiple nodes
Shared memory jobs using openmp
Jobs using the gpu units
Beyond Iceberg
•
Iceberg OK for many compute problems
•
N8 tier 2 facility for more demanding compute problems
•
Hector/Archer Larger facility for grand challenge problems (pier review process to access)
N8 HPC – Polaris – Compute Nodes
•
316 nodes (5,056 cores) with 4 GByte of RAM per core (each node has 8 DDR3 DIMMS each of 8 GByte). These are known as "thin nodes".
•
16 nodes (256 cores) with 16 GByte of RAM per core (each node has
16 DDR3 DIMMS each of 16 GByte). These are known as "fat nodes".
•
Each node comprises two of the Intel 2.6 GHz Sandy Bridge E5-2670 processors.
•
Each processor has 8 cores, giving a total core count of 5,312 cores
•
Each processor has a 115 Watts TDP and the Sandy Bridge architecture supports "turbo" mode
•
Each node has a single 500 GB SATA HDD
•
There are 4 nodes in each Steelhead chassis. 79 chassis have 4
GB/core and 4 more have 16 GB/core
N8 HPC – Polaris – Storage and Connectivity
•
Connectivity
▬ The compute nodes are fully connected by Mellanox QDR
InfiniBand high performance interconnects
•
File System & Storage
▬ 174 TBytes Lustre v2 parallel file system with 2 OSSes.
This is mounted as /nobackup and has no quota control. It is not backed up and files are automatically expired after 90 days.
▬ 109 TBytes NFS filesystem where user $HOME is mounted.
This is backed up.
Getting Access to N8
•
Note N8 is for users whose research problems require greater resource than that available through
Iceberg
•
Registration is through Projects
▬ Ask your supervisor or project leader to register their project with the N8
▬ Users obtain a project code from supervisor or project leader
▬ Complete online form provide an outline of work explaining why N8 resources are required
Steps to Apply for an N8 User Account
•
Request an N8 Project Code from supervisor/project leader
•
Complete user account online application form at
▬ http://n8hpc.org.uk/research/gettingstarted/
•
Note:
▬ If your project leader does not have a project code
▬ Project leader should apply for a project account at
▬ http://n8hpc.org.uk/research/gettingstarted/
Getting help
• Web site
– http://www.shef.ac.uk/wrgrid/
• Documentation
– http://www.shef.ac.uk/wrgrid/using
• Training (also uses the learning management system)
– http://www.shef.ac.uk/wrgrid/training
• Uspace
– http://www.shef.ac.uk/wrgrid/uspace
• Contacts
– http://www.shef.ac.uk/wrgrid/contacts.html