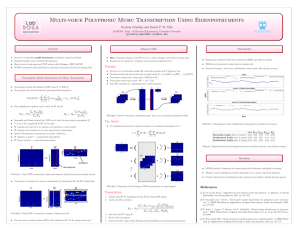
Experiments Result And Analysis
advertisement

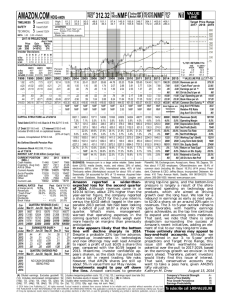
Intelligent Control and Automation, 2008. WCICA 2008. • NMF considers factorizations of the form: 𝑋 ≈ 𝑍𝐻 Where 𝑋 ∈ 𝑅+ 𝐹×𝐿 , 𝑍 ∈ 𝑅+ 𝐹×𝑀 , 𝐻 ∈ 𝑅+ 𝑀×𝐿 , 𝑀 ≪ 𝐹 • To measure the cost of the decomposition, one popular approach is to use the Kullback-Leibler (KL) divergence metric, the cost for factorizing X into ZH is evaluated as: 𝐿 𝐷𝑁𝑀𝐹 (𝑋| 𝑍𝐻 = 𝐿 𝑗=1 𝐹 = 𝑥𝑖,𝑗 ln 𝑗=1 𝑖=1 𝐾𝐿(𝑥𝑗 | 𝑍ℎ𝑗 𝑥𝑖,𝑗 + 𝑧 ℎ 𝑘 𝑖,𝑘 𝑘,𝑗 𝑧𝑖,𝑘 ℎ𝑘,𝑗 − 𝑥𝑖,𝑗 𝑘 • Using the Expectation Maximization (EM) algorithm and an appropriately designed auxiliary function, it has been shown in “Algorithms for non-negative matrix factorization,” the update rule for the 𝑡-th iteration for ℎ𝑘,𝑗 (𝑡) is given by: 𝑥𝑖,𝑗 (𝑡−1) 𝑖 𝑧𝑖,𝑘 (𝑡−1) ℎ (𝑡−1) 𝑧 𝑙,𝑗 𝑙 𝑖,𝑙 ℎ𝑘,𝑗 (𝑡) = ℎ𝑘,𝑗 (𝑡−1) (𝑡−1) 𝑧 𝑖,𝑘 𝑖 • while for 𝑧𝑖,𝑘 (𝑡) the update rule is given by: 𝑧′ 𝑖,𝑘 (𝑡) 𝑗 ℎ𝑘,𝑗 = 𝑧𝑖,𝑘 (𝑡−1) (𝑡−1) 𝑥𝑖,𝑗 (𝑡−1) (𝑡−1) 𝑧ℎ ℎ 𝑖,𝑙 𝑙,𝑗 𝑙 (𝑡−1) ℎ 𝑗 𝑘,𝑗 • Finally, the basis images matrix 𝑍 is normalized so that its column vectors elements sum up to one: ′ (𝑡) 𝑧 𝑖,𝑘 𝑧𝑖,𝑘 (𝑡) = ′ (𝑡) 𝑧 𝑙 𝑙,𝑘 Cluster 1 … Class 1 Cluster 𝐶1 Cluster 1 … Cluster 𝐶𝜃 Image 𝜌 … … … Database 𝔗 … … Class 𝑟 Image 1 Cluster 𝐶𝑟 Image 𝑁(𝑟)(𝜃) Cluster 1 Class 𝑛 … Cluster 𝐶𝑛 Image 1 Database 𝔗 Image 𝜌 Class 𝑟 Image 𝑁(𝑟)(𝜃) Cluster 𝐶𝜃 NMF Dimensionality reduction Feature Vector 𝜂𝜌 (𝑟)(𝜃) = 𝜂𝜌,1 (𝑟)(𝜃) ⋯ 𝜂𝜌,𝑀 (𝑟)(𝜃) Mean of Feature Vector for the 𝜃-𝑡ℎ cluster of the 𝑟-𝑡ℎ class: 𝜇 (𝑟)(𝜃) = 1 𝑁(𝑟)(𝜃) 𝑁(𝑟)(𝜃) 𝜂𝑖 (𝑟)(𝜃) = 𝜇1 (𝑟)(𝜃) ⋯ 𝜇𝑀 (𝑟)(𝜃) 𝑖=1 𝑇 𝑇 • Using the above notations we can define the within cluster scatter matrix 𝑆𝑤 as: 𝑛 𝐶𝑟 𝑁(𝑟)(𝜃) 𝑆𝑤 = 𝜂𝜌 (𝑟)(𝜃) − 𝜇 (𝑟)(𝜃) η𝜌 (𝑟)(𝜃) − 𝑇 (𝑟)(𝜃) 𝜇 𝑟=1 𝜃=1 ρ=1 • and the between cluster scatter matrix 𝑆𝑏 as: 𝑛 𝑛 𝐶𝑖 𝐶𝑟 𝜇 (𝑖)(𝑗) 𝑆𝑏 = − 𝜇 (𝑟)(𝜃) 𝜇 (𝑖)(𝑗) 𝑖=1 𝑟≠1 𝑗=1 𝜃=1 • Our Goal: 𝑡𝑟 𝑆𝑤 ↓ 𝑎𝑛𝑑 𝑡𝑟[𝑆𝑏 ] ↑ − 𝑇 (𝑟)(𝜃) 𝜇 Since we desire the trace of matrix 𝑆𝑤 to be as small as possible and at the same time the trace of 𝑆𝑏 to be as large as possible, the new cost function is formulated as: 𝛼 𝛽 𝐷𝑆𝐷𝑁𝑀𝐹 𝑋||𝑍𝐻 = 𝐷𝑁𝑀𝐹 𝑋||𝑍𝐻 + 𝑡𝑟 𝑆𝑤 − 𝑡𝑟 𝑆𝑏 2 2 1 where 𝛼 and 𝛽 are positive constants, while is used to simplify 2 subsequent derivations. Consequently, the new minimization problem is formulated as: min 𝐷𝑆𝐷𝑁𝑀𝐹 𝑋||𝑍𝐻 𝑍,𝐻 subject to : 𝑧𝑖,𝑘 ≥ 0, ℎ𝑘,𝑗 ≥ 0, 𝑖 𝑍𝑖,𝑘 = 1, ∀𝑖, 𝑗, 𝑘. • The constrained optimization problem is solved by introducing Lagrangian multipliers ∶ ℒ 𝛼 𝛽 = 𝐷𝑁𝑀𝐹 𝑋||𝑍𝐻 + 𝑡𝑟 𝑆𝑤 − 𝑡𝑟 𝑆𝑏 + ∅𝑖,𝑘 𝑧𝑖,𝑘 2 2 𝑖 𝑘 + 𝑗 𝑘 ѱ𝑗,𝑘 ℎ𝑗,𝑘 𝛼 𝛽 ℒ = 𝐷𝑁𝑀𝐹 𝑋||𝑍𝐻 + 𝑡𝑟 𝑆𝑤 − 𝑡𝑟 𝑆𝑏 + 𝑡𝑟 ∅𝑍 𝑇 + 𝑡𝑟 ѱ𝐻 𝑇 2 2 • Consequently, the optimization problem is equivalent to the minimization of the Lagrangian 𝑎𝑟𝑔 min ℒ 𝑍,𝐻 • To minimize ℒ, we first obtain its partial derivatives with respect to 𝑧𝑖,𝑗 and ℎ𝑖,𝑗 and set them equal to zero : 𝜕ℒ =− 𝜕ℎ𝑖,𝑗 𝜕ℒ =− 𝜕𝑧𝑖,𝑗 𝑘 𝑙 𝑥𝑘,𝑗 𝑧𝑘,𝑖 + 𝑧 ℎ 𝑙 𝑘,𝑙 𝑙,𝑗 𝑥𝑘,𝑗 𝑧𝑘,𝑖 + 𝑧 ℎ 𝑙 𝑘,𝑙 𝑙,𝑗 𝑙 𝑙 𝛼 𝜕𝑡𝑟 𝑆𝑤 𝛽 𝜕𝑡𝑟 𝑆𝑏 𝑧𝑙,𝑖 + ѱ𝑖,𝑗 + + 2 𝜕ℎ𝑖,𝑗 2 𝜕𝑧𝑖,𝑗 𝛼 𝜕𝑡𝑟 𝑆𝑤 𝛽 𝜕𝑡𝑟 𝑆𝑏 𝑧𝑙,𝑖 + ѱ𝑖,𝑗 + + 2 𝜕ℎ𝑖,𝑗 2 𝜕𝑧𝑖,𝑗 • DNMF combines Fisher’s criterion in the NMF decomposition • and achieves a more efficient decomposition of the • provided data to its discriminant parts, thus enhancing separability • between classes compared with conventional NMF 𝑉 = 𝑣1 , 𝑣2 , … , 𝑣𝑚 ∈ 𝑅1×𝑚 ↓ Dimensionality reduction 𝑈 = 𝑢1 , 𝑢2 , … , 𝑢𝑛 ∈ 𝑅1×𝑛 Where 𝑛 ≪ 𝑚 𝑉∗𝐵 =𝑈 Where 𝐵 ∈ 𝑅𝑚×𝑛 𝑉∗𝐵 =𝑈 Where 𝑉 ∈ 𝑅1×2 𝐵 ∈ 𝑅2×1 𝑈 ∈ 𝑅1×1 • • • • • • Introduction Principal Component Analysis (PCA) Method Non-negative Matrix Factorization (NMF) Method PCA-NMF Method Experiments Result and Analysis Conclusion • In this paper, we have detailed PCA and NMF, and applied them to feature extraction of facial expression images. • We also try to process basic image matrix and weight matrix of PCA and make them as the initialization of NMF. • The experiments demonstrate that the method has got a better recognition rate than PCA and NMF. Let’s suppose that m expression images are selected to take part in training, the training set X is defined by 𝑋 = 𝑥1, 𝑥2 … 𝑥𝑚 ∈ 𝑅𝑛×𝑚 (1) Covariance matrix corresponding to all training samples is obtained as 𝑚 𝐶= 𝑥𝑖 − 𝑢 𝑥𝑖 − 𝑢 𝑇 (2) 𝑖=1 u, average face, is defined by 𝑚 1 𝑢= 𝑥𝑖 𝑚 𝑖=1 (3) 𝑛 = 𝑟𝑜𝑤 × 𝑐𝑜𝑙 # of training data 𝒎=𝟒 𝑐𝑜𝑙 average face 𝒖 + + 𝑟𝑜𝑤 𝟒 𝑥1 𝑥2 𝑥3 𝑥4 Training Data Set 𝑋 ∈ 𝑅𝑛×𝑚 𝑢 + Let A = 𝑥1 − 𝑢, 𝑥2 − 𝑢 … 𝑥𝑚 − 𝑢 Then (2) becomes 𝐶 = 𝐴𝐴𝑇 𝐴 ∈ 𝑅𝑛×𝑚 𝐶 ∈ 𝑅𝑛×𝑛 (4) (5) Matrix 𝐶 has 𝑛 eigenvectors and eigenvalues. Image 50x50 𝑛 = 50 × 50 = 2500 It is difficult to get 2500 eigenvectors and eigenvalues. Therefore, we get eigenvectors and eigenvalues of 𝐴𝐴𝑇 by solving eigenvectors and eigenvalues of 𝐴𝑇 𝐴. 𝐴𝑇 𝐴 ∈ 𝑅𝑚×𝑚 The vectors 𝑣𝑖 (𝑖 = 1,2 … 𝑟)and scalars 𝜆𝑖 (𝑖 = 1,2 … 𝑟)are the eigenvectors and eigenvalues of covariance matrix 𝐴𝑇 𝐴. Then, eigenvectors 𝑢𝑖 of 𝐴𝐴𝑇 are defined by 1 𝑢𝑖 = 𝐴𝑣𝑖 𝑖 = 1,2 … 𝑟 6 𝜆𝑖 Sorting 𝜆𝑖 by size: 𝜆1 ≥ 𝜆2 ≥ ⋯ ≥ 𝜆𝑟 > ⋯ > 0 Generally, the scale is capacity that 𝑑 eigenvalues occupied: 𝑑 𝑖=1 𝜆𝑖 ≥ 𝛼,usally, 𝛼 is 0.9~0.99. (7) 𝑟 𝑖=1 𝜆𝑖 Set 𝑊 is a projection matrix, 𝑊 = 𝑊1 , 𝑊2 … 𝑊𝑑 . And then, every facial expression image feature can be denoted by following equation 𝑔𝑖 = 𝑊 𝑇 𝑥𝑖 − 𝑢 (8) PCA basic images Given a non-negative matrix 𝑋, the NMF algorithms seek to find non-negative factors 𝐵 and 𝐻 of 𝑋 ,such that : 𝑋𝑛×𝑚 ≈ 𝐵𝑛×𝑟 𝐻𝑟×𝑚 (9) where 𝑟 is the number of feature vector satisfies 𝑛×𝑚 𝑟< 𝑛+𝑚 (10) Iterative update formulae are given as follow: 𝐵𝑇 𝑋 𝑘𝑗 𝐻𝑘𝑗 ← 𝐻𝑘𝑗 𝑇 𝐵 𝐵𝐻 𝑘𝑗 𝑋𝐻 𝑇 𝑖𝑘 𝐵𝑖𝑘 ← 𝐵𝑖𝑘 𝐵𝐻𝐻 𝑇 𝑖𝑘 set 𝐴 = 𝐵𝐻, then define objective function min 𝑋 − 𝐴 2 (11) (12) (13) And then, every facial expression image feature can be denoted by following equation 𝑔𝑖 = 𝑊 −1 𝑥𝑖 (14) NMF basic images First, get projective matrix 𝑊 and weight matrix 𝐺 by PCA method. Initialization is performed for matrices 𝐵 and 𝐻 by following 𝐵 = min 1, abs 𝑊𝑖𝑘 (15) 𝐻 = min 1, abs 𝐺𝑘𝑗 (16) NMF basic images PCA-NMF basic images anger anger disgust disgust fear fear happy neutral happy neutral sad sad surprise surprise The comparison of recognition rate for every expression ( The training set comprises 70 images and the test set of 70 images) The comparison of recognition rate for every expression ( The training set comprises 70 images and the test set of 143 images) The comparison of recognition rate for every expression ( The training set comprises 140 images and the test set of 73 images) The discussion or r The results of experiments demonstrate that NMF and PCA-NMF can outperform PCA. The best recognition rate of facial expression image is 93.72%. On the whole, our approach provides good recognition rates.