rSession21
advertisement

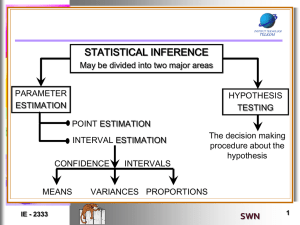
Distance-Constraint Reachability Computation in Uncertain Graphs Ruoming Jin, Lin Liu Kent State University Bolin Ding UIUC Haixun Wang MSRA Why Uncertain Graphs? Increasing importance of graph/network data Social Network, Biological Network, Traffic/Transportation Network, Peer-to-Peer Network Probabilistic perspective gets more and more attention recently. Uncertainty is ubiquitous! Protein-Protein Interaction Networks False Positive > 45% Social Networks Probabilistic Trust/Influence Model Uncertain Graph Model a 0.5 0.3 0.2 s Edge Independence 0.5 0.6 b 0.1 0.7 0.4 c t 0.9 Existence Probability • Possible worlds (2#Edge) a G1: s a b c t G2: s b t c Weight of G2: Pr(G2) =0.5 * 0.7 * 0.2 * 0.6 * (1-0.5) *(1-0.4) *(1-0.9) *(1-0.1) * (1-0.3) = 0.0007938 Distance-Constraint Reachability (DCR) Problem Given distance constraint d and two vertices s and t, Source a 0.5 Target 0.3 0.2 s 0.5 0.1 0.7 c b 0.4 0.6 t 0.9 • What is the probability that s can reach t within distance d? • A generalization of the two-terminal network reliability problem, which has no distance constraint. Important Applications • Peer-to-Peer (P2P) Networks – Communication happens only when node distance is limited. • Social Networks – Trust/Influence can only be propagated only through small number of hops. • Traffic Networks – Travel distance (travel time) query – What is the probability that we can reach the airport within one hour? Example: Exact Computation a 0.5 • d = 2, 0.5 0.2 s ? 0.3 0.1 0.7 c b 0.4 0.6 t 0.9 First Step: Enumerate all possible worlds (29), a s b c t s b c a a a t s b c t s b t c Pr(G1) Pr(G2) Pr(G3) Pr(G4) Second Step: Check for distance-constraint connectivity, = … + Pr(G1) * 0+ Pr(G2) * 1+ Pr(G3)* 0+ Pr(G4) * 1 + … Approximating Distance-Constraint Reachability Computation • Hardness – Two-terminal network reliability is #PComplete. – DCR is a generalization. • Our goal is to approximate through Sampling – Unbiased estimator – Minimal variance – Low computational cost Start from the most intuitive estimators, right? Direct Sampling Approach • Sampling Process – Sample n graphs – Sample each graph according to edge probability a 0.5 0.3 0.2 s 0.5 0.1 0.7 c b 0.4 0.6 t 0.9 a s b c t Direct Sampling Approach (Cont’) • Estimator • Unbiased • Variance = 1, s reach t within d; = 0, otherwise. Indicator function E( Rˆ B ) Path-Based Approach • Generate Path Set – Enumerate all paths from s to t with length ≤ d a 0.3 0.2 s 0.1 0.7 c b 0.4 – Enumeration methods • E.g., DFS 0.6 0.9 t Path-Based Approach (Cont’) • Path set • • Exactly computed by Inclusion-Exclusion principle • Approximated by Monte-Carlo Algorithm by R. M. Karp and M. G. Luby ( ) • Unbiased • Variance Can we do better? Divide-and-Conquer Methodology • Example a s b t +(s,a) c -(s,a) a s b a t s c b a s +(a,t) … t -(a,t) +(s,b) -(s,b) c b t c a s a s b b … t c t c … a s b … t c … a s b c t … Divide and Conquer (Cont’) Summarize: 1. # of leaf all possible worlds nodes is smaller than 2|E| . Graphs having e1 Graphs not Having e1 2. Each possible world exists only in one leaf node. … … ... s can reach t. 3. Reachability is the sum of the weights of blue nodes. … ... 4. Leaf nodes form a nice sample space. s can not reach t. How do we sample? Start from here Pri: Sample Unit Weight; Sum of possible worlds’ probabilities in the node. … … ... Sample Unit • Unequal probability sampling qi: sampling probability, determined by … ... properties of coins along the way. – Hansen-Hurwitz (HH) estimator – Horvitz-Thomson (HT) estimator Hansen-Hurwitz (HH) Estimator sample size • Estimator • Unbiased • Variance = 1, blue node Weight = 0, red node Sampling probability To minimize the variance above, we have :Pri = qi Pri = p(e1)*p(e2)*(1-p(e Pri: the leaf node weight 3))*… P(e1) 1-P(e1) p(e1) : 1 – p(e qi: the sampling 1) P(e2) probability 1-P(e2) 1-P(e4) P(e4) 1-P(e ) 3 p(e ) : 1 – p(e ) P(e ) 2 2 p(e3) : 1 – p(e3) 3 … … ... … ... Horvitz-Thomson (HT) Estimator • Estimator # of Unique sample units • Unbiased • Variance – To minimize vairance, we find Pri = qi – Smaller variance than HH estimator Can we further reduce the variance and computational cost? Recursive Estimator 1. Unbiased 2. Variance: Sample the subspace n1 times n1 +Sample n2 = n the entire space n times Sample the subspace n2 times … … ... We can not minimize the variance without knowing τ1 and τ2. Then what can we … do? ... Sample Allocation • We guess: What if – n1 = n*p(e) – n2 = n*(1-p(e))? • We find: Variance reduced! – HH Estimator: – HT Estimator: Sample Allocation (Cont’) • Sampling Time Reduced!! Sample size = n Directly allocate samples n1=n*p(e1) n3=n1*p(e2) Toss coin when sample size is small n4=n1*(1-p(e2)) n2=n*(1-p(e1)) Experimental Setup • Experiment setting – Goal: • Relative Error • Variance • Computational Time – System Specification • 2.0GHz Dual Core AMD Opteron CPU • 4.0GB RAM • Linux Experimental Results • Synthetic datasets – Erdös-Rényi random graphs – Vertex#: 5000, edge density: 10, Sample size: 1000 – Categorized by extracted-subgraph size (#edge) – For each category, 1000 queries Experimental Results • Real datasets – – – – DBLP: 226,000 vertices, 1,400,000 edges Yeast PPIN: 5499 vertices, 63796 edges Fly PPIN: 7518 vertices, 51660 edges Extracted subgraphs size: 20 ~ 50 edges Conclusions • We first propose a novel s-t distance-constraint reachability problem in uncertain graphs. • One efficient exact computation algorithm is developed based on a divide-and-conquer scheme. • Compared with two classic reachability estimators, two significant unequal probability sampling estimators Hansen-Hurwitz (HH) estimator and Horvitz-Thomson (HT) estimator. • Based on the enumeration tree framework, two recursive estimators Recursive HH, and Recursive HT are constructed to reduce estimation variance and time. • Experiments demonstrate the accuracy and efficiency of our estimators. Thank you ! Questions?