estimation II
advertisement

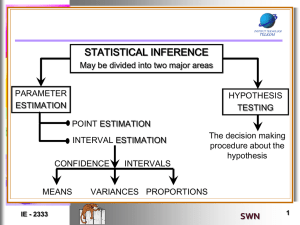
STATISTICAL INFERENCE
PART II
SOME PROPERTIES OF
ESTIMATORS
1
SOME PROPERTIES OF
ESTIMATORS
• θ: a parameter of interest; unknown
• Previously, we found good(?) estimator(s)
for θ or its function g(θ).
• Goal:
• Check how good are these estimator(s).
Or are they good at all?
• If more than one good estimator is
available, which one is better?
2
SOME PROPERTIES OF
ESTIMATORS
• UNBIASED ESTIMATOR (UE): An
estimator ˆ is an UE of the unknown
parameter , if
E ˆ for all
Otherwise, it is a Biased Estimator of .
Bias ˆ E ˆ
ˆ 0.
If ˆ is UE of , Bias
Bias of
ˆ for estimating
3
SOME PROPERTIES OF
ESTIMATORS
• ASYMPTOTICALLY UNBIASED
ESTIMATOR (AUE): An estimator ˆ is
an AUE of the unknown parameter , if
ˆ 0
Bias ˆ 0 but lim
Bias
n
4
SOME PROPERTIES OF
ESTIMATORS
• CONSISTENT ESTIMATOR (CE): An
estimator ˆ which converges in probability
to an unknown parameter for all is
called a CE of .
p
ˆ
.
For large n, a CE tends to be closer to
the unknown population parameter.
• MLEs are generally CEs.
5
EXAMPLE
For a r.s. of size n,
E X X is an UE of .
By WLLN,
p
X
X is a CE of .
6
MEAN SQUARED ERROR (MSE)
• The Mean Square Error (MSE) of an
estimator ˆ for estimating is
MSE ˆ E ˆ Var ˆ Bias ˆ
2
2
If MSE ˆ is smaller, ˆ is a better estimator
of .
For two estimators, ˆ1 and ˆ2 of , if
MSE ˆ1 MSE ˆ2 ,
ˆ1 is better estimator of .
7
MEAN SQUARED ERROR
CONSISTENCY
• Tn is called mean squared error
consistent (or consistent in quadratic
mean) if E{Tn}20 as n.
Theorem: Tn is consistent in MSE iff
i) Var(Tn)0 as n.
ii ) lim E Tn .
n
• If E{Tn}20 as n, Tn is also a CE of .
8
EXAMPLES
X~Exp(), >0. For a r.s of size n, consider
the following estimators of , and discuss
their bias and consistency.
n
n
Xi
T1 i 1
n
Xi
,
T2 i 1
n 1
Which estimator is better?
9
SUFFICIENT STATISTICS
• X, f(x;),
• X1, X2,…,Xn
• Y=U(X1, X2,…,Xn ) is a statistic.
• A sufficient statistic, Y, is a statistic which
contains all the information for the estimation
of .
10
SUFFICIENT STATISTICS
• Given the value of Y, the sample contains no
further information for the estimation of .
• Y is a sufficient statistic (ss) for if the
conditional distribution h(x1,x2,…,xn|y) does not
depend on for every given Y=y.
• A ss for is not unique:
• If Y is a ss for , then any 1-1 transformation of Y,
say Y1=fn(Y) is also a ss for .
11
SUFFICIENT STATISTICS
• The conditional distribution of sample rvs
given the value of y of Y, is defined as
f x1 , x2 , , xn , y;
h x1 , x2 , , xn y
g y;
L ; x1 , x2 , , xn
h x1 , x2 , , xn y
g y;
• If Y is a ss for , then Not depend on for every given y.
L ; x1 , x2 , , xn
h x1 , x2 , , xn y
H x1 , x2 , , xn
g y;
ss for
may include y or constant.
12
• Also, the conditional range of Xi given y not depend on .
SUFFICIENT STATISTICS
EXAMPLE: X~Ber(p). For a r.s. of size n,
n
show that Xi is a ss for p.
i 1
13
SUFFICIENT STATISTICS
• Neyman’s Factorization Theorem: Y is a
ss for iff
L k1 y; k2 x1 , x2 ,
The likelihood function
Does not depend on xi
except through y
, xn
Not depend on (also in
the range of xi.)
where k1 and k2 are non-negative
functions.
14
EXAMPLES
1. X~Ber(p). For a r.s. of size n, find a ss for
p if exists.
15
EXAMPLES
2. X~Beta(θ,2). For a r.s. of size n, find a ss
for θ.
16
SUFFICIENT STATISTICS
• A ss may not exist.
• Jointly ss Y1,Y2,…,Yk may be needed.
Example: Example 10.2.5 in Bain and
Engelhardt (page 342 in 2nd edition), X(1) and X(n)
are jointly ss for
• If the MLE of exists and unique and if a
ss for exists, then MLE is a function of a
ss for .
17
EXAMPLE
X~N(,2). For a r.s. of size n, find jss for
and 2.
18
MINIMAL SUFFICIENT STATISTICS
• If S( x ) (s1( x ),...,s k ( x )) is a ss for θ, then,
~
~
~
S* (x) (s0 (x),s1(x),...,s k (x)) is also a ss
~
~
~
~
for θ. But, the first one does a better job in
data reduction. A minimal ss achieves the
greatest possible reduction.
19
MINIMAL SUFFICIENT STATISTICS
• A ss T(X) is called minimal ss if, for any
other ss T’(X), T(x) is a function of T’(x).
• THEOREM: Let f(x;) be the pmf or pdf of
a sample X1, X2,…,Xn. Suppose there exist
a function T(x) such that, for two sample
points x1,x2,…,xn and y1,y2,…,yn, the ratio
f x1 , x2 , , xn ;
f y1 , y2 , , yn ;
is constant with respect to iff T(x)=T(y).
Then, T(X) is a minimal sufficient statistic
for .
20
EXAMPLE
• X~N(,2) where 2 is known. For a r.s. of
size n, find minimal ss for .
Note: A minimal ss is also not unique.
Any 1-to-1 function is also a minimal ss.
21
RAO-BLACKWELL THEOREM
•
Let X1, X2,…,Xn have joint pdf or pmf
f(x1,x2,…,xn;) and let S=(S1,S2,…,Sk) be a
vector of jss for . If T is an UE of ()
and (T)=E(TS), then
i) (T) is an UE of () .
ii) (T) is a fn of S, so it is also jss for .
iii) Var((T) ) Var(T) for all .
• (T) is a uniformly better unbiased estimator
of () .
22
RAO-BLACKWELL THEOREM
• Notes:
• (T)=E(TS) is at least as good as T.
• For finding the best UE, it is enough to
consider UEs that are functions of a ss,
because all such estimators are at least as good
as the rest of the UEs.
23
Example
• Hogg & Craig, Exercise 10.10
• X1,X2~Exp(θ)
• Find joint p.d.f. of ss Y1=X1+X2 for θ and
Y2=X2.
• Show that Y2 is UE of θ with variance θ².
• Find φ(y1)=E(Y2|Y1) and variance of φ(Y1).
24
ANCILLARY STATISTIC
• A statistic S(X) whose distribution does not
depend on the parameter is called an
ancillary statistic.
• Unlike a ss, an ancillary statistic contains no
information about .
25
Example
• Example 6.1.8 in Casella & Berger, page
257:
Let Xi~Unif(θ,θ+1) for i=1,2,…,n
Then, range R=X(n)-X(1) is an ancillary
statistic because its pdf does not depend
on θ.
26
COMPLETENESS
• Let {f(x; ), } be a family of pdfs (or pmfs)
and U(x) be an arbitrary function of x not
depending on . If
E U X 0 for all
requires that the function itself equal to 0 for all
possible values of x; then we say that this family
is a complete family of pdfs (or pmfs).
E U X 0 for all U x 0 for all x.
i.e., the only unbiased estimator of 0 is 0 itself.
27
EXAMPLES
1. Show that the family {Bin(n=2,); 0<<1}
is complete.
28
EXAMPLES
2. X~Uniform(,). Show that the family
{f(x;), >0} is not complete.
29
COMPLETE AND SUFFICIENT
STATISTICS (css)
• Y is a complete and sufficient statistic
(css) for if Y is a ss for and the family
g y; ;
is complete.
The pdf of Y.
1) Y is a ss for .
2) u(Y) is an arbitrary function of Y.
E(u(Y))=0 for all implies that u(y)=0
30
for all possible Y=y.
BASU THEOREM
• If T(X) is a complete and minimal sufficient
statistic, then T(X) is independent of every
ancillary statistic.
• Example: X~N(,2).
X : the mss for
X ~ N( , 2 / n ) and family of N( , 2 / n ) is complete family.
X is a complete statistic
(n-1)S2/
2 ~
2
n 1
S2 Ancillary statistic for
By Basu theorem, X and S2 are independent.
31
BASU THEOREM
• Example:
X1, X2~N(,2), independent, 2 known.
• Let T=X1+ X2 and U=X1 - X2
• We know that T is a complete minimal ss.
• U~N(0, 2) distribution free of
T and U are independent by Basu’s Theorem
32
THE MINIMUM VARIANCE UNBIASED
ESTIMATOR
• Rao-Blackwell Theorem: If T is an
unbiased estimator of , and S is a ss
for , then (T)=E(TS) is
– an UE of , i.e.,E[(T)]=E[E(TS)]= and
– the MVUE of .
33
LEHMANN-SCHEFFE THEOREM
• Let Y be a css for . If there is a function Y
which is an UE of , then the function is
the unique Minimum Variance Unbiased
Estimator (UMVUE) of .
• Y css for .
• T(y)=fn(y) and E[T(Y)]=.
T(Y) is the UMVUE of .
So, it is the best estimator of .
34
THE MINIMUM VARIANCE UNBIASED
ESTIMATOR
• Let Y be a css for . Since Y is complete,
there could be only a unique function of Y
which is an UE of .
• Let U1(Y) and U2(Y) be two function of Y.
Since they are UE’s, E(U1(Y)U2(Y))=0
imply W(Y)=U1(Y)U2(Y)=0 for all possible
values of Y. Therefore, U1(Y)=U2(Y) for all
Y.
35
Example
• Let X1,X2,…,Xn ~Poi(μ). Find UMVUE of μ.
• Solution steps: n
– Show that S X i is css for μ.
i 1
– Find a statistics (such as S*) that is UE of μ
and a function of S.
– Then, S* is UMVUE of μ by Lehmann-Scheffe
Thm.
36
Note
• The estimator found by Rao-Blackwell
Thm may not be unique. But, the estimator
found by Lehmann-Scheffe Thm is unique.
37